Nous avons fait un grand pas en avant en découvrant la technologie JDBC, mais il est déjà nécessaire de nous poser certaines questions. Dans ce chapitre, nous allons :
- lister les problèmes liés à la liaison directe entre nos objets métier et notre base de données ;
- découvrir et mettre en place le design pattern DAO, qui répond parfaitement à cette problématique ;
- apprendre à l'intégrer proprement dans notre application web.
Objectifs
Inconvénients de notre solution
Dans le précédent chapitre, nous avons uniquement testé JDBC dans un bac à sable, sans vraiment nous soucier de son intégration dans le cas d'une vraie application. Nous avons certes pris la peine de découper un minimum notre exemple, en séparant nettement le trio vue, contrôleur et modèle, mais ce n'est pas suffisant.
Voilà à la figure suivante une représentation globale de ce que nous avons actuellement, avec en rouge les objets de notre couche modèle directement en contact avec le système de stockage.
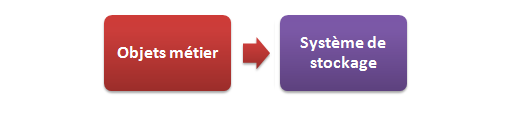
Pourquoi n'est-ce pas suffisant ? La gestion des données est bien effectuée dans le modèle !
En effet, en théorie MVC est ainsi bien respecté. Mais dans la pratique, dans une application qui est constituée de plusieurs centaines voire milliers de classes, cela constitue un réel problème de conception : si nous codons une vraie application de cette manière, nous lions alors très fortement - pour ne pas dire mélangeons - le code responsable des traitements métier au code responsable du stockage des données. Si bien qu'en fin de compte, il devient impossible d'exécuter séparément l'un ou l'autre. Et ceci est fâcheux pour plusieurs raisons :
- il est impossible de mettre en place des tests unitaires :
- impossible de tester le code métier de l'application sans faire intervenir le stockage (BDD, etc.) ;
- impossible de ne tester que le code relatif au stockage des données, obligation de lancer le code métier.
- il est impossible de changer de mode de stockage. Que ce soit vers un autre SGBD, voire vers un système complètement différent d'une base de données, cela impliquerait une réécriture complète de tout le modèle, car le code métier est mêlé avec et dépendant du code assurant le stockage.
Vous trouverez toujours quelqu'un qui vous dira que si chaque composant n'est pas testable séparément ce n'est pas un drame, quelqu'un d'autre qui vous dira que lorsque l'on crée une application on ne change pas de mode de stockage du jour au lendemain, etc. Ces gens-là, je vous conseille de ne les écouter que d'une oreille : écrire un code orienté objet et bien organisé est une excellente pratique, et c'est ce que je vais vous enseigner dans cette partie du cours.
Je pourrais continuer la liste des inconvénients, en insistant notamment sur le fait qu'un code mélangé dans une couche "modèle" monolithique est bien plus difficile à maintenir et à faire évoluer qu'un code proprement découpé et organisé, mais je pense que vous avez déjà compris et êtes déjà convaincus. 
Pour information, ce constat n'est absolument pas limité à la plate-forme Java. Vous trouverez des solutions qui répondent à ce besoin dans n'importe quelle technologie web, citons par exemple les « fat model » avec Ruby on Rails.
Isoler le stockage des données
L'idée est qu'au lieu de faire communiquer directement nos objets métier avec la base de données, ou le système de fichiers, ou les webservices, ou peu importe ce qui fait office de système de stockage, ceux-ci vont parler avec la couche DAO. Et c'est cette couche DAO qui va ensuite de son côté communiquer avec le système de stockage.
L'objectif de l'architecture que nous devons mettre en place n'est donc rien d'autre que l'isolement pur et simple du code responsable du stockage des données. Nous souhaitons en effet littéralement encapsuler ce code dans une couche plus ou moins hermétique, de laquelle aucune information concernant le mode de stockage utilisé ne s'échappe. En d'autres termes, notre objectif est de cacher la manière dont sont stockées les données au reste de l'application.
Voilà cette fois une représentation de ce que nous souhaitons mettre en place (voir figure suivante).

Vous visualisez bien que seul le DAO est en contact avec le système de stockage, et donc que seul lui en a connaissance. Le revers de la médaille, si c'en est un, c'est qu'afin de réaliser le cloisonnement du stockage des données, la création d'une nouvelle couche est nécessaire, c'est-à-dire l'écriture de codes supplémentaires et répétitifs.
En résumé, l'objectif du pattern DAO tient en une phrase : il permet de faire la distinction entre les données auxquelles vous souhaitez accéder, et la manière dont elles sont stockées.
Principe
Constitution
Le principe du pattern DAO est de séparer la couche modèle d'une application en deux sous-couches distinctes :
- une couche gérant les traitements métier appliqués aux données, souvent nommée couche service ou métier. Typiquement, tout le travail de validation réalisé dans nos objets InscriptionForm et ConnexionForm en fait partie ;
- une couche gérant le stockage des données, logiquement nommée couche de données. Il s'agit là des opérations classiques de stockage : la création, la lecture, la modification et la suppression. Ces quatre tâches basiques sont souvent raccourcies à l'anglaise en CRUD.
Pour réaliser efficacement une telle opération, il est nécessaire d'encapsuler les exceptions spécifiques au mode de stockage dans des exceptions personnalisées et propres à la couche DAO. Dans notre cas par exemple, nous allons devoir faire en sorte que les exceptions propres à SQL ou à JDBC ne soient pas vues comme telles par nos objets métier, mais uniquement comme des exceptions émanant de la « boîte noire » qu'est notre DAO.
De même, il va falloir masquer le code responsable du stockage au code « extérieur », et l'exposer uniquement via des interfaces. Dans notre cas, il s'agira donc de faire en sorte que le code basé sur JDBC soit bien à l'abri dans des implémentations de DAO, et que nos objets métier n'aient connaissance que des interfaces qui les décrivent.
Reprenons le schéma précédent et zoomons sur la couche DAO (voir la figure suivante).
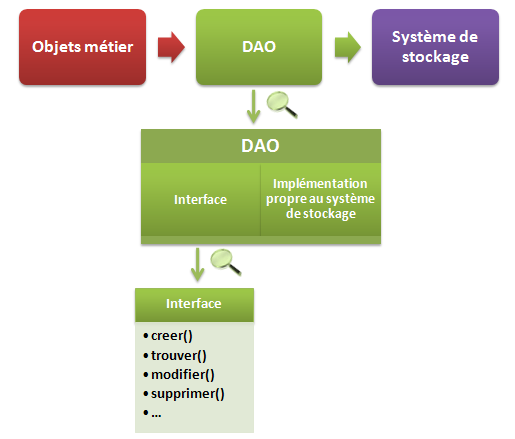
La couche modèle est constituée de la couche métier (en rouge) et de la couche données (en vert). La couche métier n'a connaissance que des interfaces décrivant les objets de la couche données. Ainsi, peu importe le système de stockage final utilisé, du point de vue du code métier les méthodes à appeler ne changent pas, elles seront toujours celles décrites dans l'interface. C'est uniquement l'implémentation qui sera spécifique au mode de stockage.
Intégration
Ne soyez pas leurrés par le schéma précédent, la couche DAO ne va pas seulement contenir les interfaces et implémentations des méthodes CRUD. Elle va également renfermer quelques classes dédiées à l'isolement des concepts liés au mode de stockage, comme les exceptions dont nous avons déjà brièvement parlé, mais également le chargement du driver et l'obtention d'une connexion. Pour ce faire, nous allons créer une Factory (une fabrique) qui sera unique dans l'application, ne sera instanciée que si les informations de configuration sont correctes et aura pour rôle de fournir les implémentations des différents DAO.
En ce qui concerne la relation entre la couche métier et le DAO, c'est très simple : les objets métier appellent les méthodes CRUD, qui ont pour rôle de communiquer avec le système de stockage et de peupler les beans représentant les données.
Assez gambergé, du code vaut mieux qu'un long discours !
Création
Pour commencer, nous allons laisser tomber le bac à sable dans lequel nous avons évolué dans le chapitre précédent, et allons reprendre les systèmes d'inscription et de connexion que nous avions utilisés jusqu'à présent. Je vous demande donc de supprimer de votre projet les classes GestionTestJDBC.java et TestJDBC.java ainsi que la JSP test_jdbc.jsp, car nous n'allons pas les réutiliser.
Modification de la table Utilisateur
En ce qui concerne la BDD, nous allons conserver la base de données bdd_sdzee et le compte java que nous y avons créé, mais allons modifier la table d'exemple Utilisateur. Plus précisément, nous allons modifier le type du champ mot_de_passe.
Pourquoi ? Qu'est-ce qui ne va pas avec le type utilisé dans notre bac à sable ?
Je ne vous en ai volontairement pas parlé jusqu'ici pour ne pas compliquer votre apprentissage de JDBC, mais maintenant que vous êtes à l'aise, discutons-en ! 
Dans l'exemple du chapitre précédent, j'ai choisi de déléguer le chiffrement du mot de passe de l'utilisateur à la fonction MD5() de MySQL afin de ne pas encombrer inutilement le code. Seulement c'est une mauvaise pratique, notamment parce que :
- d'une part, c'est une fonction propre à MySQL. Si vous optez pour un autre SGBD, voire pour un autre système de stockage, vous n'êtes pas certains de pouvoir lui trouver un équivalent ;
- d'autre part, et c'est là le point le plus important, c'est un algorithme rapide et peu sûr qu'il est déconseillé d'utiliser pour la sécurisation de mots de passe.
Je ne vais pas vous faire un cours de cryptographie, vous trouverez à ce sujet d'excellentes bases sur le Site du Zéro et plus largement sur le web. Sachez simplement que pour sécuriser de manière efficace les mots de passe de vos utilisateurs, il est préférable aujourd'hui :
- d'utiliser un algorithme de hashage relativement fort et lent. Typiquement, une des variantes de SHA-2 (SHA-224, SHA-256, SHA-384 ou SHA-512) est un excellent choix ;
- d'associer au mot de passe un « grain de sel » aléatoire et suffisamment long : 1) pour faire en sorte que deux mots de passe identiques aient une empreinte différente ; 2) afin d'empêcher un éventuel pirate d'utiliser des structures de données comme les fameuses rainbow tables pour déchiffrer rapidement une empreinte ;
- d'itérer récursivement la fonction de hashage un très grand nombre de fois, mais surtout pas uniquement sur l'empreinte résultant du hashage précédent afin de ne pas augmenter les risques de collisions, en veillant bien à réintroduire à chaque itération des données comme le sel et le mot de passe d'origine, avec pour objectif de rendre le travail d'un éventuel pirate autant de fois plus lent.
Bref, vous l'aurez compris, pour un débutant c'est presque mission impossible de protéger efficacement les mots de passe de ses utilisateurs ! Heureusement, il existe des solutions simplifiant grandement cette opération, et notre choix va se porter sur la bibliothèque Jasypt. En quelques mots, il s'agit d'une surcouche aux API de cryptographie existant nativement dans Java, qui fournit des objets et méthodes très faciles d'accès afin de chiffrer des données.
Très bien, mais en quoi cela va-t-il impacter le type de notre champ mot_de_passe dans notre table Utilisateur ?
Eh bien comme je vous l'ai dit, nous n'allons plus utiliser l'algorithme MD5, mais lui préférer cette fois SHA-256. Le premier générait des empreintes longues de 32 caractères, voilà pourquoi nous les stockions dans un champ SQL de taille 32. Le second génère des empreintes longues de 64 caractères, que Jasypt encode pour finir à l'aide de Base64 en chaînes longues de 56 caractères. Celles-ci ne vont donc pas rentrer dans le champ mot_de_passe que nous avions défini, et nous devons donc le modifier via la commande suivante à exécuter depuis l'invite de commandes de votre serveur MySQL :
1 | ALTER TABLE Utilisateur CHANGE mot_de_passe mot_de_passe CHAR(56) NOT NULL; |
Modification du type du champ mot_de_passe dans la table des utilisateurs
Bien entendu, avant d'effectuer cette modification, vous n'oublierez pas de vous positionner sur la bonne base en exécutant la commande USE bdd_sdzee; après connexion à votre serveur MySQL.
Reprise du bean Utilisateur
Nous disposons déjà d'un bean Utilisateur, sur lequel nous avons travaillé jusqu'à présent, mais celui-ci ne contient pour l'instant qu'une adresse mail, un nom et un mot de passe. Afin qu'il devienne utilisable pour effectuer la correspondance avec les données stockées dans notre table Utilisateur, il nous faut réaliser quelques ajouts :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 | package com.sdzee.beans; import java.sql.Timestamp; public class Utilisateur { private Long id; private String email; private String motDePasse; private String nom; private Timestamp dateInscription; public Long getId() { return id; } public void setId( Long id ) { this.id = id; } public void setEmail( String email ) { this.email = email; } public String getEmail() { return email; } public void setMotDePasse( String motDePasse ) { this.motDePasse = motDePasse; } public String getMotDePasse() { return motDePasse; } public void setNom( String nom ) { this.nom = nom; } public String getNom() { return nom; } public Timestamp getDateInscription() { return dateInscription; } public void setDateInscription( Timestamp dateInscription ) { this.dateInscription = dateInscription; } } |
com.sdzee.beans.Utilisateur
C'est simple, nous avons simplement créé deux nouvelles propriétés id et dateInscription stockant logiquement l'id et la date d'inscription, et nous disposons maintenant d'un bean qui représente parfaitement une ligne de notre table Utilisateur.
Pourquoi avoir utilisé un objet Long pour stocker l'id ?
En effet, nous aurions pu a priori nous contenter d'un type primitif long. Seulement dans une base de données les valeurs peuvent être initialisées à NULL, alors qu'un type primitif en Java ne peut pas valoir null. Voilà pourquoi il est déconseillé de travailler directement avec les types primitifs, et de leur préférer les objets « enveloppeurs » (les fameux Wrapper) : ceux-ci peuvent en effet être initialisés à null.
En l'occurrence, les champs de notre table SQL se voient tous appliquer une contrainte NOT NULL, il n'y a donc pas de risque de valeurs nulles. Cependant, c'est une bonne pratique de toujours utiliser les objets Wrapper dans les beans dont les propriétés correspondent à des champs d'une base de données, afin d'éviter ce genre d'erreurs !
Maintenant que nous avons créé les différentes représentations d'un utilisateur dans notre application, nous allons pouvoir nous attaquer au fameux cloisonnement de la couche de données, autrement dit à la création à proprement parler de notre DAO.
Création des exceptions du DAO
Afin de cacher la nature du mode de stockage des données au reste de l'application, c'est une bonne pratique de masquer les exceptions spécifiques (celles qui surviennent au runtime, c'est-à-dire lors de l'exécution) derrière des exceptions propres au DAO. Je m'explique. Typiquement, nous allons dans notre application avoir besoin de gérer deux types d'exceptions concernant les données :
- celles qui sont liées à la configuration du DAO et du driver JDBC ;
- celles qui sont liées à l'interaction avec la base de données.
Dans la couche modèle actuelle de notre système d'inscription, nous nous apprêtons à introduire le stockage des données. Puisque nous avons décidé de suivre le modèle de conception DAO, nous n'allons pas réaliser les manipulations sur la base de données directement depuis les traitements métier, nous allons appeler des méthodes de notre DAO, qui à leur tour la manipuleront. Nous obtiendrons ainsi un modèle divisé en deux sous-couches : une couche métier et une couche de données.
Seulement vous vous en doutez, lors d'une tentative de lecture ou d'écriture dans la base de données, il peut survenir de nombreux types d'incidents : des soucis de connexions, des requêtes incorrectes, des données absentes, la base qui ne répond plus, etc. Et à chacune de ces erreurs correspond une exception SQL ou JDBC particulière. Eh bien notre objectif ici, c'est de faire en sorte que depuis l'extérieur de la couche de données, aucune de ces exceptions ne sorte directement sous cette forme.
Pour ce faire, c'est extrêmement simple, il nous suffit de créer une exception personnalisée qui va encapsuler les exceptions liées à SQL ou JDBC. Voici donc le code de nos deux nouvelles exceptions :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | package com.sdzee.dao; public class DAOException extends RuntimeException { /* * Constructeurs */ public DAOException( String message ) { super( message ); } public DAOException( String message, Throwable cause ) { super( message, cause ); } public DAOException( Throwable cause ) { super( cause ); } } |
com.sdzee.dao.DAOException
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | package com.sdzee.dao; public class DAOConfigurationException extends RuntimeException { /* * Constructeurs */ public DAOConfigurationException( String message ) { super( message ); } public DAOConfigurationException( String message, Throwable cause ) { super( message, cause ); } public DAOConfigurationException( Throwable cause ) { super( cause ); } } |
com.sdzee.dao.DAOConfigurationException
Comme vous pouvez le constater, il s'agit uniquement de classes héritant de RuntimeException, qui se contentent de redéfinir les constructeurs. Ne vous inquiétez pas si vous ne saisissez pas encore bien pourquoi nous avons besoin de ces deux exceptions, vous allez très vite vous en rendre compte dans les codes qui suivent !
Création d'un fichier de configuration
Dans le chapitre précédent, nous avions directement stocké en dur l'adresse et les identifiants de connexion à notre base de données, dans le code Java de notre objet. C'était pratique pour l'exemple, mais vous vous doutez bien que nous n'allons pas procéder de manière aussi brute dans une vraie application.
Afin de séparer les informations de configuration du reste de l’application, il est recommandé de les placer dans un endroit accessible par le code Java et aisément modifiable à la main. Une bonne pratique très courante dans ce genre de cas est la mise en place d'un fichier properties, qui n'est rien d'autre qu'un fichier texte dont les lignes respectent un certain format.
Nous allons donc créer un fichier nommé dao.properties, que nous allons placer dans le package com.sdzee.dao :
1 2 3 4 | url = jdbc:mysql://localhost:3306/bdd_sdzee driver = com.mysql.jdbc.Driver nomutilisateur = java motdepasse = $dZ_£E |
dao.properties
Vous retrouvez dans ce fichier les informations de connexion à notre base. Chacune d'elles est associée à une clé, représentée par la chaîne de caractères placée à gauche du signe égal sur chacune des lignes.
Puisque ce fichier contient des informations confidentielles, comme le mot de passe de connexion à la base de données, il est hors de question de le placer dans un répertoire public de l'application ; il est impératif de le placer sous /WEB-INF ou un de ses sous-répertoires ! Si vous le mettiez par exemple directement à la racine, sous le répertoire WebContent d'Eclipse, alors ce fichier deviendrait accessible depuis le navigateur du client…
Dans une vraie application, les fichiers de configuration ne sont pas stockés au sein de l'application web, mais en dehors. Il devient ainsi très facile d'y modifier une valeur sans avoir à naviguer dans le contenu de l'application. En outre, mais nous étudierons cela en annexe de ce cours, cela permet de ne pas avoir besoin de redéployer l'application à chaque modification, et de se contenter de simplement redémarrer le serveur. Toutefois dans notre cas, nous n'en sommes qu'au stade de l'apprentissage et n'allons donc pas nous embêter avec ces considérations : placer le fichier sous /WEB-INF nous convient très bien !
Création d'une Factory
Nous arrivons maintenant à une étape un peu plus délicate de la mise en place de notre couche de données. Il nous faut créer la Factory qui va être en charge de l'instanciation des différents DAO de notre application. Alors certes, pour le moment nous n'avons qu'une seule table en base et donc un seul DAO à mettre en place. Mais rappelez-vous : l'important est de créer un code facile à maintenir et à faire évoluer. En outre, maintenant que nous avons placé nos informations de connexion dans un fichier à part, cette Factory va être responsable de :
- lire les informations de configuration depuis le fichier properties ;
- charger le driver JDBC du SGBD utilisé ;
- fournir une connexion à la base de données.
Je vous donne le code, relativement bref, et je vous commente le tout ensuite :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 | package com.sdzee.dao; import java.io.FileNotFoundException; import java.io.IOException; import java.io.InputStream; import java.sql.Connection; import java.sql.DriverManager; import java.sql.SQLException; import java.util.Properties; public class DAOFactory { private static final String FICHIER_PROPERTIES = "/com/sdzee/dao/dao.properties"; private static final String PROPERTY_URL = "url"; private static final String PROPERTY_DRIVER = "driver"; private static final String PROPERTY_NOM_UTILISATEUR = "nomutilisateur"; private static final String PROPERTY_MOT_DE_PASSE = "motdepasse"; private String url; private String username; private String password; DAOFactory( String url, String username, String password ) { this.url = url; this.username = username; this.password = password; } /* * Méthode chargée de récupérer les informations de connexion à la base de * données, charger le driver JDBC et retourner une instance de la Factory */ public static DAOFactory getInstance() throws DAOConfigurationException { Properties properties = new Properties(); String url; String driver; String nomUtilisateur; String motDePasse; ClassLoader classLoader = Thread.currentThread().getContextClassLoader(); InputStream fichierProperties = classLoader.getResourceAsStream( FICHIER_PROPERTIES ); if ( fichierProperties == null ) { throw new DAOConfigurationException( "Le fichier properties " + FICHIER_PROPERTIES + " est introuvable." ); } try { properties.load( fichierProperties ); url = properties.getProperty( PROPERTY_URL ); driver = properties.getProperty( PROPERTY_DRIVER ); nomUtilisateur = properties.getProperty( PROPERTY_NOM_UTILISATEUR ); motDePasse = properties.getProperty( PROPERTY_MOT_DE_PASSE ); } catch ( IOException e ) { throw new DAOConfigurationException( "Impossible de charger le fichier properties " + FICHIER_PROPERTIES, e ); } try { Class.forName( driver ); } catch ( ClassNotFoundException e ) { throw new DAOConfigurationException( "Le driver est introuvable dans le classpath.", e ); } DAOFactory instance = new DAOFactory( url, nomUtilisateur, motDePasse ); return instance; } /* Méthode chargée de fournir une connexion à la base de données */ /* package */ Connection getConnection() throws SQLException { return DriverManager.getConnection( url, username, password ); } /* * Méthodes de récupération de l'implémentation des différents DAO (un seul * pour le moment) */ public UtilisateurDao getUtilisateurDao() { return new UtilisateurDaoImpl( this ); } } |
com.sdzee.dao.DAOFactory
Pour commencer, analysons la méthode getInstance() qui, comme son nom l'indique, a pour principal objectif d'instancier la classe DAOFactory. En premier lieu, remarquez qu'il s'agit là d'une méthode statique. Il n'y a ici rien de compliqué, ça tient tout simplement du bon sens : si nous n'avions pas déclaré cette méthode static, alors nous ne pourrions pas l'appeler avant d'avoir instancié la classe DAOFactory… Alors que c'est justement là le but de la méthode !
Pourquoi avoir utilisé une telle méthode statique, et pas simplement un constructeur public ?
En effet, la plupart du temps lorsque vous souhaitez créer un objet, vous vous contentez d'appeler un de ses constructeurs publics. Typiquement, pour créer un objet de type A, vous écrivez A monObjet = new A(); . La limite de cette technique, c'est qu'à chaque appel un nouvel objet va être créé quoi qu'il arrive.
Dans notre cas, ce n'est pas ce que nous souhaitons ! Je vous l'ai déjà expliqué, nous voulons instancier notre DAOFactory uniquement sous certaines conditions :
- si le fichier dao.properties est accessible ;
- si les données qu'il contient sont valides ;
- si le driver JDBC est bien présent dans l'application.
Voilà pourquoi nous utilisons une méthode statique et pas un simple constructeur. Pour information, sachez que c'est une pratique courante dans énormément de projets et de bibliothèques. Voilà tout pour cet aparté, revenons à notre analyse du code.
À la ligne 34, nous initialisons un objet Properties qui, comme son nom l'indique, va nous permettre de gérer notre fichier de configuration. Ensuite, nous procédons à l'ouverture du fichier dao.properties aux lignes 40 et 41.
Qu'est-ce que c'est que cet objet ClassLoader et cette méthode getResourceAsStream() ? Pourquoi ne pas avoir utilisé un traditionnel FileInputStream pour ouvrir notre fichier properties ?
En effet, nous aurions pu confier cette tâche à un simple FileInputStream, seulement il nous aurait alors fallu :
- donner le chemin complet vers le fichier dans le système, pour procéder à l'ouverture du flux ;
- gérer une éventuelle
FileNotFoundExceptiondans un bloccatch, et procéder à la fermeture du flux dans un blocfinally.
En lieu et place de cette technique, j'utilise ici une méthode plus sophistiquée à première vue mais qui en réalité est très simple : elle consiste à appeler la méthode getResourceAsStream() de l'objet ClassLoader, qui se charge pour nous d'ouvrir le flux demandé et de retourner null en cas d'erreur. Comme vous pouvez l'observer dans le code, nous récupérons le ClassLoader depuis le thread courant grâce à la méthode getContextClassLoader().
Nous aurions pu écrire le tout en une ligne, mais la décomposition en deux actions distinctes vous permet de comprendre plus facilement de quoi il s'agit. Si vous n'êtes pas familiers avec les objets manipulés ici, qui font partie de la plate-forme Java SE, la Javadoc est là pour vous renseigner : n'hésitez pas à parcourir les liens que je vous donne !
Une fois l'appel à la méthode getResourceAsStream() réalisé, nous vérifions à la ligne 43 si elle a retourné null, ce qui signifierait alors que le flux n'a pas pu être ouvert. Si tel est le cas, nous envoyons une exception personnalisée DAOConfigurationException stipulant que le fichier n'a pas été trouvé.
Nous procédons ensuite au chargement des propriétés contenues dans le fichier à la ligne 48, puis à leur lecture aux lignes 49 à 52. Je vous laisse parcourir les documentations des méthodes Properties.load() et Properties.getProperty() si vous n'êtes pas à l'aise avec ces manipulations. Après tout, ceci n'est pas l'objet de ce cours et vous devriez déjà connaître cette fonctionnalité si vous avez correctement étudié Java SE !
Observez alors attentivement ce que nous effectuons au niveau du bloc catch : nous interceptons l'exception éventuellement envoyée en cas d'erreur lors du chargement des propriétés (format du fichier properties incorrect), et l'encapsulons dans une exception DAOConfigurationException. Vous devez ici commencer à mieux comprendre pourquoi nous avons pris la peine de créer des exceptions personnalisées, mais ne vous inquiétez pas si vous n'avez pas encore bien saisi, nous y reviendrons plus tard.
Une fois les informations lues avec succès, nous tentons de charger le driver JDBC dont le nom est précisé dans le fichier dao.properties, en l'occurrence dans notre cas il s'agit du driver pour MySQL. Le principe est le même que dans le chapitre précédent, nous effectuons un simple appel à Class.forName(). Là encore, observez l'encapsulation de l'exception envoyée en cas d'erreur (driver introuvable) dans une exception personnalisée de type DAOConfigurationException.
Pour en terminer avec cette méthode getInstance(), en cas de succès des étapes précédentes nous instancions la DAOFactory en faisant appel au constructeur défini aux lignes 23 à 27.
Nous créons ensuite la méthode getConnection() chargée de fournir une connexion à la base de données, aux lignes 68 à 70. Là encore pas de surprise, nous utilisons le même principe que dans le chapitre précédent, à savoir un appel à DriverManager.getConnection().
Par ailleurs, vous avez là un bel exemple de l'utilisation d'une méthode statique à la place d'un constructeur public. En effet, nous ne récupérons pas un objet de type Connection en appelant un constructeur public, mais en faisant appel à une méthode statique de l'objet DriverManager !
Enfin, nous devons écrire les getters retournant les différentes implémentations de DAO contenues dans notre application, ce qui, ne l'oublions pas est le rôle d'origine de notre DAOFactory. Comme je vous l'ai déjà précisé, pour le moment nous ne travaillons que sur une seule table et n'allons donc créer qu'un seul DAO ; voilà pourquoi nous n'avons qu'un seul getter à mettre en place, aux lignes 76 à 78.
Ne vous préoccupez pas du code de ce getter pour le moment, j'y reviendrai après vous avoir expliqué les interfaces et implémentations du DAO Utilisateur. De même, ne vous inquiétez pas si le code ne compile pas encore, il compilera lorsque nous aurons créé les classes mises en jeu !
Création de l'interface du DAO Utilisateur
Avant de créer une implémentation de notre DAO Utilisateur, il nous faut écrire le contrat qui va définir toutes les actions qui devront être effectuées sur les données, c'est-à-dire sur le bean Utilisateur. Qui dit contrat dit interface, et c'est donc une interface que nous allons mettre en place.
En ce qui concerne le nommage des classes et interfaces, il existe différentes bonnes pratiques. Pour ma part, je nomme AbcDao l'interface d'un DAO correspondant à la table Abc, et AbcDaoImpl son implémentation. Je vous conseille de suivre cette règle également, cela permet de s'y retrouver rapidement dans une application qui contient beaucoup de DAO différents ! Nous créons ici un DAO correspondant à la table Utilisateur, nous allons donc créer une interface nommée UtilisateurDao :
1 2 3 4 5 6 7 8 9 10 11 | package com.sdzee.dao; import com.sdzee.beans.Utilisateur; public interface UtilisateurDao { void creer( Utilisateur utilisateur ) throws DAOException; Utilisateur trouver( String email ) throws DAOException; } |
com.sdzee.dao.UtilisateurDao
Vous retrouvez ici les deux méthodes mises en jeu par nos formulaires d'inscription et de connexion :
- la création d'un utilisateur, lors de son inscription ;
- la recherche d'un utilisateur, lors de la connexion.
Ces méthodes font partie du fameux CRUD dont je vous ai parlé auparavant ! Notre système se limitant à ces deux fonctionnalités, nous n'allons volontairement pas implémenter les méthodes de mise à jour et de suppression d'un utilisateur. Dans une vraie application toutefois, il va de soi que l'interface de chaque DAO se doit d'être complète.
Petite information au passage : en Java, les méthodes d'une interface sont obligatoirement publiques et abstraites, inutile donc de préciser les mots-clés public et abstract dans leurs signatures. L'écriture reste permise, mais elle est déconseillée dans les spécifications Java SE publiées par Oracle, dans le chapitre concernant les interfaces.
Création de l'implémentation du DAO
Nous voilà arrivés à l'étape finale : la création de l'implémentation de notre DAO Utilisateur. Il s'agit de la classe qui va manipuler la table Utilisateur de notre base de données. C'est donc elle qui va contenir le code des méthodes creer() et trouver() définies dans le contrat que nous venons tout juste de mettre en place.
La première chose à faire, c'est de créer une classe qui implémente l'interface UtilisateurDao. Nous allons bien entendu suivre la convention de nommage que nous avons adoptée, et nommer cette implémentation UtilisateurDaoImpl :
1 2 3 4 5 6 7 8 9 10 11 12 | public class UtilisateurDaoImpl implements UtilisateurDao { /* Implémentation de la méthode trouver() définie dans l'interface UtilisateurDao */ @Override public Utilisateur trouver( String email ) throws DAOException { return null; } /* Implémentation de la méthode creer() définie dans l'interface UtilisateurDao */ @Override public void creer( Utilisateur utilisateur ) throws IllegalArgumentException, DAOException { } } |
com.sdzee.dao.UtilisateurDaoImpl
Vous le savez très bien, en Java lorsqu'une classe implémente une interface, elle doit impérativement définir toutes les méthodes qui y sont décrites. En l'occurrence notre interface UtilisateurDao contient deux méthodes creer() et trouver(), voilà pourquoi nous devons écrire leur code dans notre implémentation.
Nous devons maintenant réfléchir un peu. Dans l'architecture que nous sommes en train de construire, nous avons mis en place une Factory. En plus d'assurer sa fonction principale, c'est-à-dire créer le DAO via le getter getUtilisateurDao(), elle joue le rôle de pierre angulaire : c'est par son intermédiaire que le DAO va pouvoir acquérir une connexion à la base de données, en appelant sa méthode getConnection().
Pour pouvoir appeler cette méthode et ainsi récupérer une connexion, le DAO doit donc avoir accès à une instance de la DAOFactory. Comment faire ?
C'est simple, nous avons déjà préparé le terrain à la ligne 77 du code de notre DAOFactory ! Si vous regardez bien, nous passons une instance de la classe (via le mot-clé this) à l'implémentation du DAO lors de sa construction. Ainsi, il nous suffit de créer un constructeur qui prend en argument un objet de type DAOFactory dans notre DAO :
1 2 3 4 5 6 7 8 9 | public class UtilisateurDaoImpl implements UtilisateurDao { private DAOFactory daoFactory; UtilisateurDaoImpl( DAOFactory daoFactory ) { this.daoFactory = daoFactory; } ... } |
com.sdzee.dao.UtilisateurDaoImpl
Jusque-là, rien de bien compliqué. Mais ne vous endormez surtout pas, le gros du travail reste à faire ! Nous devons maintenant écrire le code des méthodes creer() et trouver(), autrement dit le code à travers lequel nous allons communiquer avec notre base de données ! Vous connaissez déjà le principe : connexion, requête préparée, etc. !
Plutôt que d'écrire bêtement du code à la chaîne en recopiant et adaptant ce que nous avions écrit dans le chapitre précédent, nous allons étudier les besoins de nos méthodes et réfléchir à ce qu'il est possible de factoriser dans des méthodes utilitaires. Mieux encore, nous n'allons pas nous concentrer sur ces deux méthodes en particulier, mais réfléchir plus globalement à ce que toute méthode communiquant avec une base de données doit faire intervenir. Nous pouvons d'ores et déjà noter :
- initialiser une requête préparée avec des paramètres ;
- récupérer une ligne d'une table et enregistrer son contenu dans un bean ;
- fermer proprement les ressources ouvertes (
Connection,PreparedStatement,ResultSet).
Pour accomplir ces différentes tâches, a priori nous allons avoir besoin de trois méthodes utilitaires :
- une qui récupère une liste de paramètres et les ajoute à une requête préparée donnée ;
- une qui récupère un
ResultSetet enregistre ses données dans un bean ; - une qui ferme toutes les ressources ouvertes.
Étudions tout cela étape par étape.
1. Initialisation d'une requête préparée
Nous avons besoin d'une méthode qui va prendre en argument une connexion, une requête SQL et une liste d'objets, et s'en servir pour initialiser une requête préparée via un appel à connexion.prepareStatement(). À ce propos, rappelez-vous de ce que nous avons découvert dans le chapitre précédent : c'est lors de cet appel qu'il faut préciser si la requête doit retourner un champ auto-généré ou non ! Le problème, c'est que nous ne pouvons pas savoir à l'avance si notre requête a besoin de retourner cette information ou non. Voilà pourquoi nous allons ajouter un quatrième argument à notre méthode, dont voici le code complet :
1 2 3 4 5 6 7 8 9 10 11 | /* * Initialise la requête préparée basée sur la connexion passée en argument, * avec la requête SQL et les objets donnés. */ public static PreparedStatement initialisationRequetePreparee( Connection connexion, String sql, boolean returnGeneratedKeys, Object... objets ) throws SQLException { PreparedStatement preparedStatement = connexion.prepareStatement( sql, returnGeneratedKeys ? Statement.RETURN_GENERATED_KEYS : Statement.NO_GENERATED_KEYS ); for ( int i = 0; i < objets.length; i++ ) { preparedStatement.setObject( i + 1, objets[i] ); } return preparedStatement; } |
Observez les quatre arguments passés à la méthode :
- la connexion, dont nous avons besoin pour appeler la méthode
connexion.prepareStatement(); - la requête SQL, que nous passons en argument lors de l'appel pour construire l'objet
PreparedStatement; - un booléen, indiquant s'il faut ou non retourner d'éventuelles valeurs auto-générées. Nous l'utilisons alors directement au sein de l'appel à
connexion.prepareStatement()grâce à une simple expression ternaire ; - une succession d'objets… de tailles variables ! Eh oui, là encore nous n'avons aucun moyen d'anticiper et de savoir à l'avance combien de paramètres attend notre requête préparée.
Que signifient ces '…' dans le type du dernier argument de la méthode ?
C'est une notation purement Java, dite varargs. Vous pouvez la voir comme un joker : en déclarant ainsi votre méthode, vous pourrez ensuite l'appeler avec autant de paramètres que vous voulez (tant qu'ils respectent le type déclaré), et l'appel fonctionnera toujours ! La seule différence sera la taille de l'objet passé en tant que quatrième et dernier argument ici. Exemples :
1 2 3 4 | initialisationRequetePreparee( connexion, requeteSQL, true, email); initialisationRequetePreparee( connexion, requeteSQL, true, email, motDePasse ); initialisationRequetePreparee( connexion, requeteSQL, true, email, motDePasse, nom ); initialisationRequetePreparee( connexion, requeteSQL, true, email, motDePasse, nom, dateInscription ); |
Exemples d'appels avec un nombre variable d'arguments
Bien qu'ils ne présentent pas tous le même nombre d'arguments, tous ces appels font bien référence à une seule et même méthode : celle que nous avons précédemment définie, et dont la signature ne mentionne que quatre arguments ! En réalité sous la couverture, le compilateur regroupera lui-même tous les arguments supplémentaires dans un simple tableau. En fin de compte, cette notation varargs s'apparente en quelque sorte à un tableau implicite.
Dans ce cas, pourquoi ne pas utiliser directement un tableau, en déclarant à la place de Object... un argument de type Object[] ?
Tout simplement parce que cela compliquerait l'utilisation de la méthode. En effet, si nous devions absolument passer un objet de type tableau, alors il faudrait prendre la peine d’initialiser un tableau avant d'appeler la méthode. Nos exemples précédents deviendraient alors :
1 2 3 4 5 6 7 8 | Object[] objets = { email }; initialisationRequetePreparee( connexion, requeteSQL, true, objets); objets = { email, motDePasse }; initialisationRequetePreparee( connexion, requeteSQL, true, objets); objets = { email, motDePasse, nom }; initialisationRequetePreparee( connexion, requeteSQL, true, objets); objets = { email, motDePasse, nom, dateInscription }; initialisationRequetePreparee( connexion, requeteSQL, true, objets); |
Exemples d'appels avec un tableau
Observez la différence avec l'exemple précédent : les appels à la méthode sont, cette fois, tous identiques, mais le fait de devoir initialiser des tableaux avant chaque appel est pénible et complique la lecture du code.
Au sujet de la nature de ce tableau implicite, pourquoi le déclarer de type Object ?
Eh bien parce que là encore, nous n'avons aucun moyen d'anticiper et de déterminer à l'avance ce que notre requête attend en guise de paramètres ! Voilà pourquoi nous devons utiliser le type le plus global possible, à savoir Object.
D'ailleurs, en conséquence nous n'allons pas pouvoir faire appel aux méthodes preparedStatement.setString(), preparedStatement.setInt(), etc. que nous avions découvertes et utilisées dans le chapitre précédent, puisque nous n'aurons ici aucun moyen simple de savoir de quel type est chaque objet. Heureusement, il existe une méthode preparedStatement.setObject() qui prend en argument un objet de type Object, et qui s'occupe ensuite derrière les rideaux d'effectuer la conversion vers le type SQL du paramètre attendu avant d'envoyer la requête à la base de données. Sympathique, n'est-ce pas ?
Nous y voilà : ce grand aparté sur les varargs vous donne toutes les clés pour comprendre ce qui se passe dans la boucle for qui conclut notre méthode. Nous y parcourons le tableau implicite des arguments passés à la méthode lors de son appel, et plaçons chacun d'eux dans la requête préparée via un appel à la méthode preparedStatement.setObject().
En fin de compte, c'est ici une méthode courte que nous avons réalisée, mais qui fait intervenir des concepts intéressants et qui va nous être très utile par la suite. Par ailleurs, notez qu'il s'agit d'une méthode purement utilitaire, que nous pourrons réutiliser telle quelle dans n'importe quel DAO !
2. Mapping d'un ResultSet dans un bean
Abordons maintenant notre seconde méthode utilitaire, qui va nous permettre de faire la correspondance entre une ligne d'un ResultSet et un bean. Contrairement à notre précédente méthode, nous n'allons cette fois pas pouvoir totalement découpler la méthode de notre DAO en particulier, puisque nous travaillons directement sur un ResultSet issu de notre table d'utilisateurs et sur un bean de type Utilisateur. Voici le code :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | /* * Simple méthode utilitaire permettant de faire la correspondance (le * mapping) entre une ligne issue de la table des utilisateurs (un * ResultSet) et un bean Utilisateur. */ private static Utilisateur map( ResultSet resultSet ) throws SQLException { Utilisateur utilisateur = new Utilisateur(); utilisateur.setId( resultSet.getLong( "id" ) ); utilisateur.setEmail( resultSet.getString( "email" ) ); utilisateur.setMotDePasse( resultSet.getString( "mot_de_passe" ) ); utilisateur.setNom( resultSet.getString( "nom" ) ); utilisateur.setDateInscription( resultSet.getTimestamp( "date_inscription" ) ); return utilisateur; } |
Rien de bien compliqué ici : notre méthode prend en argument un ResultSet dont le curseur a déjà été correctement positionné, et place chaque champ lu dans la propriété correspondante du nouveau bean créé.
3. Fermeture des ressources
Pour terminer, nous allons gérer proprement la fermeture des différentes ressources qui peuvent intervenir dans une communication avec la base de données. Plutôt que de tout mettre dans une seule et même méthode, nous allons écrire une méthode pour fermer chaque type de ressource :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 | /* Fermeture silencieuse du resultset */ public static void fermetureSilencieuse( ResultSet resultSet ) { if ( resultSet != null ) { try { resultSet.close(); } catch ( SQLException e ) { System.out.println( "Échec de la fermeture du ResultSet : " + e.getMessage() ); } } } /* Fermeture silencieuse du statement */ public static void fermetureSilencieuse( Statement statement ) { if ( statement != null ) { try { statement.close(); } catch ( SQLException e ) { System.out.println( "Échec de la fermeture du Statement : " + e.getMessage() ); } } } /* Fermeture silencieuse de la connexion */ public static void fermetureSilencieuse( Connection connexion ) { if ( connexion != null ) { try { connexion.close(); } catch ( SQLException e ) { System.out.println( "Échec de la fermeture de la connexion : " + e.getMessage() ); } } } /* Fermetures silencieuses du statement et de la connexion */ public static void fermeturesSilencieuses( Statement statement, Connection connexion ) { fermetureSilencieuse( statement ); fermetureSilencieuse( connexion ); } /* Fermetures silencieuses du resultset, du statement et de la connexion */ public static void fermeturesSilencieuses( ResultSet resultSet, Statement statement, Connection connexion ) { fermetureSilencieuse( resultSet ); fermetureSilencieuse( statement ); fermetureSilencieuse( connexion ); } |
Vous connaissez déjà le principe des trois premières méthodes, puisque nous avons effectué sensiblement la même chose dans le chapitre précédent. Nous créons ensuite deux méthodes qui font appel à tout ou partie des trois premières, tout bonnement parce que certaines requêtes font intervenir un ResultSet, d'autres non ! En outre, notez que tout comme la méthode initialisationRequetePreparee(), ces méthodes sont purement utilitaires et nous pouvons les réutiliser dans n'importe quel DAO.
4. Récapitulons
Les méthodes purement utilitaires peuvent être placées dans une classe à part entière, une classe utilitaire donc, et être utilisées depuis n'importe quel DAO. Voilà pourquoi j'ai donc créé une classe finale que j'ai nommée DAOUtilitaire et placée dans le package com.sdzee.dao. Vous pouvez la mettre en place vous-mêmes, ou bien la télécharger en cliquant sur ce lien et l'ajouter à votre projet.
En ce qui concerne la méthode map(), celle-ci doit simplement être placée dans la classe UtilisateurDaoImpl.
La méthode trouver()
Maintenant que nos méthodes utilitaires sont prêtes, nous pouvons finalement écrire le code de la méthode trouver() :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | private static final String SQL_SELECT_PAR_EMAIL = "SELECT id, email, nom, mot_de_passe, date_inscription FROM Utilisateur WHERE email = ?"; /* Implémentation de la méthode définie dans l'interface UtilisateurDao */ @Override private Utilisateur trouver( String email ) throws DAOException { Connection connexion = null; PreparedStatement preparedStatement = null; ResultSet resultSet = null; Utilisateur utilisateur = null; try { /* Récupération d'une connexion depuis la Factory */ connexion = daoFactory.getConnection(); preparedStatement = initialisationRequetePreparee( connexion, SQL_SELECT_PAR_EMAIL, false, email ); resultSet = preparedStatement.executeQuery(); /* Parcours de la ligne de données de l'éventuel ResulSet retourné */ if ( resultSet.next() ) { utilisateur = map( resultSet ); } } catch ( SQLException e ) { throw new DAOException( e ); } finally { fermeturesSilencieuses( resultSet, preparedStatement, connexion ); } return utilisateur; } |
com.sdzee.dao.UtilisateurDaoImpl
Vous retrouvez ici les principes découverts et appliqués dans le chapitre précédent : l'obtention d'une connexion, la préparation d'une requête de lecture, son exécution, puis la récupération et l'analyse du ResultSet retourné, et enfin la fermeture des ressources mises en jeu.
Les trois lignes surlignées font intervenir chacune des méthodes utilitaires que nous avons développées. À ce propos, vous n'oublierez pas d'importer le contenu de la classe DAOUtilitaire afin de rendre disponibles ses méthodes ! Pour ce faire, il vous suffit d'ajouter la ligne suivante dans les imports de votre classe UtilisateurDaoImpl :
1 | import static com.sdzee.dao.DAOUtilitaire.*; |
Import des méthodes utilitaires
En précisant directement dans l'import le mot-clé static, vous pourrez appeler vos méthodes comme si elles faisaient directement partie de votre classe courante. Par exemple, vous n'aurez pas besoin d'écrire DAOUtilitaire.fermeturesSilencieuses( ... ), mais simplement fermeturesSilencieuses( ... ). Pratique, n'est-ce pas ?
En outre, vous retrouvez également dans ce code la bonne pratique que je vous ai enseignée en début de cours, à savoir la mise en place d'une constante. Elle détient en l'occurrence l'instruction SQL utilisée pour préparer notre requête.
La méthode creer()
Dernière pierre à notre édifice, nous devons écrire le code de la méthode creer() :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | private static final String SQL_INSERT = "INSERT INTO Utilisateur (email, mot_de_passe, nom, date_inscription) VALUES (?, ?, ?, NOW())"; /* Implémentation de la méthode définie dans l'interface UtilisateurDao */ @Override public void creer( Utilisateur utilisateur ) throws DAOException { Connection connexion = null; PreparedStatement preparedStatement = null; ResultSet valeursAutoGenerees = null; try { /* Récupération d'une connexion depuis la Factory */ connexion = daoFactory.getConnection(); preparedStatement = initialisationRequetePreparee( connexion, SQL_INSERT, true, utilisateur.getEmail(), utilisateur.getMotDePasse(), utilisateur.getNom() ); int statut = preparedStatement.executeUpdate(); /* Analyse du statut retourné par la requête d'insertion */ if ( statut == 0 ) { throw new DAOException( "Échec de la création de l'utilisateur, aucune ligne ajoutée dans la table." ); } /* Récupération de l'id auto-généré par la requête d'insertion */ valeursAutoGenerees = preparedStatement.getGeneratedKeys(); if ( valeursAutoGenerees.next() ) { /* Puis initialisation de la propriété id du bean Utilisateur avec sa valeur */ utilisateur.setId( valeursAutoGenerees.getLong( 1 ) ); } else { throw new DAOException( "Échec de la création de l'utilisateur en base, aucun ID auto-généré retourné." ); } } catch ( SQLException e ) { throw new DAOException( e ); } finally { fermeturesSilencieuses( valeursAutoGenerees, preparedStatement, connexion ); } } |
com.sdzee.dao.UtilisateurDaoImpl
Là encore, vous retrouvez les principes découverts jusqu'à présent : l'obtention d'une connexion, la préparation d'une requête d'insertion avec demande de renvoi de l'id auto-généré grâce au booléen à true passé à notre méthode utilitaire DAOUtilitaire.initialisationRequetePreparee(), son exécution et la récupération de son statut, la récupération de l'id auto-généré via l'appel à la méthode preparedStatement.getGeneratedKeys(), et enfin la fermeture des ressources mises en jeu.
Dans ces deux méthodes, vous observerez bien l'utilisation de l'exception personnalisée DAOException que nous avons créée auparavant. Si vous avez encore un peu de mal à voir où nous voulons en venir avec nos exceptions, ne vous inquiétez pas : vous allez comprendre dans la suite de ce chapitre !
Intégration
Nous allons maintenant tâcher d'intégrer proprement cette nouvelle couche dans notre application. Pour l'exemple, nous allons travailler avec notre système d'inscription et laisser de côté le système de connexion pour le moment.
Chargement de la DAOFactory
Notre DAOFactory est un objet que nous ne souhaitons instancier qu'une seule fois, le démarrage de l'application semble donc l'instant approprié pour procéder à son initialisation.
Dans une application Java classique, il nous suffirait de placer quelques lignes de code en tête de la méthode main(), et le tour serait joué. Mais dans une application Java EE, comment faire ?
La solution, c'est l'interface ServletContextListener. Lisez sa très courte documentation, vous observerez qu'elle fournit une méthode contextInitialized() qui est appelée dès le démarrage de l'application, avant le chargement des servlets et filtres du projet. Il s'agit exactement de ce dont nous avons besoin !
Création du Listener
Nous allons donc mettre en place un nouveau package com.sdzee.config et y créer une classe nommée InitialisationDaoFactory qui implémente l'interface ServletContextListener :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | package com.sdzee.config; import javax.servlet.ServletContext; import javax.servlet.ServletContextEvent; import javax.servlet.ServletContextListener; import com.sdzee.dao.DAOFactory; public class InitialisationDaoFactory implements ServletContextListener { private static final String ATT_DAO_FACTORY = "daofactory"; private DAOFactory daoFactory; @Override public void contextInitialized( ServletContextEvent event ) { /* Récupération du ServletContext lors du chargement de l'application */ ServletContext servletContext = event.getServletContext(); /* Instanciation de notre DAOFactory */ this.daoFactory = DAOFactory.getInstance(); /* Enregistrement dans un attribut ayant pour portée toute l'application */ servletContext.setAttribute( ATT_DAO_FACTORY, this.daoFactory ); } @Override public void contextDestroyed( ServletContextEvent event ) { /* Rien à réaliser lors de la fermeture de l'application... */ } } |
com.sdzee.config.InitialisationDaoFactory
Comme d'habitude en Java, puisque nous implémentons une interface nous devons définir toutes ses méthodes, en l'occurrence elle en contient deux : une qui est lancée au démarrage de l'application, et une autre à sa fermeture. Vous l'aurez deviné, seule la méthode appelée lors du démarrage nous intéresse ici.
Le code est très simple et très court, comme vous pouvez l'observer. Si vous avez été très assidus, vous devez vous souvenir que le ServletContext n'est rien d'autre que l'objet qui agit dans les coulisses de l'objet implicite application ! Sachant cela, vous devez maintenant comprendre sans problème ce que nous faisons ici :
- nous récupérons le
ServletContextà la ligne 16 ; - nous obtenons une instance de notre DAOFactory via un appel à sa méthode statique
DAOFactory.getInstance(); - nous plaçons cette instance dans un attribut du
ServletContextvia sa méthodesetAttribute(), qui a donc pour portée l'application entière !
Il faut être très prudent lors de la manipulation d'objets de portée application. En effet, puisque de tels objets sont partagés par tous les composants durant toute la durée de vie de l'application, il est recommandé de les utiliser uniquement en lecture seule. Autrement dit, il est recommandé de les initialiser au démarrage de l'application et de ne plus jamais les modifier ensuite - que ce soit depuis une servlet, un filtre ou une JSP - afin d'éviter les modifications concurrentes et les problèmes de cohérence que cela pourrait impliquer. Dans notre cas, il n'y a aucun risque : notre objet est bien créé dès le démarrage de l'application, et il sera ensuite uniquement lu.
Configuration du Listener
Pour que notre Listener fraîchement créé soit pris en compte lors du démarrage de notre application, il nous faut ajouter une section au fichier web.xml :
1 2 3 | <listener> <listener-class>com.sdzee.config.InitialisationDaoFactory</listener-class> </listener> |
/WEB-INF/web.xml
Voilà tout ce qu'il est nécessaire d'écrire. N'oubliez pas de redémarrer Tomcat pour que la modification soit prise en compte !
Utilisation depuis la servlet
Notre DAOFactory étant prête à l'emploi dans notre projet, nous pouvons maintenant récupérer une instance de notre DAO Utilisateur depuis notre servlet d'inscription.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 | package com.sdzee.servlets; import java.io.IOException; import javax.servlet.ServletException; import javax.servlet.http.HttpServlet; import javax.servlet.http.HttpServletRequest; import javax.servlet.http.HttpServletResponse; import com.sdzee.beans.Utilisateur; import com.sdzee.dao.DAOFactory; import com.sdzee.dao.UtilisateurDao; import com.sdzee.forms.InscriptionForm; public class Inscription extends HttpServlet { public static final String CONF_DAO_FACTORY = "daofactory"; public static final String ATT_USER = "utilisateur"; public static final String ATT_FORM = "form"; public static final String VUE = "/WEB-INF/inscription.jsp"; private UtilisateurDao utilisateurDao; public void init() throws ServletException { /* Récupération d'une instance de notre DAO Utilisateur */ this.utilisateurDao = ( (DAOFactory) getServletContext().getAttribute( CONF_DAO_FACTORY ) ).getUtilisateurDao(); } public void doGet( HttpServletRequest request, HttpServletResponse response ) throws ServletException, IOException { /* Affichage de la page d'inscription */ this.getServletContext().getRequestDispatcher( VUE ).forward( request, response ); } public void doPost( HttpServletRequest request, HttpServletResponse response ) throws ServletException, IOException { /* Préparation de l'objet formulaire */ InscriptionForm form = new InscriptionForm( utilisateurDao ); /* Traitement de la requête et récupération du bean en résultant */ Utilisateur utilisateur = form.inscrireUtilisateur( request ); /* Stockage du formulaire et du bean dans l'objet request */ request.setAttribute( ATT_FORM, form ); request.setAttribute( ATT_USER, utilisateur ); this.getServletContext().getRequestDispatcher( VUE ).forward( request, response ); } } |
com.sdzee.servlets.Inscription
La première étape consiste à récupérer une instance de notre DAOFactory. Puisque nous en avons placé une dans un attribut de portée application lors de son chargement, il nous suffit depuis notre servlet de récupérer le ServletContext et d'appeler sa méthode getAttribute(). En réalité, le principe est exactement le même que pour un attribut de requête ou de session, seul l'objet de référence change.
Cette méthode retournant un objet de type Object, nous devons ensuite effectuer un cast vers le type DAOFactory pour pouvoir appeler sa méthode getUtilisateurDao(). Nous enregistrons finalement l'instance de notre DAO Utilisateur dans un attribut de notre servlet.
Quelle est cette méthode nommée init() ?
Cette méthode fait partie de celles que je ne vous avais volontairement pas expliquées lorsque je vous ai présenté les servlets. Je vous avais d'ailleurs précisé alors, que vous n'étiez pas encore assez à l'aise avec le concept de servlet lui-même, pour avoir besoin d'intervenir sur son cycle de vie. Le temps est venu pour vous d'en savoir un petit peu plus.
Pour rappel, une servlet n'est créée qu'une seule et unique fois par le conteneur, lors du démarrage de l'application ou bien lors de son premier accès (ceci dépendant de la présence ou non d'une section <load-on-startup> dans la déclaration de la servlet au sein du fichier web.xml). Eh bien sachez que lorsque la servlet est instanciée, cette fameuse méthode init() va être appelée, une seule et unique fois donc. Ainsi, vous avez la possibilité à travers cette méthode d'effectuer des tâches uniques, qui ne sont pas destinées à être lancées à chaque appel aux méthodes doGet() ou doPost() par exemple.
Pourquoi créer notre instance de DAO depuis cette méthode init() ?
Eh bien tout simplement parce que si nous en créions une depuis nos méthodes doXXX(), une nouvelle instance serait créée à chaque requête reçue ! En l'occurrence, ce n'est pas nécessaire puisque notre DAO est bien écrit : il manipule les ressources dont il a besoin au plus près de la requête SQL à effectuer, et les ferme correctement de la même manière.
Par contre, notre DAO pourrait très bien être construit d'une manière différente et nécessiter alors une nouvelle instance à chaque utilisation. Par exemple, imaginez que notre DAO partage une seule et même connexion à la base de données pour l'ensemble de ses méthodes CRUD. Eh bien dans ce cas, il serait impensable de ne créer qu'une seule instance du DAO et de la partager à tous les clients qui enverraient des requêtes vers la servlet, car cela reviendrait à partager une seule connexion à la BDD pour tous les clients ! 
Ce type de problématiques porte un nom : il s'agit de la thread-safety. En quelques mots, il s'agit de la possibilité ou non de partager des ressources à l'ensemble des threads intervenant sur un objet ou une classe. C'est un concept particulièrement important dans le cas d'une application web, parce qu'il y a bien souvent un nombre conséquent de clients utilisant une seule et même application centralisée.
Qu'est-ce qu'un attribut de servlet a de particulier face à un attribut déclaré au sein d'une méthode doXXX() ?
La différence est majeure : un attribut de servlet est partagé par tous les threads utilisant l'instance de la servlet, autrement dit par tous les clients qui y font appel ! Alors qu'un simple attribut déclaré par exemple dans une méthode doGet() n'existe que pour un seul thread, et se matérialise ainsi par un objet différent d'un thread à l'autre.
Voilà pourquoi dans notre cas, nous enregistrons notre instance de DAO dans un attribut de servlet : il peut tout à fait être partagé par l'ensemble des clients faisant appel à la servlet, puisque je vous le rappelle il est correctement écrit et gère proprement les ressources. L'intérêt est avant tout d'économiser les ressources du serveur : ré-instancier un nouveau DAO à chaque requête reçue serait un beau gâchis en termes de mémoire et de performances !
Bref, vous comprenez maintenant mieux pourquoi je n'ai pas souhaité vous présenter le cycle de vie d'une servlet trop tôt. Il implique des mécanismes qui ne sont pas triviaux, et il est nécessaire de bien comprendre le contexte d'utilisation d'une servlet avant d'intervenir sur son cycle de vie. Là encore, je ne vous dis pas tout et me limite volontairement à cette méthode init(). Ne vous inquiétez pas, le reste du mystère sera levé en annexe !
Pour finir, il faut transmettre notre instance DAO Utilisateur à l'objet métier InscriptionForm. Eh oui, c'est bien lui qui va gérer l'inscription d'un utilisateur, et c'est donc bien lui qui va en avoir besoin pour communiquer avec la base de données ! Nous lui passons ici à la ligne 35 par l'intermédiaire de son constructeur, qu'il va donc nous falloir modifier par la suite pour que notre code compile…
Reprise de l'objet métier
Comme je viens de vous le dire, la première étape consiste ici à modifier le constructeur de l'objet InscriptionForm pour qu'il prenne en compte le DAO transmis. En l'occurrence, nous n'avions jusqu'à présent créé aucun constructeur, et nous étions contentés de celui par défaut. Nous allons donc devoir ajouter le constructeur suivant, ainsi que la variable d'instance associée permettant de stocker le DAO passé en argument :
1 2 3 4 5 | private UtilisateurDao utilisateurDao; public InscriptionForm( UtilisateurDao utilisateurDao ) { this.utilisateurDao = utilisateurDao; } |
com.sdzee.forms.InscriptionForm
Le DAO étant maintenant disponible au sein de notre objet, nous allons pouvoir l'utiliser dans notre méthode d'inscription pour appeler la méthode creer() définie dans l'interface UtilisateurDao. Il faudra alors bien penser à intercepter une éventuelle DAOException envoyée par le DAO, et agir en conséquence !
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | public Utilisateur inscrireUtilisateur( HttpServletRequest request ) { String email = getValeurChamp( request, CHAMP_EMAIL ); String motDePasse = getValeurChamp( request, CHAMP_PASS ); String confirmation = getValeurChamp( request, CHAMP_CONF ); String nom = getValeurChamp( request, CHAMP_NOM ); Utilisateur utilisateur = new Utilisateur(); try { traiterEmail( email, utilisateur ); traiterMotsDePasse( motDePasse, confirmation, utilisateur ); traiterNom( nom, utilisateur ); if ( erreurs.isEmpty() ) { utilisateurDao.creer( utilisateur ); resultat = "Succès de l'inscription."; } else { resultat = "Échec de l'inscription."; } } catch ( DAOException e ) { resultat = "Échec de l'inscription : une erreur imprévue est survenue, merci de réessayer dans quelques instants."; e.printStackTrace(); } return utilisateur; } |
com.sdzee.forms.InscriptionForm
Vous pouvez observer plusieurs choses ici :
- j'appelle la méthode
utilisateurDao.creer()à la ligne 14, uniquement si aucune erreur de validation n'a eu lieu. En effet, inutile d'aller faire une requête sur la BDD si les critères de validation des champs du formulaire n'ont pas été respectés ; - il est alors nécessaire de mettre en place un
try/catchpour gérer une éventuelle DAOException retournée par cet appel ! En l'occurrence, j'initialise la chaîne resultat avec un message d'échec ; - enfin, j'ai regroupé le travail de validation des paramètres et d'initialisation des propriétés du bean dans des méthodes
traiterXXX(). Cela me permet d'aérer le code, qui commençait à devenir sérieusement chargé avec tout cet enchevêtrement de blocstry/catch, sans oublier les ajouts que nous devons y apporter !
Quels ajouts ? Qu'est-il nécessaire de modifier dans nos méthodes de validation ?
La gestion de l'adresse mail doit subir quelques modifications, car nous savons dorénavant qu'une adresse doit être unique en base, et le mot de passe doit absolument être chiffré avant d'être envoyé en base. En plus de cela, nous allons mettre en place une exception personnalisée pour la validation des champs afin de rendre notre code plus clair. Voici donc le code des méthodes gérant ces fonctionnalités :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 | private static final String ALGO_CHIFFREMENT = "SHA-256"; ... /* * Appel à la validation de l'adresse email reçue et initialisation de la * propriété email du bean */ private void traiterEmail( String email, Utilisateur utilisateur ) { try { validationEmail( email ); } catch ( FormValidationException e ) { setErreur( CHAMP_EMAIL, e.getMessage() ); } utilisateur.setEmail( email ); } /* * Appel à la validation des mots de passe reçus, chiffrement du mot de * passe et initialisation de la propriété motDePasse du bean */ private void traiterMotsDePasse( String motDePasse, String confirmation, Utilisateur utilisateur ) { try { validationMotsDePasse( motDePasse, confirmation ); } catch ( FormValidationException e ) { setErreur( CHAMP_PASS, e.getMessage() ); setErreur( CHAMP_CONF, null ); } /* * Utilisation de la bibliothèque Jasypt pour chiffrer le mot de passe * efficacement. * * L'algorithme SHA-256 est ici utilisé, avec par défaut un salage * aléatoire et un grand nombre d'itérations de la fonction de hashage. * * La String retournée est de longueur 56 et contient le hash en Base64. */ ConfigurablePasswordEncryptor passwordEncryptor = new ConfigurablePasswordEncryptor(); passwordEncryptor.setAlgorithm( ALGO_CHIFFREMENT ); passwordEncryptor.setPlainDigest( false ); String motDePasseChiffre = passwordEncryptor.encryptPassword( motDePasse ); utilisateur.setMotDePasse( motDePasseChiffre ); } /* Validation de l'adresse email */ private void validationEmail( String email ) throws FormValidationException { if ( email != null ) { if ( !email.matches( "([^.@]+)(\\.[^.@]+)*@([^.@]+\\.)+([^.@]+)" ) ) { throw new FormValidationException( "Merci de saisir une adresse mail valide." ); } else if ( utilisateurDao.trouver( email ) != null ) { throw new FormValidationException( "Cette adresse email est déjà utilisée, merci d'en choisir une autre." ); } } else { throw new FormValidationException( "Merci de saisir une adresse mail." ); } } |
com.sdzee.forms.InscriptionForm
Pour commencer, remarquez la structure des méthodes traiterXXX() créées : comme je vous l'ai déjà annoncé, celles-ci renferment simplement l'appel à la méthode de validation d'un champ et l'initialisation de la propriété du bean correspondante.
Ensuite dans la méthode de traitement des mots de passe, j'ai ajouté la procédure de chiffrement à l'aide de la bibliothèque Jasypt aux lignes 39 à 42. Vous pouvez la télécharger directement en cliquant sur ce lien. De la même manière que pour les bibliothèques que nous avons déjà manipulées dans le passé, il suffit de placer le fichier .jar récupéré sous /WEB-INF/lib.
Je vous laisse parcourir sa documentation et découvrir les méthodes et objets disponibles, en l'occurrence le code que je vous donne est suffisamment commenté pour que vous compreniez comment ce que j'ai mis en place fonctionne.
Il est important de réaliser cette sécurisation du mot de passe en amont, afin d'initialiser la propriété du bean avec l'empreinte ainsi générée et non pas directement avec le mot de passe en clair. Par la suite, lorsque nous souhaiterons vérifier si un utilisateur entre le bon mot de passe lors de sa connexion, il nous suffira de le comparer directement à l'empreinte stockée grâce à la méthode passwordEncryptor.checkPassword(). De manière générale, la règle veut qu'on ne travaille jamais directement sur les mots de passe en clair.
Enfin, j'ai ajouté dans la méthode de validation de l'adresse email un appel à la méthode trouver() du DAO, afin de renvoyer une exception en cas d'adresse déjà existante. Cela veut dire que nous effectuons deux requêtes sur la base lors d'une inscription utilisateur : une pour vérifier si l'adresse n'existe pas déjà via l'appel à trouver(), et une pour l'insérer via l'appel à creer().
Est-ce bien nécessaire d'effectuer deux requêtes ? Économiser une requête vers la BDD ne serait pas préférable ?
Eh bien oui, c'est bien plus pratique pour nous d'effectuer une vérification avant de procéder à l'insertion. Si nous ne le faisions pas, alors nous devrions nous contenter d'analyser le statut retourné par notre requête INSERT et d'envoyer une exception en cas d'un statut valant zéro. Le souci, c'est qu'un échec de l'insertion peut être dû à de nombreuses causes différentes, et pas seulement au fait qu'une adresse email existe déjà en base ! Ainsi en cas d'échec nous ne pourrions pas avertir l'utilisateur que le problème vient de son adresse mail, nous pourrions simplement l'informer que la création de son compte à échoué. Il tenterait alors à nouveau de s'inscrire avec les mêmes coordonnées en pensant que le problème vient de l'application, et recevrait une nouvelle fois la même erreur, etc.
En testant en amont la présence de l'adresse en base via une bête requête de lecture, nous sommes capables de renvoyer une erreur précise à l'utilisateur. Si l'appel à trouver() retourne quelque chose, alors cela signifie que son adresse existe déjà : nous envoyons alors une exception contenant un message lui demandant d'en choisir une autre, qui provoque dans traiterEmail() la mise en place du message dans la Map des erreurs, et qui ainsi permet de ne pas appeler la méthode creer() en cas d'adresse déjà existante.
En outre, chercher à économiser ici une requête SQL relève du détail. Premièrement parce qu'il s'agit ici d'un simple SELECT très peu gourmand, et deuxièmement parce qu'à moins de travailler sur un site extrêmement populaire, l'inscription reste une opération effectuée relativement peu fréquemment en comparaison du reste des fonctionnalités. Bref, pas de problème !
Création d'une exception dédiée aux erreurs de validation
Enfin, vous remarquez que nos méthodes renvoient dorénavant des FormValidationException, et non plus de banales Exception. J'ai en effet pris soin de créer une nouvelle exception personnalisée, qui hérite d'Exception et que j'ai placée dans com.sdzee.forms :
1 2 3 4 5 6 7 8 9 10 | package com.sdzee.forms; public class FormValidationException extends Exception { /* * Constructeur */ public FormValidationException( String message ) { super( message ); } } |
com.sdzee.forms.FormValidationException
Ce n'est pas une modification nécessaire en soit, mais cela rend le code plus compréhensible à la lecture, car nous savons ainsi quel type d’erreur est manipulé par une méthode au premier coup d’œil.
Vérifications
Le code final
Avant tout, je vous propose de vérifier que vous avez bien reporté toutes les modifications nécessaires au code existant, et réalisé tous les ajouts demandés. Voici sur la figure suivante l'arborescence que vous êtes censés obtenir.
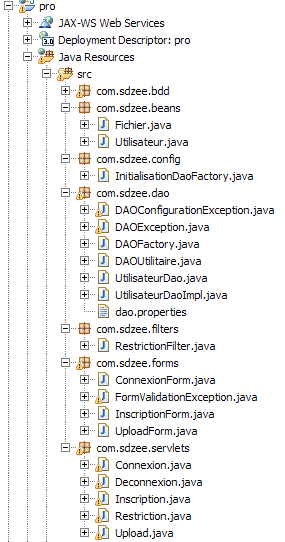
Certaines classes ayant subi beaucoup de retouches, j'ai dû fractionner leur code en plusieurs sections, afin de vous l'expliquer le plus clairement possible et ainsi de vous en faciliter la compréhension. Ne souhaitant pas vous voir vous emmêler les pinceaux, je vous propose de télécharger les codes complets des deux classes les plus massives :
Vous pourrez ainsi vous assurer que vous n'avez omis aucun changement.
Le scénario de tests
Après toutes ces nouveautés, tous ces ajouts et toutes ces modifications, il est temps de tester le bon fonctionnement de notre application. Le scénario est relativement léger, il suffit de tester ce qui se passe lorsqu'un utilisateur tente de s'inscrire deux fois avec la même adresse email. Je vous laisse reprendre les scénarios des chapitres précédents, afin de vous assurer que tout ce que nous avions mis en place dans les chapitres précédents fonctionne toujours.
Pour information, cela s'appelle un test de régression. Cela consiste à vérifier que les modifications apportées sur le code n'ont pas modifié le fonctionnement de la page ou de l'application, et c'est bien entendu un processus récurrent et extrêmement important dans le développement d'une application !
Voici à la figure suivante le formulaire avant soumission des données.
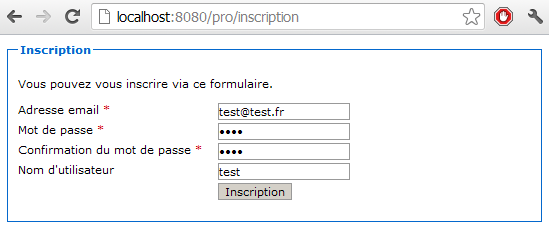
Voici à la figure suivante le formulaire après soumission la première fois.
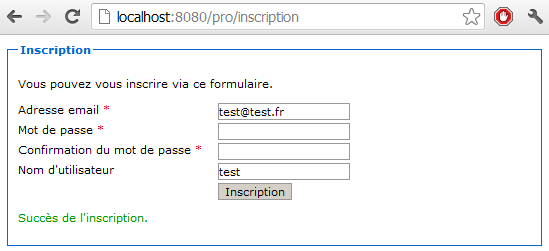
Voici à la figure suivante le formulaire après soumission une seconde fois.
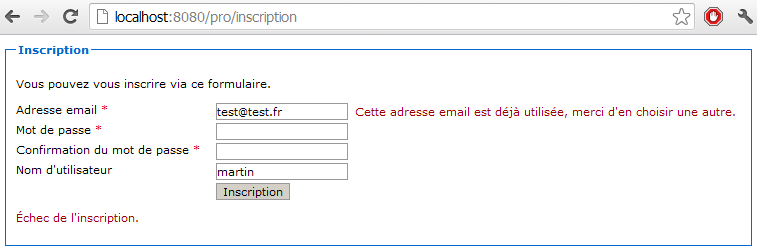
Comme prévu, la méthode de validation de l'adresse email a correctement fait son travail. Elle a reçu un résultat lors de l'appel à la méthode trouver(), et a par conséquent placé un message d'erreur sur le champ email.
En outre, vous pouvez regarder le contenu de votre table Utilisateur depuis la console de votre serveur MySQL, via un simple SELECT * FROM Utilisateur;. Vous constaterez alors que les informations que vous avez saisies depuis votre navigateur ont bien été enregistrées dans la base de données, et que le mot de passe a bien été chiffré.
Voilà tout ce qu'il est nécessaire de vérifier pour le moment. En apparence, cela paraît peu par rapport à tout le code que nous avons dû mettre en place, je vous l'accorde. Mais ne vous en faites pas, nous n'avons pas uniquement rendu notre premier DAO opérationnel, nous avons préparé le terrain pour tous les futurs DAO de notre application !
- Le pattern DAO permet d'isoler l'accès aux données et leur stockage du reste de l'application.
- Mettre en place des exceptions spécifiques au DAO permet de masquer le type du stockage sous-jascent.
- Mettre en place une Factory initialisée au démarrage de l'application via un
ServletContextListenerpermet de ne charger qu'une seule et unique fois le driver JDBC. - Mettre en place des utilitaires pour la préparation des requêtes et la libération des ressources permet de limiter la duplication et d'alléger grandement le code.
- Notre DAO libérant proprement les ressources qu'il met en jeu, une seule et unique instance de notre DAO peut être partagée par toutes les requêtes entrantes.
- Récupérer une telle instance de DAO de manière unique depuis une servlet, et non pas à chaque requête entrante, peut se faire simplement en utilisant sa méthode
init(). - Notre servlet transmet alors simplement l'instance du DAO à l'objet métier, qui sera responsable de la gestion des données.
- Notre objet métier ne connaît pas le système de stockage final utilisé : il ne fait qu'appeler les méthodes définies dans l'interface de notre DAO.