Préparation aux cas d'étude
Comme pour la partie précédente, nous allons apprendre les différentes notions qui vont suivre via deux cas d’étude.
Qui dit "cas d’étude" dit "ajustement à opérer". L’avantage, contrairement aux cas d’études déjà réalisés, c’est que cette fois-ci, vous pouvez voir la préparation comme un TP en soit.
En effet, vous avez sûrement remarqué qu’ASP.NET aimerait que vous développiez une page Article/Details.
C’est ce que nous allons devoir faire dans un premier temps, si vous ne l’avez pas déjà fait avant :p.
Comme cela peut être vu comme un TP, la "correction" sera masquée.
public ActionResult Details(int id)
{
Article art = bdd.Articles.Find(id);
if (art == null)
{
return new HttpNotFoundResult();
}
return View(art);
}
@model Blog.Models.Article
@using Blog.Models;
<section>
<h1>@Html.DisplayFor(model => model.Titre)</h1>
<hr />
<header>
<dl class="dl-horizontal">
<dt>
@Html.DisplayNameFor(model => model.Pseudo)
</dt>
<dd>
@Html.DisplayFor(model => model.Pseudo)
</dd>
<dd>
<img src="@Html.DisplayFor(model => model.ImageName)" alt="@Html.DisplayFor(m => m.Titre)" />
</dd>
</dl>
</header>
<article>
@Html.DisplayFor(model => model.Contenu)
</article>
</section>
<footer>
@Html.ActionLink("Edit", "Edit", new { id = Model.ID }) |
@Html.ActionLink("Retour à la liste", "List")
</footer>
Cas d'étude numéro 1 : les commentaires
Relation 1->n
Commençons à étoffer notre blog. Le principe d’un tel site est que chacun puisse commenter un article.
Pour simplifier, nous allons dire qu’un commentaire peut être publié par n’importe qui du moment que cette personne donne son adresse e-mail.
Ainsi, une représentation basique, comme nous l’avions fait jusqu’à présent du commentaire serait celle-ci :
public class Commentaire{
public int ID {get; set;}
[DataType(DataType.Email)]
public string Email {get; set;}
[StringLength(75)]
public string Pseudo {get; set;}
[DataType(DataType.MultilineText)]
public string Contenu {get; set;}
public DateTime Publication{get; set;}
}
Le problème de cette représentation, c’est qu’elle ne prend pas en compte le fait que le commentaire se réfère à un article. Je dirais même plus, le commentaire se réfère à un et un seul article.
Pour schématiser cela, on pourrait écrire :

Ce schéma, signifie qu’il y a un lien entre le commentaire et l’article et donc qu’à partir d’un commentaire on peut retrouver l’article auquel il est lié.
Sous forme de code, cela s’écrit :
public class Commentaire{
public int ID {get; set;}
[DataType(DataType.EmailAddress)]
public string Email {get; set;}
[StringLength(75)]
public string Pseudo {get; set;}
[DataType(DataType.MultilineText)]
public string Contenu {get; set;}
public DateTime Publication{get; set;}
//On crée un lien avec l'article
public Article Parent {get; set;}
}
Jusque là rien de très compliqué.
N’oubliez pas de créer un DbSet nommé Commentaires dans votre contexte
Pour créer un commentaire, le code ne change pas, il faudra juste s’assurer que lorsque vous créez le commentaire vous lui liez un article, sinon EntityFramework vous dira que la sauvegarde est impossible.
Là où le code va changer, c’est quand il va falloir aller chercher l’article lié au commentaire.
Par défaut, EntityFramework ne va pas le chercher par peur de surcharger la mémoire. Il faudra donc lui dire explicitement d’aller chercher l’objet.
Pour cela, il faut utiliser la méthode Include.
Cette méthode attend en paramètre le nom du lien à charger. Dans notre cas c’est Parent.
//obtient le premier commentaire (ou null s'il n'existe pas) du premier article du blog
Commentaire com = bdd.Commentaires.Include('Parent').Where(c => c.Id = 1).FirstOrDefault();
Article articleLie = com.Article;//
J’ai un problème : ce que je veux, moi, c’est afficher un article grâce à son identifiant puis, en dessous afficher les commentaires liés.
Comme je vous comprends !  Pour faire cela, on dit qu’il faut "inverser" la relation 1-n.
Pour faire cela, on dit qu’il faut "inverser" la relation 1-n.
Inverser la relation 1-n
Le principe
Derrière le mot "inverser", rien de très inquiétant finalement. Vous vous souvenez du schéma de tout à l’heure ? Nous avions une flèche. Cette flèche disait dans quel sens on pouvait parcourir la relation. Comme nous voulons la parcourir dans le sens inverse, il faudra "implémenter" non plus une flèche simple mais une flèche double.

A priori, cela ne devrait pas être trop compliqué de mettre en place cette inversion. En effet, si nous voulons une liste de commentaires, intuitivement, nous sommes tentés de mettre dans la classe Article un attribut de type List<Commentaire> :
public class Article{
public List<Commentaire> Commentaires { get; set; }
}
Sachez qu’on peut s’en contenter, néanmoins, cela peut poser quelques difficultés lorsque nous coderons par la suite.
Lazy Loading
Souvenons-nous que nous utilisons un ORM : Entity Framework.
Ce qui est bien avec les ORM, c’est qu’ils créent leurs requêtes tous seuls.
A priori, néanmoins, il ne va pas charger tout seul les entités liées. Il vous faudra, comme lorsqu’on n’avait pas encore inversé la relation, utiliser Include pour aller chercher la liste des commentaires.
Cela peut être intéressant de faire ça si vous devez précharger en une seule requête un nombre important de données.
Par contre, si vous ne devez en charger qu’une toute petite partie (pagination, objets les plus récents…) vous allez occuper de l’espace mémoire en préchargeant tout. Une astuce sera donc de charger uniquement à la demande. Dans le monde des ORMs, cette technique a un nom : le lazy loading.
Le lazy loading est une fonctionnalité très appréciable des ORM, néanmoins, n’en abusez pas, si vous l’utilisez pour des gros volumes de données, votre page peut devenir très longue à charger.
Pour activer le lazy loading, il faut ajouter le mot clef virtual devant notre liste de commentaires.
Virtual ? comme pour surcharger les méthodes héritées ?
Oui, le même virtual. Mais à contexte différent, sens différent, vous vous en doutez.
public class Article
{
public int ID { get; set; }
/// <summary>
/// Le pseudo de l'auteur
/// </summary>
[Required(AllowEmptyStrings = false)]
[StringLength(128)]
[RegularExpression(@"^[^,\.\^]+$")]
[DataType(DataType.Text)]
public string Pseudo { get; set; }
/// <summary>
/// Le titre de l'article
/// </summary>
[Required(AllowEmptyStrings = false)]
[StringLength(128)]
[DataType(DataType.Text)]
public string Titre { get; set; }
/// <summary>
/// Le contenu de l'article
/// </summary>
[Required(AllowEmptyStrings = false)]
[DataType(DataType.MultilineText)]
public string Contenu { get; set; }
/// <summary>
/// Le chemin de l'image
/// </summary>
public string ImageName { get; set; }
public virtual List<Commentaire> Comments { get; set; }
}
Interface graphique : les vues partielles
Maintenant que vous avez mis à jour votre modèle, mis à jour votre contrôleur d’article, il faut qu’on affiche les commentaires.
Habituellement, les commentaires sont affichés dans la page Details de l’article.
Par contre, nous pouvons imaginer qu’ils seront affichés autre part : modération des commentaires, commentaire le plus récent en page d’accueil…
Mettre en dur l’affichage des commentaires dans la page d’article, ça peut être assez contre productif.
Étape 1 : la liste des commentaires
Dans le dossier View, ajouter un dossier Commentaire. Puis ajoutez une vue nommée _List avec pour modèle Commentaire. Par contre, veillez à sélectionner "créer en tant que vue partielle" :
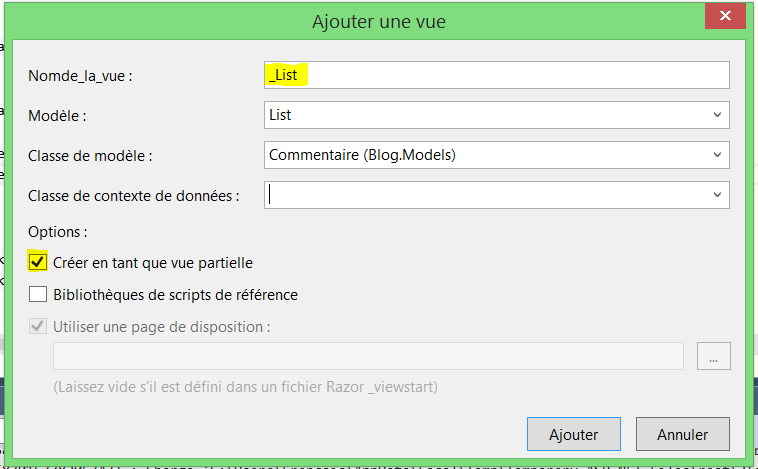
Vous remarquerez l’underscore utilisé dans le nom de la vue. C’est une convention pour les vues partielles.
Cas d'étude numéro 2 : les tags
Bien, maintenant, nous avons nos articles avec leurs commentaires. C’est une bonne chose, et sachez que la relation One To Many est la plus courante dans le monde de la base de données.
Définition et mise en place
Pour autant elle n’est pas la seule à être très utilisée, nous allons le découvrir grâce à ce nouveau cas d’étude qui concerne les Tags.
Avant d’aller plus loin, essayons de comprendre ce qu’est un Tag et son intérêt.
Basiquement, un tag c’est un mot clef ou une expression clef. Ce mot clef permet de regrouper un certain nombre de contenu sous son égide. Mais comme ce n’est qu’un mot clef, et non une catégorie hiérarchique, un article peut se référer à plusieurs mots clefs.
Prenons un exemple avec ce tutoriel, il se réfère aux mots clefs .NET, Web Service et C#. En effet, nous avons utilisé le C# pour créer un Web Service à partir du framework .NET. On dit que grâce aux tags, on navigue de manière horizontale plutôt que hiérarchique (ou verticale). En effet, quelqu’un qui lit notre tutoriel peut se vouloir se renseigner plus à propos de ce qui se passe dans le framework .NET et ira sûrement obtenir d’autres tutoriels pour faire une application Windows Phone, un navigateur avec Awesomium…
Vous l’aurez compris, un article possède plusieurs tags mais chaque tag pointe vers plusieurs articles. On dit alors que la relation entre les deux entités est une relation Many To Many.

L’idée sera donc, du point de vue du code, de simplement créer dans la classe Article une liste de tags et dans la classe Tag une liste d’articles.
public class Tag
{
public int ID { get; set; }
public string Name { get; set; }
[StringLength(255)]
[Display(AutoGenerateField = true)]
[Index(IsUnique=true)]//permet de rendre unique le slug comme ça le tag "Mon Tag" et "mon tag" et "MOn Tag" seront le même :-)
public string Slug { get; set; }
public virtual List<Article> LinkedArticles { get; set; }
}
public class Article
{
public int ID { get; set; }
/// <summary>
/// Le pseudo de l'auteur
/// </summary>
[Required(AllowEmptyStrings = false)]
[StringLength(128)]
[RegularExpression(@"^[^,\.\^]+$")]
[DataType(DataType.Text)]
public string Pseudo { get; set; }
/// <summary>
/// Le titre de l'article
/// </summary>
[Required(AllowEmptyStrings = false)]
[StringLength(128)]
[DataType(DataType.Text)]
public string Titre { get; set; }
/// <summary>
/// Le contenu de l'article
/// </summary>
[Required(AllowEmptyStrings = false)]
[DataType(DataType.MultilineText)]
public string Contenu { get; set; }
/// <summary>
/// Le chemin de l'image
/// </summary>
public string ImageName { get; set; }
public virtual List<Commentaire> Comments { get; set; }
public virtual List<Tag> Tags { get; set; }
}
Vous l’avez peut-être remarqué, j’ai utilisé l’attribut [Index]. Ce dernier permet de spécifier que notre Slug sera unique dans la bdd ET qu’en plus trouver un tag à partir de son slug sera presque aussi rapide que de le trouver par sa clef primaire.
Dans notre base de données, nous aurons par contre un léger changement. Allons voir notre explorateur de serveurs une fois que la classe Tag a été ajoutée à notre DbContext.
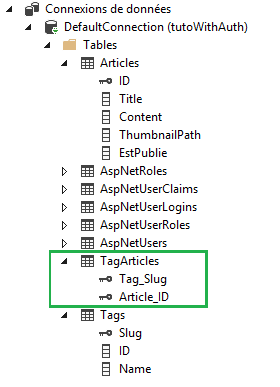
Nous observons qu’une nouvelle table a été ajoutée, je l’ai encadrée pour vous. Elle a été automatiquement nommée "TagArticle" et permet de faire le lien entre les articles et les tags. En fait lorsque vous ajouterez un tag à un article, c’est dans cette table que l’entrée sera enregistrée. Et cette entrée sera l’identifiant de votre article en première colonne et celui du tag lié en seconde colonne.
Retenez bien cela : toute relation many to many crée en arrière plan une nouvelle table. Mais ne vous inquiétez pas, dans bien des cas cette table n’impacte pas les performances de votre site, en fait si vous avez bien réfléchi, cela va même les améliorer car la bdd est faite pour ça !
Un champ texte, des virgules
Notre but, désormais, sera, à la création de l’article, de choisir une liste de Tags. Comme le nombre de tags est indéterminé au départ, on ne peut pas proposer 5 ou 10 cases juste pour rentrer des tags, le mieux, c’est de proposer un champ texte simple et de dire que chaque tag sera séparé par une virgule.
Je vous rappelle que le modèle d’article nécessite un ViewModel pour traiter facilement les données d’image. Le meilleur moyen d’arriver à nos fins est donc de continuer le travail de ce ViewModel pour réussir à traiter notre liste de tags.
Je mets le code "final" en caché, mais voici ce qu’il vous faudra faire :
- Modifier le ViewModel pour qu’il accepte une chaîne de caractères nommée "Tags" qui s’affiche correctement ;
- Modifier le contrôleur pour qu’il récupère les tags qu’on veut ajouter ;
- Ensuite il doit regarder en bdd ceux qui existent déjà ;
- Pour pouvoir ajouter ceux qui n’existent pas en bdd ;
- Et enfin tout lier à l’article qu’on vient de créer !
[HttpPost]
[ValidateAntiForgeryToken]
public ActionResult Create(ArticleCreation articleCreation)
{
if (!ModelState.IsValid)
{
return View(articleCreation);
}
string fileName = "";
if (!handleImage(articleCreation, out fileName))
{
return View(articleCreation);
}
Article article = new Article
{
Contenu = articleCreation.Contenu,
Pseudo = articleCreation.Pseudo,
Titre = articleCreation.Titre,
ImageName = fileName,
Tags = new List<Tag>()
};
IEnumerable<Tag> askedTags = new List<Tag>();
SlugHelper slugifier = new SlugHelper();
if(articleCreation.Tags.Trim().Length > 0)
{
askedTags = from tagName in articleCreation.Tags.Split(',') select new Tag { Name = tagName.Trim(), Slug = slugifier.GenerateSlug(tagName.Trim()) };
}
foreach (Tag tag in askedTags)
{
Tag foundInDatabase = bdd.Tags.FirstOrDefault(t => t.Slug == tag.Slug);
if (foundInDatabase != default(Tag))
{
article.Tags.Add(foundInDatabase);
}
else
{
article.Tags.Add(tag);
}
}
bdd.Articles.Add(article);
bdd.SaveChanges();
return RedirectToAction("List", "Article");
}
Si vous avez réussi à produire un code similaire à la correction que je vous propose, bravo !
Vous allez pouvoir faire la même chose pour la fonction d’édition. Par contre, faites attention, il faudra en plus prendre en compte le fait que le tag a peut-être déjà été ajouté à l’article.
[HttpPost]
[ValidateAntiForgeryToken]
public ActionResult Edit(int id, ArticleCreation articleCreation)
{
//on ne peut plus utiliser Find car pour aller chercher les tags nous devons utiliser Include.
Article entity = bdd.Articles.Include("Tags").FirstOrDefault(m => m.ID == id);
if (entity == null)
{
return RedirectToAction("List");
}
string fileName;
if (!handleImage(articleCreation, out fileName))
{
return View(articleCreation);
}
DbEntityEntry<Article> entry = bdd.Entry(entity);
entry.State = System.Data.Entity.EntityState.Modified;
Article article = new Article
{
Contenu = articleCreation.Contenu,
Pseudo = articleCreation.Pseudo,
Titre = articleCreation.Titre,
ImageName = fileName
};
entry.CurrentValues.SetValues(article);
IEnumerable<Tag> askedTags = new List<Tag>();
SlugHelper slugifier = new SlugHelper();
if (articleCreation.Tags.Trim().Length > 0)
{
askedTags = from tagName in articleCreation.Tags.Split(',') select new Tag { Name = tagName.Trim(), Slug = slugifier.GenerateSlug(tagName.Trim()) };
}
foreach (Tag tag in askedTags)
{
Tag foundInDatabase = bdd.Tags.FirstOrDefault(t => t.Slug == tag.Slug);
if (foundInDatabase != default(Tag) && !article.Tags.Contains(foundInDatabase))
{
article.Tags.Add(foundInDatabase);
}
else if(foundInDatabase == default(Tag))
{
article.Tags.Add(tag);
}
}
bdd.SaveChanges();
return RedirectToAction("List");
}
Vous l’aurez peut-être remarqué, nous avons plusieurs fois dupliqué du code. Je sais, c’est mal ! Ne vous inquiétez, pas nous y reviendrons. En effet, pour simplifier énormément notre code, nous allons devoir apprendre comment créer nos propres validateurs, ainsi que la notion de ModelBinder. Cela sera fait dans la prochaine partie.
Allons plus loin avec les relations Plusieurs à Plusieurs
Pour terminer ce cas d’étude et ce chapitre sur les relations, nous allons juste parler d’un cas qui restera ici théorique mais qui est très courant dans le monde du web et des bases de données.
On appelle cela "la relation avec propriété". Bon, c’est un peu long à écrire comme nom. Le mieux c’est de s’imaginer un système de vote "+1" réservé aux personnes qui ont un compte sur votre blog (pour simplifier, on n’essaie pas de faire de -1).
Une personne peut voter pour plusieurs articles, et chaque article peut avoir un nombre important de votes. Mais en plus, nous, gérant du blog, on veut savoir si les gens votent même quand l’article a été posté il y a longtemps. Dans ce cas, il faut qu’on retienne la date du vote. Eh bien, c’est exactement là que vient la "relation avec propriété" : nous avons une relation n-n entre les utilisateurs et les articles, mais il faut aussi qu’on retienne la date.
Et là, il vous faudra vous souvenir de ce qui s’était passé au sein de la BDD quand on avait créé une relation n-n : une table intermédiaire avait été créée.
Eh bien nous allons devoir faire la même chose : nous allons créer une entité intermédiaire qui aura une relation 1-n avec les articles et une relation 1-n avec les utilisateurs.
De plus, pour s’assurer qu’on ne peut voter qu’une fois sur un article, il faudra configurer un peu notre entité.
Je vous poste le code, il constitue un modèle pour vos futurs besoins :
public class MemberComment
{
[Key, Column(Order = 0)]
public int MemberID { get; set; }
[Key, Column(Order = 1)]
public int VotedArticleID { get; set; }
//les deux attributs virtuels suivants vous permettent d'utiliser les propriétés comme d'habitude
//elles seront automatiquement liées à MemberID et VotedArticleID
public virtual Member Member { get; set; }
public virtual Article VotedArticle { get; set; }
public DateTime VoteDate { get; set; }
}