Les textures sont des images que l'on va plaquer sur la surface d'un objet, du papier peint en quelque sorte. Les cartes graphiques supportent divers formats de textures, qui indiquent comment les pixels de l'image sont stockés en mémoire : RGB, RGBA, niveaux de gris, etc. Une texture est donc composée de "pixels", comme toute image numérique. Pour bien faire la différence entre les pixels d'une texture, et les pixels de l'écran, les pixels d'une texture sont couramment appelés des texels.
Plaquer une texture sur un objet consiste à attribuer une vertice à chaque texel, ce qui est fait lorsque les créateurs de jeu vidéo conçoivent le modèle de l'objet. Chaque vertice contient donc des coordonnées de texture, qui indiquent quel texel appliquer sur la vertice. Ces coordonnes précisent la position du texel dans la texture. Par exemple, la coordonnée de texture peut dire : je veux le pixel qui est à la ligne 5, et la colonne 27 dans ma texture.

Lors de la rasterization, ces coordonnées sont interpolées, et chaque pixel de l'écran se voit attribuer une coordonnée de texture, qui indique avec quel texel il doit être colorié. À partir de ces coordonnées de texture, le circuit de gestion des textures calcule l'adresse du texel qui correspond, et se charge de lire celui-ci. Sur les anciennes cartes graphiques, les textures disposaient de leur propre mémoire, séparée de la mémoire vidéo. Mais c'est du passé : de nos jours, les textures sont stockées dans la mémoire vidéo principale.
Évidemment, l'algorithme de rasterization a une influence sur l'ordre dans lequel les pixels sont envoyés aux unités de texture. Et suivant l'algorithme, les texels lus seront proches ou dispersés en mémoire. Généralement, le meilleur algorithme est celui du tiled traversal.
Filtrage
On pourrait croire que plaquer des textures sans autre forme de procès suffit à garantir des graphismes d'une qualité époustouflante. Mais les texels ne vont pas tomber tout pile sur un pixel de l'écran : la vertice correspondant au texel peut être un petit peu trop en haut, ou trop à gauche, etc. Pour résoudre ce problème, on peut colorier avec le texel correspondant à la vertice la plus proche. Autant être franc, le résultat est assez dégueulasse.
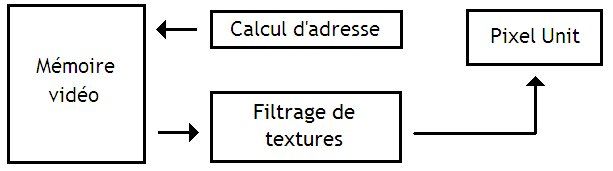
Pour améliorer la qualité de l'image, la carte graphique va effectuer un filtrage de la texture. Ce filtrage consiste à choisir le texel à appliquer sur un pixel du mieux possible, par un calcul mathématique assez simple. Ce filtrage est réalisé par un circuit spécialisé : le texture sampler, lui-même composé :
- d'un circuit qui calcule les adresses mémoire des texels à lire et les envoie à la mémoire ;
- d'un circuit qui va filtrer les textures.
Filtrage bilinéaire
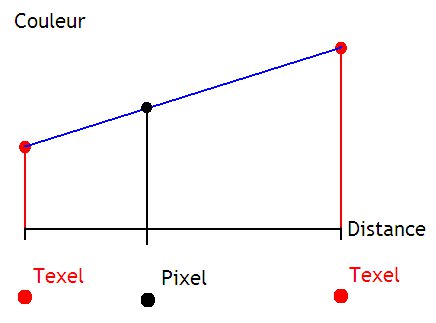
Le plus simple de ces filtrage est le filtrage bilinéaire, qui effectue une sorte de moyenne des quatre texels les plus proches du pixel à afficher. Plus précisément, ce filtrage va effectuer ce qu'on appelle des interpolations linéaires. Pour comprendre l'idée, nous allons prendre une situation très simple, où un pixel est aligné avec deux autres texels.
Pour effectuer l'interpolation linéaire entre ces deux texels, nous allons faire une première supposition : la couleur varie entre les deux texels en suivant une fonction affine. On peut alors calculer la couleur du pixel par un petit calcul mathématique.
Il suffit de :
- calculer la pente de la courbe ;
- multiplier cette pente par la distance entre le texel choisit et le pixel ;
- ajouter la couleur de base du texel choisit.
Seul problème, cela marche pour deux pixels, pas 4. Avec 4 pixels, nous allons devoir calculer la couleur de points intermédiaires :
- celui qui se situe à l'intersection entre la droite formé par les deux texels de gauche, et la droite parallèle à l'abscisse qui passe par le pixel.
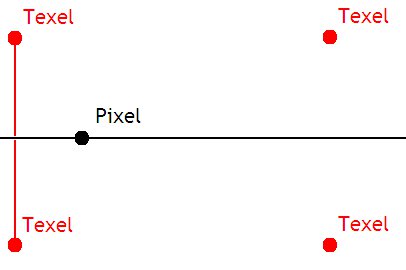
- celui qui se situe à l'intersection entre la droite formé par les deux texels de gauche, et la droite parallèle à abscisse qui passe par le pixel.
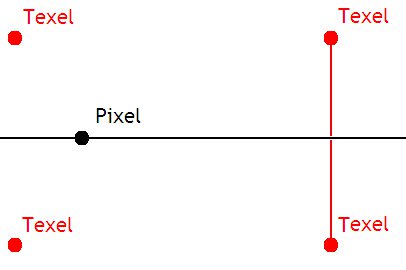
La couleur de ces deux points se calcule par interpolation linéaire, et il suffit d'utiliser une troisième interpolation linéaire pour obtenir le résultat.
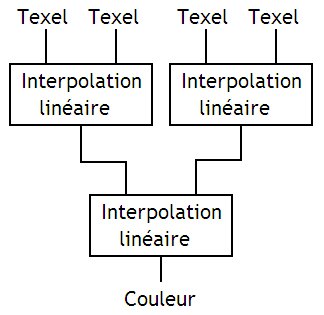
Le circuit qui permet de faire ce genre de calcul est particulièrement simple. On trouve un circuit de chaque pour chaque composante de couleur de chaque texel : un pour le rouge, un pour le vert, un pour le bleu, et un pour la transparence. Chacun de ces circuit est composé de sous-circuits chargés d'effectuer une interpolation linéaire, reliés comme suit :
Mip-mapping
Si une texture est plaquée sur un objet lointain, une bonne partie des détails de la texture est invisible pour l'utilisateur : un objet assez lointain peut très bien ne prendre que quelques dizaines de pixels à l'écran. Dans ces conditions, plaquer une texture de 512 pixel de coté serait vraiment du gâchis en terme de performance : il faudrait charger tous les pixels de la texture, les traiter, et n'en garder que quelque uns. De plus, procéder comme cela pourrait créer des artefacts visuels : les textures affichées ont tendance à pixeliser.
Pour limiter la casse, les concepteurs de jeux vidéo utilisent souvent la technique du mip-mapping. Cette technique consiste simplement à utiliser plusieurs exemplaires d'une même texture, chaque exemplaire étant adapté à une certaine distance. Ce qui différenciera ces exemplaires, ce sera leur résolution. Par exemple, une texture sera stocké dans un exemplaire de 512 * 512 pixels, un autre de 256 * 256, un autre de 128 * 128 et ainsi de suite jusqu’à un dernier exemplaire de 32 * 32. Chaque exemplaire correspond à un niveau de détail, aussi appelé Level Of Detail en anglais (abrévié en LOD).
Le bon exemplaire sera choisit lors de l'application de la texture. Ainsi, les objets proches seront rendus avec la texture la plus grande (512 par 512 dans notre exemple). Au-delà d'une certaine distance, les textures 256 par 256 seront utilisées. Encore plus loin, les textures 128 par 128 seront utilisées, etc.
Pour faire en sorte que la bonne mip-map soit choisie, les circuits chargés de calculer l'adresse de la texture doivent recevoir des informations supplémentaires pour choisir la mip-map à appliquer. Der plus, ils doivent être adaptés pour calculer l'adresse du texel correctement : celui doit être chargé depuis la bonne mip-map.
Pour faciliter ces calculs, les mip-maps d'une texture sont stockées les unes après les autres en mémoire. Pas besoin de se souvenir de la position en mémoire de chacune des mip-map : l'adresse de la plus grande, et quelques astuces arithmétiques suffisent.
Évidemment, cette technique consomme de la mémoire RAM : chaque texture est dupliquée en plusieurs exemplaires. On peut remarquer une chose : si je prend une texture à un niveau de détail donné, la texture de niveau de détail immédiatement inférieur sera 4 fois plus petite : 2 fois moins de pixels en largeur, et 2 fois moins en hauteur. Donc, si je pars d'une texture de base contenant X pixels, la totalité des mip-maps, texture de base comprise, prendra X + (X/4) + (X/44) + (X/44*4) + … Cela donne 4/3 * X. La technique du mip-mapping prendra donc au maximum 33% de mémoire en plus (sans compression).
Filtrage trilinéaire
Avec le mip-mapping, les textures sont un peu plus belles, mais cette technique a un défaut : des discontinuités apparaissent lorsqu'une texture est appliquée répétitivement sur une surface, comme quand on fabrique un carrelage à partir de carreaux tous identiques. Par exemple, pensez à une texture de sol : celle-ci est appliquée plusieurs fois sur toute la surface du sol. Au delà d'une certaine distance, le LOD utilisé change brutalement et passe par exemple de 512512 à 256256, ce qui est visible pour un joueur attentif.
Le filtrage trilinéaire permet d'adoucir ces transitions. Son principe est simple : il consiste à faire « une moyenne » entre les textures des niveaux de détails adjacents. Le filtrage trilinéaire demande d'effectuer deux filtrages bilinéaires : un sur la texture du niveau de détail adapté, et un autre sur la texture de niveau de détail inférieur. Les deux textures obtenues par filtrage vont ensuite subir une interpolation linéaire.
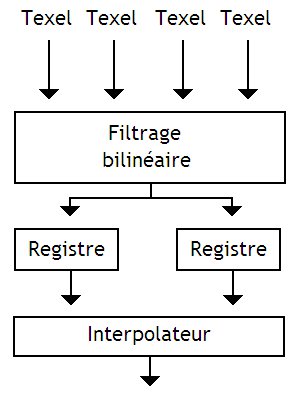
Le circuit qui s'occupe de calculer un filtrage trilinéaire est une amélioration du circuit utilisé pour le filtrage bilinéaire. Il est constitué d'un circuit effectuant un filtrage bilinéaire, de deux registres, d'un interpolateur linéaire, et de quelques circuits de gestion, non-représentés.
Son fonctionnement est simple : ce circuit charge 4 texels d'une mip-map, les filtre, et stocke le tout dans un registre. Il recommence l'opération avec les 4 texels de la mip-map de niveau de détail inférieure, et stocke le résultat dans un autre registre. Enfin, le tout passe par un circuit qui interpole les couleurs finales en tenant compte des coefficients d'interpolation linéaire, mémorisés dans des registres.
Il est possible de créer un circuit qui effectue les deux filtrages en parallèle. Seul problème : ce genre de circuit nécessite de charger 8 pixels simultanément. Qui plus est, ces 8 pixels ne sont pas consécutifs en mémoire. Utiliser ce genre de circuit nécessiterait d'adapter la mémoire et le cache, ce qui ne vaut généralement pas la peine.
Modifier le circuit de filtrage ne suffit pas. Comme je l'ai dit plus haut, la dernière étape d'interpolation linéaire utilise des coefficients, qui lui sont fournis par des registres. Seul problème : entre le temps où ceux-ci sont calculés par l'unité de mip-mapping, et le moment où les texels sont chargés depuis la mémoire, il se passe beaucoup de temps.
Le problème, c'est que les unités de texture sont souvent pipelinées : elles peuvent démarrer une lecture de texture sans attendre que les précédentes soient terminées. A chaque cycle d'horloge, une nouvelle lecture de texels peut commencer. La mémoire vidéo est conçue pour supporter ce genre de chose. Cela a une conséquence : durant les 400 à 800 cycles d'attente entre le calcul des coefficients, et la disponibilité des texels, entre 400 et 800 coefficients sont produits : un par cycle. Autant vous dire que mémoriser 400 à 800 ensembles de coefficient prend beaucoup de registres.
Filtrage anisotropique
Le filtrage trilinéaire permet de gommer les imperfections dues au mip-mapping. Mais d'autres artefacts peuvent survenir lors de l'application d'une texture : la perspective a tendance à déformer les textures, et peut entraîner l'apparition de flou dans certains cas. Pour gommer ce flou de perspective, les chercheurs ont inventé le filtrage anisotropique.
Dans tous les cas, le filtrage anisotropique va charger un grand nombre de texels, et effectuer des suites de filtrages bilinéaires sur ces texels chargés. Les texels chargés seront convenablement choisis, d'une manière qui change selon l'algorithme utilisé. De plus, ces texels se verront attribuer des coefficients afin de prendre en compte certains texels en priorité.
Au niveau des circuits, l'utilisation de filtrage anisotropique ne change rien au niveau des circuits de filtrage. Cela peut paraître bizarre, mais en réalité, le filtrage anisotropique ne fait que mieux choisir les texels sur lesquels utiliser le filtrage, et leur attribuer des coefficients. Tout se passe donc lors du choix des texels, à savoir : l'étape de calcul d'adresse.
Quand je parle de filtrage anisotropique, je mens un tout petit peu. En fait, je devrais plutôt dire : LES filtrages anisotropique. Il en existe plusieurs. Certains sont des algorithmes qui ne sont pas utilisés dans les cartes graphiques actuelles. Ceux-ci prennent beaucoup trop de circuits, et sont trop gourmand en accès mémoires et en calculs pour être efficaces. Il semblerait que les cartes graphiques actuelles utiliseraient des variantes de l'algorithme TEXRAM, comme l'algorithme Fast Footprint Assembly. On pourrait aussi citer l'algorithme Talisman de Microsoft, qui serait implémenté depuis Direct X 6.0.
Compression
Certaines textures un peu spéciales peuvent aller jusqu'au mébioctet, et quand on sait qu'une scène 3D normale peut dépasser la cinquantaine de textures, on est heureux de ne pas être une mémoire vidéo. Et c'est sans compter le filtrage, qui impose de lire plusieurs texels pour colorier un seul pixel : 4 d'un coup pour un filtrage bilinéaire, 8 pour le filtrage trilinéaire, et encore plus pour le filtrage anisotropique.
Pour limiter la casse, les cartes graphiques peuvent compresser les textures. La carte graphique contient alors un circuit, capable de décompresser un ou plusieurs texels. Fait important : toute la texture n'est pas décompressée : seuls les texels lus depuis la mémoire le sont.
Nos cartes graphiques supportent un grand nombre de formats de compression de texture. Nous allons en voir quelque uns. Tous ces formats sont des formats de compression dits avec pertes. Cela signifie qu'il y a une légère pertes de qualité lors de la compression. Toutefois, cette perte peut être compensée en utilisant des textures à résolution plus grande.
Comme je l'ai dit auparavant dans ce tutoriel, on peut approximativement considérer qu'une texture est une image. Il existe cependant des textures qui ne sont pas vraiment des images, et qui sont de simples tableaux de données manipulés par les pixels shaders. Et comprimer ces textures n'est pas la même chose que comprimer des textures images. Comme format, on pourrait le format 3dc d'ATI/AMD, qui sert à compresser els normals maps.
Pour les textures qui mémorisent des images, on pourrait penser utiliser des algorithmes comme le JPEG pour compresser les textures qui représentent des images. Seul problème : ces algorithmes codent des pixels sur un nombre de bits variable : impossible de calculer à l'avance la position d'un pixel en mémoire vidéo. On devrait parcourir la totalité de la texture pour lire un seul pixel ! Utiliser de tels algorithmes est donc impossible : il faut ruser…
Palette
La première technique est celle de la palette, que l'on a entraperçue dans le chapitre sur les cartes graphiques 2D. Avec cette technique, chaque texture est fournie avec une table des couleurs, qui contient les couleurs utilisées dans la texture : ce tableau s'appelle la palette. La texture ne contient aucune couleur par elle-même : à la place de chaque couleur, la texture stockera l'indice de la couleur dans la table.
Cependant, la table des couleurs a une taille fixe (de même que les numéros utilisés pour encoder les couleurs). En conséquence, cette technique ne marche pas pour les textures qui utilisent beaucoup de couleurs différentes : on est obligé de sélectionner un nombre limité de couleurs. Certains pixels se voient attribuer la couleur la plus proche qui est présente dans la palette, ce qui fait que la compression n'est pas sans pertes.
Compression par blocs
Mais il y a moyen de ruser. Dans la sous-partie sur le filtrage de texture, on a vu que les cartes graphiques lisent les textures par blocs de 1616, 88 ou 4*4 texels. De nos jours, la compression ne cherche pas à compresser des pixels individuels, mais ces blocs de texels. Le nombre de bit utilisé pour chaque texel peut varier : certains pixels se voient attribuer plus de pixels que prévus, alors que d'autres sont moins prioritaires.
Vector quantization
La technique de vector quantization peut être vue comme une amélioration de la palette, qui travaille non pas sur des texels, mais sur des blocs de texels. À l'intérieur de la carte graphique, on trouve une table qui stocke tous les blocs possible de 2 * 2, 3 * 3 , ou 4 * 4 texels. Chaque de ces blocs se voit attribuer un numéro, et la texture sera composé d'une suite de ces numéros. Quelques anciennes cartes graphiques ATI, ainsi que quelques cartes utilisées dans l’embarqué utilisent ce genre de compression.
Block Truncation coding
La première technique de compression élaborée est celle du Block Truncation Coding. Cette méthode a toutefois un défaut : elle ne marche que pour les images en niveaux de gris. Mais on va voir que cet algorithme peut être amélioré pour gérer les images couleur. La majorité des algorithmes de compression de texture utilisés dans nos cartes graphiques sont une sorte d'amélioration du Block Truncation Coding.
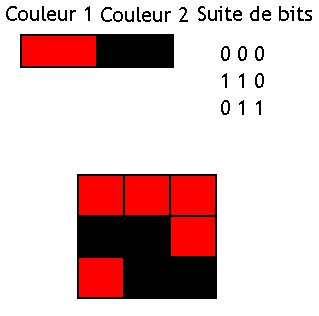
Le BTC ne mémorise que deux niveaux de gris par bloc, que nous appellerons couleur 1 et couleur 2 : à l'intérieur du bloc, chaque pixel est obligatoirement colorié avec un de ces niveaux de gris. Pour chaque pixel dans le bloc, il faut mémoriser quelle est la couleur du pixel : s'agit-il de la couleur 1 ou de la couleur 2 ? Pour cela, on utilise un bit par pixel, dont la valeur indique quelle couleur choisir : 0 pour couleur 1, et 1 pour couleur 2.
Chaque bloc est donc mémorisé en mémoire par :
- deux entiers, qui codent chacun une couleur ;
- une suite de bits.
La méthode de décompression est la suivante :
- sélectionner le bit attribué au pixel à lire ;
- selon la valeur de ce bit, choisir la couleur 1 ou couleur.
Le circuit de décompression est alors vraiment très simple : il suffit d'utiliser deux multiplexeurs.
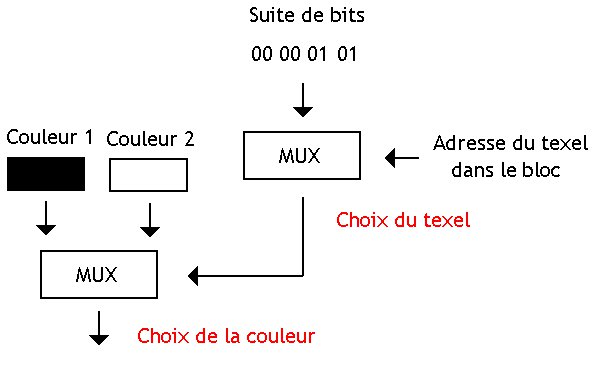
La technique du BTC peut être appliquée non pas du des niveaux de gris, mais pour chaque composante Rouge, Vert et Bleu d'un pixel. Dans ces conditions, chaque bloc sera séparé en trois sous-bloc : un sous-bloc pour la composante verte, un autre pour le rouge, et un dernier pour le bleu. Cela prend donc trois fois plus de place en mémoire que le BTC pur, mais cela permet de gérer les images couleur.
Color Cell Compression
On peur améliorer le BTC pour qu'il gère des couleurs autre que des niveaux de gris : on obtient alors l'algorithme du Color Cell Compression, ou CCC.
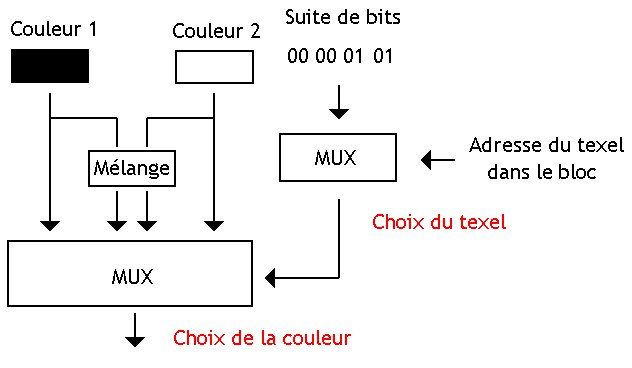
Ce CCC est très simple : au lieu d'utiliser deux niveaux de gris par bloc, on utilise deux couleurs RGBA codées sur 32 bits. Le circuit de décompression est identique à celui utilisé pour le BTC.
S3TC / DXTC
Le format de compression de texture utilisé de base par Direct X s'appelle le DXTC. Il est décliné en plusieurs versions : DXTC1, DXTC2, etc.
La première version du DXTC est une sorte d'amélioration du CCC : il ajoute une gestion minimale de transparence, et découpe la texture à compresser en carrés de 4 pixels de coté. La différence, c'est que la couleur finale d'un texel est un mélange des deux couleurs attribuée au bloc. Pour indiquer comment faire ce mélange, on trouve deux bits de contrôle par texel.

Si jamais la couleur 1 < couleur2, ces deux bits sont à interpréter comme suit :
- 00 = Couleur1
- 01 = Couleur2
- 10 = (2 * Couleur1 + Couleur2) / 3
- 11 = (Couleur1 + 2 * Couleur2) / 3
Sinon, les deux bits sont à interpréter comme suit :
- 00 = Couleur1
- 01 = Couleur2
- 10 = (Couleur1 + Couleur2) / 2
- 11 = Transparent
Le circuit de décompression du DXTC ressemble alors à ceci :
DXTC 2, 3, et 4
Pour combler les limitations du DXT1, le format DXT2 a fait son apparition. Il a rapidement été remplacé par le DXT3. Dans le DXT3, la texture et toujours découpée en blocs de 16 texels. Seule différence : la transparence fait son apparition. Chacun de ces blocs de texels est encodé sur 128 bits. Les premiers 64 bits servent à stocker des informations de transparence : 4 bits par texel. Le tout est suivi d'un bloc de 64 bits identique au bloc du DXT1. Le DXT3 a rapidement été replacé par le DXT4 et par le DXT5.
Dans ces deux formats, l'information de transparence est stockée par :
- un en-tête contenant deux valeurs de transparence ;
- le tout suivi d'une matrice qui attribue trois bits à chaque texel.
En fonction de la valeur de ces bits, les deux valeurs de transparence sont combinées pour donner la valeur de transparence finale. Le tout est suivi d'un bloc de 64 bits identique à celui qu'on trouve dans le DXT1. Pour être franc, tous les jeux vidéos actuels encodent une bonne partie de leurs textures en DXT5.
PVRTC
Passons maintenant à un format de compression de texture un peu moins connu, mais pourtant omniprésent dans notre vie quotidienne : le PVRTC. Ce format de texture est utilisé notamment dans les cartes graphiques de marque PowerVR. Vous ne connaissez peut-être pas cette marque, et c'est normal : elle ne crée par de cartes graphiques pour PC. Elle travaille surtout dans les cartes graphiques embarquées. Ses cartes se trouvent notamment dans l'ipad, l'iPhone, et bien d'autres smartphones actuels.
Avec le PVRTC, les textures sont encore une fois découpées en blocs de 4 texels par 4, mais la ressemblance avec le DXTC s’arrête là. Chacun de ces blocs est stocké en mémoire dans un bloc qui contient :
- une couleur codée sur 16 bits ;
- une couleur codée sur 15 bits ;
- 32 bits qui servent à indiquer comment mélanger les deux couleurs ;
- et un bit de modulation, qui permet de configurer l’interprétation des bits de mélange.
Les 32 bits qui indiquent comment mélanger les couleurs sont une collection de 2 paquets de 2 bits. Chacun de ces deux bits permet de préciser comment calculer la couleur d'un texel du bloc de 4*4.
Méthodes plus récentes
Il existe des format de texture plus récents, comme l'Ericsson Texture Compression ou l'Adaptive Scalable Texture Compression.
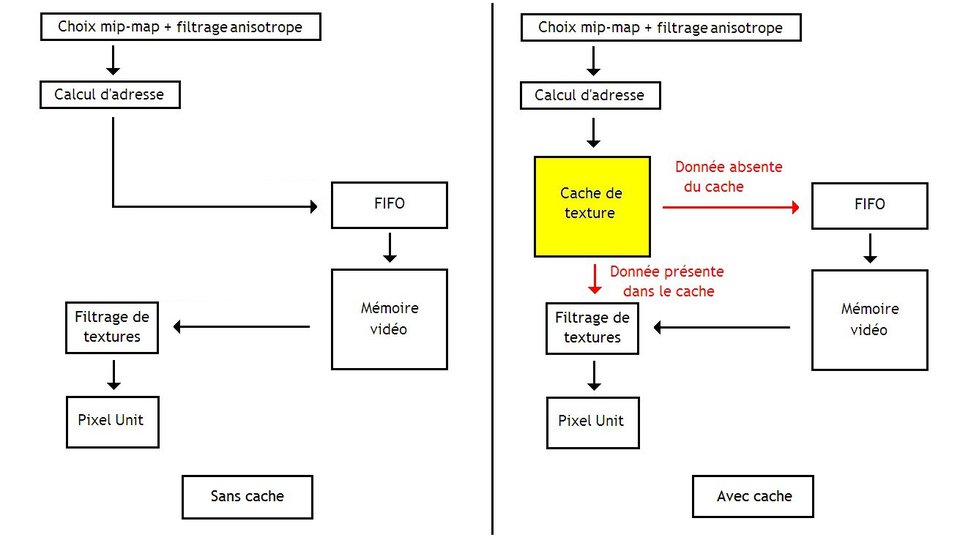
Texture cache
Les accès aux textures se font donc en mémoire vidéo. Seul problème : notre mémoire vidéo est lente. Pour faciliter l'accès aux textures, les cartes 3D utilisent souvent une ou plusieurs mémoires caches ultra-rapides, spécialisées dans le traitement des textures. Lorsqu'un texel est lu pour la première fois, celui-ci est placée dans ce cache de textures. Lors des utilisations ultérieures, la carte graphique aura juste à lire le texel depuis ce cache au lieu de devoir accéder à la mémoire vidéo, ce qui est nettement plus rapide.
Stockage des textures en mémoire
Ce cache est composé de blocs de mémoire de taille fixe, les lignes de cache, qui servent d'unité de base pour les échanges entre mémoire et cache. De base, les pixels d'une texture sont stockés les uns à la suite des autres, ligne par ligne. On pourrait croire que cette solution fonctionne bien pour échanger des données entre le cache de textures et la mémoire vidéo, mais en réalité, elle entre en conflit avec le filtrage de texture.
Comme on l'a vu précédemment, le filtrage de texture utilise souvent des carrés de texels. Dans ces conditions, mieux vaut découper la texture en carrés de N texels de coté, placés les uns à coté des autres en mémoire. Les performances sont les meilleurs possible quand chaque carré de texel permet de remplir exactement une ligne de cache.
D'ordinaire, les textures sont décompressées après lecture dans le cache. Il est possible de décompresser les textures avant de les placer dans le cache, mais ces textures décompressées prennent beaucoup plus de cache que les textures compressées. L'utilisation du cache est alors moins optimale.
Multi-level texture cache
Ceci dit, les cartes graphiques actuelles n'ont pas qu'un seul cache de textures. Toute les cartes graphiques actuelles disposent de deux caches de textures : un petit, et un gros. Les deux caches sont fortement différents. L'un est un gros cache, qui fait dans les 4 kibioctets, et l'autre est un petit cache, faisant souvent moins d'1 kibioctet.
Cohérence des caches
Dans la majorité des cas, le cache de textures est accessible uniquement en lecture, pas en écriture. Simple question de coût. Seulement, les jeux vidéos 3D récents utilisent des techniques dites de render-to-texture, qui permettent de calculer certaines données et à les écrire en mémoire vidéo pour une utilisation ultérieure. La présence d'une mémoire cache en lecture seule peut alors poser des problèmes : la modification d'une texture via render-to-texture n'est pas propagée dans le cache, qui conserve l'ancienne donnée.
Une solution simple consiste à garder un cache en lecture seule, et à invalider les données mises à jour lors d'une écriture. Si la carte graphique écrit dans la mémoire, le cache vérifie si la donnée dans le cache est mise à jour, l'invalide si c'est le cas. Pour cela, notre cache contient un bit pour chaque ligne, qui indique si la donnée est invalide, qui est mis à jour lors des écritures.
Cette technique peut être adaptée dans le cas où plusieurs mémoires de textures séparées existent sur une même carte graphique : les écritures doivent invalider toutes les copies dans tous les caches de texture. Cela nécessite d'ajouter des circuits qui propagent l'invalidation dans tous les autres caches.
Autre solution : rendre le cache de texture accessible en écriture. Si un seul cache de texture est présente dans la carte graphique, il n'y a pas besoin de modifications supplémentaires. Mais si il y en a plusieurs, le problème mentionné plus haut revient : les copies des autres caches doivent être invalidées. De plus, la mémoire cache qui a la bonne donnée doit fournir la bonne version de la donnée, quand les autres caches voudront la mettre à jour.
Prefetching
Avec l'organisation telle qu'on l'a vue, l'accès aux textures est lent : plusieurs centaines de cycles d'horloges si on lit depuis la mémoire vidéo, et environ 20 cycles si on lit dans le cache. Pour améliorer la rapidité des accès, il est possible d'utiliser un prefetch de texture. Avec ce prefetch, la carte graphique peut préparer certaines lectures de texture à l'avance.
Un accès à une texture est composé d'un grand nombre de sous-étapes. Par exemple, cette série d'étapes pourrait être :
- déterminer le niveau de mip-map ;
- effectuer des calculs pour le filtrage anisotropique ;
- calculer l'adresse effective en mémoire vidéo des texels à lire ;
- accéder à la mémoire ;
- filtrer les texels et les décompresser.
Le but du prefetching est d'effectuer à l'avance les étapes avant l'accès mémoire pour certaines requêtes de texture. Ainsi, pas besoin d'attendre qu'une lecture termine pour commencer à déterminer les mip-maps ou calculer l'adresse de la prochaine lecture : les adresses des texels sont précalculées. Les adresses précalculées sont mise en attente dans une petite mémoire tampon, en attendant que la mémoire vidéo soit libre. Cette mémoire tampon est une mémoire FIFO, une mémoire dans laquelle les données sont stockées dans leur ordre d'arrivée. Lors d'une lecture, la donnée arrivée en dernier est renvoyée.
Ce prefetch peut s'implémenter de deux façons, suivant que la carte graphique utilise ou non un cache de texture.