Bonjour
j’ai un petit soucis lié surement à l’encodage
J’ai un programme en cours de réalisation en python qui utilise GTk+ et un textview qui contient du texte avec des tags (tout cela enregistré dans une base de donnée) Lien GitLab du projet

Depuis quelque jour je suis sur la partie "Impression/Sauvegarde" de mes TextView (qui sont déjà dans une Base de donnée)
Je compte générer un fichier HTML et j’ai commencer à intégrer "BeautifulSoup"
format = self.buffer.register_serialize_tagset("application/x-gtk-text-buffer-rich-text")
data = self.buffer.serialize(self.buffer, format, self.buffer.get_start_iter(), self.buffer.get_end_iter())
print("[1] -> ",data)
data=str(data).split('<text_view_markup>', 1)
# data = data.decode("utf-8")
del data[0]
data[0] = '<text_view_markup>' + str(data[0])
data = data[0].split('</tags>', 1)
del data[0]
data = data[0].split('</text_view_markup>', 1)
print("[3] -> ",data)
data = str(data[0]).replace("\\n", '<br>')
print("[4] -> ",data)
soup = BeautifulSoup(data,features="lxml")
soupTags = soup.find_all('apply_tag')
for tag in soupTags:
if tag['name'] == 'bold':
tag.name = 'b'
del tag['name']
elif tag['name'] == 'italic':
tag.name = 'em'
del tag['name']
elif tag['name'] == 'underline':
tag.name = 'u'
del tag['name']
elif tag['name'] == 'size12':
tag.name = 'font size=12'
del tag['name']
elif tag['name'] == 'size15':
tag.name = 'font size=15'
del tag['name']
elif tag['name'] == 'red':
tag.name = 'font color="#FF0000";'
del tag['name']
print ("[5] -> ",soup)
Voici les sorties textes :
[1] -> b’GTKTEXTBUFFERCONTENTS-0001\x00\x00\x01\x82 <text_view_markup>\n <tags>\n <tag name="bold" priority="0">\n <attr name="weight" type="gint" value="700" />\n </tag>\n <tag name="size15" priority="14">\n <attr name="size" type="gint" value="15360" />\n </tag>\n </tags>\n<text><apply_tag name="size15"><apply_tag name="bold">Th\xc3\xa8me : Equipements / Lettre A :</apply_tag></apply_tag>\n\nNote pour la lettre A</text>\n</text_view_markup>\n'
et
[5] -> <html><body><br/><text><font size=15><b>Th\xc3\xa8me : Equipements / Lettre A :</b></font size=15><br/><br/>Note pour la lettre A</text><br/></body></html>
Comme vous le voyez ça n’est pas trop mal mais ensuite si je sauve ma sortie html, IMPOSSIBLE D’AVOIR LES BON ACCENTS sur le navigateur même si je rajoute une balise meta
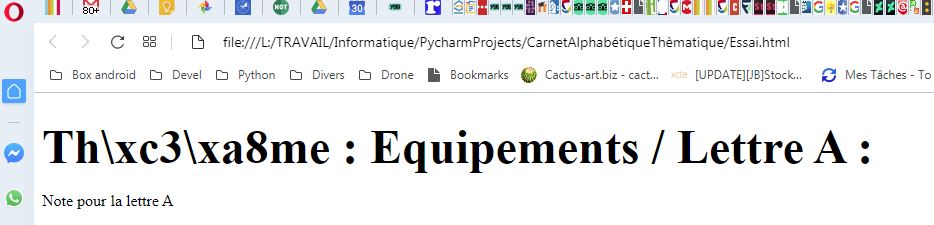
J’ai bien tenté de décoder l’utf-8 juste après le 'buffer.serialize' mais cela me donne des erreurs
Je cherche des pistes de solutions
Merci d’avance


