
Salutations !
Je suis Alex-D, développeur fullstack ayant notamment designé et intégré Zeste de Savoir dans sa première version.
Me faisant discret ces derniers temps par ici, je travaille sur plusieurs projets dont celui que je vais vous présenter ici : Colllect.
Ce projet est en cours de développement, ce qui est décrit ici est susceptible d’évoluer

Visiter la page de présentation de Colllect (en anglais)
Qu’est-ce que c’est ?
Il s’agit là d’une application Web Open Source de gestion visuelle de "marque pages" qui gère différent éléments : images (jpg, png, gif), notes (markdown), palettes de couleurs et évidemment des liens.
L’outil est principalement orienté vers le design et tout ce qui est graphique, mais est tout à fait utilisable pour d’autres usages, par exemple dans mon cas pour faire de la veille technique.
Le but est de pouvoir déposer des éléments, de les ranger dans des Colllections qui seront potentiellement collaboratives, d’appliquer des tags aux éléments, de pouvoir les filtrer…
Objectifs
Des outils du genre, il en existe tout un tas, notamment pas mal qui sont morts. Si vous en étiez utilisateur, vous avez perdu tout votre travail de veille et de recherche graphique. Colllect propose de tout baser sur des fichiers que vous stockez où bon vous semble. Pas de base de données "propriétaire" au format illisible. Tout est fait pour que l’on puisse gérer les bookmarks à partir de l’interface ou des fichiers eux-mêmes.
En résumé :
- c’est open source, licence MIT
- tout est fichier et lisible pour un humain
- l’interface et le stockage sont dissociables
- API REST ouverte
- pérennité de la veille
Du point de vue de l’utilisateur, comment ça marche ?
Stockage
Par défaut, nous proposons quelques Mo d’espace gratuits pour tester l’application. Pour aller plus loin il faudra choisir un stockage : Colllect (payant), Dropbox, (S)FTP. Nous prévoyons de rajouter d’autres services tels Google Drive, Amazon Drive… mais nous procédons par étape.
Tout étant fichier, vous pouvez profiter par exemple de "fonctionnalités" supplémentaire avec Dropbox par exemple : dans le train en étant hors ligne, mettez les fichiers dans votre Dropbox, une fois reconnecté à internet, accédez à l’interface de Colllect et vous y verrez les éléments que vous avez mis de côté 
Interface
Vous voulez tout héberger vous-même ? Téléchargez le zip depuis GitHub, suivez les instructions, vous voilà sur votre propre instance et vous pouvez vous reconnecter à votre Dropbox précédemment utilisée ou bien en local ou sur un autre (S)FTP…
Votre entreprise ne souhaite pas s’embêter avec l’installation et la maintenance d’une instance dédiée ni gérer le stockage : souscrivez un abonnement à notre application, nous gérons cela pour vous !
Du point de vue technique, comment ça marche ?
Pour l’instant, le back-end est écrit en PHP (pour la simplicité de déploiement pour les utilisateurs qui voudraient leur propre instance). J’utilise notamment Symfony et Flysystem. Optionnellement, un Redis pour le cache, sinon cache fichier.
Le back-end de l’application est une API REST, qui sera ouverte à qui le veut à terme, pour que chacun puisse développer des extensions / scripts ou que sais-je. Nous prévoyons nous-mêmes de développer des extensions pour navigateurs afin d’ajouter des choses facilement à vos colllections.
Stockage
Comme dit plus haut, tout est fichier. Il a fallu trouver une astuce pour réussir à faire tout fonctionner sans base de données. Ainsi le nom du fichier comporte le nom de l’élément, les tags et son extension défini son type.
Les colllections sont des dossiers. Rien de plus compliqué.
J’ai du mettre en place une grosse couche d’abstraction, notamment grâce à Flysystem, pour pouvoir manipuler indifféremment les différents types de stockage, actuellement : Dropbox, FTP, SFTP, Amazon AWS S3, local.
Interface
De ce côté c’est encore pas mal en travaux, mais on part sur du Vue.js + masonry, le tout responsive.
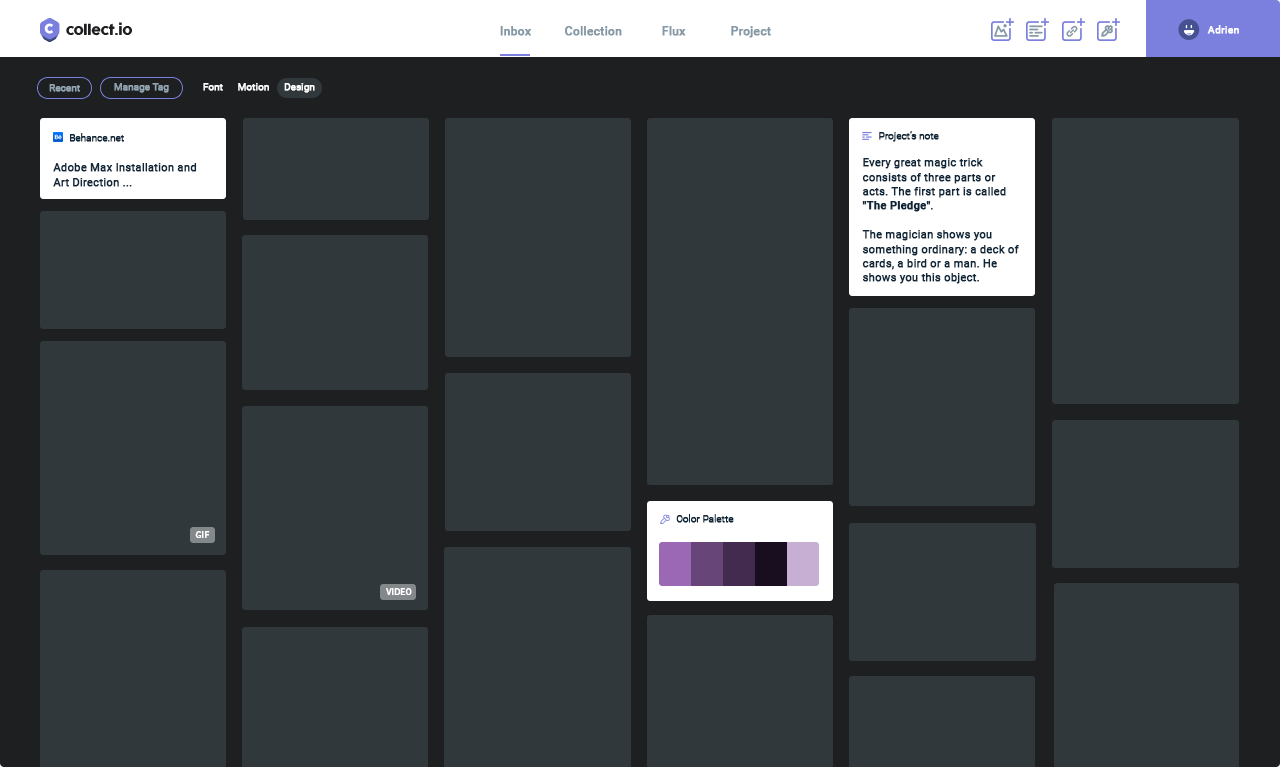
Pour en voir un peu plus sur l’interface, vous pouvez aller voir le projet Colllect sur le portfolio de mon compère Adrien Gervaix.
Vous avez dit Open Source ?
On s’est dit que c’était la meilleure façon de rendre le projet pérenne pour les utilisateurs. Si par malheur nous devions fermer notre instance, les utilisateurs pourront récupérer leur veille voire continuer d’utiliser l’outil en installant leur propre instance.
Community Edition vs Enterprise Edition
Pour l’instant on est partis sur l’idée du modèle de GitLab : le projet est Open Source, licence MIT. C’est la Community Edition. Puis, de notre côté on fait un fork pour créer l'Enterprise Edition. On y rajoute des fonctionnalités qui ont un coût important ou qui sont très lourdes à gérer au niveau de l’installation. Le but étant que l’installation de sa propre instance de Colllect (Community Edition, donc) se fasse très simplement : téléchargement du zip, dé-zip, upload sur son serveur, on suit quelques instructions => ça tourne !
A ce niveau là on a pas encore beaucoup creusé car on se concentre déjà à créer le noyau dur du projet qui sera la Community Edition.
Tout notre code est déjà sur GitHub ici : https://github.com/Colllect/Colllect
Conclusion
Encore une fois, tout ceci est sujet à évolutions, mais nous commençons à bien avancer \o/
J’essayerais de maintenir sur sujet à jour au fur et à mesure du développement.
Si vous avez des remarques / questions, n’hésitez pas, c’est aussi pour ça que je crée ce sujet !



 )
)

