Sortez une feuille et un crayon, contrôle surprise ! Comment cela, ce n’est pas crédible ? 
Nous avons vu que TCP permettait d’assurer le bon déroulement d’une transmission grâce à divers mécanismes. Nous allons détailler certains d’entre eux pour comprendre comment ce protocole fait pour assurer que les données parviennent en toute intégrité et de manière fluide.
Le contrôle de flux
Un des mécanismes proposés par TCP est le contrôle de flux. Il permet de réguler la vitesse de transmission au sein d’une session TCP.
Quel intérêt ? Ce qu’on veut, c’est aller le plus vite possible !
Cela peut sembler paradoxal, mais pour aller le plus vite, il ne faut pas se lancer à pleine vitesse. Sur une route, si toutes les automobiles se mettent à rouler à leur vitesse maximale, au moindre obstacle ou virage, cela va provoquer des freinages brusques, des ralentissements, des collisions… Et ce, même si la route est large ! Au final, entre celles qui ne sont jamais arrivées, celles qui sont parties très vite mais se sont retrouvées ralenties derrières d’autres très lentes ou dans les bouchons, et les quelques-unes qui s’en sont sorties, la vitesse moyenne est hasardeuse. Tandis que si tout le monde se met d’accord pour ne pas dépasser une vitesse donnée, disons 100 km/h, et pour que ceux qui ne peuvent pas atteindre cette vitesse restent sagement sur la file de droite, on aura une vitesse moyenne de 100 km/h pour les plus rapides, et une vitesse moyenne qui correspondra à leur vitesse maximale pour les plus lents. Et on évite ainsi bouchons et accidents !
Quel rapport avec le réseau ?
Au niveau transport, UDP ne contrôle pas sa vitesse. Quand un datagramme part sur le réseau, il part, point. Si un million de datagrammes veulent partir simultanément et que la machine de l’émetteur le permet, ils partiront. Le problème va se poser à l’arrivée. Que se passe-t-il si tout arrive en même temps chez un destinataire qui ne peut pas tout traiter, par exemple parce qu’il a déjà beaucoup de trafic à gérer ? Les premiers datagrammes pourront être traités, une partie pourra être stockée dans une mémoire tampon le temps d’écouler des flux, mais cette mémoire n’est pas illimitée. Une fois remplie, tout le reste est refusé par le destinataire et les données sont tout bonnement perdues. Nous avons vu précédemment qu’UDP n’est pas utilisé pour le transport de gros volumes pour ce genre de raisons.
TCP permet de pallier ce manque. Le contrôle de flux a pour but d’adapter la vitesse en fonction des performances du destinataire. Pour cela, 3 paramètres d’en-tête interviennent : le numéro de séquence, le numéro d’acquittement et la fenêtre.
Offsets | Octet | 0 | 1 | 2 | 3 | ||||||||||||||||||||||||||||
Octet | Bit | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 |
0 | 0 | Port source | Port destination | ||||||||||||||||||||||||||||||
4 | 32 | Numéro de séquence | |||||||||||||||||||||||||||||||
8 | 64 | Numéro d’acquittement | |||||||||||||||||||||||||||||||
12 | 96 | Taille en-tête | Réservé | E C N | C W R | E C E | U R G | A C K | P S H | R S T | S Y N | F I N | Fenêtre | ||||||||||||||||||||
16 | 128 | Somme de contrôle | Pointeur de données urgentes | ||||||||||||||||||||||||||||||
20 | 160 | Option(s) (facultatif) | |||||||||||||||||||||||||||||||
selon options | Données | ||||||||||||||||||||||||||||||||
Acquitté !
Voyons ce qui se passe du début à la fin d’une transmission. Lorsqu’une session TCP est initiée par un hôte A, un numéro de séquence est généré. Le plus souvent, il est aléatoire. Il est inclus dans l’en-tête. Comme c’est le tout début, il faut réaliser le 3-way handshake pour ouvrir la connexion. L’hôte A envoie donc un segment TCP ne contenant pas de données utiles mais seulement un en-tête, qui contient alors notamment un numéro de séquence (disons 3.000.000) et le flag SYN levé.
Offsets | Octet | 0 | 1 | 2 | 3 | ||||||||||||||||||||||||||||
Octet | Bit | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 |
0 | 0 | Port source | Port destination | ||||||||||||||||||||||||||||||
4 | 32 | Numéro de séquence : 3.000.000 | |||||||||||||||||||||||||||||||
8 | 64 | Numéro d’acquittement : 0 | |||||||||||||||||||||||||||||||
12 | 96 | Taille en-tête | Réservé | S Y N | Fenêtre | ||||||||||||||||||||||||||||
16 | 128 | Somme de contrôle | Pointeur de données urgentes | ||||||||||||||||||||||||||||||
Que se passe-t-il chez le destinataire, l’hôte B ? On suppose qu’il accepte la connexion et procède à la 2ème étape de la poignée de main. Il doit donc renvoyer un segment vide avec, dans l’en-tête, un numéro de séquence qui lui est propre. Celui-ci est totalement dissocié de celui de l’hôte A et peut être généré aléatoirement. Nous décidons arbitrairement que ce sera 15.000.000. Les drapeaux SYN et ACK sont levés, mais qu’est-ce qui est acquitté ? Il s’agit de la demande d’ouverture de connexion. Celle-ci est identifiée par le numéro de séquence du segment, en l’occurrence, 3.000.000. Pour que l’hôte A le sache, on le mentionne dans l’en-tête.
J’ai compris ! On va donc avoir la valeur 3.000.000 dans le champ ACK du segment !
Presque.  Nous avions évoqué cela dans le chapitre précédent : pour accuser réception d’un segment, on envoie le numéro qui correspond au prochain numéro de séquence attendu. Pour cela, on ajoute au numéro de séquence reçu le nombre d’octets utiles (de payload) reçus, ou bien 1 si le flag SYN, RST ou FIN est présent. Cela montre à l’expéditeur quel est le numéro de la prochaine séquence attendue, et par là même, que l’on a reçu toutes les séquences qui précèdent. Dans le cas présent, il n’y a pas de donnée utile mais le flag SYN est levé, on ajoute donc seulement 1. La valeur du champ ACK est ainsi 3.000.001.
Nous avions évoqué cela dans le chapitre précédent : pour accuser réception d’un segment, on envoie le numéro qui correspond au prochain numéro de séquence attendu. Pour cela, on ajoute au numéro de séquence reçu le nombre d’octets utiles (de payload) reçus, ou bien 1 si le flag SYN, RST ou FIN est présent. Cela montre à l’expéditeur quel est le numéro de la prochaine séquence attendue, et par là même, que l’on a reçu toutes les séquences qui précèdent. Dans le cas présent, il n’y a pas de donnée utile mais le flag SYN est levé, on ajoute donc seulement 1. La valeur du champ ACK est ainsi 3.000.001.
Offsets | Octet | 0 | 1 | 2 | 3 | ||||||||||||||||||||||||||||
Octet | Bit | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 |
0 | 0 | Port source | Port destination | ||||||||||||||||||||||||||||||
4 | 32 | Numéro de séquence : 15.000.000 | |||||||||||||||||||||||||||||||
8 | 64 | Numéro d’acquittement : 3.000.001 | |||||||||||||||||||||||||||||||
12 | 96 | Taille en-tête | Réservé | A C K | S Y N | Fenêtre | |||||||||||||||||||||||||||
16 | 128 | Somme de contrôle | Pointeur de données urgentes | ||||||||||||||||||||||||||||||
Ce système peut sembler abscons. Pourtant, ce simple système de calcul permet d’assurer l’acquittement d’un segment dans tous les cas. Les segments SYN ou FIN de poignée de main sans payload ? En ajoutant seulement 1, on est sûr de ne pas confondre un SYN ou un FIN avec un autre segment. Un accusé de réception se perd ? Le suivant assurera l’acquittement de tous les octets précédents et compensera la perte. Des données utiles se perdent ? S’il y a un « trou » dans le flux, le destinataire n’acquittera pas plus loin que le début du trou, permettant ainsi à l’expéditeur de savoir quoi renvoyer. Ces cas seront détaillés tout au long de ce chapitre.
Dans la 3ème phase de la connexion TCP, c’est à A d’envoyer un ACK à B. Comme B a envoyé un ACK de 3.000.001, cela signifie qu’il s’attend à recevoir un segment commençant par ce numéro de séquence. De plus, B a envoyé un numéro de séquence de 15.000.000. Comme il n’y a pas de données utiles mais seulement un SYN, A doit donc s’attendre à ce que la prochaine séquence provenant de B sur cette session porte le numéro 15.000.001. Cela nous donne l’en-tête suivant :
Offsets | Octet | 0 | 1 | 2 | 3 | ||||||||||||||||||||||||||||
Octet | Bit | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 |
0 | 0 | Port source | Port destination | ||||||||||||||||||||||||||||||
4 | 32 | Numéro de séquence : 3.000.001 | |||||||||||||||||||||||||||||||
8 | 64 | Numéro d’acquittement : 15.000.001 | |||||||||||||||||||||||||||||||
12 | 96 | Taille en-tête | Réservé | A C K | Fenêtre | ||||||||||||||||||||||||||||
16 | 128 | Somme de contrôle | Pointeur de données urgentes | ||||||||||||||||||||||||||||||
Maintenant, si A transmet sur cette session le message « Bonjour », le numéro de séquence sera toujours 3.000.001. La valeur du ACK ne bouge pas, vu que A s’attend toujours à recevoir la séquence 15.000.001.
Offsets | Octet | 0 | 1 | 2 | 3 | ||||||||||||||||||||||||||||
Octet | Bit | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 |
0 | 0 | Port source | Port destination | ||||||||||||||||||||||||||||||
4 | 32 | Numéro de séquence : 3.000.001 | |||||||||||||||||||||||||||||||
8 | 64 | Numéro d’acquittement : 15.000.001 | |||||||||||||||||||||||||||||||
12 | 96 | Taille en-tête | Réservé | A C K | P S H | Fenêtre | |||||||||||||||||||||||||||
16 | 128 | Somme de contrôle | Pointeur de données urgentes | ||||||||||||||||||||||||||||||
Bonjour | |||||||||||||||||||||||||||||||||
B reçoit ce segment et l’acquitte. Comme prévu, cette séquence porte le numéro 15.000.001. La valeur de l’ACK est augmentée du nombre d’octets utiles reçus, soit 7. L’ACK vaut donc 3.000.008. Quand A va le recevoir, il comprendra que toutes les données émises avant la séquence 3.000.008 ont bien été reçues. Il peut donc continuer ses envois sans souci.
À quoi sert le PSH dans l’en-tête ?
Quand un segment TCP porte le drapeau PSH (push), cela indique que les données doivent être traitées par l’application de destination immédiatement. Il n’y a pas lieu d’attendre une suite pour pouvoir traiter l’information, et donc le segment ne doit pas rester en mémoire tampon.
Derrière les fenêtres…
Les éléments que nous venons de voir sont à la base du contrôle de flux, mais ils ne peuvent pas réguler la vitesse d’un flux tous seuls. La fenêtre vient les aider.
Nous avons évoqué en début de cette section une mémoire tampon. Elle permet de stocker des paquets reçus sur le réseau en attendant qu’ils soient traités par les applications. Si elle est remplie, les données qui arrivent ne pourront pas être retenues par le système et seront alors perdues. La fenêtre est un champ de l’en-tête TCP qui permet de renseigner l’état de cette mémoire. Dans chaque segment envoyé, le système renseigne la quantité de données qu’il peut garder en stock à un instant donné pour la session. L’interlocuteur ne doit alors pas envoyer davantage d’octets utiles tant qu’au moins une partie n’a pas été acquittée.
Ainsi, si l’hôte B a informé l’hôte A que sa fenêtre est de 900 octets, l’hôte A peut envoyer 3 segments de 300 octets chacun, mais pas davantage. Il doit attendre un acquittement pour être sûr que le tampon de son interlocuteur a commencé à se vider. Lorsque A reçoit l’acquittement du premier segment, il sait que le tampon s’est libéré de 300 octets et peut donc envoyer un segment supplémentaire (on suppose que la fenêtre ne varie pas). Cela permet de maintenir une vitesse d’émission stable, comme on peut le voir sur l’exemple ci-dessous.
Dans l’illustration suivante, on considère que la connexion TCP est déjà établie et que B a informé A que sa fenêtre est de 900. On suppose que cette valeur ne varie pas et que chaque segment contient 300 octets de données utiles.
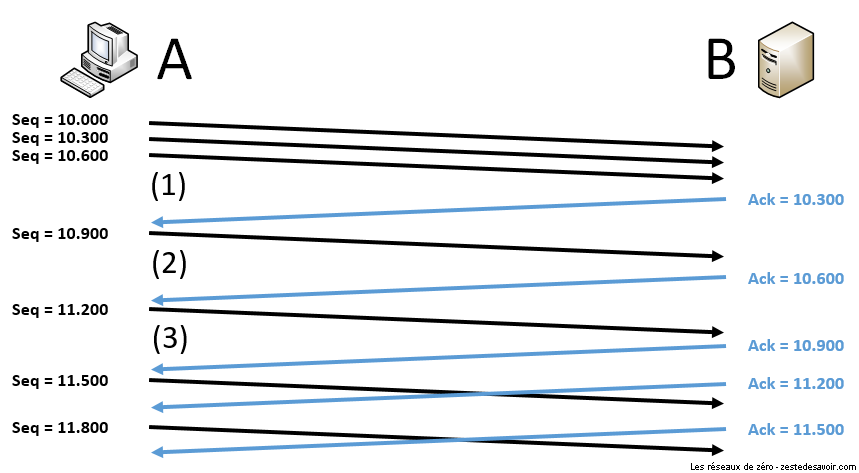
Cet échange montre qu’au début, A envoie des segments beaucoup plus vite que B ne peut les traiter. Le pauvre est très sollicité et ne peut pas répondre immédiatement ! A est contraint de ralentir la cadence et d’attendre patiemment de recevoir un accusé de réception avant de continuer. Cela stabilise la vitesse de l’échange.
On parle aussi de fenêtre glissante (sliding window), car on peut la voir comme une zone qui se déplace le long du flux de données à envoyer. Sur l’illustration ci-dessous, la flèche représente tout ce qui doit être envoyé dans la session TCP. Des traits sont placés tous les 300 octets, le nombre en dessous étant le numéro de séquence correspondant au segment. La fenêtre est représentée en orange et fait toujours 900 octets. On peut voir que sa position évolue entre les points (1), (2) et (3) qui font référence aux points indiqués dans l’illustration précédente.

Ce procédé de contrôle de flux permet ainsi de gérer la transmission au niveau d’une session TCP. Il ne prend pas en compte les éléments qui peuvent gêner la communication sur le réseau : c’est le rôle du contrôle de congestion.
Le contrôle de congestion
Il peut arriver que des données se perdent et n’arrivent pas à destination. Cela se produit notamment lorsque des routeurs, qui font transiter les paquets sur le réseau, sont surchargés. C’est ce qu’on appelle la congestion. Ce phénomène se produit au niveau réseau. Pourtant, c’est TCP qui doit se débrouiller pour gérer cette problématique, alors que c’est un protocole de transport. Si le modèle OSI, voire le modèle TCP/IP, était strictement respecté, ce devrait être au protocole IP de s’y coller… Mais non, il n’a pas été conçu comme ça. Qu’à cela ne tienne !
TCP utilise plusieurs mécanismes pour éviter la congestion. Nous n’en verrons que quelques-uns ici afin que vous appreniez les bases du sujet.
Le premier : Tahoe
C’est en 1988 qu’un premier algorithme a été implémenté dans TCP pour tenter de gérer la congestion. Son nom : Tahoe. Il n’est pas extrêmement performant mais comme il est relativement simple, nous allons l’étudier pour poser quelques bases.
Commençons par définir plusieurs variables. La première sera la fenêtre de congestion. Attention, rien à voir avec la fenêtre du contrôle de flux ! La fenêtre de congestion, en anglais congestion window et souvent abrégée cwnd, c’est un paramètre utilisé par le programme qui gère les connexions TCP. Il n’est pas visible, on ne le retrouve pas dans les champs du protocole. Cette variable sera utilisée pour tester différentes vitesses de transmission.
Un autre paramètre est le seuil de démarrage lent, plus connu sous le nom de slow start threshold et abrégé ssthresh. C’est une valeur arbitraire, souvent fixée par défaut à 2^16 – 1, soit 65535.
L’algorithme Tahoe définit deux phases : slow start (démarrage lent) et congestion avoidance (évitement de congestion).
Slow Start
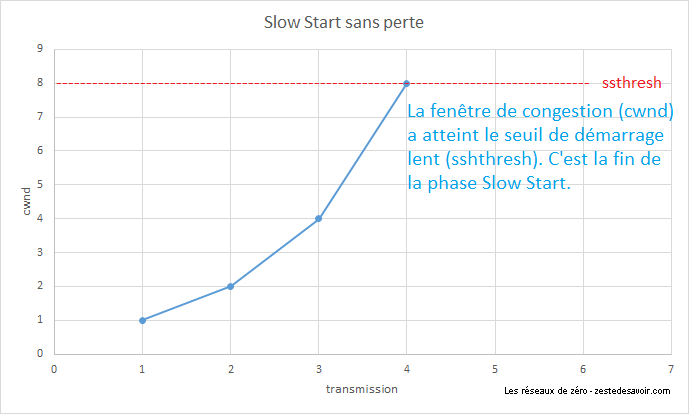
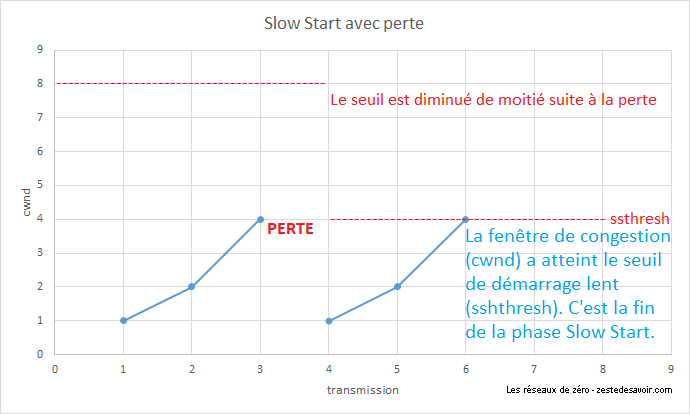
Pour commencer, on attribue à la fenêtre de congestion (cwnd) la valeur 1. Cela veut dire que l’on n’envoie que 1 segment rempli au maximum, c’est-à-dire 1 fois la taille maximale d’un segment (Maximum Segment Size, MSS), et on attend de recevoir un accusé de réception. Quand ce dernier est reçu, on double cwnd. On se permet donc d’envoyer 2 fois le MSS avant d’attendre l’acquittement. Une fois reçu, on double encore cwnd, et ainsi de suite. En cas de perte, le seuil ssthresh est abaissé à la moitié de la dernière cwnd. La fenêtre repart à zéro, et on recommence, jusqu’à ce que la valeur de la fenêtre dépasse le seuil. Ensuite, on quitte le mode slow start pour passer en collision avoidance.
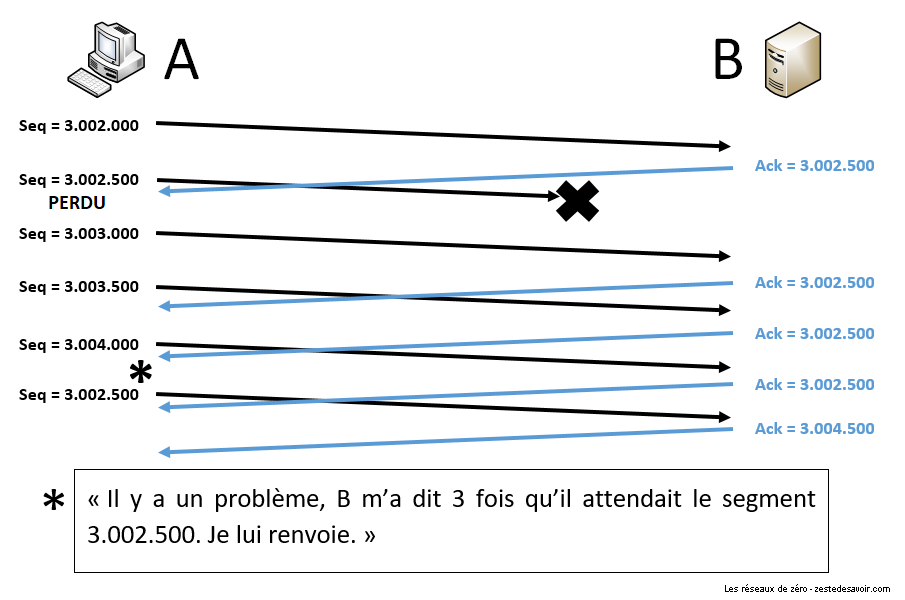
Comment identifie-t-on une perte ?
Il y a 2 cas de figure. Soit on ne reçoit pas du tout d’accusé de réception et on considère que le paquet est perdu après un temps défini : le RTO (Retransmission TimeOut), qui est de l’ordre de la seconde. Soit, au contraire, on reçoit des accusés de réception, mais avec un ACK qui ne bouge pas. Cela signifie que le destinataire continue de recevoir des segments, mais ne peut pas les interpréter car il en manque un morceau, qui est celui désigné par le champ ACK number. Dans ce cas, au bout du 3ème accusé de réception identique, TCP comprend qu’il y a un problème avec ce segment et reprend la transmission à ce niveau-là. C’est ce qu’on appelle fast retransmission.
Revenons à notre Slow Start. L’illustration suivante représente l’évolution de la fenêtre de congestion au fur et à mesure des transmissions. Pour toutes les images qui suivent, le terme « transmission » désigne une salve de segments envoyés en même temps. La ligne rouge en pointillés représente le seuil de démarrage lent.
Si une perte est constatée avant d’avoir atteint le seuil, celui-ci est divisé par deux et la fenêtre de congestion retombe à 1.
Congestion Avoidance
Une fois que la fenêtre a dépassé le seuil, cela signifie que nous ne sommes plus très loin de la vitesse maximale possible. Nous savons a priori que nous ne pouvons plus doubler la valeur de la fenêtre (sauf si le seuil de base a été dépassé). On passe alors en phase congestion avoidance. Le paramètre cwnd est alors augmenté de 1 à chaque fois, jusqu’à la prochaine perte. Cela permet d’estimer finement une vitesse de transmission maximale. Lorsqu’une perte est constatée, le seuil ssthresh est modifié et prend pour valeur la moitié de la dernière fenêtre. La cwnd est remise à 1 et on reprend en mode slow start.
L’illustration suivante intègre le slow start, en trait bleu continu, et la congestion avoidance, en pointillés verts.
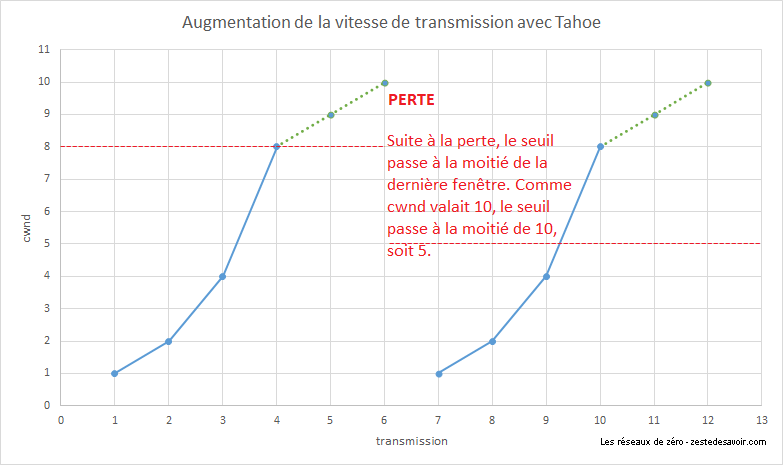
Ce système a le mérite de poser de bonnes bases du contrôle de congestion, mais on visualise bien vite ses limites. Le passage en mode slow start à chaque perte provoque une chute brusque du débit, qui met à chaque fois du temps pour revenir à la vitesse d’avant. Il n’est pas possible d’avoir une transmission rapide sans variations régulières. Pour tenter de pallier ces problèmes, un nouvel algorithme a vu le jour 2 ans plus tard : Reno.
Reno
Cet algorithme reprend le même mode de fonctionnement que Tahoe, mais il y ajoute le principe de fast recovery. Ce mode se déclenche quand un hôte reçoit 3 accusés de réception identiques, indiquant une perte. Quand ce cas se produit, la valeur de la fenêtre est réduite de moitié. Cette nouvelle valeur devient aussi le nouveau seuil ssthresh. Une fast retransmission est opérée, et l’augmentation linéaire de la fenêtre reprend. Cela permet de réduire les variations de débit en évitant de retomber en slow start à la moindre perte. Toutefois, ce mode se réactivera en l’absence totale d’acquittement après le RTO.
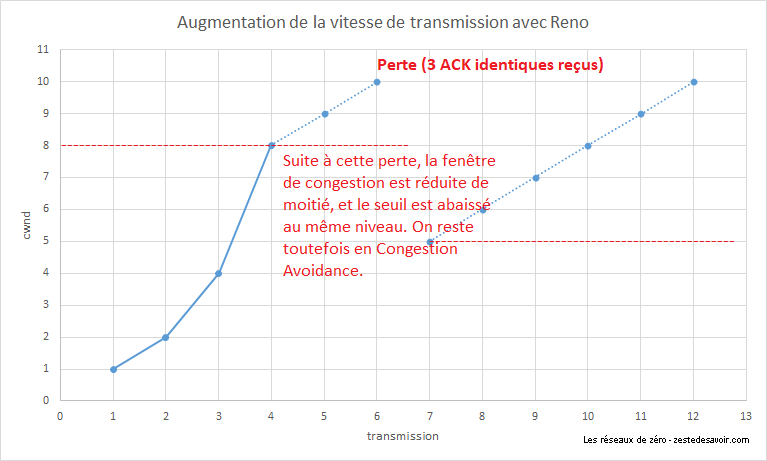
Reno, ainsi que son évolution, NewReno, ont été beaucoup utilisés dans les années 1990 et au début des années 2000. De nombreux autres ont été inventés. D’autres approches ont été tentées, avec plus ou moins de succès. Les algorithmes Vegas et Westwood+ se basaient sur le temps de transit aller-retour des segments (round time trip, RTT) pour ajuster au mieux la fenêtre de congestion. Tous ont été rendus obsolètes par l’augmentation globale des débits.
Depuis 2006, Microsoft utilise Compound TCP comme algorithme de contrôle de congestion pour ses systèmes Windows, tandis que Linux utilise CUBIC. On ne trouve quasiment pas de documentation à leur sujet en français, si ce n’est leurs pages Wikipédia qui sont assez sommaires. Pour plus de détails, et ce sera en anglais, vous pouvez vous référer à ce papier très complet de Microsoft pour Compound TCP, ou, pour CUBIC, à ce document de l’université d’État de Caroline du Nord ou encore à la RFC 8312 (contrairement à la plupart des RFC, celle-ci est une notice d’information et non une spécification).
Modification du protocole
En plus des algorithmes, le protocole TCP lui-même a été adapté pour faciliter le contrôle de congestion. Reprenons l’en-tête TCP. Nous pouvons voir au niveau des drapeaux les 3 éléments suivants : ECN, CWR et ECE. Leur fonctionnement est particulièrement astucieux.
La congestion survenant au niveau réseau, quoi de plus à même de signaler la congestion qu’un routeur ? Seulement, un routeur ne doit pas interférer avec des protocoles plus hauts que la couche réseau. Le principe ECN, pour Explicit Congestion Notification (notification de congestion explicite), tente de faire passer l’information d’une couche à une autre.
Les routeurs qui supportent l’ECN peuvent, s’ils commencent à saturer, le faire savoir directement dans les paquets IP, notamment ceux qui font circuler les flux TCP. Pour cela, ils vont modifier dans l’en-tête IP un champ particulier. Comme nous n’en sommes pas encore à la couche 3 dans notre cours, nous ne rentrerons pas dans les détails. Cela permet au destinataire d’être informé d’une congestion. Ce dernier, s’il supporte cette fonctionnalité, va en informer l’expéditeur en levant le drapeau ECE (ECN Echo) dans ses acquittements TCP. L’expéditeur, quand il verra ce flag, va réduire de lui-même sa vitesse d’émission, selon les algorithmes dont il dispose. Une fois cela fait, il positionne à 1 le flag CWR (Congestion Window Reduced, fenêtre de congestion réduite) pour informer le destinataire qu’il a bien reçu l’information et qu’il a pris les mesures appropriées. Le drapeau ECE peut alors être éteint pour la suite des acquittements.
L’illustration suivante suppose que tous les équipements impliqués supportent ECN. Nous partons du principe que la connexion TCP a déjà été initialisée et qu’une congestion est détectée par le routeur (au milieu) lors de la transmission du deuxième segment. On suppose aussi que tout ce matériel peut parler, parce que c’est quand même beaucoup plus simple quand les objets peuvent s’exprimer. 
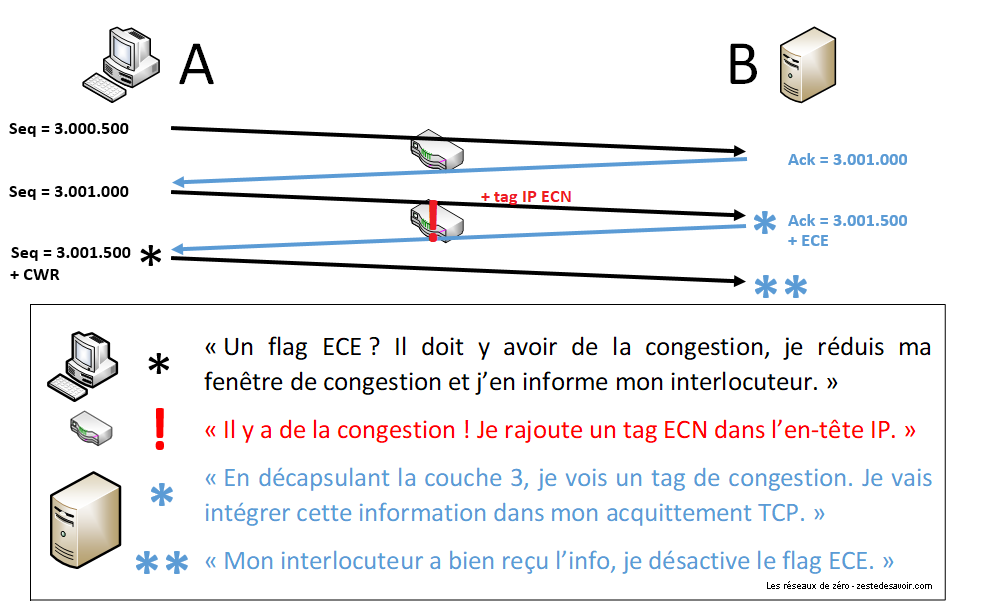
Lors de l’établissement de la connexion TCP, les hôtes se disent dès le départ s’ils supportent l’ECN. Bien que cette amélioration existe depuis 2001, son adoption à grande échelle s’est faite au milieu des années 2010. Si l’un des deux hôtes ne l’implémente pas ou ne l’a pas activée, l’autre ne cherchera pas à l’utiliser.
Nous avons vu avec le contrôle de congestion que de nombreux mécanismes ont été inventés pour fluidifier au maximum les communications. Cela ne garantit toutefois pas que les données arriveront intègres. Pour cela, on peut utiliser des algorithmes de somme de contrôle.
Le principe de la somme de contrôle
Cette sous-partie ne sera rien d’autre qu’une petite introduction à la somme de contrôle. Nous ne voulons pas aborder les notions importantes trop rapidement, aussi nous avons préféré consacrer un autre chapitre à la somme de contrôle ainsi qu’à ses différents algorithmes.
C’est quoi, une somme de contrôle ?
La somme de contrôle est un mécanisme utilisé par un protocole afin de détecter des erreurs et de s’assurer que le message reçu est bien intègre, c’est-à-dire qu’il n’a pas subi de modification.
Le principe par l’analogie (encore et toujours)
Une fois de plus, nous allons simplement voir en quoi consiste ce principe avec un exemple. Vous vous souvenez de l’exemple avec les cousins et les enveloppes ?
Pour vous rafraichir la mémoire, nous avons dit que les cousins de « Maison-Est » écrivaient des lettres aux cousins de « Maison-Ouest ». Les lettres étaient dans des enveloppes, et leur grand frère Pierre les collectait afin de les déposer au bureau de poste, qui à son tour, se chargerait de les envoyer dans Ville-Ouest. Si vous ne vous souvenez plus du scénario, vous pouvez relire le début du chapitre précédent.
Nous avons également dit qu’il n’était pas possible de nous assurer que les lettres ne seraient pas modifiées par quelqu’un au niveau de la Poste, n’est-ce pas ? Alors si Junior, un cousin dans Ville-Est, veut s’assurer que Robert, dans Ville-Ouest, reçoive la lettre dans son intégralité, comment peut-il faire ?
Après avoir réfléchi, il décide d’inscrire un motif précis dans la lettre. Il appelle Robert : « Dans ma lettre, à la fin de chaque paragraphe, j’ai mis « it ». Si un paragraphe ne se termine pas par « it », c’est que quelqu’un a modifié cette lettre » (c’est un peu bête et pas fiable, mais l’idée est là ).
La lettre est envoyée et Robert la reçoit. Il s’empresse de vérifier si chaque paragraphe se termine par « it ». Si c’est le cas, alors on peut supposer que la lettre est bien arrivée dans son intégralité. Sinon, il y a eu des erreurs de transmission. 
La somme de contrôle ne peut pas garantir la détection d’erreur à 100% (surtout dans notre exemple bidon). Voilà pourquoi il y a plusieurs algorithmes de calcul de cette somme. Chacun a ses avantages.
En réseau, c’est cela le principe de base de la somme de contrôle. Un protocole (UDP, TCP ou même un autre d’une autre couche) va, par une fonction de computation de somme de contrôle, générer une valeur précise. Cette valeur sera inscrite dans le champ « somme de contrôle (checksum) » du protocole utilisé. Lorsque les données arriveront au destinataire, le même protocole va également computer la somme de contrôle avec le même algorithme et comparer la valeur obtenue à celle qui se trouve dans le champ « somme de contrôle » de l’en-tête du paquet. Si les deux valeurs sont les mêmes, alors les données sont intègres, sinon, il y a eu des erreurs de transmission.
Schématiquement, voici comment ça se passe :
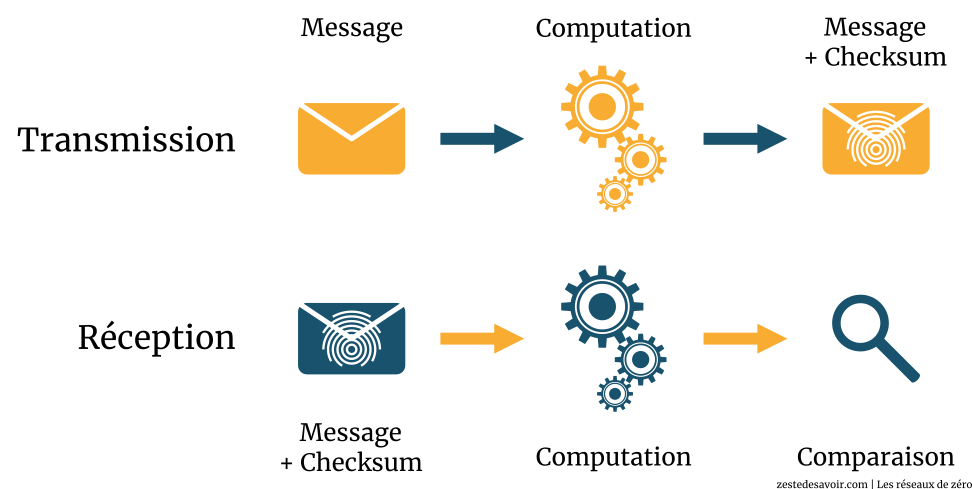
La somme de contrôle permet uniquement de détecter les erreurs de transmission et non de les corriger.
Exemple de computation abstraite
Nous allons essayer de vous expliquer la somme de contrôle par une illustration.
Nous allons implémenter une computation abstraite. C’est juste pour vous donner un exemple, ce n’est même pas proche de la réalité. Mais on reprend juste le principe et notre but c’est de vous faire comprendre le principe, et non de vous expliquer les détails techniques que nous réservons pour l’annexe consacrée au sujet.
L’hôte A désire envoyer un fichier contenant le message « Salut Pierrot » à l’hôte B. Au niveau de la couche transport, un mécanisme de computation de somme de contrôle est effectué et sa valeur est F00XTT01. L’hôte A a utilisé l’application ClemNet qui a pour numéro de port 56890 (au hasard) et utilise le protocole TFTP avec comme numéro de port de destination 69.
TFTP utilise UDP comme protocole de transmission.
Construisons notre segment UDP.
Nous allons ignorer la valeur du champ « longueur » (length) pour cet exercice. Nous y reviendrons dans le chapitre suivant, pour le moment ce n’est pas important.
Voici à quoi ressemblera notre segment UDP :
Bits | 0 - 15 | 16 - 31 |
|---|---|---|
0 | 56890 | 69 |
32 | Length | F00XTT01 |
64 | Salut Pierrot | |
Lorsque l’hôte B va recevoir ce message, il va lui aussi computer une somme de contrôle. La computation lui retourne la valeur F00XTT01. Il regarde alors le champ « checksum » (somme de contrôle) dans l’en-tête du segment reçu et compare :
| Checksum reçue | Checksum calculée |
|---|---|
| F00XTT01 | F00XTT01 |
UDP constate alors que c’est pareil, donc le message est bien intègre, aucune erreur de transmission ne s’est produite.
Par contre si les deux sommes de contrôle ne sont pas les mêmes, alors il y a eu une ou plusieurs erreurs de transmission entre l’instant où l’hôte A a envoyé le message, et l’instant où l’hôte B l’a reçu.
Voici un schéma pour résumer ces étapes :
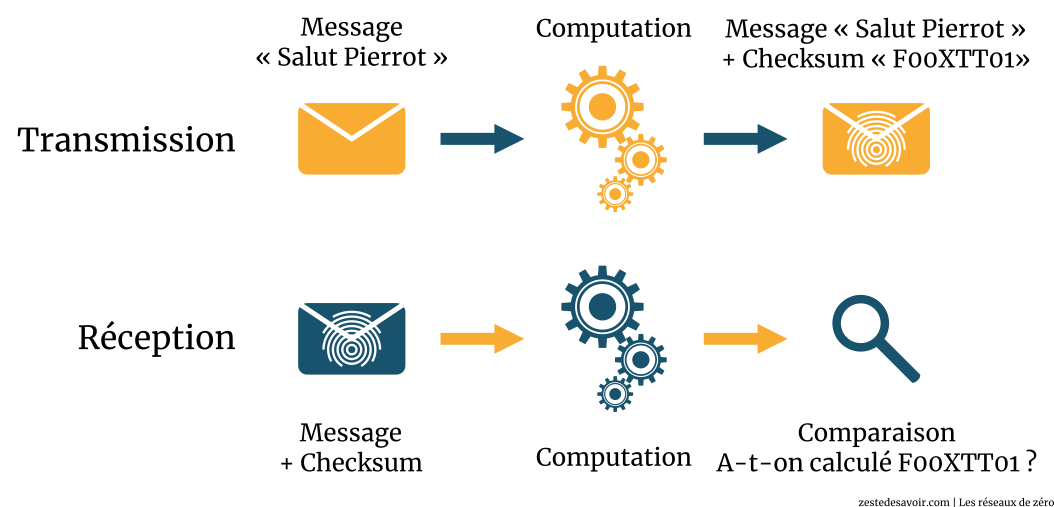
Cet exemple est très, très simplifié. Le but est de vous faire comprendre le principe (d’où le titre de la sous-partie).
Vous avez réussi à appréhender toutes ces notions ? Bravo, vous méritez un 20/20 !  Si le contrôle de flux n’est pas trop difficile à comprendre quand on connait un minimum TCP, le contrôle de congestion a de quoi déboussoler. Le principe est intéressant, après, il n’est pas indispensable de s’arracher les cheveux pour saisir le détail de chaque algorithme. C’est pour cela que nous n’en avons vu que les bases.
Si le contrôle de flux n’est pas trop difficile à comprendre quand on connait un minimum TCP, le contrôle de congestion a de quoi déboussoler. Le principe est intéressant, après, il n’est pas indispensable de s’arracher les cheveux pour saisir le détail de chaque algorithme. C’est pour cela que nous n’en avons vu que les bases.
Nous venons aussi d’aborder le principe de la somme de contrôle. Si vous souhaitez aller plus loin, une annexe est disponible à ce sujet. Sa lecture est facultative pour suivre le reste du cours.