Après une longue introduction, l’heure est à l’exploration de la couche transport ! Au menu : rôti de porc découverte des ports, multiplexage et sockets. Bon appétit !
Appelle mon numéro... de port
Les numéros de port : késaco ?
Déjà, qu’est-ce qu’une adresse IP ? Vous vous en souvenez ? C’est une adresse unique assignée à un hôte pour permettre de distinguer chaque hôte dans des réseaux. Vous vous en souveniez, bien sûr.
Qu’est-ce qu’une adresse physique (MAC) ? C’est une adresse associée à la carte réseau d’un hôte pour distinguer les hôtes dans un réseau local. Jusque-là, pas de problème.
Ces deux adresses ont-elles quelque chose en commun ? Oui, elles servent toutes les deux à identifier un hôte. 
Un numéro de port sert également à identifier quelque chose. Mais ce quelque chose est une application. Le numéro de port est donc le numéro qui nous permet de faire la distinction entre les applications. Nous savons déjà que la couche transport établit une communication bout-à-bout entre les processus d’applications. Alors comment faire pour distinguer les nombreux processus d’une application qui sont en fait des services exécutés sur une machine ? C’est le numéro de port qui permettra de les différencier.
Par exemple, nous avons vu que, dans la transmission d’un mail, le premier service ou la première application utilisée est un MUA. Le MUA utilise le protocole SMTP pour envoyer le mail au serveur de messagerie souvent en passant par un MSA. Dans l’ordre de réception, on utilisait également un autre MUA pour retirer le mail du serveur de messagerie avec un protocole de réception comme IMAP ou POP. Il se peut donc que les deux services (POP/IMAP et SMTP) soient exécutés au même moment sur une même machine hôte. C’est là qu’intervient le numéro de port, parce qu’il nous permet de faire la distinction entre les services qui ont été demandés par l’application distante, qu’il s’agisse d’un serveur de messagerie ou d’un client de messagerie. Le protocole SMTP utilise le protocole TCP pour la transmission au numéro de port 25.
L’organisme IANA (Internet Assigned Numbers Authority) (en) classe les numéros de port en trois catégories principales, comme l’illustre le tableau ci-dessous.
| Portée | Catégorie | Description |
|---|---|---|
| 0 - 1023 | Ports bien connus | Ports réservés pour des services bien connus (web, envoi de mail, etc.). |
| 1024 – 49 151 | Ports réservés | Ports réservés pour être utilisés par des applications propriétaires. |
| 49 152 – 65 635 | Ports dynamiques | Ports « libres » que vous pouvez utiliser pour vos applications. Ils ne sont ni pour des services bien connus, ni réservés par une entreprise quelconque. |
Voici quelques ports bien connus :
| Protocole | Description | Protocole de transmission | Numéro de port | Statut d’assignation |
|---|---|---|---|---|
| File Transfert Protocol (FTP) | Protocole de transfert de fichier | TCP | 21 | Officiel |
| Secured SHell (SSH) | Protocole permettant l’échange de données par le biais d’un canal sécurisé | TCP & UDP | 22 | Officiel |
| Telnet | Utilisé pour l’établissement des sessions à distance | TCP | 23 | Officiel |
| Simple Mail Transfer Protocol (SMTP) | Protocole d’envoi de courrier électronique | TCP | 25 | Officiel |
| WHOIS protocol | Protocole ou service utilisé pour l’identification d’une machine par son nom de domaine ou son adresse IP. La procédure d’identification se fait par une requête envoyée à un des registres Internet pour obtenir des informations. | TCP | 43 | Officiel |
| Domain Name System (DNS) | Protocole de résolution des noms de domaine | TCP & UDP | 53 | Officiel |
| HyperText Transfer Protocol (HTTP) | Protocole de téléchargement (principalement de pages web) | TCP & UDP | 80 | Officiel |
| Post Office Protocol Version 2 (POP2) | Protocole de retrait de mails d’un serveur de messagerie | TCP | 109 | Officiel |
| Post Office Protocol Version 3 (POP3) | Protocole de retrait de mails d’un serveur de messagerie | TCP | 110 | Officiel |
| Internet Message Access Protocol (IMAP) | Protocole de retrait et consultation de mails d’un serveur de messagerie | TCP & UDP | 143 | Officiel |
| … | … | … | … | … |
Il y a tellement de protocoles que nous ne pouvons pas tous les énumérer. Voici une liste des numéros de port (en).
Expliquons quelques en-têtes de ce tableau avant de clore cette section.
- Statut d’assignation : le statut officiel veut dire que le couple application / numéro de port a été enregistré dans les registres de l'IANA. En d’autres termes, il est défini par une convention que telle application utilise tel numéro de port. Il y a également des applications qui utilisent des numéros de port non officiels, mais nous ne les avons pas listées. Vous pourrez les trouver en suivant le lien que nous vous avons donné.
- Protocole de transmission : vous devez normalement savoir que les protocoles peuvent s’utiliser entre eux. Le protocole SMTP qui sert à envoyer un mail s’appuie sur le protocole TCP pour le transmettre. On parle de sous-couchage de protocoles (underlayering protocols). Vous pouvez voir que certains protocoles n’utilisent que TCP ou UDP alors que d’autres peuvent utiliser les deux, c’est au choix.
Les notions autour du numéro de port
Les ports sont un concept très important en réseau. Grâce à ces derniers, nous pouvons faire beaucoup de choses très utiles et intéressantes. Nous allons voir quelques-unes de ces notions qui gravitent autour des ports. Pour l’instant, nous allons vous en fournir une brève description pour la culture. Plus de détails dans la (future) partie du cours consacrée aux services.
La redirection de port (port forwarding)
Le port forwarding ou encore port mapping permet à un hôte d’un réseau distant (Internet par exemple) de communiquer avec un hôte d’un réseau local en faisant transiter les paquets par une machine tel qu’un routeur. L’intérêt est que l’hôte local n’est pas directement sollicité par d’autres, une machine fait le relai et peut ainsi servir de filtre.
Le scan de port (port scanning)
Le scan ou balayage de port est une technique très populaire en réseau et surtout en sécurité. Cette technique consiste à « scanner » un hôte afin de découvrir les ports ouverts et d’avoir la liste des services exécutés sur cet hôte. Connaître les ports ouverts et les services exécutés permet à un pirate, par exemple, d’exploiter les vulnérabilités des services afin de planifier une attaque. 
Déclenchement de port (port triggering)
Le port triggering consiste, comme son nom l’indique, à déclencher quelque chose. Cette technique permet de déclencher l’ouverture d’un port précis. Le port triggering ne se produit donc que lorsqu’un événement déclencheur particulier a lieu. Par exemple, l’ouverture d’une connexion sur le port 60000 va déclencher une redirection de port.
PAT : Port Address Translation
PAT permet à plusieurs hôtes dans un réseau local d’utiliser une même adresse IP d’un réseau public. On l’utilise dans le même but que le subnetting, c’est-à-dire pour mieux gérer les adresses disponibles. PAT est une technique qui opère dans les couches 3 et 4 du modèle OSI. L’un des défauts de cette technique est la complexité que cela implique au niveau du pare-feu ou du routeur qui l’implémente : il doit jongler avec les numéros de ports pour suivre les communications en cours et éviter de confondre plusieurs hôtes.
Multiplexing / demultiplexing
Dans le chapitre précédent, nous vous avons dit que nous ne pouvions pas parler du multiplexing / demultiplexing (en français : multiplexage / démultiplexage) sans aborder la notion des ports. Maintenant que c’est fait, nous pouvons parler du beau temps, du soleil et du vent de ces deux notions fondamentales.  Dans l’exemple des cousins, frères, etc., nous avons implicitement parlé du multiplexing et demultiplexing. Nous avons également parlé des principes de transmissions fiables et non fiables (TCP et UDP). Tout est dans l’exemple. Les plus caïds d’entre vous seront capables de remplacer X par sa valeur, comme nous l’avons fait.
Dans l’exemple des cousins, frères, etc., nous avons implicitement parlé du multiplexing et demultiplexing. Nous avons également parlé des principes de transmissions fiables et non fiables (TCP et UDP). Tout est dans l’exemple. Les plus caïds d’entre vous seront capables de remplacer X par sa valeur, comme nous l’avons fait.
L’hôte-récepteur, lors d’un échange de données, reçoit les PDU de la couche réseau. Nous avons vu que le rôle de la couche transport est d’acheminer ou de donner les PDU reçus à qui de droit, c’est-à-dire aux processus d’application. Ces applications sont identifiables par un numéro de port, comme nous l’avons vu. Il se peut que plusieurs services (processus d’applications) soient exécutés au même moment (ce qui est presque tout le temps le cas). Certaines applications peuvent avoir plusieurs instances en cours d’exécution. Par exemple, vous pouvez utiliser Firefox et Chrome au même moment. Ces deux applications vous donnent accès aux services du protocole HTTP. Supposons alors que vous ayez deux processus d’application HTTP, et deux sessions à distance (Telnet) en cours d’exécution sur une machine. Alors, lorsque la couche transport aura reçu les PDU de la couche réseau, elle va examiner les en-têtes de ces PDU afin de retrouver l’identifiant du processus auquel le PDU doit être acheminé. C’est cela, le démultiplexage. C’est le fait de transmettre un PDU donné au processus d’une application donnée.
Si vous vous souvenez de notre exemple des cousins, Jean et Pierre sont responsables du démultiplexage, étant donné que lorsqu’ils reçoivent les enveloppes du bureau de poste, ils doivent vérifier à qui est destinée chaque enveloppe, et finalement la remettre à qui de droit. Il y a 12 enfants dans chaque maison, avons-nous dit. Ce tri et l’acheminement d’une lettre à la bonne personne, c’est cela le démultiplexage en réseau.
Le multiplexage est exactement le contraire du démultiplexage. Ça devrait donc vous paraître évident. Si, à la réception (avec Jean), la distribution de chaque lettre à son destinataire est le démultiplexage, en toute logique le multiplexage sera donc « l’encapsulation » des lettres et leur acheminement à la poste locale (avec Pierre, donc).
Quand les cousins de Maison-Est écrivent des lettres, Pierre les collecte et met chaque lettre dans une enveloppe. Sur l’enveloppe, il met le nom de l’émetteur et le nom du destinataire. Ensuite, il donne ces enveloppes au bureau de poste. Sa mission s’arrête là. Ainsi, un protocole de la couche transport est responsable de la collection des SDU, de leur encapsulation, en spécifiant le numéro de port du processus de l’application utilisée et le numéro de port à utiliser pour le processus de l’application réceptrice. Cette encapsulation, c’est la transformation du SDU en PDU. Ce protocole est aussi responsable de la livraison de ce PDU à un protocole de la couche inférieure (couche réseau, protocole IP).
Schématiquement, ça donne ceci :
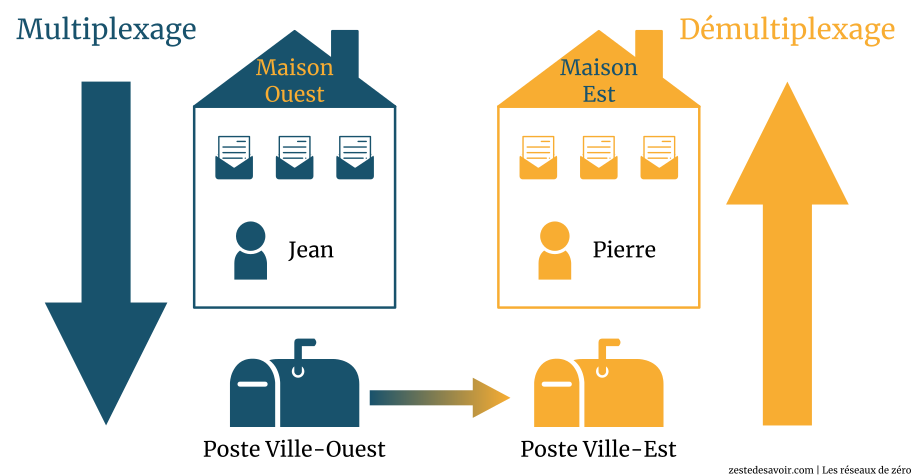
Le schéma est tellement clair ! Les processus (cousins) écrivent des lettres (SDU). Un protocole de transport (Pierre), qui peut être TCP ou UDP, accomplit une opération de multiplexage en rangeant chaque SDU dans son enveloppe (c’est l’encapsulation). Nous nous retrouvons donc avec 12 PDU (12 cousins ont écrit des lettres). Le protocole TCP ou UDP transmet ces PDU au protocole réseau IP (le bureau de poste). Le protocole IP, bien entendu, fera plusieurs autres choses que nous (protocole de transport) n’avons pas besoin de connaître. Quand vous allez déposer un courrier à la poste, le reste, ce n’est plus votre affaire : vous avez fait votre part, à la poste d’assumer ses responsabilités. Une fois que ces lettres ont emprunté un média de transmission (câble, etc.), elles vont arriver au niveau de la couche réseau de l’hôte récepteur. Là, également, le protocole réseau IP va accomplir un certain nombre d’opérations qui ne nous intéressent pas. Après avoir terminé son travail, ce dernier va faire appel à un protocole de transport (Jean), lequel effectuera une opération de démultiplexage, en transmettant chaque enveloppe à son destinataire.
Les protocoles TCP et UDP sont donc responsables de la modification des en-têtes des unités de données lors du multiplexage / démultiplexage.
Structure partielle de l’en-tête de transport
Comme nous l’avons dit plus haut, le multiplexage et démultiplexage sont des opérations effectuées par un protocole de transport. Ces opérations modifient les en-têtes des unités de données. Nous parlons de structure partielle parce que les valeurs que nous allons examiner ne sont pas les seules qu’il y a dans les en-têtes d’un protocole de la couche 4. Il y a plusieurs autres choses que nous allons progressivement découvrir. Pour l’instant, contentons-nous de voir la structure partielle d’un segment :
Champ | Port source | Port destination | SDU |
Partie concernée | En-tête | Message | |
Comme vous le voyez, un segment de protocole de transport est partiellement constitué des champs « port source » (source port), « port de destination » (destination port) et « SDU ». Les parties en italique sont des champs membres de l’en-tête. Vous êtes censés savoir ce qu’est le SDU : nous en avons parlé dans la sous-partie traitant du principe d’encapsulation.
Il n’y a pas grand-chose à dire sur ces champs, tout est déjà si clair. Le champ « port source » contiendra le numéro de port utilisé par l’application émettrice. Le champ « port de destination » contiendra le numéro de port identifiant l’application réceptrice. Finalement, le champ « SDU », c’est le message original. Alors, si l’application utilisée était un service de résolution de nom de domaine (DNS), et que le contenu du message était « 192.168.0.1 -> zestedesavoir.com », à quoi ressemblerait partiellement le segment généré par un protocole de transport ? Vous êtes en mesure de résoudre cet exercice tout seul. Vous pouvez vous référer à la liste des numéros de ports bien connus. Nous allons supposer que l’application source, comme l’application réceptrice, utilise le même numéro de port.
Champ | 53 | 53 | SDU |
Partie concernée | En-tête | 192.168.0.1 -> zestedesavoir.com | |
Pourquoi un numéro de port source et un numéro de port destination ?
Vous savez tous ce qu’est un port et un numéro de port. Un numéro de port est un nombre entier codé sur 16 bits (2 octets). Ainsi, il peut avoir une valeur allant de 0 à 65 535. Nous savons que chaque type d’application a un numéro de port, alors vous vous demandez « Comment ça se fait que la structure de notre segment de transport contienne deux numéros de port ? Un seul devrait suffire, non ?  ».
».
La réponse est… non. Un seul numéro de port ne suffirait pas !
Supposons que l’hôte A ait une instance d’une application HTTP en cours d’exécution (disons qu’il surfe sur le web) et qu’il envoie une requête (il demande une page) à un serveur web B qui a plusieurs instances du service HTTP en cours d’exécution. Chaque instance a le même numéro de port, soit 80, selon les numéros de ports bien connus.
Les serveurs web créent un nouveau processus pour chaque requête HTTP qu’ils reçoivent. Un serveur qui gère 10 requêtes gère donc 10 processus utilisant tous le même numéro de port.
Alors, comment le protocole de transport au niveau du serveur web va réussir son démultiplexage (acheminer la requête au processus adéquat) ? Il y a plusieurs processus exécutés au même moment. En se basant uniquement sur un seul numéro de port dans le segment de transport, le démultiplexage va échouer. 
Nous avons donc besoin de deux numéros de port (source et destination). OK, mais comment savoir quelle valeur mettre dans tel champ du segment ? Dans le mini-exercice que nous vous avons donné plus haut, nous avons dit de supposer que les deux hôtes utilisaient un même numéro de port. Ce n’est pas le cas, en réalité. Donc vous rencontrerez un segment de transport avec des valeurs différentes dans les champs « Source port » et « Destination port ».
Comme vous devriez le savoir, normalement, en réseau, la communication entre deux hôtes se fait selon une architecture client-serveur. Celui qui initialise la transmission est le client, celui qui répond est le serveur. Ainsi, si nous avons un hôte junior0-PC qui essaie de communiquer avec un hôte vince-PC via une session à distance (Telnet), quelles seront les valeurs des champs « Source port » et « Destination port » ? Eh bien, le champ « Destination port » aura pour valeur 23, car c’est le numéro de port bien connu, conventionnellement attribué par l’IANA pour Telnet. Mais quid du champ « Source port » ? Quelle valeur allons-nous y mettre ? 23 ?
En général, le protocole de cette couche (UDP ou TCP) va générer automatiquement un numéro de port qu’aucun processus n’utilise actuellement. Comme vous le savez, plusieurs processus (parfois plusieurs processus d’un même type d’application) peuvent être exécutés au même moment sur une même machine. Chaque processus a un numéro de port. On ne peut pas utiliser un numéro de port déjà utilisé par un autre processus pour le champ « Source port ».
Ok, cool, mais si je veux spécifier un numéro de port non officiel pour une application que j’ai créée ?
Bonne question ! Si, grâce à la programmation des sockets, vous avez créé une application qui doit utiliser un numéro de port de votre choix, alors, bien entendu, vous pouvez déterminer le numéro de port source à utiliser, et ce dernier sera marqué dans le champ « Source port » du segment. Pour ce faire, utilisez la fonction bind() de l’API que vous aurez utilisée pour la création de votre application.
Disons que nous avons programmé une application clemNet (  ) de manière à utiliser le numéro de port Y. Nous voulons utiliser clemNet et envoyer une requête HTTP à un serveur web. Nous savons que le serveur écoute (grâce à la fonction listen() ) le port 80. Le message que nous envoyons au serveur web sera par exemple l’URL d’un site web : zestedesavoir.com (c’est simplifié, une requête HTTP est plus complexe, en réalité).
) de manière à utiliser le numéro de port Y. Nous voulons utiliser clemNet et envoyer une requête HTTP à un serveur web. Nous savons que le serveur écoute (grâce à la fonction listen() ) le port 80. Le message que nous envoyons au serveur web sera par exemple l’URL d’un site web : zestedesavoir.com (c’est simplifié, une requête HTTP est plus complexe, en réalité).
À quoi ressemblera notre segment de transport ?
Champ | Y | 80 | zestedesavoir.com |
Partie concernée | En-tête | Message | |
Y sera la valeur du champ « Source port » et 80 la valeur du champ « Destination port ».
Le serveur va recevoir ce PDU et examiner sa constitution. « Ah tiens, c’est une requête d’une page web (port 80) par l’application clemNet (port Y) ». Il va traiter la requête et renvoyer une réponse. C’est là qu’on comprend l’importance des deux numéros de port.
Dans la procédure d’envoi de la requête, le champ « Source port » avait pour valeur Y. Dans l’envoi de la réponse, le champ « Source port » prend la valeur du champ « Destination port » de la requête, et le champ « Destination port » prend la valeur du champ « Source port » de la requête. Ainsi, notre segment envoyé par le serveur web ressemblera à ceci :
Champ | 80 | Y | index.html |
Partie concernée | En-tête | Message | |
Pour résumer cela, voici un tableau qui montre les valeurs de chaque champ au niveau du client et au niveau du serveur :
| Machine | Port source | Port destination | Ressource |
|---|---|---|---|
 Clem-PC Clem-PC |
Y | 80 |  Demande de www.zestedesavoir.com Demande de www.zestedesavoir.com |
 Serveur ZdS Serveur ZdS |
80 | Y |
Tout est clair ? Fin de la section ! 
Introduction aux sockets
Cette section introduit quelques notions relatives à la programmation réseau. Sa lecture n’est pas indispensable pour le reste du cours.
Nous savons maintenant que les protocoles se chevauchent. Un protocole applicatif (SMTP, POP, HTTP, etc) peut être interfacé à un protocole de transport (UDP, TCP). Mais comment faire pour que les processus des applications communiquent avec les ports des protocoles de transport ? C’est à ça que servent les sockets. Un socket est une interface entre les processus : en réseau, un socket sert donc à faire communiquer un processus avec un service qui gère le réseau. Chaque socket a une adresse de socket. Cette adresse est constituée de deux choses : une adresse IP et un numéro de port. C’est grâce à la programmation de socket que l’on définit le modèle de communication. Si le socket a été configuré de manière à envoyer ou recevoir, c’est un modèle half-duplex. S’il a été configuré de manière à envoyer et recevoir simultanément, il s’agit d’un modèle full-duplex. Étant donné que les sockets sont en fait une interface de programmation d’applications (API), on peut donc s’en servir pour programmer des applications en réseaux (par exemple, créer une application pour faire communiquer un client et un serveur). Dans le souci de vous encourager à faire des recherches sur la programmation des sockets, voici un schéma illustrant une communication entre un client et un serveur.
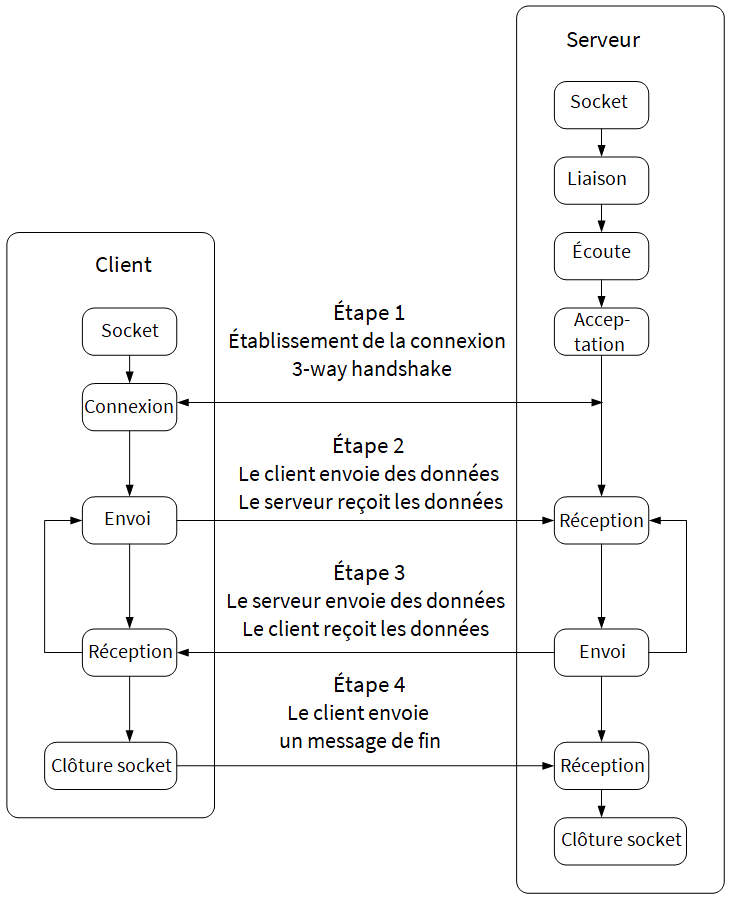
Le schéma en lui-même est assez explicite, mais nous allons vous guider afin de bien le comprendre.
Le client commence à se connecter au serveur grâce aux sockets. Une fois la connexion établie (étape 1), le client et le serveur peuvent communiquer (s’échanger des messages). C’est ce qui se passe dans les étapes 2 et 3. À la fin de la communication, le client envoie une demande de terminaison de session au serveur (étape 4) et le serveur met fin à la connexion.
Mais avant tout cela, vous remarquerez que le serveur n’effectue pas les mêmes actions initiales que le client. Le serveur utilise les sockets pour lier un port d’application à son processus correspondant. Ensuite, il « écoute » ce port. « Écouter », ici, c’est « continuellement vérifier s’il y a un événement qui se passe sur ce port précis ». Ce faisant, il va découvrir qu’un client essaie de se connecter à lui par le numéro de port qu’il écoute. Il accepte donc la requête, établit la connexion (étape 1) et, finalement, les deux communiquent (étapes 2, 3 et 4). Le modèle de communication est half-duplex parce que le client envoie et attend la réponse du serveur et vice-versa.
Les fonctions des API
Nous allons un peu entrer dans des expressions propres à la programmation. Si vous n’êtes pas intéressés par la programmation des applications en réseaux, sautez ce petit point et continuez la lecture plus bas.
Comme vous le savez dorénavant, la programmation des sockets se fait par le biais d’une API (Interface de Programmation d’Application). Il existe plusieurs API pour programmer les sockets ; l’une des plus populaires est Winsock. Cependant, chaque API propose les fonctions suivantes :
- socket() : dans le schéma, vous voyez bien que la première case est « socket ». Cette fonction crée un objet de type Socket que l’on peut identifier par un nombre entier. La création de cet objet, bien entendu, nécessite l’allocation de ressources (mémoire) pour cet objet.
- bind() : en français, ça veut dire « lier ». Au niveau du serveur, dans le schéma, nous avons mis « liaison » juste après socket. Ainsi, après avoir créé une nouvelle instance d’un objet de type Socket, au niveau du serveur, il faut utiliser la fonction bind() pour lier ou associer un socket à une adresse de socket (IP + port).
- listen() : cette fonction est également utilisée au niveau du serveur. Dans le schéma, c’est le bloc « écoute ». Cette fonction change l’état du socket et le met dans un état d’écoute. Comme nous l’avons expliqué, le serveur va « écouter » l’adresse à laquelle est associé le socket en attendant un événement. Il y a également une fonction poll() qui agit aussi dans le même but que la fonction listen(), mais d’une manière différente.
- connect() : cette fonction permet au client d’établir une connexion avec le serveur. En général, ça sera une connexion TCP, car la majorité des sockets utilisent TCP comme protocole de transmission. Cette fonction assigne également un numéro de port local au socket coté client.
- accept() : en toute logique, cette fonction sera appelée du côté du serveur, car elle sert principalement à accepter une requête de connexion envoyée par le client.
- send() : cette fonction, qui signifie « envoyer » et qui est également représentée dans le schéma (bloc « envoi »), sert à envoyer des données du client au serveur et vice-versa. On utilise également la fonction write() (écrire) ou sendto() (envoyer à).
- recv() : cette fonction, représentée par le bloc « réception » du schéma, sert à recevoir les données envoyées par la fonction send(). On utilise également la fonction read() (lire) ou recvfrom() (recevoir de).
- close() : c’est la fonction qui permet au système d’exploitation de libérer les ressources allouées lors de la création de l’objet de type Socket avec la fonction socket(). C’est donc la terminaison de la connexion. Elle est représentée par le bloc « fin » dans notre schéma.
Nous y sommes enfin ! Ou pas… En effet, nous avons terminé notre tour d’horizon de la couche transport. Néanmoins, nous allons nous attarder sur les deux protocoles capitaux de cette couche 4 : UDP et TCP. Courage ! 