Dans ce chapitre, nous allons étudier les trois dernières couches du modèle OSI, à savoir, de haut en bas : la couche applicative (7), la couche de présentation (6) et la couche de session (5).
- Rôle des couches
- BitTorrent, le protocole de partage
- SMTP : le protocole de transmission de mail
- IMAP vs POP : les protocoles de retrait de mail
Rôle des couches
Les couches 7, 6 et 5 du modèle OSI correspondent à une seule couche applicative dans le modèle TCP/IP, voilà pourquoi nous allons les étudier dans une même sous-partie.
Couche 7 : application
À votre grande surprise, vous apprendrez que cette couche n’a pas de rôle défini. En fait, il s’agit seulement d’une couche-interface. Le terme « interface », comme nous l’avons vu, sous-entend que cette couche sert de point de contact ou d’interaction entre l’utilisateur que vous êtes et les services en réseaux. Par exemple, votre navigateur web est une application qui vous permet d’être en contact avec un service offert par le protocole HTTP (HyperText Transfer Protocol). Quand vous utilisez votre messagerie, vous êtes en interaction avec la couche applicative.
La couche applicative héberge principalement :
- Des API (Application Programming Interface : « interface de programmation d’application ») : une API est grosso-modo un ensemble de fonctions permettant à un programme externe d’interagir avec un programme interne pour ne pas exposer le code source. Vous n’êtes pas obligés de savoir ce qu’est une API, mais notez que les API offrant des fonctions de réseaux se trouvent dans la couche application.
- Des services : plusieurs services en réseaux tels que la navigation Internet, la messagerie, la résolution de noms de domaine sont concentrés dans cette couche.
Cette couche regorge de protocoles tels que :
- FTP ;
- HTTP ;
- TFTP ;
- Telnet ;
- SMTP.
Nous n’allons pas étudier tous les protocoles de cette couche (il y en a tellement…) mais en examiner quelques-uns qui sont plutôt intéressants et simples à comprendre.
Couche 6 : présentation
Le nom de cette couche est suffisamment explicite : la couche 6 s’occupe de tout ce qui a trait à la présentation. En d’autres termes, elle offre des services permettant de convertir des données d’un système d’encodage à un autre (de l’EBCDIC vers l’ASCII, par exemple), de compresser des fichiers, de les crypter, etc. Lorsque vous utilisez Winzip, un logiciel de compression, vous utilisez un service de la couche 6 du modèle OSI. Par conséquent, c’est dans cette couche que nous trouvons des protocoles — que nous n’allons pas étudier — tels que LPP (Lightweight Presentation Protocol), NDR (Network Data Representation) ou encore NCP (NetWare Core Protocol).
Un détail souvent omis lorsqu’on traite cette couche est qu’elle se subdivise en deux (sous-)couches. Détail peu important puisque l’union de ces deux sous-couches forme la couche en elle-même. Cependant, afin d’enrichir vos connaissances, voici un schéma illustrant les deux couches qui composent la couche présentation du modèle OSI.
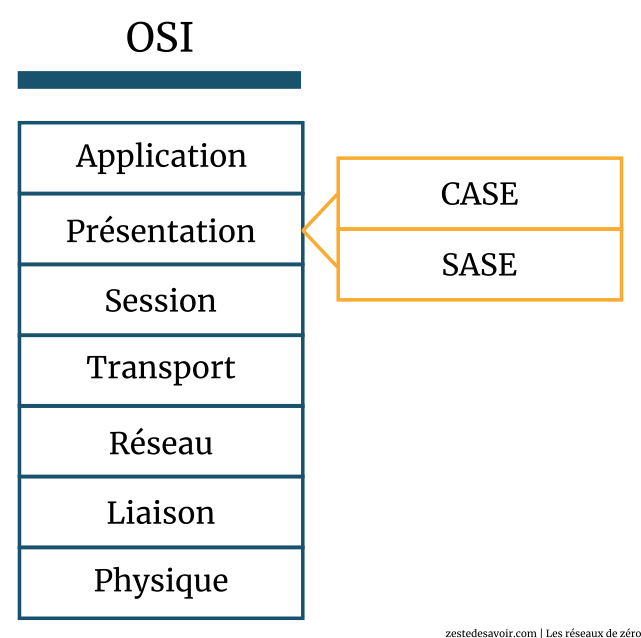
La sous-couche CASE (Common Application Service Element : « élément de service pour les applications courantes ») se charge d’offrir des services pour… les applications courantes ; tandis que SASE (Specific Application Service Element : « élément de service pour une application spécifique »), comme son acronyme l’indique, offre des services pour des applications précises. Si l’explication vous paraît ambiguë, ne vous en faites pas : vous comprendrez tout de même la suite du tutoriel. 
Couche 5 : le gestionnaire de session
Tout est dans le titre. La couche 5 du modèle OSI a la responsabilité de l’ouverture, de la fermeture et de la gestion des sessions entre les applications. Les deux services principaux offerts par cette couche sont la gestion des sessions (ouverture, fermeture, restauration) et la gestion des permissions (quelle application peut faire quoi).
Les protocoles de la couche 5, tels que X.225, peuvent déterminer la direction de la communication. Il existe deux types de communication :
- Half Duplex (HDX) : système de communication permettant l’échange par tour. Si deux entités A et B sont membres d’un réseau fondé sur ce système de communication, elles ne peuvent pas échanger de données au même moment. Chacune doit attendre son tour !
- Full Duplex (FDX) : l’exact contraire du HDX. A et B peuvent communiquer simultanément sans que cela ne pose problème.
Voici deux schémas illustrant ces deux systèmes de communication.
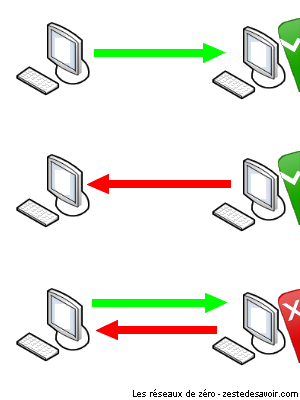
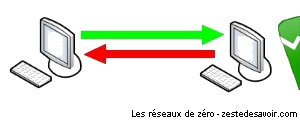
Sachez qu’il existe un autre système de communication appelé simplex. Nous avons préféré le mettre de côté puisqu’il n’est pas utile pour la suite du tutoriel.
BitTorrent, le protocole de partage
Vous savez maintenant à quoi sert la couche applicative des modèles TCP/IP et OSI. Mais nous ne vous avons pas inculqué le concept de cette couche pour nous arrêter en si bon chemin. Nous allons donc explorer quelques protocoles de cette couche, en commençant par un protocole de partage : le célèbre BitTorrent.
La naissance de BitTorrent
Conçu par Bram Cohen, BitTorrent est un protocole permettant le partage de fichiers de taille importante. BitTorrent est sans conteste le protocole de partage le plus utilisé sur Internet et ne vous est certainement pas inconnu. Créé en 2001, son développement continu est assuré par l’entreprise BitTorrent, Inc. Avec BitTorrent, l’échange ou le partage de fichiers se fait dans une infrastructure Peer2Peer (« pair-à-pair »). Par opposition à une architecture centralisée, le pair-à-pair relie les hôtes directement en formant une sorte de topologie maillée.
Pourquoi avoir créé BitTorrent ?
Le succès de BitTorrent est sans doute dû à la minimisation de surcharge du réseau de partage. Imaginez un serveur qui hébergerait 10 000 vidéos. Que se passerait-il si un million d’utilisateurs téléchargeaient simultanément la même vidéo sur ce serveur ? Il aurait à répondre à un million de requêtes à la fois, ce qui ralentirait significativement le réseau de partage. Plus le nombre d’internautes essayant d’accéder à un même fichier au même moment est grand, plus le fichier devient difficilement accessible à cause de la congestion du réseau. C’est de ce constat qu’est né le protocole BitTorrent.
Le fonctionnement de BitTorrent
Et si chaque utilisateur devenait à la fois client et serveur ? Telle est la question que le créateur de BitTorrent a dû se poser. Le fonctionnement de ce protocole de partage est en effet le suivant : si un utilisateur X télécharge un film Y provenant d’un serveur Z, les autres utilisateurs pourront télécharger le même film à travers X pour ne pas alourdir le serveur de base Z.
Pour mieux comprendre ce principe, voici une animation illustrant un réseau utilisant un protocole de partage classique (client-serveur) :
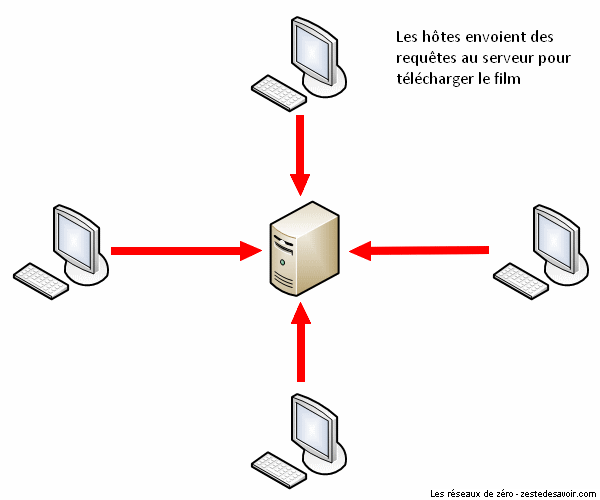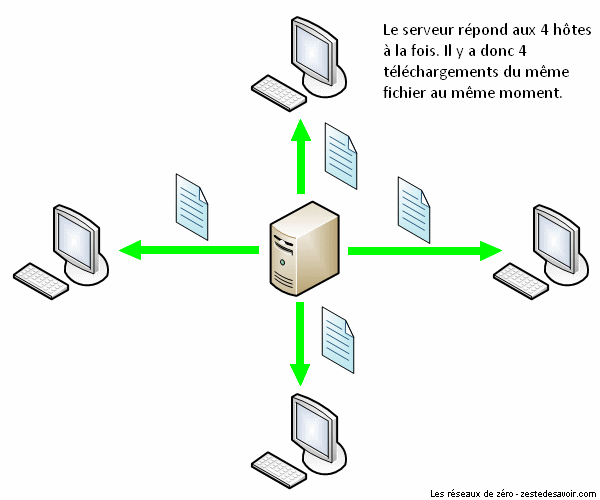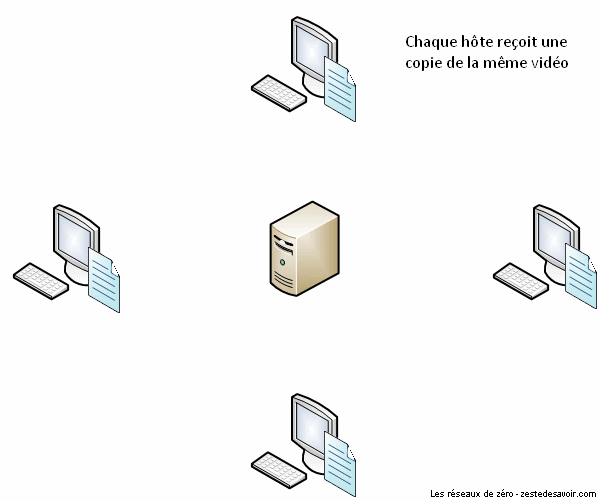
Comme vous pouvez le voir dans cette animation, le serveur envoie quatre copies de ladite vidéo aux quatre clients.
À présent, voici une animation décrivant un partage via BitTorrent.
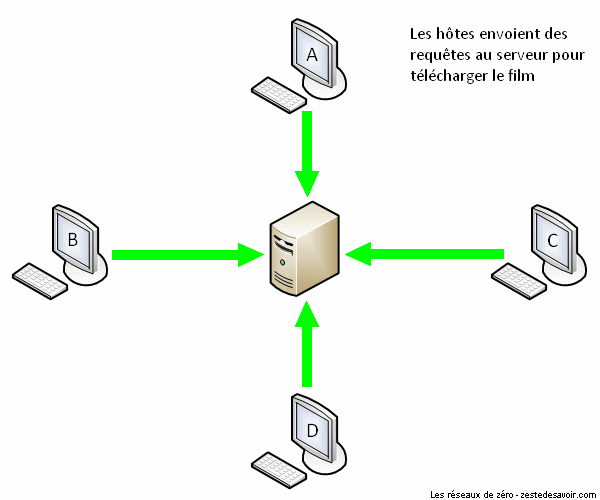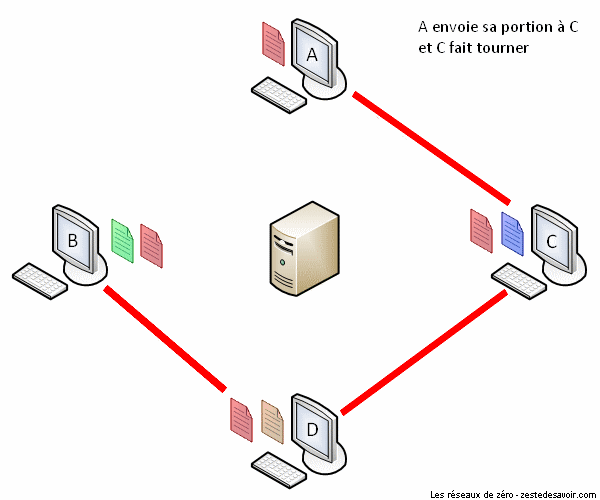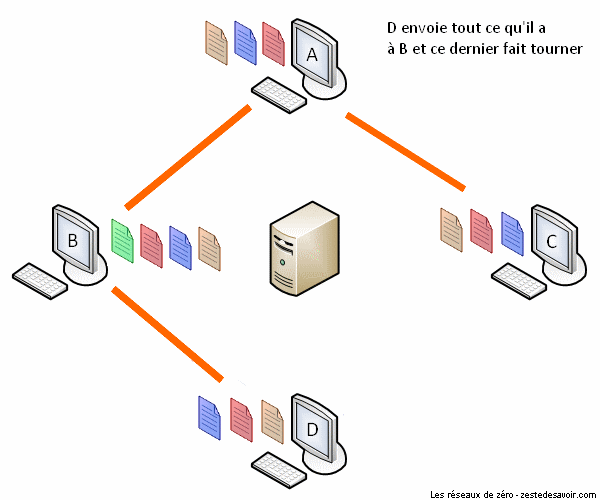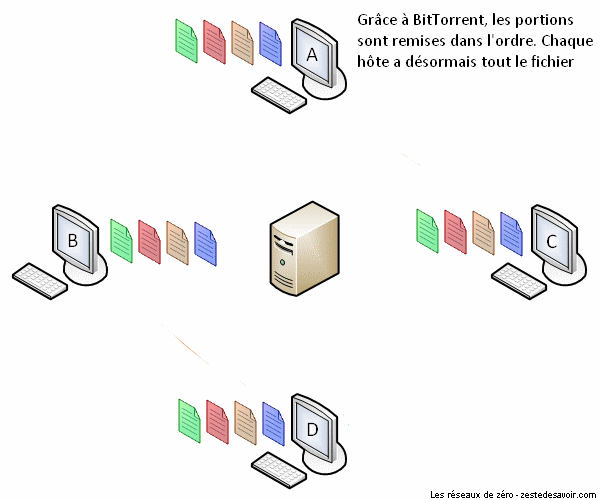
BitTorrent minimise la congestion du réseau en coupant le fichier en plusieurs portions. Tous les clients en reçoivent une, puis ils font office de serveurs les uns pour les autres jusqu’à ce que chaque client ait reçu toutes les portions du fichier. Certes, les portions seront reçues dans le désordre, mais BitTorrent est assez intelligent pour les réagencer correctement. C’est ce qu’on appelle le contrôle de séquence (ça vous dit quelque chose ?). BitTorrent est donc un protocole très pratique et économe. Pas étonnant que Facebook et Twitter l’utilisent pour la distribution des mises à jour sur leurs serveurs !
La terminologie de BitTorrent
En matière de réseaux, le vocabulaire est très important. Nous allons donc parcourir quelques termes propres au protocole que nous étudions.
Les termes de BitTorrent sont vraiment interdépendants : chacun d’eux peut faire référence à un autre, qui en appelle un autre à son tour, etc. Soyez concentrés pour ne pas vous embrouiller.
Les semences et les semeurs
Vous avez certainement déjà rencontré les termes seed et seeder. Seed est un mot anglais signifiant « semence ». Un seeder est un pair (en anglais peer) dans le réseau de partage qui a en sa possession une copie complète d’un fichier. Le seeder a la totalité du fichier en partage, alors que le peer n’a en général qu’une partie dudit fichier. Dans notre animation, chaque ordinateur qui détient une portion de la vidéo est un peer. À la fin du téléchargement, il devient seeder étant donné qu’il a acquis la totalité de la vidéo. Le seeder est donc un « semeur » qui distribue un seed dans le réseau, comme un jardinier répartirait des semences à la surface de la terre.
Les essaims
Avez-vous déjà entendu l’expression « essaim d’abeilles » ? Un essaim est un groupement important d’insectes d’une même famille. Par exemple, les zAgrumes sont un essaim : ils forment un groupement important d’insectes sur un même site.  Avec BitTorrent, un essaim (swarm en anglais) est formé par les peers partageant un même torrent. Si sept seeders et sept autres peers ont tous un torrent en commun, ils forment un essaim de quatorze unités.
Avec BitTorrent, un essaim (swarm en anglais) est formé par les peers partageant un même torrent. Si sept seeders et sept autres peers ont tous un torrent en commun, ils forment un essaim de quatorze unités.
Le traqueur : Big Brother
Un tracker (« traqueur ») n’est rien d’autre qu’un serveur dans le réseau de partage. Cependant, il n’est pas directement impliqué dans la transmission ou dans le partage — d’ailleurs, il ne possède pas de copie du fichier partagé. En quelque sorte, il sert de policier en gardant en mémoire les traces laissées par les seeds et les peers de l’essaim. Il informe également les clients, desquels il reçoit des comptes rendus périodiques, de la présence d’autres clients auxquels ils peuvent se connecter.
Les sangsues et les lâches
Il y a des sangsues dans un protocole ? 
Oh que oui ! Une sangsue (leech en anglais) est un ver qui se nourrit du sang d’autres êtres vivants. Dans un réseau de partage, on qualifie de sangsue tout client qui télécharge plus qu’il ne partage. On parle également de lurker (de l’anglais to lurk : « se cacher », « se dissimuler »). En gros, c’est un lâche. On utilise le terme lurker pour faire référence à un client qui télécharge sans ajouter de contenu nouveau au réseau. La différence entre un lurker et un leech(er) est assez mince. Un leech décide parfois de lui-même de ne plus semer après avoir téléchargé, alors que le lurker, même s’il n’uploade aucune nouveauté, a la bonne pratique de partager ce qu’il télécharge.
Le ratio de partage (share ratio)
Le ratio de partage permet d’évaluer la contribution d’un client à un réseau de partage. Il est obtenu en divisant le nombre de partages par le nombre de téléchargements. Il est souhaitable qu’un client ait un ratio de partage supérieur à 1, c’est-à-dire qu’il partage plus qu’il ne télécharge. En revanche, un ratio de partage inférieur à 1 veut dire qu’un client est plus impliqué dans le téléchargement que dans le partage.
En ce qui concerne les termes propres à BitTorrent, nous allons nous arrêter là. Nous vous invitons à faire une recherche sur Internet à chaque fois que vous tomberez sur l’un des termes que nous n’avons pas abordés. Pour ceux qui désirent poursuivre l’exploration de BitTorrent, nous vous recommandons le tutoriel de Natim (lien d’archive) qui est bien plus complet que notre présentation.
SMTP : le protocole de transmission de mail
Le service de messagerie (instantanée ou non) est sans doute le plus utilisé de nos jours quotidiennement. Enfin, en dehors de Facebook. Chacun de nous est amené à consulter ses mails régulièrement, voire à en rédiger. La messagerie électronique nous a facilité la tâche en réduisant le temps de rédaction et d’acheminement d’un courrier. Ça vous dirait de voir comment ça se passe dans les coulisses ? Nous allons donc étudier le fonctionnement d’un protocole nous permettant d’envoyer un message électronique.
Présentation rapide de SMTP
SMTP (Simple Mail Transfer Protocol : « protocole simple de transfert de courrier ») a été créé dans les années 1970, aux débuts d’Internet. Comme tout bon protocole qui se veut être un standard, il a fallu qu’il soit spécifié par une requête de commentaires (RFC). C’est donc en 1982 qu’il est spécifié par la RFC 821. Une RFC de 2008 comprenait des mises à jour de la première implémentation de ce protocole : la RFC 5321.
SMTP a commencé à être massivement utilisé au début des années 1980. Il sert principalement à envoyer des mails. Comme son nom l’indique, il s’agit d’un protocole de transmission et non de réception. Cependant, les serveurs de messagerie utilisent SMTP pour faire les deux, c’est-à-dire la transmission et la réception, cette dernière n’étant en fait qu’une transmission, n’est-ce pas ? Comment ça, vous ne le saviez pas ?  En voici une démonstration :
En voici une démonstration :
- Vous écrivez une lettre (physique) à un ami au Japon.
- La lettre arrive à la poste centrale du Japon.
- La poste centrale va à son tour transmettre la lettre au domicile de votre camarade.
Vous avez confié la lettre à la poste, qui l’a envoyée au destinataire. Pour vous et pour la poste, il s’agit d’une transmission ; pour votre ami, d’une réception. La réception n’est donc qu’une autre transmission. 
Ainsi, les serveurs de messagerie utilisent SMTP pour la transmission et la réception, tandis que les clients de messagerie utilisent SMTP pour l’envoi et un autre protocole (POP ou IMAP) pour la réception. Nous allons étudier ces protocoles de retrait dans la sous-partie suivante.
SMTP sert donc à transmettre un mail, mais n’a-t-il pas besoin d’utiliser un protocole de transmission ?
La probabilité que vous vous soyez posé cette question est proche de zéro.  Mais bon… SMTP est un protocole de transfert. Or pour transférer, il faut un autre protocole de transmission.
Mais bon… SMTP est un protocole de transfert. Or pour transférer, il faut un autre protocole de transmission.
Un protocole peut en utiliser un autre ? 
Les protocoles qui assurent la transmission se trouvent dans la couche de transport. Par conséquent, un protocole de transfert de la couche application (comme SMTP) ne peut se passer d’un protocole de transmission de la couche transport (UDP ou TCP). Nous étudierons et comparerons justement les protocoles de transport dans la partie 4 du cours.
Si vous avez décroché à partir des protocoles de transmission, ce n’est pas grave : nous verrons cela de manière plus claire dans le prochain chapitre. Mais il faut raccrocher au protocole SMTP maintenant !
Cheminement d’un courriel
Maintenant, nous allons voir les étapes par lesquelles passe un courriel avant d’atteindre son destinataire. Comme il est de coutume dans ce tutoriel, nous allons commencer par une analogie qui ne doit pas vous être inconnue. Pierre (encore lui) habite à Paris. Il veut écrire une lettre à André, qui habite Lyon. Dans notre scénario, la procédure de transmission/réception de la lettre se fera ainsi :
- Pierre écrit la lettre.
- Le facteur vient la chercher.
- La lettre arrive à la poste locale.
- La poste envoie la lettre à Lyon.
- Elle arrive à la poste locale de Lyon.
- Un facteur est chargé de la porter au domicile d’André.
- André reçoit la lettre.
Hormis l’étape 1 (écriture de la lettre) et l’étape 7 (réception), la lettre est passée entre les mains du facteur, de la poste locale, de la poste distante (celle de Lyon) et d’un autre facteur. Soit quatre étapes.
Vous pouvez constater qu’il y a deux facteurs dans notre exemple : le premier peut être qualifié de « facteur de transmission », car il est impliqué dans l’étape de transmission de notre lettre ; le second, de « facteur de réception », car il est impliqué dans la transmission/réception de notre lettre.
Voici un schéma illustrant ces étapes :
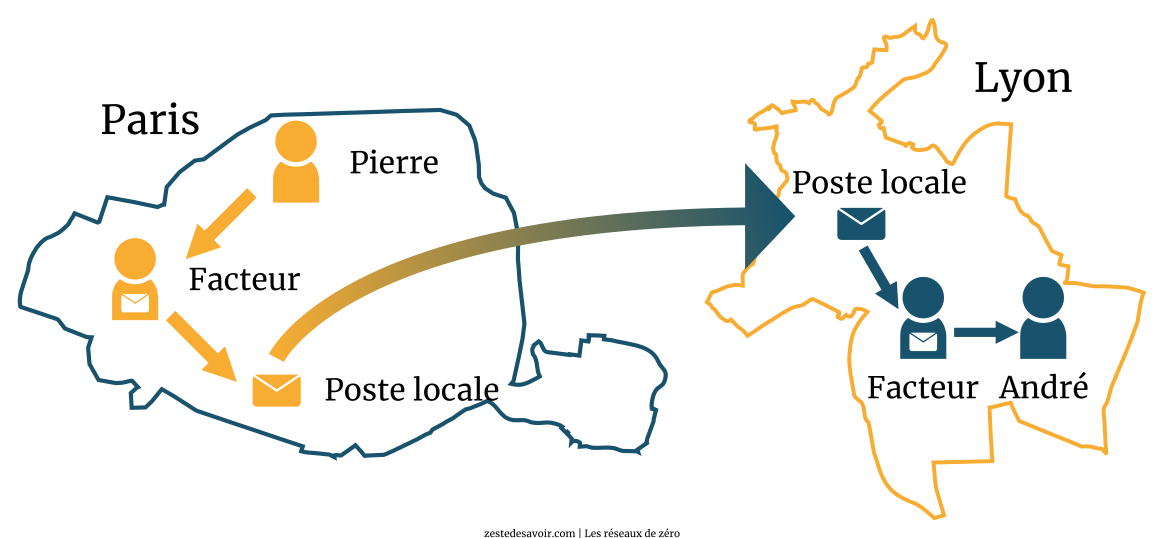
Et alors, où est le rapport avec le protocole SMTP ?
Avez-vous déjà oublié que la technologie s’inspire de la vie quotidienne ? Le protocole SMTP suivra exactement le même principe et votre mail passera lui aussi par quatre étapes : le facteur, la poste locale, la poste distante et un autre facteur (voir schéma suivant).
Quoi, il y a des bureaux de poste dans les réseaux ?
Mais bien sûr. C’est d’ailleurs pour cela qu’il existe un protocole POP, acronyme de Post Office Protocol, soit littéralement « protocole de bureau de poste ».
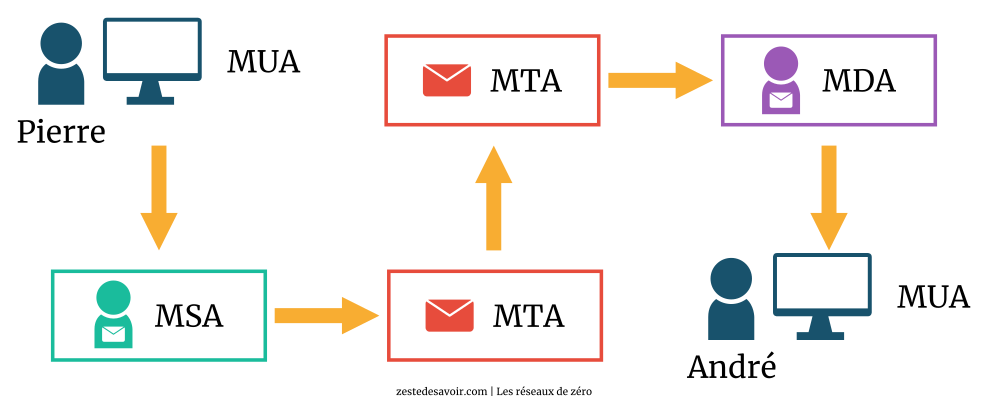
D’abord vous nous dites que notre courriel passera par le facteur, la poste locale, etc. Mais maintenant vous nous parlez de MUA, de MTA… 
Et alors ? Remplacez X par sa valeur ! 
Le facteur de transmission correspond sur le schéma au MSA, les deux bureaux de poste sont des MTA et le facteur de réception est un MDA.
Ok, voulez-vous bien nous expliquer tout ça ? Et qu’est-ce que le MUA ?
Pas de panique !
Commençons par le MUA
Considérons que le papier et le stylo que vous utilisez pour écrire une lettre forment une « application de rédaction ». Dans la couche applicative, qui nous sert d’interface avec les services réseaux, le MUA (Mail User Agent : « client de messagerie ») n’est autre que l’application de rédaction d’un courriel, un client de messagerie. C’est une application, comme Outlook ou Thunderbird, qui vous permet de retirer des mails de votre boîte de réception et d’en écrire.
Je n’utilise aucun logiciel pour le retrait de mes mails, je le fais directement sur Hotmail/Yahoo/Gmail/autre. Alors, qu’en est-il ?
Hotmail & cie sont également des MUA, plus précisément des webmails. Ce sont des applications auxquelles on accède par l’intermédiaire d’un navigateur.
Alors, dans notre schéma, Pierre utilise Outlook/Yahoo/autre pour écrire un courriel et clique sur… « Envoyer ». Direction : le MSA !
C’est quoi, ce MSA ?
MSA signifie Mail Submission Agent, soit « agent de soumission de courrier ». Comme son nom l’indique, son rôle est donc de soumettre le mail. O.K., mais à qui ? Dans notre scénario, le MSA est le facteur de transmission. Votre lettre ne peut pas quitter directement Pékin pour la terre Adélie, n’est-ce pas ? Surtout qu’il n’y a aucun habitant en terre Adélie. C’est pour l’exemple. Le facteur se chargera de la conduire à la poste où les mesures nécessaires d’envoi seront prises pour l’acheminement de votre courrier à son destinataire, dans les plus brefs délais et dans des conditions normales de température et de pression satisfaisantes. Un MSA n’est en fait qu’un autre logiciel-interface, c’est-à-dire un intermédiaire entre votre client de messagerie et le serveur de messagerie (serveur Gmail ou autre).
Il est possible de fusionner un MTA et un MSA. Dans ce cas, on parle seulement de MTA — mais ce dernier assure également le rôle d’un MSA. Comme si, pour en revenir à notre scénario, vous décidiez d’aller vous-même déposer votre lettre à la poste locale au lieu de passer par un facteur.
MTA, l’agent de Jack Bauer de transfert
Un MTA ou Mail Transfer Agent est l’agent de transmission du courriel, tout comme le bureau de poste est l’agent de transmission de votre courrier. Mais le bureau de poste reçoit également les courriers externes pour les expédier à leurs destinataires respectifs. Voilà pourquoi nous voyons sur le schéma que le courrier passe d’un MTA à un autre, de la même manière que la lettre de Pierre passe du bureau de poste local de Paris à celui de Lyon.
Quand vous écrivez un mail à une personne dont l’adresse appartient à un autre domaine que la vôtre, il passe par un second MTA. Cependant, lorsqu’il s’agit d’un mail interne à un même domaine, il est directement pris en charge par le MDA sans passer par le second MTA. Un exemple ? Si Pierre écrit un courrier à Jacques et qu’ils habitent tous deux à Paris, la lettre ira à la poste locale via le facteur de transmission. Une fois à la poste, on enverra simplement un facteur de réception livrer la lettre puisqu’il est inutile de passer par la poste d’une autre ville.
Voici un schéma illustrant le transfert d’un mail entre deux clients dans un même domaine.
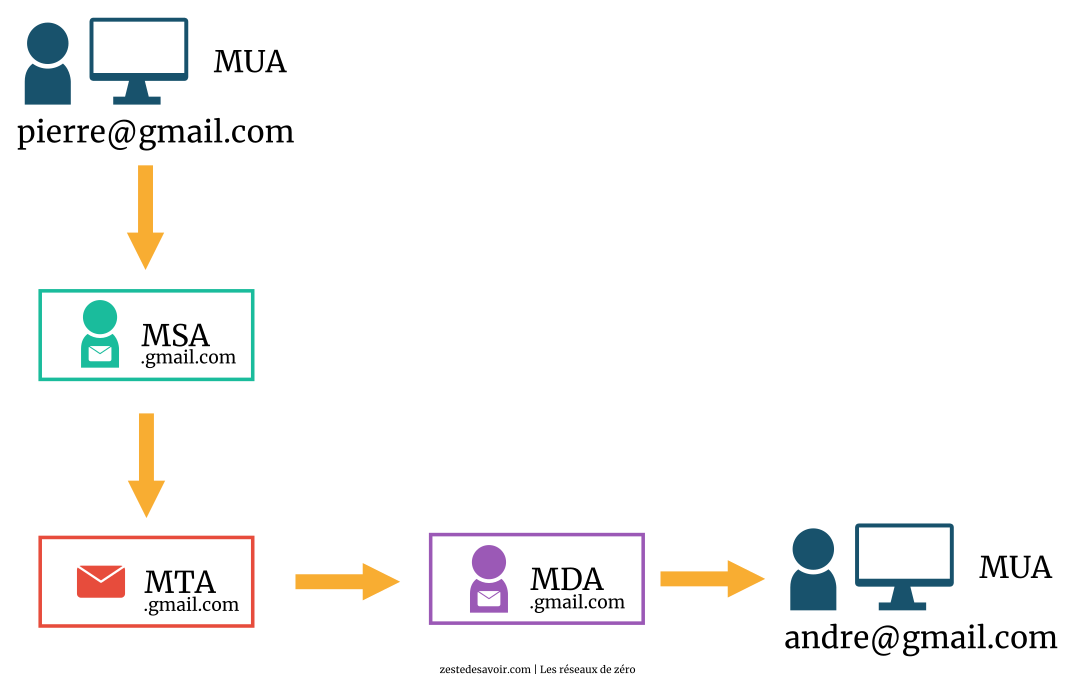
Voici à présent un autre schéma illustrant le transfert d’un mail entre deux clients de domaines différents.
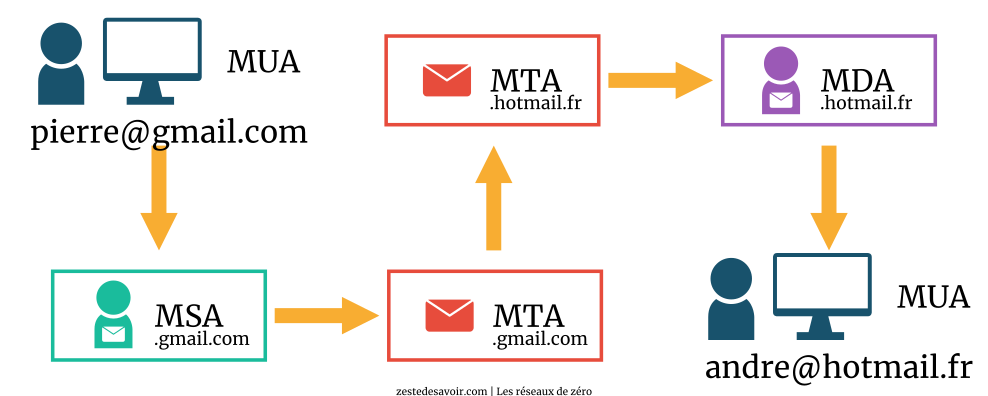
Le MTA de Gmail étudiera la partie qui se trouve après le caractère @ dans l’adresse du destinataire afin de vérifier s’il s’agit d’un transfert de mail à un client du même domaine (un client Gmail en l’occurrence). Il se rendra compte que hotmail.fr ne concerne pas son domaine et enverra donc le courriel au MTA du domaine de Hotmail.
Nous reverrons les noms de domaine dans une autre partie de ce cours. En attendant, vous pouvez lire le tutoriel très complet de Mathieu Nebra sur la gestion du nom de domaine.
Pour terminer : le grand MDA
Pour comprendre ce qu’est le MDA (Mail Delivery Agent : « agent livreur de courrier »), posons-nous deux questions.
Qu’est-ce qu’un livreur de pizzas ?
Un livreur de pizzas, c’est quelqu’un qui livre des pizzas.
Quelle est la différence entre le facteur de transmission et le facteur de réception dans notre schéma ?
Voilà une question sérieuse ! Les deux sont des facteurs, les deux livrent donc des pizzas du courrier. Sauf que vous envoyez vous-même le premier (facteur de transmission) livrer le courrier, alors que le second (facteur de réception) est envoyé par le bureau de poste. Vous commandez une pizza, la demande est traitée et on vous envoie un livreur, n’est-ce pas ? Mais ce n’est pas vous qui avez donné l’ordre directement au livreur de vous apporter la pizza.
Voilà pourquoi nous faisons une nette distinction entre les deux facteurs. L’un s’appelle MSA et l’autre MDA pour les raisons évoquées ci-dessus. Nous disons au MSA : « Écoute, va transmettre ce mail à X » ; tandis que le MTA dit au MDA : « Tiens, X a reçu un mail, viens le chercher et le stocker ». Tout est clair ?
Nous pourrions aussi considérer le MDA comme une vraie boîte aux lettres où les courriers sont stockés en attendant que leur destinataire vienne les chercher. Cependant, en vertu du scénario établi, le MDA sera considéré comme le facteur de réception qui vient déposer le courrier dans votre boîte aux lettres.
Quand les protocoles s’emmêlent…
Du MUA de Pierre au dernier MTA impliqué dans le processus de transmission, c’est le protocole SMTP qui est utilisé. Entre le MDA et le dernier MUA (celui d’André), c’est un protocole de réception qui est utilisé : POP, POP2 ou IMAP.
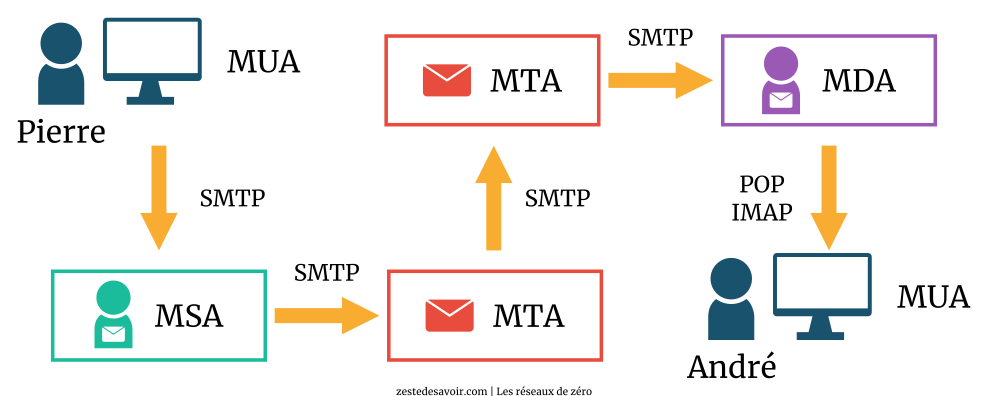
Vous pouvez également vous rendre compte que les MTA utilisent SMTP pour la transmission et la réception comme nous l’avons indiqué un peu plus haut. Suivez-nous dans la prochaine sous-partie pour une exploration de ces protocoles de retrait de mail !
IMAP vs POP : les protocoles de retrait de mail
Nous allons vous présenter seulement les protocoles POP et IMAP dans une même sous-partie, car ils servent à faire la même chose et que chacun présente des avantages que l’autre n’a pas. Commençons par le protocole POP.
Le bureau de poste version électronique : présentation
POP (Post Office Protocol : « protocole de bureau de poste ») a l’avantage d’être simple et efficace et surtout, il est supporté par tous les clients de messagerie. Pour comprendre le rôle assuré par ce protocole, nous allons examiner le rôle d’un bureau de poste dans la vie courante.
Quels sont les services offerts par un bureau de poste ?
La question peut paraître idiote, mais quand on sait qu’en France, La Poste est aussi une banque et un opérateur de téléphonie mobile… Cependant, nous n’allons retenir que les services qui concernent directement notre étude. Le bureau de poste a pour fonction principale de traiter les courriers : il les reçoit et les distribue à leurs destinataires respectifs. Il est également en contact avec les autres bureaux de poste distants.
En réseau, en ce qui concerne la messagerie électronique, le protocole POP fait plus ou moins la même chose. La différence avec un véritable service postal est que deux bureaux de poste de villes différentes peuvent échanger du courrier, alors que le protocole POP ne peut pas en envoyer. POP n’est qu’un protocole de retrait : il permet d’aller chercher un mail se situant sur un serveur de messagerie, mais pas d’en envoyer. L’envoi est assuré par le protocole SMTP.
Il existe trois versions de ce protocole : POP1, POP2 et POP3. La toute première version est spécifiée par la RFC 918. POP2 est spécifié par la RFC 937 et vous pouvez retrouver les spécifications de POP3 dans la RFC 1081. La spécification actuelle de ce protocole se trouve dans la RFC 1939, qui n’est en fait que la RFC 1081 incluant un mécanisme de gestion d’extension et un autre d’authentification. La RFC 2595 sécurise le protocole POP en l’utilisant de pair avec le protocole SSL (Secure Socket Layer) : on parle donc aussi de POP3S, avec un S pour SSL. Le protocole SSL a depuis évolué en TLS (Transport Layer Security). Nous n’allons pas étudier en détail le protocole POP : il existe déjà un tutoriel à ce sujet que nous vous invitons à lire.
Le protocole POP permet bien sûr de récupérer son courrier, mais aussi d’en laisser une copie sur le serveur. Cela est particulièrement utile si l’on ne peut plus accéder pour une raison quelconque (panne…) aux e-mails déjà téléchargés : on peut toujours les télécharger de nouveau. Néanmoins, il n’a pas vraiment été conçu pour cela, contrairement à IMAP.
IMAP : un protocole qui a la tête dans les nuages
IMAP (Internet Message Access Protocol) est un protocole de lecture d’e-mails. Contrairement à POP, il n’a pas été conçu pour recevoir des messages mais pour les consulter directement depuis un serveur. Cette consultation s’apparente à du cloud, c’est-à-dire l’accès par Internet à des données qui ne se trouvent pas sur notre disque dur. IMAP est assez avancé puisqu’il permet de gérer ses messages directement sur un serveur distant pour organiser nos messages en dossiers, par exemple. Il supporte également TLS. Dans le cas d’IMAP, le clouding est à la fois un avantage et un inconvénient : on peut accéder à ses messages depuis n’importe quel ordinateur, à condition d’être connecté à son compte de messagerie. Quelques clients permettent néanmoins de télécharger les messages pour pallier ce problème. Certains clients de messagerie ne gèrent pas très bien le protocole IMAP, qui est défini par la RFC 3501. Vous pouvez avoir plus de détails sur ce protocole en lisant ce tutoriel.
Voilà qui est fait ! On descend encore une marche ? Ah, on nous demande de nous identifier pour accéder à la couche suivante… Mais comment faire ? Eh bien, suivez-nous dans la prochaine partie pour découvrir l’identification et l’adressage, puis nous pourrons accéder à la couche 4 !