Ne soyez pas déçu·e ! Nous n’en sommes qu’au début du cours, alors ce chapitre sera plus une introduction aux modèles que Le Modèle OSI de A à Z en vingt-cinq volumes… Mais ne vous inquiétez pas, vous aurez déjà fort à faire ! 
- Le modèle OSI en douceur
- Le modèle OSI par l'exemple : le facteur
- Survol des couches du modèle OSI
- TCP/IP vs OSI : le verdict ?
- Principe d'encapsulation
Le modèle OSI en douceur
Dans cette sous-partie, nous allons définir le plus simplement possible ce qu’est le modèle OSI. En effet, vous allez le comprendre, il n’y a aucun rapport avec la mode ni la 3D (si si, nous vous le jurons).
Qu’est-ce que le modèle OSI ?
Le modèle OSI (Open Systems Interconnection : « interconnexion de systèmes ouverts ») est une façon standardisée de segmenter en plusieurs blocs le processus de communication entre deux entités. Chaque bloc résultant de cette segmentation est appelé couche. Une couche est un ensemble de services accomplissant un but précis. La beauté de cette segmentation, c’est que chaque couche du modèle OSI communique avec la couche au-dessus et au-dessous d’elle (on parle également de couches adjacentes). La couche au-dessous pourvoit des services que la couche en cours utilise, et la couche en cours pourvoit des services dont la couche au-dessus d’elle aura besoin pour assurer son rôle. Voici un schéma pour illustrer ce principe de communication entre couches :
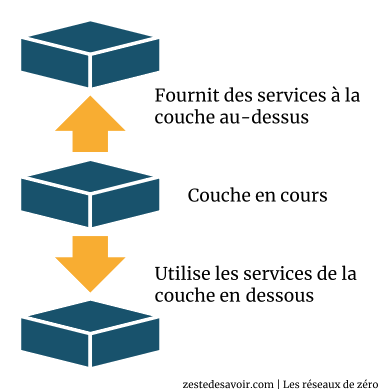
Ainsi le modèle OSI permet de comprendre de façon détaillée comment s’effectue la communication entre un ordinateur A et un ordinateur B. En effet, il se passe beaucoup de choses dans les coulisses entre l’instant t, où vous avez envoyé un mail (par exemple), et l’instant t1, où le destinataire le reçoit.
Le modèle OSI a segmenté la communication en sept couches :
- Application (ou couche applicative).
- Présentation.
- Session.
- Transport.
- Réseau.
- Liaison de données.
- Physique.
Une façon efficace de connaître ces couches par cœur, de haut en bas et en anglais, serait de mémoriser la phrase suivante : All People Seem To Need Data Processing, ce qui signifie : « Tout le monde a besoin du traitement de données. » Chaque majuscule représente la première lettre d’une couche : A pour application, P pour présentation, S pour session, T pour transport, N pour réseau (network en anglais), D pour data (liaison de données) et finalement le dernier P (processing) pour physique.
De bas en haut, le moyen mnémotechnique anglais utilisé est Please Do Not Throw Sausage Pizza Away. Ce qui donne en français : « S’il vous plaît, ne jetez pas les saucisses de pizza. » Ces sacrés anglophones ont des inspirations hilarantes !  On trouve d’autres moyens mnémotechniques en français pour retenir ces couches de bas en haut : Partout Le Roi Trouve Sa Place Assise, ou encore : Pour Le Réseau, Tout Se Passe Automatiquement.
On trouve d’autres moyens mnémotechniques en français pour retenir ces couches de bas en haut : Partout Le Roi Trouve Sa Place Assise, ou encore : Pour Le Réseau, Tout Se Passe Automatiquement.
Le modèle OSI par l'exemple : le facteur
Oui, nous le savons, vous êtes impatient·e ; néanmoins, allons-y lentement mais sûrement.  Nous n’allons rien vous enseigner de trop complexe, rassurez-vous. Nous avons pris l’habitude de toujours illustrer nos propos par un exemple concret, une analogie parlante.
Nous n’allons rien vous enseigner de trop complexe, rassurez-vous. Nous avons pris l’habitude de toujours illustrer nos propos par un exemple concret, une analogie parlante.
Pour comprendre le modèle OSI, nous allons inventer un scénario. Vous vous souvenez de Pierre et de Jacques ? Oui, nos camarades d’antan ! Pierre garde une lettre dans son bureau. Il veut la donner au facteur, qui attend devant le portail de sa belle villa. La lettre est destinée à Jacques, mais Pierre n’a pas le droit d’entrer dans le bureau de Jacques. Jacques non plus n’a pas le droit de sortir de son bureau. Seul le facteur peut entrer dans le bureau de Jacques pour délivrer la lettre, mais il lui est interdit d’aller dans celui de Pierre pour la chercher.
La maison de Pierre est mal construite : il n’y a pas de couloir, juste un alignement vertical de pièces séparées par une porte. Pour aller du bureau au portail, Pierre doit traverser le salon et le jardin. Schématiquement, cela donne ceci :
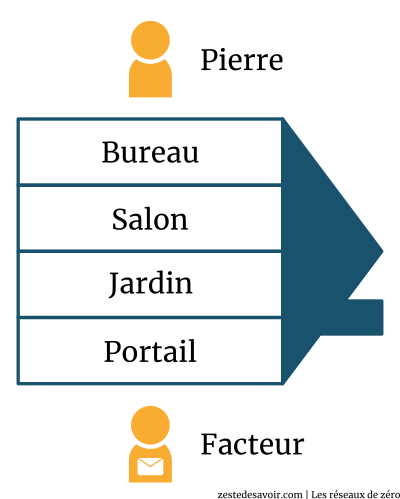
Dans le schéma ci-dessus, chaque pièce de la maison peut être considérée comme une couche. Pierre doit quitter la couche la plus élevée pour se diriger vers la plus basse (le portail). Une fois la lettre remise au facteur, ce dernier devra faire l’inverse chez Jacques, c’est-à-dire quitter la couche la plus basse pour aller vers la couche la plus élevée (le bureau de Jacques).
Chaque pièce de la maison possède une fonction précise. Le bureau est généralement réservé au travail ; le salon, à la distraction (discussions, télévision, etc.). Le jardin, lui, nous offre sa beauté et son air pur. Quant au portail, il permet d’accéder aussi bien au jardin qu’à la maison.
Faisons intervenir un autre personnage, Éric, dans notre histoire. Éric ne connaît absolument rien au processus de transfert de lettres. Alors quand Pierre lui dit : « J’ai écrit une lettre à Jacques », Éric imagine le scénario suivant :
- Pierre a écrit la lettre.
- Il l’a envoyée.
- Jacques a reçu la lettre.
Éric, c’est un peu vous avant la lecture de ce tutoriel. Vous pensiez sans doute qu’après avoir envoyé un mail, par exemple, M. le destinataire le recevait directement. Mais vous venez de comprendre grâce à l’exemple de la lettre que votre mail est passé par plusieurs couches avant d’arriver au destinataire. Cet exemple vous semble peut-être aberrant, mais nous pensons qu’il a aidé plusieurs personnes à mieux concevoir le principe du modèle OSI.
Pour illustrer ce processus et faciliter votre compréhension, nous n’avons abordé que quelques couches du modèle OSI en faisant appel à un facteur. N’en déduisez pas quoi que ce soit !
Survol des couches du modèle OSI
Nous y sommes presque ! Nous allons regarder le modèle OSI d’un œil plus technique, cela devrait vous plaire !  Le modèle OSI est donc constitué de sept couches distinctes. Dans chacune de ces couches opèrent un certain nombre de protocoles.
Le modèle OSI est donc constitué de sept couches distinctes. Dans chacune de ces couches opèrent un certain nombre de protocoles.
Comment ça fonctionne ?
Lorsque vous voulez envoyer un mail à l’équipe des rédacteurs de ce tutoriel (comment ça, ça ne vous tente pas ?  ), plusieurs choses se passent en coulisses.
), plusieurs choses se passent en coulisses.
Couche applicative
Vous avez besoin d’accéder aux services réseaux. La couche applicative fait office d’interface pour vous donner accès à ces services, qui vous permettent notamment de transférer des fichiers, de rédiger un mail, d’établir une session à distance, de visualiser une page web… Plusieurs protocoles assurent ces services, dont FTP (pour le transfert des fichiers), Telnet (pour l’établissement des sessions à distance), SMTP (pour l’envoi d’un mail), etc.
Couche présentation
Il vous faut formater votre mail pour une bonne présentation. C’est dans la couche… présentation que cela se passe. Elle s’occupe de la sémantique, de la syntaxe, du chiffrement/déchiffrement, bref, de tout aspect « visuel » de l’information. Un des services de cette couche, entre autres : la conversion d’un fichier codé en EBCDIC (Extended Binary Coded Decimal Interchange Code) vers un fichier codé en ASCII (American Standard Code for Information Interchange).
Le chiffrement peut être pris en charge par une autre couche que la couche de présentation. En effet, il peut s’effectuer dans la couche application, transport, session, et même réseau. Chaque niveau de chiffrement a ses avantages.
Certains protocoles, tels que le HTTP, rendent la distinction entre la couche applicative et la couche de présentation ambiguë. Le HTTP, bien qu’étant un protocole de la couche applicative, comprend des fonctionnalités de présentation comme la détection du type de codage de caractères utilisé.
Couche session
Une fois que vous êtes prêt(e) à envoyer le mail, il faut établir une session entre les applications qui doivent communiquer. La couche session du modèle OSI vous permet principalement d’ouvrir une session, de la gérer et de la clore. La demande d’ouverture d’une session peut échouer. Si la session est terminée, la « reconnexion » s’effectuera dans cette couche.
Couche transport
Une fois la session établie, le mail doit être envoyé. La couche de transport se charge de préparer le mail à l’envoi. Le nom de cette couche peut prêter à confusion : elle n’est pas responsable du transport des données proprement dit, mais elle y contribue. En fait, ce sont les quatre dernières couches (transport, réseau, liaison de données et physique) qui toutes ensemble réalisent le transport des données. Cependant, chaque couche se spécialise. La couche de transport divise les données en plusieurs segments (ou séquences) et les réunit dans la couche transport de l’hôte récepteur (nous y reviendrons). Cette couche permet de choisir, en fonction des contraintes de communication, la meilleure façon d’envoyer une information. « Devrai-je m’assurer que la transmission a réussi, ou devrai-je juste l’envoyer et espérer que tout se passe bien ? Quel port devrai-je utiliser ? » La couche de transport modifie également l’en-tête des données en y ajoutant plusieurs informations, parmi lesquelles les numéros de ports de la source et de la destination. Le protocole TCP (Transmission Control Protocol) est le plus utilisé dans la couche de transport.
Couche réseau
Maintenant que nous savons quel numéro de port utiliser, il faut aussi préciser l’adresse IP du récepteur. La couche réseau se charge du routage (ou relai) des données du point A au point B et de l’adressage. Ici aussi, l’en-tête subit une modification. Il comprend désormais l’en-tête ajouté par la couche de transport, l’adresse IP source et l’adresse IP du destinataire. Se fait également dans cette couche le choix du mode de transport (mode connecté ou non connecté, nous y reviendrons là encore). Le protocole le plus utilisé à ce niveau est bien sûr le protocole IP.
La couche liaison
Présentation effectuée ? O.K. !
Session établie ? O.K. !
Transport en cours ? O.K. !
Adresses IP précisées ? O.K. !
Il reste maintenant à établir une liaison « physique » entre les deux hôtes. Là où la couche réseau effectue une liaison logique, la couche de liaison effectue une liaison de données physique. En fait, elle transforme la couche physique en une liaison, en assurant dans certains cas la correction d’erreurs qui peuvent survenir dans la couche physique. Elle fragmente les données en plusieurs trames, qui sont envoyées une par une dans un réseau local. Par conséquent, elle doit gérer l’acquittement des trames (nous… enfin bref, ce chapitre n’est qu’une introduction, vous l’avez compris  ). Quelques exemples de protocoles de cette couche : Ethernet, PPP (Point to Point Protocol), HDLC (High-Level Data Link Control), etc.
). Quelques exemples de protocoles de cette couche : Ethernet, PPP (Point to Point Protocol), HDLC (High-Level Data Link Control), etc.
La couche 2 assure la livraison des trames dans un réseau local. Cela dit, elle utilise des adresses physiques, la transmission des données au-delà du réseau local ne peut donc pas être gérée à ce niveau. Logique, quand on y pense : c’est le rôle de la couche 3. Tous les protocoles de cette couche n’ont pas forcément la possibilité de gérer l’acquittement des trames, qui se fait alors dans une couche supérieure.
Finalement : la couche physique
Notre mail est en cours de transport, mettons-le sur le média. La couche physique reçoit les trames de la couche de liaison de données et les « convertit » en une succession de bits qui sont ensuite mis sur le média pour l’envoi. Cette couche se charge donc de la transmission des signaux électriques ou optiques entre les hôtes en communication. On y trouve des services tels que la détection de collisions, le multiplexing, la modulation, le circuit switching, etc.
Résumé
Nous avons abordé, en donnant quelques détails, chacune des couches du modèle OSI ; voici un tableau récapitulatif.
| Position dans le modèle OSI | Nom de la couche | Rôle de la couche |
|---|---|---|
| 7 | Application | Point de contact avec les services réseaux. |
| 6 | Présentation | Elle s’occupe de tout aspect lié à la présentation des données : format, chiffrement, encodage, etc. |
| 5 | Session | Responsable de l’initialisation de la session, de sa gestion et de sa fermeture. |
| 4 | Transport | Choix du protocole de transmission et préparation de l’envoi des données. Elle spécifie le numéro de port utilisé par l’application émettrice ainsi que le numéro de port de l’application réceptrice. Elle fragmente les données en plusieurs séquences (ou segments). |
| 3 | Réseau | Connexion logique entre les hôtes. Elle traite de tout ce qui concerne l’identification et le routage dans le réseau. |
| 2 | Liaison de données | Établissement d’une liaison physique entre les hôtes. Fragmente les données en plusieurs trames. |
| 1 | Physique | Conversion des trames en bits et transmission physique des données sur le média. |
Processus de transmission/réception
Quand un hôte A envoie un message à un hôte B, le processus d’envoi va de la couche 7 (application) à la couche 1 (physique). En revanche, quand il s’agit de recevoir, le message emprunte le chemin inverse : il part de la couche 1 (physique) pour arriver à la couche 7 (application). Souvenez-vous de l’exemple de Pierre, Jacques et le facteur : Pierre quittait le salon pour le portail afin d’envoyer sa lettre, alors que le facteur quittait le portail et se dirigeait vers le bureau de Jacques pour la délivrer.

TCP/IP vs OSI : le verdict ?
Vous vous êtes peut-être posé la question de savoir pourquoi le titre de ce chapitre était Ils en tiennent une couche : OSI et TCP/IP, alors que ce dernier semble être passé aux oubliettes. Nous allons bien étudier deux modèles différents : TCP/IP et OSI. Nous allons commencer par revoir leurs origines et le but de leur création, ensuite nous comparerons leurs architectures respectives.
Il y a une génération…
Le modèle TCP/IP fut créé dans les années 1970 par le département de la Défense des États-Unis d’Amérique, plus précisément par l’agence DARPA (Defense Advanced Research Projects Agency). C’est pour cette raison que vous le trouverez aussi sous l’appellation DoD Model pour Department of Defense Model (« modèle du département de la Défense »). Quant au modèle OSI, il a été créé en 1978 par l’Organisation internationale pour la standardisation (ou ISO, International Organization for Standardization). C’est un certain Charles Bachman qui proposa la segmentation de la communication dans un réseau en sept couches distinctes.
Les buts de ces deux modèles ne sont pas les mêmes. En effet, le modèle OSI a été développé à vocation normative, c’est-à-dire pour servir de référence dans le déroulement de la communication entre deux hôtes. D’ailleurs, il est également connu sous les noms OSI Reference model (« modèle de référence OSI ») ou OSI-RM. Alors que le modèle TCP/IP a une vocation descriptive, c’est-à-dire qu’il décrit la façon dont se passe la communication entre deux hôtes. En d’autres termes, si vous voulez comprendre comment se déroule la communication « sur le terrain », prenez le modèle TCP/IP. Par contre, si vous voulez comprendre la suite logique, la procédure selon la norme, penchez-vous sur le modèle OSI. Ceci dit, c’est le modèle OSI qui vous servira de « plan » si vous voulez créer un protocole ou un matériel en réseau.
Il se peut qu'Internet Reference Model fasse parfois référence au modèle TCP/IP. Cette appellation n’est pas fausse, mais inexacte : la suite protocolaire TCP/IP sert de description plutôt que de référence.
Comparaison dans la structure
Voici un schéma comparatif des deux modèles.
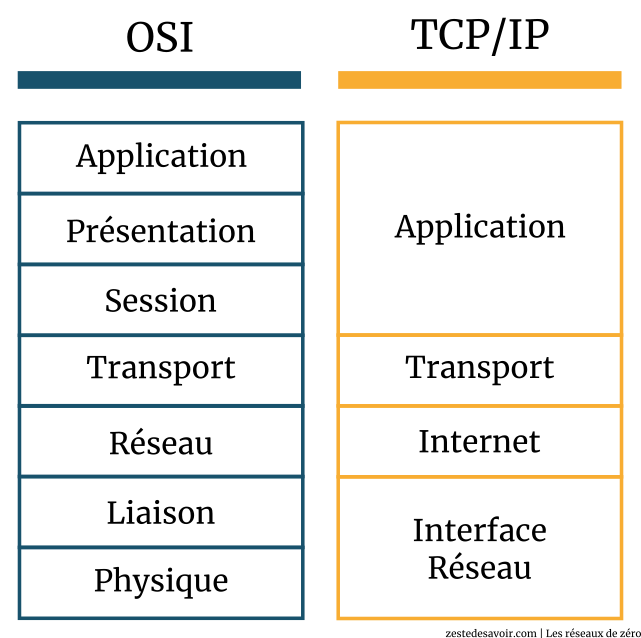
Comme vous le voyez, le modèle TCP/IP n’est constitué que de quatre couches. Ce sont des couches d’abstraction, autrement dit des couches qui cachent les détails d’implémentation de la communication et leurs noms ne reflètent pas mot pour mot les fonctions qu’elles assurent. Le modèle OSI, quant à lui, est fièrement constitué de sept couches. Les trois premières couches du modèle OSI correspondent à la couche applicative du modèle TCP/IP.
Cette correspondance ne veut pas dire que la couche applicative du modèle TCP/IP soit une synthèse des trois premières couches du modèle OSI. Non ! Elle ne remplit que les rôles des couches application et présentation du modèle OSI, comme le spécifie la RFC 1122.
Le formatage des données dans le modèle TCP/IP peut également se faire via des bibliothèques.
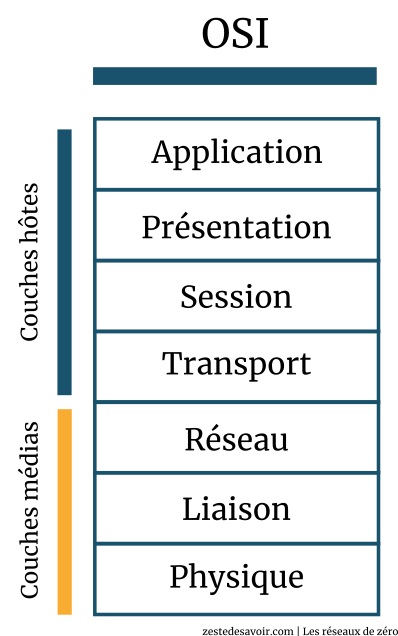
Les deux modèles possèdent une couche de transport. La couche réseau du modèle OSI correspond à la couche Internet(work) du modèle TCP/IP. Les couches liaison de données et physique du modèle OSI forment une seule couche pour le modèle TCP/IP : interface réseau. Les couches application, présentation, session et transport sont dites « couches hôtes » (host layers en anglais). En effet, ces couches « concernent » directement les hôtes. Les couches réseau, liaison et physique, elles, sont des couches de médias (media layers) : elles sont plus liées au média qu’à l’hôte. Voici un schéma illustrant cette correspondance :
Point vocabulaire : les unités de données
Au début de la communication entre deux hôtes, chaque information qui sera transmise est une donnée. Cependant, cette donnée a plusieurs unités selon la couche dans laquelle elle se trouve : il s’agit de la même donnée, mais sous plusieurs appellations. Prenons un exemple : votre père, vous l’appelez papa à la maison. Au travail, on l’appelle M. X ; chez son frère, ses neveux l’appellent tonton, etc. C’est bien la même personne, connue sous plusieurs appellations selon le milieu.
Ainsi, les données que vous transmettez sont tout simplement appelées unité de données (data unit en anglais). On les nomme parfois PDU (Protocol Data Unit : « unité de données de protocole ») ; dans ce cas, leur nom sera précédé de l’initiale de la couche dont ces données sont issues. Par exemple dans la couche applicative, elles prennent le nom d’APDU (Application Protocol Data Unit : « unité de données de protocole d’application »). Dans la couche de session, elles s’appelleront donc… SPDU (Session Protocol Data Unit : « unité de données de protocole de session »). Même principe pour la couche de présentation. Une fois dans la couche de transport, où elles sont segmentées, ces données deviennent logiquement des segments. (Nous les avons appelés séquences dans le chapitre précédent.)
L’appellation TPDU (Transport Protocol Data Unit) est également correcte en ce qui concerne la couche de transport.
Dans la couche réseau du modèle OSI, ces données prennent le nom de paquets ; dans les couches liaison et physique, respectivement ceux de frame (trame) et bit.
Voici une image résumant cela pour votre plus grand plaisir. Les acronymes dans l’image ci-dessous sont en anglais parce qu’ils sont plus courts.  Vous ne devriez pas avoir de difficulté à les comprendre puisque leurs équivalents français sont juste plus haut.
Vous ne devriez pas avoir de difficulté à les comprendre puisque leurs équivalents français sont juste plus haut.
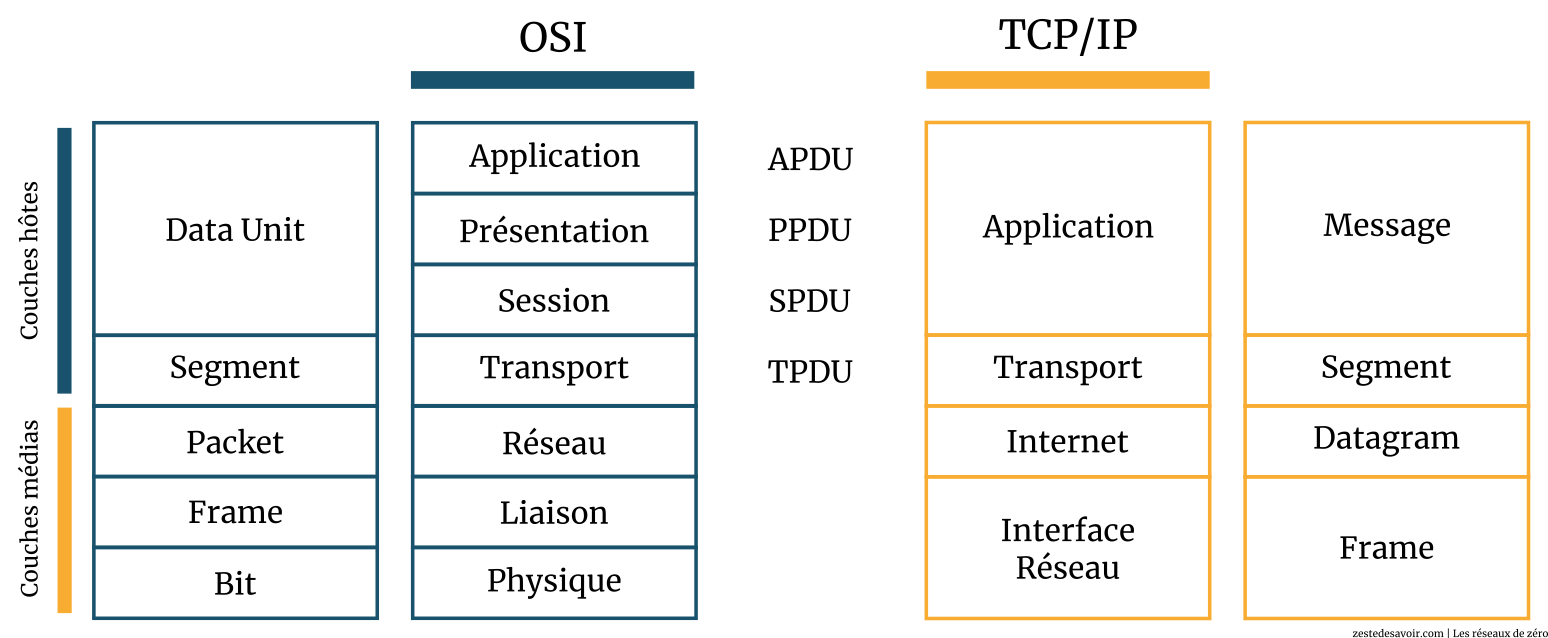
Vous pouvez remarquer la présence de datagram dans le schéma. Datagram (datagramme) est le nom donné à un PDU transmis par un service non fiable (UDP par exemple). On pourra, dans certains cas, retrouver ce terme sur la couche transport. Mais le moment n’est pas encore venu.
Tout au long du tutoriel, nous utiliserons souvent les mots « données » et « paquets » pour faire référence à toute information qui se transmet. Vous vous rendrez vite compte qu’il est difficile de faire autrement. L’utilisation du mot approprié interviendra lorsqu’elle sera de rigueur.
Faites attention à l’abstraction des noms de couches
Les noms des couches des modèles TCP/IP ou OSI sont abstraits, voilà pourquoi nous vous avons parlé de couches d’abstraction. Leurs noms ne sont pas toujours synonymes de leurs fonctions et peuvent par moments être vagues. Par exemple, la couche application du modèle OSI ne veut pas dire grand-chose. Quand vous lisez application, est-ce que cela vous donne une idée de la fonction de cette couche ? Ce nom n’est pas si explicite. La couche transport des deux modèles est certainement la plus abstraite dans sa dénomination. Quand on lit transport, on a tendance à croire que cette couche transporte vraiment les données jusqu’à son destinataire — alors que la transmission s’effectue à la couche 1 (physique) du modèle OSI et à la couche interface réseau du modèle TCP/IP. Par contre, la couche réseau est la moins abstraite, l’on comprend tout de suite qu’il s’agit de l’exercice des fonctions intimement liées au réseau.
Critiques du modèle OSI
En dehors de l’abstraction des noms de couches, dont le modèle TCP/IP est également coupable, les reproches faits à ce modèle relèvent de quatre domaines : la technologie, l’implémentation, la durée de recherche et l’investissement.
La technologie
Par technologie, nous voulons parler de degré de complexité. Le modèle OSI est plus complexe que le modèle TCP/IP. En effet, sept couches contre quatre : y a pas photo ! Cette complexité peut faire douter de l’utilité de certaines couches. Par exemple, les couches présentation et session sont assez rarement utilisées. Lorsque l’ISO a voulu « neutraliser » la normalisation/standardisation du modèle OSI, les Britanniques n’ont pas hésité à demander la suppression de ces couches-là. Comme nous l’avons vu en survolant les couches de ce modèle, certaines fonctions se partagent entre plusieurs niveaux. Par conséquent, la complexité même du modèle OSI réduit l’efficacité de la communication.
L’implémentation
À cause de la complexité de ce modèle, ses premières implémentations ont été très difficiles, lourdes et surtout lentes.
La durée et l’investissement
En technologie, il faut sortir le bon produit au bon moment, n’est-ce pas ? OSI n’a pas respecté cette règle. Les recherches de l’ISO pour mettre au point un modèle normalisé ont pris du temps : OSI est sorti alors que le modèle TCP/IP était déjà utilisé. De ce fait, l’ISO a rencontré des difficultés pour trouver un investissement, le monde n’étant pas tellement intéressé par une deuxième suite de protocoles.
Critiques du modèle TCP/IP
N’allez pas croire que le modèle TCP/IP est parfait ! Nous pouvons lui reprocher plusieurs choses :
- Contrairement au modèle OSI, TCP/IP ne distingue pas clairement le concept de services réseaux, des interfaces et des protocoles. Par conséquent, il ne respecte même pas la bonne procédure de l’ingénierie logicielle.
- Le modèle TCP/IP est un peu « carré ». Nous voulons dire par là qu’il est tellement spécifique que l’on ne peut pas se servir de ce modèle pour en décrire un autre, alors que le modèle OSI peut être utilisé pour décrire le principe du modèle TCP/IP.
- Interface réseau : c’est ainsi que l’académie Cisco appelle cette couche du modèle TCP/IP. La RFC 1122 la nomme tout simplement lien ; on la trouve aussi sous l’appellation hôte-à-réseau (host-to-network). Cette couche a été fortement critiquée parce qu’il ne s’agit pas d’une couche à proprement parler, mais d’une interface entre le réseau et la liaison de données.
- Le modèle TCP/IP ne fait pas la distinction entre la couche physique et la couche liaison de données. En principe, la couche physique devrait être une couche à part, car elle « conclut » la transmission grâce à la mise sur média.
Et maintenant : le verdict des juges
Après avoir comparé les deux modèles, l’heure est à la sanction au verdict !
En conclusion à cette analyse/critique des deux modèles, il est clair que TCP/IP a plus de succès qu’OSI. Mais ce succès est simplement dû au fait que les protocoles de ce modèle sont les plus utilisés. Sans ses protocoles, le modèle TCP/IP serait pratiquement inexistant. Par contre, le modèle OSI, avec ou sans protocoles, est la parfaite norme dictant la procédure de communication. Plusieurs personnes ont sanctionné le modèle OSI au profit de TCP/IP et, d’après elles, TCP/IP gagnerait ce duel.
Le paragraphe suivant a été écrit par Jean Pouabou, auteur historique du cours
Cependant, je ne partage pas cet avis, et après quelques recherches fructueuses, je me déclare pro-OSI. Je voterais même pour le remplacement du modèle TCP/IP. La seule chose que je peux reprocher au modèle OSI, qui est encore d’actualité, est la présence des couches présentation et session — qui sont presque inutiles. Sans elles, le modèle OSI serait, pour moi, le modèle idéal. Cette conviction est également fondée sur le rapport analytique publié en 2004 par Internet Mark 2 Project, intitulé Internet Analysis Report 2004 - Protocols and Governance (« Rapport de l’analyse d’Internet - Protocoles et gouvernance »). Vous pouvez télécharger un résumé de ce rapport gratuitement ici et le rapport complet (en anglais) se trouve là.
L’analyse en soi est très critiquable. À votre niveau, vous ne serez peut-être pas capable d’en proposer une autre. Ce n’est pas grave. Cependant, notez qu’il y a matière à réflexion dans certaines remarques.
Si le modèle OSI est meilleur que le TCP/IP, pourquoi ce dernier a-t-il plus de succès ?
TCP/IP est sorti, et fut donc largement utilisé, avant le modèle OSI. De cette utilisation massive découle une complexité de migration vers un autre modèle, d’où le maintien du succès de TCP/IP.
Je ne comprends pas l’anglais, mais je veux lire le rapport de l’analyse. Une solution ?
Oui : apprendre l’anglais !
Principe d'encapsulation
Chaque couche du modèle OSI a une fonction déterminée. Nous avons vu que la couche en cours utilise les services de la couche au-dessous d’elle qui, à son tour, en offre pour la couche du dessous. Cette corrélation indique bien que certaines informations peuvent se retrouver d’une couche à une autre. Cela n’est possible que grâce au principe d’encapsulation.
L’encapsulation consiste à encapsuler. En d’autres termes, elle consiste à envelopper les données à chaque couche du modèle OSI.
Quand vous écrivez une lettre (pas un mail), vous devez la glisser dans une enveloppe. C’est à peu près le même principe dans le modèle OSI : les données sont enveloppées à chaque couche et le nom de l’unité de données n’est rien d’autre que le nom de l’enveloppe. Nous avons vu dans la sous-partie précédente que, dans la couche applicative, l’unité de données était l’APDU (ou plus simplement le PDU). Ensuite, nous avons vu que dans la couche réseau, l’unité de données était le paquet. Ces PDU forment une sorte d’enveloppe qui contient deux choses : la donnée en elle-même et l’en-tête spécifique à cette couche. La partie « donnée » de ce paquet est composée de la donnée initiale, mais aussi des en-têtes des couches qui la précèdent. Il existe une toute petite formule mathématique définissant la relation entre les couches. Ce n’est pas difficile, pas la peine de fuir !
Considérons l’image ci-dessous :
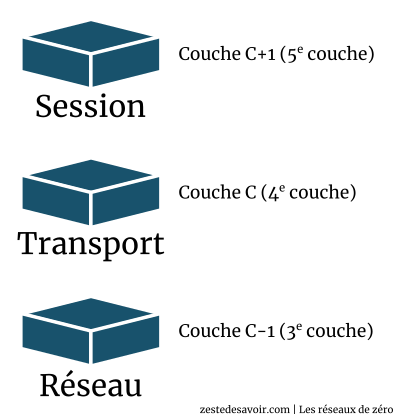
Soit C une couche du modèle OSI. La couche C + 1 utilise les services de la couche C. Facile, n’est-ce pas ? La couche session utilise les services de la couche transport, par exemple. La donnée que la couche C + 1 transmet à la couche C est appelée SDU tant qu’elle n’a pas encore été encapsulée par cette dernière. Si, par contre, la couche C encapsule ce SDU, on l’appelle désormais… PDU.
Quelle est donc la relation entre le PDU et le SDU ?
Dans une couche C, le PDU est le SDU de la couche C + 1 plus son en-tête (couche C). Ce SDU ne devient un PDU qu’après l’encapsulation. La couche C ajoute des informations dans l’en-tête (header) ou le pied (trailer), voire les deux, du SDU afin de le transformer en un PDU. Ce PDU sera alors le SDU de la couche C - 1. Donc le PDU est un SDU encapsulé avec un en-tête.
Voici la constitution d’un PDU :

Comprendre la relation entre un SDU et un PDU peut être complexe. Pour vous simplifier la tâche, nous allons considérer un exemple inspiré du monde réel et vous aurez ensuite droit à un schéma.
Nous classons l’exemple ci-dessous entre les catégories « un peu difficile » et « difficile ». Il est important de ne pas admirer les mouches qui voltigent dans votre bureau en ce moment. Soyez concentrés.
Quand vous écrivez une (vraie) lettre, c’est un SDU. Vous la mettez dans une enveloppe sur laquelle est écrite une adresse. Cette lettre qui n’était qu’un SDU devient un PDU du fait qu’elle a été enveloppée (encapsulée). Votre lettre arrive à la poste. Un agent du service postal regarde le code postal du destinataire et place la lettre dans un sac. Mais on ne la voit plus, puisqu’elle est dans un sac. Pour l’instant, la lettre, l’enveloppe et le sac forment un SDU. L’agent du service postal va alors inscrire le code postal du destinataire sur le sac en question, qui devient donc un PDU. S’il contient d’autres lettres partant pour la même ville, elles seront alors toutes mises dans une caisse : c’est un SDU. Tout comme on a ajouté des informations sur l’enveloppe et sur le sac, il faut également mettre un code postal sur la caisse. Cet ajout fait de cette caisse un PDU.
Voilà pour la procédure de transmission. Mais pour la réception, les sacs à l’intérieur de la caisse (des SDU) sont enlevés lorsqu’elle atteint sa destination. Attention, c’est ici que vous devez être très attentif·ve. Si un individu prend un sac et en lit le code postal pour l’acheminer à son destinataire, le sac n’est plus considéré comme un SDU mais comme un PDU. C’était un SDU au moment de sa sortie de la caisse. Étant donné qu’il y a des informations de plus sur le sac, c’est un PDU pour celui qui les lit.
Lorsque le destinataire recevra la lettre, les informations ajoutées sur le sac ou sur la caisse ne seront plus visibles : il ne restera plus qu’une enveloppe contenant la lettre originale (un SDU).
Tenez, un schéma illustrant l’encapsulation des SDU dans le modèle OSI :
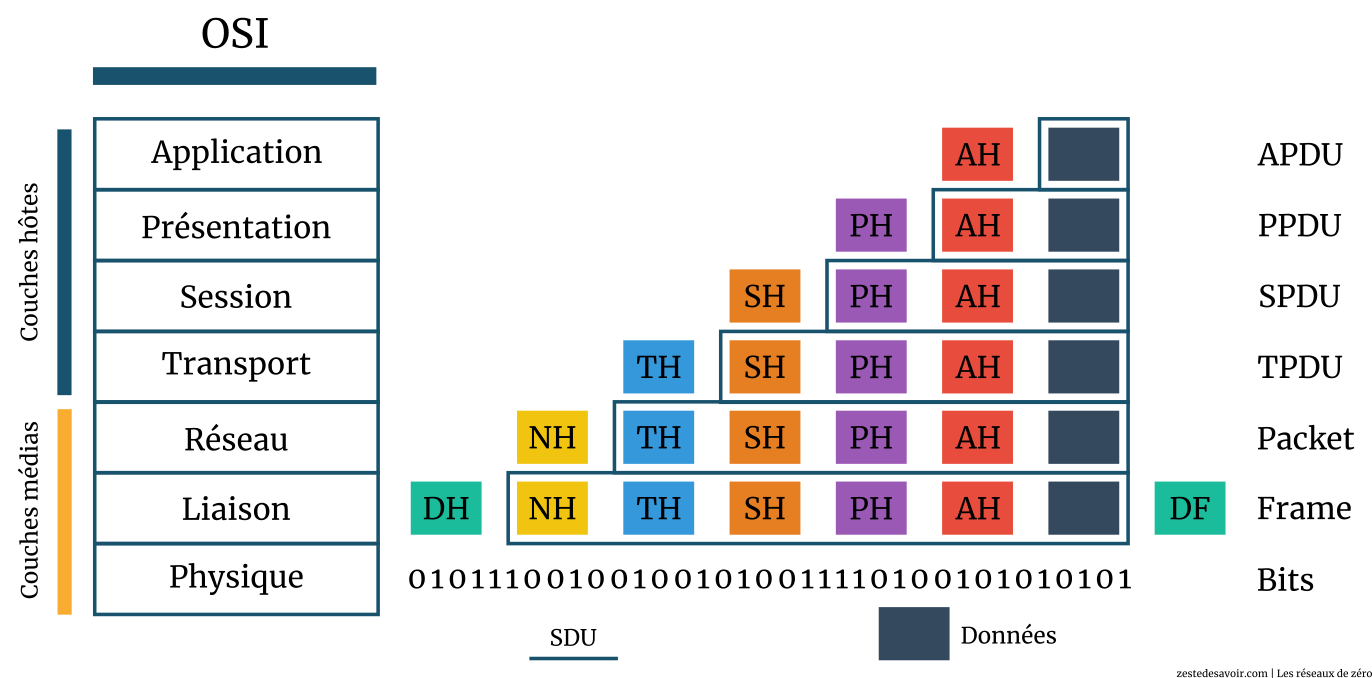
Dans le schéma ci-dessus, DF signifie Data link Footer. Le terme n’est pas exact, mais nous l’utilisons pour faciliter votre compréhension. Le vrai terme français qui équivaut au mot trailer est « remorque ». Une remorque est un genre de véhicule que l’on attèle à un autre véhicule ; la remorque est en quelque sorte la queue ou le footer du véhicule principal. Il est donc plus facile d’utiliser footer plutôt que trailer, le mot pied plutôt que remorque.
Tous les éléments encadrés en bleu forment un SDU, comme le stipule la légende.
Comme vous le voyez, au début nous n’avons que les données initiales, que l’on pourrait également appeler données d’application. La donnée initiale à ce stade est un SDU. Une fois dans la couche applicative, un en-tête AH (Application Header : « en-tête d’application ») est ajouté à cette donnée initiale. La donnée de la couche applicative est un APDU. La couche applicative transmet cela à la couche de présentation au-dessous. Cette donnée transmise est un SDU. Par l’encapsulation, cette couche ajoute un en-tête PH au SDU de la couche applicative. La couche de présentation envoie ce « nouveau » message à la couche de session et cette dernière encapsule son header avec le SDU obtenu de la couche présentation pour former son SPDU. Et ainsi de suite jusqu’à la couche liaison, qui a la particularité d’ajouter également un trailer. Finalement, toutes ces données sont converties en une série de bits et mises sur le média pour la transmission.
Une couche ne doit pas connaître (ne connaît pas) l’existence de l’en-tête ajouté par la couche au-dessus d’elle (la couche C + 1). En fait, cet en-tête, par l’encapsulation, apparaît comme faisant partie intégrante de la donnée initiale. Par conséquent, la couche ignore qu’il s’agit d’un en-tête, mais elle le considère comme appartenant aux données à transmettre.
Vous pouvez également constater que toutes les informations ajoutées dans la couche supérieure se retrouvent dans la couche inférieure. Ainsi dans la couche réseau, par exemple, on retrouve la donnée initiale + l’en-tête d’application (AH) + PH + SH + TH. Toutes ces « informations » seront considérées par la couche réseau comme la donnée initiale. Dans cet exemple, la couche réseau ne s’occupe donc que de son propre en-tête.
Si, à chaque couche, l’en-tête est ajouté à la donnée initiale, ne serait-ce pas compromettre l’intégralité du message ?
Qui peut répondre à cela ? Très belle question, soit dit en passant. Chaque couche ajoute à la donnée initiale un en-tête. De la sorte, tous les en-têtes sont réunis dans la couche de liaison. Lorsque ces informations seront converties en une suite de bits, le récepteur devrait recevoir des données erronées puisque la donnée initiale n’avait pas tous ces en-têtes, n’est-ce pas ? En principe. Mais le modèle OSI (ou le modèle TCP/IP) est assez intelligent. En effet, dans la procédure de réception, chaque en-tête est enlevé lorsque le message « grimpe » les couches, tel qu’illustré par le schéma ci-dessous. Cette « suppression » d’en-tête, c’est la décapsulation !
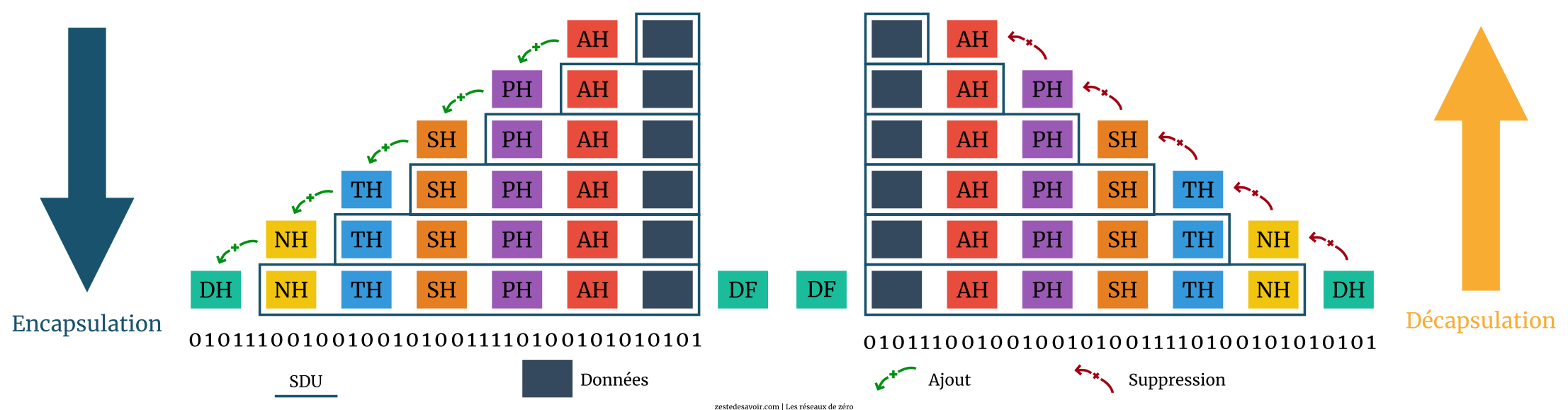
Comme vous le voyez sur le schéma, dans la procédure de réception, chaque couche supprime son en-tête correspondant après l’avoir lu. Par exemple, l’en-tête NH (réseau) est supprimé dans la couche réseau de l’hôte récepteur après que ce dernier l’a lu.
Maintenant que vous savez à quoi il sert, nous allons entrer dans les coulisses du modèle OSI par le haut. Pourquoi pas par le bas ? Parce qu’il est plus facile de descendre des escaliers que de les monter. Parce que nous estimons qu’il est plus intéressant de commencer par ce qui est plus proche de nous, à savoir les applications que nous utilisons.