Entre un fichier exécutable sur le disque dur et un programme en cours d'exécution, il y a un monde. Le fichier exécutable doit être copié en mémoire RAM par le chargeur de programme, le système d'exploitation doit gérer tout ce qui a trait à l'allocation mémoire, configurer certaines de ses structures et j'en passe et des meilleures. Le résultat final de ces opérations est ce qu'on appelle un processus, un programme chargé en mémoire et en cours d’exécution sur l'ordinateur.
Pour manipuler des processus, l'OS doit mémoriser des informations sur eux : à quel fichier exécutable correspond le processus, où se situe-t-il en mémoire et ainsi de suite. Toutes ces informations sont stockées dans ce qu'on appelle un Process Control Block, une portion de la mémoire dans laquelle le système d'exploitation va stocker toutes les informations attribuées à un processus.
Vie et mort des processus
Création de processus
Les processus peuvent naître et mourir. La plupart des processus démarre quand l'utilisateur demande l’exécution d'un programme, n'importe quel double-clic sur une icône d’exécutable en est un bon exemple. Mais, le démarrage de la machine en est un autre exemple. En effet, il faut bien lancer le système d'exploitation, ce qui demande de démarrer un certain nombre de processus. Après tout, vous avez toujours un certain nombre de services qui se lancent avec le système d'exploitation et qui tournent en arrière-plan.
À l'exception du premier processus, lancé par le noyau, les processus sont toujours créés par un autre processus. On dit que le processus qui les a créés est le processus parent. Les processus créés par le parent sont appelés processus enfants. On parle aussi de père et de fils. Certains systèmes d'exploitation conservent des informations sur qui a démarré quoi et mémorisent ainsi qui est le père ou le fils pour chaque processus. L'ensemble forme alors une hiérarchie de processus.
Sur la majorité des systèmes d'exploitation, un appel système suffit pour créer un processus. Mais certains systèmes d'exploitation (les unixoïdes, notamment) ne fonctionnent pas comme cela. Sur ces systèmes, la création d'un nouveau processus est indirecte : on doit d'abord copier un processus existant avant de remplacer son code par celui d'un autre programme. Ces deux étapes correspondent à deux appels systèmes différents.
Dans la réalité, le système d'exploitation ne copie pas vraiment le processus, mais utilise des optimisations pour faire comme si tout se passait ainsi.
Destruction de processus
Si les processus peuvent être créés, il est aussi possible de les détruire. De façon générale, un processus peut se terminer de deux façons :
- de façon normale (il a terminé son exécution) ;
- de façon anormale (le processus a commis une « faute », par exemple en tentant d'accéder à une zone mémoire protégée ou en réalisant une division par zéro, ou s'est trouvé en présence d'un problème ou d'une erreur l'empêchant de poursuivre).
Dans tous les cas, le processus père est informé de la terminaison du processus fils par le système d'exploitation. Le processus fils passe alors dans un mode appelé mode zombie : il attend que son père prenne connaissance de sa terminaison. Lorsque le processus se termine, le système récupère tout ce qu'il a attribué au processus (PCB, espaces mémoire, etc.), mais garde une trace du processus dans sa table des processus. C'est seulement lorsque le père prend connaissance de la mort de son fils qu'il supprime l'entrée du fils dans la table des processus.
Et si un processus père est terminé avant son fils, il se passe quoi ?
Bonne question ! Nous avons dit plus haut qu'un processus devait toujours avoir un père. C'est le processus qui est le père de tous qui « adopte » le processus qui a perdu son père et qui se chargera alors de le « tuer ».
Ordonnancement
Pouvoir lancer plusieurs programmes en même temps est quelques chose de commun. Mais tout cela doit pouvoir fonctionner avec des ordinateurs qui ne sont pourvu que d'un seul processeur. Or, un processeur ne peut exécuter qu'un seul programme à la fois (il existe toutefois des exceptions). Pour éviter tout problème, le système d'exploitation utilise une technique pour permettre la multiprogrammation sur les ordinateurs à un seul processeur : l'ordonnancement. Cela consiste à constamment switcher entre les différents programmes qui doivent être exécutés. Ainsi, en switchant assez vite, on peut donner l'illusion que plusieurs processus s'exécutent en même temps.
États d'un processus
Tous les programmes n'ont pas forcément besoin du processeur, certains attendent par exemple la réponse d'un périphérique et ne peuvent donc rien faire durant cette période. Pour éviter de les exécuter inutilement, l'OS se souvient que ces processus sont bloqués en attente des entrées-sorties. Même chose pour les programmes qui attendent le processeur : l'OS doit savoir quel est le programme en cours d’exécution et quels sont ceux qui attendent. Pour cela, on va donner à chaque processus un état qui permettra de savoir si notre programme veut s'exécuter sur le processeur.
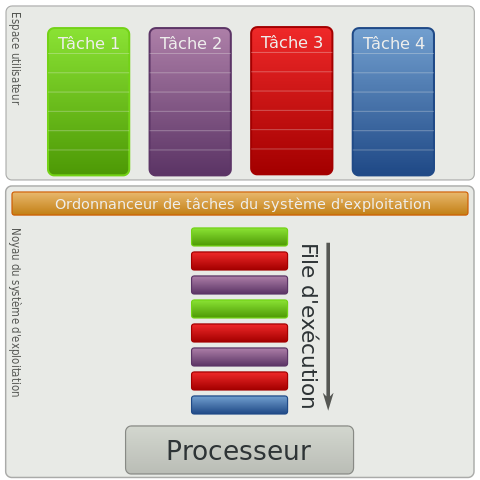
Un processus peut être dans (au moins) trois états :
- Élu : un processus en état élu est en train de s'exécuter sur le processeur.
- Prêt : celui-ci a besoin de s'exécuter sur le processeur et attend son tour.
- Bloqué : celui-ci n'a pas besoin de s'exécuter (par exemple, parce que que celui-ci attend une donnée en provenance d'une entrée-sortie).
Il arrive qu'un programme stoppe son exécution. Il peut y avoir plusieurs raisons à cela :
- il a besoin d'accéder à un périphérique et passe donc à l'état bloqué ;
- il n'a plus rien à faire et a fini (temporairement ou définitivement) son exécution ;
- il est interrompu par le système d'exploitation, histoire de laisser la place à un autre programme.

Sélection
Lors d'un changement d'état, le processus en cours d’exécution passe en état bloqué ou prêt. En même temps, un processus va passer de l'état prêt à l'état élu. Reste qu'il faut choisir un programme dans la liste d'attente et c'est le rôle d'un programme système spécialisé : l'ordonnanceur. Pour utiliser notre processeur au mieux, il faut faire en sorte que tous les processus aient leur part du gâteau et éviter qu'un petit nombre de processus monopolisent le processeur. Bien choisir le processus à exécuter est donc une nécessité.
On peut préciser qu'il existe deux grandes formes d'ordonnancements : l'ordonnancement collaboratif et l'ordonnancement préemptif. Dans le premier cas, c'est le processus lui-même qui décide de passer de l'état élu à l'état bloqué ou prêt. Pour ce faire, le programme en question doit exécuter un appel système bien précis qui rendra la main à l’ordonnanceur. Dans ces conditions, il n'est pas rare qu'un processus « un peu égoïste » décide de ne pas rendre la main et monopolise le processeur. Un bon exemple d'ordonnancement collaboratif n'est autre que les co-routines, des fonctionnalités de certains systèmes d'exploitations ou langages de programmation.
Avec l'ordonnancement préemptif, c'est le système d’exploitation qui stoppe l’exécution d'un processus. L'ordonnancement préemptif se base souvent sur la technique du quantum de temps : chaque programme s’exécute durant un temps fixé une bonne fois pour toute. En clair, toutes les « x » millisecondes, le programme en cours d’exécution est interrompu et l'ordonnanceur exécuté. Ainsi, il est presque impossible qu'un processus un peu trop égoïste puisse monopoliser le processeur au dépend des autres processus. La durée du quantum de temps doit être grande devant le temps mis pour changer de programme. En même temps, on doit avoir un temps suffisamment petit pour le cas où un grand nombre de programmes s'exécutent simultanément. Généralement, un quantum de temps de 100 millisecondes donne de bons résultats.
Divers algorithmes permettent de choisir un processus dans la file d'attente. Pour faire simple, on peut classer ces algorithmes en trois classes :
- traitement par lots ;
- traitement interactif ;
- traitement temps réel.
Nous n'aborderons pas le traitement temps réel, vu qu'il s'agit d'un cas assez spécial qui demanderait une petite connaissance de ce qu'est le temps réel et les contraintes associées. Mais nous allons voir le traitement par lots et le traitement interactif.
On peut préciser que certains algorithmes vont privilégier certains programmes sur d'autres. Chaque programme aura alors une priorité, codée par un nombre, plus ou moins grande. Plus celle-ci est grande, plus l'ordonnanceur aura tendance à élire souvent ce processus ou plus ce processus s’exécutera sur le processeur longtemps.
Traitement par lots
Tout d'abord, on va commencer par un système d'exploitation qui exécute des programmes les uns après les autres, jusqu’à ce qu'ils finissent leur travail ou décident eux-mêmes de stopper leur exécution, soit pour accéder à un périphérique, soit pour laisser la place à un autre programme. Ce genre de chose est notamment très utilisé dans les banques ou les grosses entreprises, pour sauvegarder les comptes ou mettre à jour de grosses bases de données.
Avec l'algorithme Premier arrivé, premier servi, l'ordonnanceur exécute le programme entré dans la file d'attente : les programmes sont exécutés dans l'ordre dans lequel ils sont rentrés dans la file d'attente. Cet algorithme est particulièrement trivial à programmer : une simple liste chainée suffit.
Avec l'algorithme Dernier arrivé, premier servi, l'ordonnanceur exécute le programme entré en dernier dans la file d'attente et non le premier. Cet algorithme peut souffrir d'un phénomène assez particulier : dans certains cas, un programme peut très bien mettre énormément de temps avant d'être exécuté. Si vous exécutez beaucoup de programme, ceux-ci seront rentrés dans la file d'attente avant les tout premiers programmes. Ceux-ci doivent alors attendre la fin de l’exécution de tous les programmes rentrés avant eux.
Avec l'algorithme du job le plus court en premier, on suppose que les temps d’exécution des différents programmes sont connus à l'avance et sont parfaitement bornés. Cette contrainte peut sembler absurde, mais elle a un sens dans certains cas assez rares dans lesquels on connait à l'avance le temps mis par un programme pour s’exécuter. Dans ce cas, l'algorithme est simple : on exécute le programme qui met le moins de temps à s’exécuter en premier. Une fois celui-ci terminé, on le retire de la file d'attente et on recommence.
L'algorithme Shortest Remaining Time Next est une variante préemptive de l'algorithme précédent. Le fonctionnement est donc identique, à un point de détail prêt : que se passe-t-il si un nouveau processus est ajouté ? Dans ce cas, on compare le temps d’exécution du processus ajouté avec celui du processus en cours d’exécution. Si le processus ajouté prend moins de temps, alors il est exécuté directement. Néanmoins, cet algorithme a un léger problème : dans certaines conditions, des processus peuvent attendre indéfiniment leur tour. En effet, il suffit pour cela d'ajouter en permanence de nouveaux processus plus prioritaires avant leur exécution, qui passeront systématiquement devant le processus en attente.
Traitement interactif
Maintenant, il est temps de passer aux algorithmes que l'on trouve sur nos OS actuels. Il s'agit des algorithmes destinés à des environnements multimédias où l'utilisateur veut une réactivité optimale.
Une première idée consiste à adapter l'algorithme du « job le plus court en premier » sur les systèmes interactifs. Le seul problème est que le temps d’exécution des processus n'est pas connu. La seule solution consiste à effectuer une estimation de ce temps d’exécution à partir des temps d’exécution précédents.
L'algorithme du tourniquet utilise la méthode du quantum de temps. Avec cet algorithme, chaque programme est exécuté l'un après l'autre, dans l'ordre. Quand son quantum se termine, le programme doit attendre que tous les autres programmes aient eu droit à leur tour. Pour cela, à la fin de chaque quantum de temps, on place le programme à la fin de la liste d'attente. Cet algorithme est redoutablement efficace et des OS comme Windows ou Linux l'ont utilisé durant longtemps. Mais cet algorithme a un défaut : le choix du quantum de temps doit être calibré au mieux et n'être ni trop court, ni trop long.
L'algorithme des files d'attentes multiple-niveau ordonnance aux mieux un ensemble de programmes aux temps d’exécution et aux particularités disparates en donnant la priorité aux programmes rapides et à ceux qui accèdent souvent aux périphériques.
Cet algorithme utilise plusieurs files d'attentes, classées de la plus basse à la plus haute, auxquelles ont donne des quantum de temps différents. Plus une file est haute, plus son quantum est petit. Quand on exécute un programme, celui-ci est placé dans la file d'attente la plus haute. Si un programme utilise la totalité de son quantum de temps, c'est le signe qu'il a besoin d'un quantum plus gros : il descend alors d'un niveau. La seule façon pour lui de remonter d'un niveau est de ne plus utiliser complètement son quantum de temps. Ainsi, un programme va changer de file suivant son temps d’exécution et se stabilisera dans la file dont le quantum de temps est optimal (ou presque).
Dans certaines variantes de cet algorithme, chaque file d'attente peut utiliser un algorithme d'ordonnancement différent ! L'utilité, c'est que chaque file aura un algorithme d’ordonnancement adapté pour des programmes plus ou moins rapides.
L'ordonnancement par loterie repose sur un ordonnancement aléatoire. Chaque processus se voit attribuer des tickets de loterie : pour chaque ticket, le processus a droit à un quantum de temps. À chaque fois que le processeur change de processus, il tire un ticket de loterie et le programme qui a ce ticket est alors élu. Évidemment, certains processus peuvent être prioritaires sur les autres : ils disposent alors de plus de tickets de loterie que les autres. Dans le même genre, des processus qui collaborent entre eux peuvent échanger des tickets. Comme quoi, il y a même moyen de tricher avec de l'aléatoire…
Changements d'états
Pour que notre programme puisse reprendre où il en était quand l'ordonnanceur lui redonne la main, il faut impérativement qu'un certain nombre de données soient restaurées. Par exemple, les registres du processeur doivent redevenir ce qu'ils étaient quand le programme a été interrompu. Le contexte d'exécution d'un processus est l'ensemble de ces informations. Ce contexte d’exécution est sauvegardé en RAM quand l’ordonnanceur interrompt l’exécution du programme. Pour reprendre l’exécution d'un programme là ou il en était, il suffit de remettre en place le contexte sauvegardé.
Une fois un processus élu, il doit être exécuté par notre processeur, c'est le rôle du dispatcher. Celui-ci stoppe le programme en cours d’exécution et restaure le contexte du programme élu. Le système d'exploitation doit donc mémoriser les contextes de tous les processus. Cette ensemble de contexte est appelé la table des processus. Certains systèmes d'exploitation utilisent deux listes : une pour les processus prêts et une autre pour les processus bloqués.
L'ensemble des processus prêts est ce qu'on appelle la file d'attente. Quand un programme démarre, celui-ci est ajouté à cette file d'attente. Les programmes ayant fini leur exécution ou qui passent en état bloqué sont retirés de la liste d'attente. Cette file d'attente est implémentée par ce qu'on appelle une liste chainée. Bien sûr, cette file d'attente n'accepte qu'un nombre limité de programmes : l'ordonnanceur décide toujours si oui ou non un programme peut être ajouté à cette liste et le nombre de programmes dans cette liste a une limite fixée par le système d'exploitation.
Communication entre processus
Dans les chapitres précédents, nous avons fait la confusion entre programmes et processus, notamment pour ce qui est de la protection mémoire. Nous avons dit que deux programmes ne pouvaient pas se marcher l'un sur l'autre, dans le sens où chaque programme n'a accès qu'à une portion de mémoire qui lui est dédiée et pas au reste de la mémoire. Cela vaut toujours pour les processus, qui sont placés dans des espaces mémoire dédiés où seuls eux peuvent écrire, on parle d'isolation des processus. Il faut cependant noter que tous les systèmes d'exploitation n'implémentent pas cette isolation des processus, MS-DOS en étant un exemple.
Avec isolation des processus
Des processus peuvent avoir besoin de s'échanger des données alors qu'ils s’exécutent sur un même ordinateur, ce qui est très compliqué sur les systèmes avec isolation des processus. Sur ces systèmes, on est obligé d'utiliser des mécanismes de communication entre processus. La méthode la plus simple consiste à partager un bout de mémoire entre processus, qui pourront lire ou écrire dedans pour échanger des données (cela peut être un fichier, un morceau de mémoire RAM, etc). Cette méthode pose toutefois des problèmes assez spécifiques et plutôt complexe, aussi, nous ne les aborderons pas ici. Mais il existe des méthodes plus simples, que nous allons voir maintenant.
Échange de messages
L'échange de messages est un autre moyen pour faire communiquer deux processus. Avec celui-ci, les processus s'échangent des blocs de données de taille fixe, appelés messages. Ce message contient des données, qui peuvent être de tout type simple (entier positif ou négatif, flottant positif ou négatif, caractère isolé ou chaine de caractères) ou une combinaison de ces éléments (plusieurs nombres, des nombres et une chaine de caractères, …). De plus, il contient un type, un entier positif, choisi par le programmeur, qui indique quel est le contenu du message. Il n'y a que trois restrictions sur le contenu du message :
- le type doit être présent ;
- le format des données doit être connu ;
- la taille des données doit être connue pour pouvoir être stockée par le processus qui recevra le message.
Sur certaines implémentations, les messages sont envoyés directement, sans aucune mise en attente. Le processus destinataire du message est alors prévenu qu'on souhaite communiquer avec lui et doit arrêter ce qu'il fait pour échanger avec l'émetteur du message. Dit autrement, les deux processus doivent se synchroniser pour l'échange. On parle alors tout simplement de passage de message. Cela fonctionne bien quand les deux processus ne sont pas sur le même ordinateur et communiquent entre eux via un réseau local ou par Internet.
Avec les tubes et les files de messages (message queue en anglais ou MSQ en abrégé), le processus destinataire d'un message et son émetteur n'ont pas besoin de se synchroniser. Il est dès lors possible d'envoyer un message sans avoir à prévenir le processus destinataire. Pour cela, les messages que s'envoient les processus sont mis en attente dans une file d'attente (tant que celle-ci n'est pas remplie, auquel cas le processus émetteur se bloque). Les processus destinataires peuvent consulter cette file de message quand ils le souhaitent, notamment pour voir si on leur a envoyé des données (si la file d'attente est vide, ils se bloquent en attendant des données qui leur sont destinés).
Dans tous les cas, les données envoyées via la file d'attente doivent de préférence être récupérées dans l'ordre d'envoi. Pour cela, le processus récupère systématiquement le message le plus ancien. Ainsi, les messages sont triés dans leur ordre d'envoi et sont retirés dans cet ordre par le processus destinataire. Notez que j'ai bien dit « retiré » et non pas « lus » : une fois qu'un message est consulté, il est retiré de la file. C'est ce qu'on appelle un fonctionnement « FIFO » pour First In First Out, premier entré, premier sorti.
Les tubes
Le premier type de file d'attente est celui des tubes. La différence entre les deux tient dans le fait que les tubes permettent à seulement deux processus de communiquer, qui plus est dans un seul sens, là où une file de message ne souffre pas de ces limites.
Il faut donc deux tubes pour que les deux processus s’échangent des informations dans les deux sens : l'un fonctionnant dans un sens et le second dans l'autre.
Il existe deux types de tubes : les tubes anonymes et les tubes nommés. Un tube anonyme n'est disponible que pour le processus qui l'a créé et ses fils. De plus, il est détruit sitôt qu'il n'a plus d'utilité. Toute rupture de communication (perte du processus qui lit ou ce celui qui écrit) entraine dès lors la fermeture du tube.
Un tube nommé est un tube qui permet la communication entre processus qui n'ont pas de lien de parenté. L'un d'eux écrit dans le fichier, l'autre lit ce fichier. Le tube reste en place une fois la communication terminée. Pour le reste, le fonctionnement est le même que pour un tube anonyme.
Les files de messages
Après avoir vu les tubes, il est temps de passer aux files de messages. On peut les voir comme un tube partagé entre plusieurs processus, chacun pouvant émettre à un ou plusieurs autres processus. De plus, chaque processus peut aussi bien lire qu'écrire dans la file de message.
Créer une file de message se fait assez simplement, souvent avec un appel système. Toutefois, il faut pouvoir identifier et sélectionner celle-ci parmi toutes les autres MSQ qui peuvent avoir été créées. Pour cela, le système d'exploitation utilise un système de clé, c'est-à-dire un nombre choisi par le programmeur ou qui est généré automatiquement. Avec cette clé on génère une MSQ qui sera identifiée par un numéro dans le système.
Une fois la MSQ en place, tout processus qui souhaite l'utiliser doit récupérer la clé de la file de messages. À partir de ce moment, les processus rattachés peuvent déposer ou récupérer un message. Pour récupérer un message, le processus se connecte à la MSQ et demande à récupérer les messages. Là encore, le processus récupère systématiquement le message le plus ancien.
Contrairement à ce qui se passe avec le passage de message, la file d'attente est persistante. Elle reste donc en place une fois créé, et doit être supprimée soit par l'un des processus soit par une action des administrateurs système. Cette caractéristique permet de déposer des messages même lorsque le processus receveur est absent (comme dans votre boite mail ou postale : vous recevez toujours le courrier même si vous n'êtes pas chez vous). En revanche, cela peut mener à la saturation de la table. Il faudra donc toujours veiller à supprimer une file de messages lorsqu'elle n'est plus utilisée. Attention que si une MSQ est supprimée, les messages qu'elle contenait au moment de la suppression sont perdus, sans possibilité de les récupérer.
Signaux
Enfin, il existe une dernière méthode de communication inter-processus : les signaux. Lorsqu'un processus souhaite signaler un évènement à un autre processus, il lui envoie un numéro appelé un signal. La plupart concernent des erreurs, c'est-à-dire qu'ils sont envoyés à un processus lorsque celui-ci commet une « faute », une opération interdite, mais ce n'est pas systématique. Il en existe plusieurs qui sont définis par le système d'exploitation. Le tableau d'exemple ci-dessous est celui des signaux du noyau Linux.
| Numéro (dépend de l'implémentation ou du processeur) | Nom | Signification |
|---|---|---|
| 1 | SIGHUP | Déconnexion du terminal ou mort du processus de contrôle |
| 2 | SIGINT | Interruption depuis le clavier |
| 3 | SIGQUIT | Quitter (depuis le clavier) |
| 4 | SIGILL | Instruction illégale |
| 5 | SIGTRAP | Un point d'arrêt a été trouvé |
| 6 | SIGABRT | Signal d'arrêt depuis la fonction abort() du langage C |
| 6 | SIGIOT | Synonyme de SIGABRT |
| 7 | SIGEMT | Terminaison |
| 8 | SIGFPE | Erreur mathématique en virgule flottante |
| 9 | SIGKILL | Signal KILL. Permet de terminer un processus en urgence |
| 10 | SIGBUS | Erreur de bus |
| 11 | SIGSEGV | Référence mémoire invalide |
| 11 | SIGSEGV | Référence mémoire invalide |
| 12 | SIGSYS | Mauvais argument de routine |
| 13 | SIGPIPE | Tentative d'écriture dans un tube sans lecteur à l'autre bout |
| 14 | SIGALARM | Envoyé quand un timer atteint la durée décomptée |
| 15 | SIGTERM | Terminaison normale de processus |
| 16, 10, 30 | SIGUSR1 | Au choix de l'utilisateur |
| 16 | SIGSTKFLT | Erreur de pile sur coprocesseur |
| 16, 23, 21 | SIGURG | Un socket a le flag "urgent d'activé |
| 17, 12, 31 | SIGUSR2 | Au choix de l'utilisateur |
| 17, 20, 18 | SIGCHLD | Processus fils arrêté ou terminé |
| 17, 19, 23 | SIGSTOP | Arrêt du processus |
| 18, 20, 24 | SIGTSTP | Stop déclenché depuis un terminal |
| 18 | SIGTSTP | Idem SIGCHLD |
| 19, 18, 25 | SIGCONT | Continuer si le processus est arrêté |
| 20, 21, 26 | SIGTTIN | Lecture depuis un terminal (en arrière-plan) |
| 20, 21, 26 | SIGTTOU | Écriture depuis un terminal (en arrière-plan) |
| 23, 29, 22 | SIGIO | Entrées-sorties à nouveau possibles |
| - | SIGPOLL | Idem SIGIO |
| 24, 24, 30 | SIGXCPU | Limite de temps CPU dépassée |
| 25, 31 | SIGFSZ | Taille de fichier excessive |
| 26, 28 | SIGVTALRM | Alarme virtuelle |
| 27, 29 | SIGPROP | Profile Alarm Clock |
| 28, 20 | SIGWINCH | Fenêtre redimensionnée |
| 29, 30, 19 | SIGPWR | Chute d'alimentation |
| 29 | SIGINFO | Idem SIGPWR |
| - | SIGLOST | Perte de verrou de fichier |
| 31 | SIGUNUSED | Signal inutilisé |
Un signal n'est pas toujours immédiatement transmis au processus concerné. En effet, celui-ci peut très bien être occupé et ne pas pouvoir le traiter directement. Il existe donc un système pour placer en attente ces signaux et les mettre à disposition du processus. Cette mise en attente prend la forme de drapeaux (flags), un par signal reçu. Si un signal a été reçu, on lève le drapeau correspondant à ce signal précis, sinon le drapeau reste baissé. Un signal qui est ainsi en attente et qui n'a pas encore été transmis est appelé un signal pendant.
Lorsque le processus est à nouveau disponible, il reçoit les signaux qui étaient en attente (on dit qu'ils sont délivrés au processus concerné). Cette transmission a lieu lors d'un retour du processus dans le mode utilisateur. À partir de ce moment, le processus peut :
- ignorer le signal (même si certains signaux ne peuvent pas être ignorés, comme SIGKILL et SIGCHLD) ;
- traiter le signal avec l'action définie par le système ;
- traiter le signal de façon spécifique.
Le programmeur du logiciel a la possibilité de traiter les signaux comme il l'entend, que ce soit pour ignorer le signal ou lancer une action spécifique. Dans le second cas, le programmeur peut prévoir une fonction pour gérer le signal reçu appelée un handler (gestionnaire) de signal.
Dans le cas où le programmeur n'a pas prévu d'action particulière pour un ou plusieurs signaux, le système d'exploitation a prévu une action par défaut, les plus courantes étant les suivantes :
- ignorer le signal ;
- la fermeture (abandon) du processus ;
- la fermeture du processus et l'écriture des causes dans un fichier spécifique appelé fichier core ;
- s'arrêter (se mettre en pause) ;
- reprendre (fin de la pause, au boulot !
 ) .
) .
Sans isolation des processus
Par convention, on qualifie de processus tout programme pour lequel il y a isolation des processus, les autres formes de programmes pouvant exister. Avec cette définition, un processus est simplement un fichier exécutable chargé en mémoire et isolé des autres processus/programmes. Mais cette définition ne dit pas que ce processus correspond à un seul programme qui s'exécute d'un seul bloc. Il est en effet possible de rassembler plusieurs programmes dans un seul processus : ces sous-programmes sont appelés des threads.
Les threads peuvent s'exécuter sur le processeur tout comme les processus : on peut ordonnancer des threads ou les exécuter en parallèle sur des processeurs séparés. Chaque thread possède son propre code à exécuter et sa propre pile d'appel. Cela facilite beaucoup la programmation d'applications qui utilisent plusieurs processeurs. Cependant, les threads doivent partager leur zone de mémoire avec les autres threads du processus : ils peuvent ainsi partager des données sans devoir passer par de lourds systèmes de communication inter-processus.
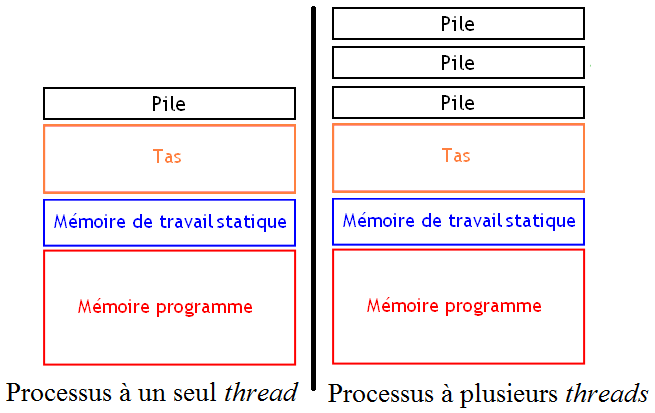
Le changement de contexte entre deux threads est beaucoup plus rapide que pour les processus. En effet, le fait que les threads se partagent la même mémoire évite certaines manipulations, obligatoires avec les processus. Par exemple, on n'est pas obligé de vider le contenu des mémoires caches sur certains processeurs. Généralement, les threads sont gérés en utilisant un ordonnancement préemptif, mais certains threads utilisent l'ordonnancement collaboratif (on parle alors de fibers).
Threads utilisateurs
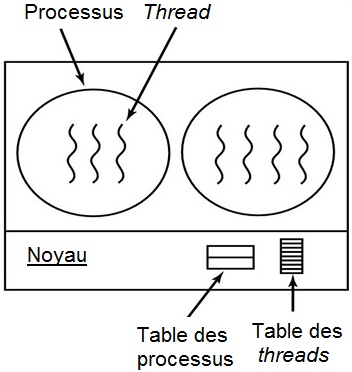
Les threads utilisateurs sont des threads qui ne sont pas liés au système d'exploitation. Ceux-ci sont gérés à l'intérieur d'un processus, par une bibliothèque logicielle. Celle-ci s'occupe de la création et la suppression des threads, ainsi que de leur ordonnancement. Le système d'exploitation ne peut pas les ordonnancer et n'a donc pas besoin de mémoriser les informations des threads. Par contre, chaque thread doit se partager le temps alloué au processus lors de l'ordonnancement : c'est dans un quantum de temps que ces threads peuvent s'exécuter.
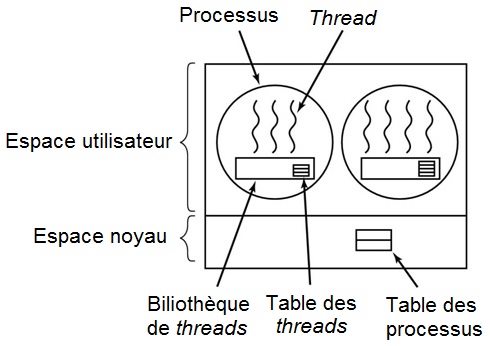
Threads noyaux
Les threads noyaux sont gérés par le système d'exploitation, qui peut les créer, les détruire ou les ordonnancer. L'ordonnancement est donc plus efficace, vu que chaque thread est ordonnancé tel quel. Il est donc nécessaire de disposer d'une table des threads pour mémoriser les contextes d'exécution et les informations de chaque thread.