- Premiers exemples de structures de données et d'algorithmes courants
- Une classe d'algorithme non naïfs : diviser pour régner
Maintenant que vous avez vos premières notions concernant ce qu'est la complexité algorithmique, il est temps de faire une introduction au concept de structure de données que l'on vous a fait miroiter dans l'introduction. Tout comme la première partie, nous ne ferons rien de compliqué pour l'instant, mais les bases présentées ici seront utiles pour la suite du cours.
Nous nous concentrerons sur deux structures extrêmement courantes : les listes (simplement chaînées) et les tableaux.
Définition
Le principe de base d'une structure de données, c'est de stocker des éléments auxquels le programmeur veut pouvoir accéder plus tard. On appelle les différentes utilisations possibles de la structure de données des opérations.
Par exemple, une opération courante est la lecture : on veut récupérer un élément stocké dans la structure. Il existe de nombreuses autres opérations, comme l'insertion, qui rajoute un nouvel élément dans la structure de données, ou la suppression, qui en enlève.
Toutes les structures de données ne permettent pas les mêmes opérations, et surtout elles n'ont pas toujours le même coût. Par exemple, sur certaines structures, il est très rapide d'ajouter un élément, dans d'autres c'est difficile et cela peut demander une réorganisation complète. Le coût des structures de données peut se mesurer assez finement, mais ce qui nous intéresse dans ce cours, c'est la complexité : pour chaque structure de données utilisée, on essaiera d'avoir une bonne idée de la complexité des opérations que l'on effectue.
Cette connaissance des coûts a deux intérêts : quand on nous donne un algorithme utilisant une structure de données particulière, on a besoin de connaître le coût (la complexité) des opérations effectuées pour évaluer la complexité globale de l'algorithme. Mais surtout, et c'est sans doute l'aspect le plus intéressant, quand on a une idée des opérations dont on a besoin pour un algorithme, on peut choisir la structure de données la plus adaptée (celle pour laquelle ces opérations sont les moins coûteuses).
Dans la pratique, la plupart des gens utilisent des algorithmes assez simples (qui ne reposent pas sur des manipulations sophistiquées), où le seul choix de la bonne structure de données peut faire la différence au niveau des performances. Bien connaître ses structures de données et savoir faire un choix joue donc un rôle très important pour le programmeur.
Tableaux
Le tableau est sans doute la structure de données la plus courante, du moins dans les langages dérivés ou inspirés par le langage C.
Le principe d'un tableau est très simple : on stocke les éléments dans des cases, chaque case étant étiquetée d'un numéro (généralement appelé indice). Pour accéder à un élément particulier d'un tableau, on donne son indice.
Les indices sont des entiers consécutifs, et on considérera qu'ils commencent à 0, comme dans la plupart des langages de programmation. Le premier élément est donc à l'indice 0, le deuxième à l'indice 1, etc. (attention au décalage). En particulier, si n est la taille du tableau, le dernier élément se trouve à l'indice n-1. Demander l'accès à un indice qui n'existe pas provoque une erreur.

On considère que la taille d'un tableau est toujours connue (le programmeur a dû la connaître quand il a demandé la création du tableau, et ensuite il suffit de la conserver).
Le temps de création du tableau dépend des langages. En général, la fonction de création met dans chaque case une valeur par défaut, et son temps d'exécution est alors proportionnel à la longueur du tableau (donc en complexité O(N) si N est la taille du tableau). Cependant, il est possible dans certains langages de créer des tableaux "non initialisés" (avec des valeurs inconnues pour chaque case) plus rapidement. C'est une pratique qui peut être dangereuse car on a alors parfois des valeurs qui n'ont aucun sens dans notre tableau. On considérera ici que tous les tableaux sont initialisés dès leur création, et donc qu'elle est toujours en O(N).
Listes
La liste est une structure de données extrêmement utilisée. En particulier, elle a joué un rôle majeur dans le langage Lisp et reste très présente dans les nombreux langages qui s'en sont inspirés.
Remarque : pour décrire correctement une liste, je suis forcé de m'écarter légèrement des pures considérations algorithmiques, pour détailler un peu plus précisément la manière dont les langages de programmation gèrent les structures de données. Je vais utiliser ici une description indépendante du langage de programmation : on parlera de cellules possédant un ou plusieurs champs. Une cellule est tout simplement un ensemble de cases qui permettent de stocker des données, et auxquelles on accède par leur nom (que l'on appelle nom du champ, comme les champs des formulaires par exemple). Par exemple, on pourra décrire une structure servant à stocker l'adresse et le numéro d'une personne comme une cellule à trois champs, nom, adresse et téléphone.
Selon votre langage, les cellules auront des formes différentes : struct en C, objets en Java, etc. : à vous de choisir la traduction qui vous plaît le plus. Nous ne rentrerons pas non plus dans les détails de bas niveau sur l'organisation mémoire, mais il est bon d'avoir un modèle commun pour pouvoir discuter.
On considérera de plus que la création (et la destruction) d'une cellule (si elle a un nombre fixé de champs), ainsi que la lecture ou la modification d'un champ, se fait en temps constant.
Venons-en maintenant à la définition d'une liste. Une liste est :
- soit la liste vide ;
- soit une cellule à deux champs, un champ
têtecontenant un élément, et un champqueuecontenant l'adresse d'une autre liste.
Autrement dit, une liste est "soit vide, soit un élément suivi d'une liste". Cette définition est amusante car elle est récursive : elle utilise le mot "liste". La définition d'une liste utilise la définition d'une liste ! Mais, de même que les programmes récursifs ne tournent pas tous en boucle à l'infini, cette définition n'est pas un cercle vicieux, et elle est tout à fait correcte (vous le verrez à l'usage).
Une liste peut donc être la liste vide (0 élément), ou un élément suivi de la liste vide (1 élément), ou un élément suivi d'un élément suivi de la liste vide (2 éléments), etc.
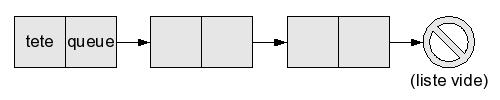
On dira que l'élément dans le champ tête est la tête de la liste, et que la liste dans le champ queue est sa queue. La queue d'une liste contient tous les éléments de la liste, sauf le premier. Par exemple, la queue de la liste [1; 2; 3] est [2; 3]. Bien sûr, la liste vide n'a ni queue ni tête : essayer d'accéder à un de ces champs provoque une erreur.
Il existe en réalité de nombreuses variantes de cette structure. J'ai décrit ici la plus simple, que l'on appelle aussi liste simplement chaînée car les cellules contiennent seulement, en plus d'un élément, une flèche vers le suivant (on imagine que ces flèches forment une chaîne). D'autres structures sont utiles dans des cas particuliers (par exemple on peut mettre deux flèches par cellule, une vers l'élément suivant, et une vers l'élément précédent, c'est le principe de la liste doublement chaînée), mais celle-ci est la plus courante et la plus utile.
Implémentation : la représentation des listes chainées dépend beaucoup des langages de programmation. Dans les langages fonctionnels, ce type est déjà défini (par exemple en Caml on note [] la liste vide et tete::queue la cellule dont la tête est tete et la queue queue. En C, il faut le construire soi-même. On utilise une représentation très classique : une structure pour les cellules, et le pointeur NULL pour la liste vide :
1 2 3 4 5 6 | struct list { int val; struct list *next; }; typedef struct list List; |
On représentes alors les listes comme des pointeurs vers une cellule :
1 | List *une_liste; |
Comme en C, il faut allouer et libérer la mémoire à la main, on aura aussi besoin d'une fonction qui libère toutes les cellules d'une liste :
1 2 3 4 5 6 7 8 | void free_list(List *list) { while (list != NULL) { /* tant que la liste n'est pas vide */ List *cell = list; list = list->next; free(cell); } } |
À chaque étape de la boucle while, on stocke la tête de la liste dans une variable cell, on avance dans la liste (list devient la queue de la liste), et on libère cell. On est obligé d'utiliser cette variable intermédiaire, parce que si on commençait par free(list), alors list->next n'aurait plus de sens (puisque list a été effacée) et on ne pourrait pas passer à la suite de la liste.
Ajout / retrait, taille, accès à un élément
Ajout / Retrait
Quelle est la manière la plus simple d'ajouter, ou d'enlever un élément à un tableau ou à une liste ?
Pour une liste, ces deux opérations sont très simples tant que l'on considère seulement un ajout (ou une suppression) en tête de liste : pour supprimer l'élément de tête, il suffit de remplacer la liste par sa queue (qui est la liste de tous les éléments suivants). Pour ajouter un élément en tête, il suffit de créer une nouvelle cellule, de mettre cet élément dans le champ tête, et la liste de départ dans le champ queue.
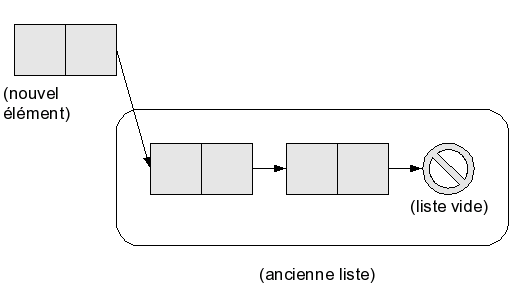
Ces deux opérations se font en temps constant (la première revient à lire un champ, et la deuxième à créer une cellule), donc leur complexité est en O(1).
Remarque : l'opération d'ajout en tête de liste (c'est-à-dire la création d'une nouvelle liste à partir d'un élément et d'une ancienne liste) est fondamentale dans les manipulations de liste. Elle possède un nom spécifique, cons (lire "consse"), qui a même donné lieu à un verbe (utilisé seulement en informatique) en anglais, to cons. Elle est fondamentale parce qu'en quelque sorte elle fait partie de la définition des listes, que l'on peut reformuler ainsi : soit une liste vide, soit un cons d'une liste.
Implémentation : Dans les langages où les listes existent déjà, il est extrêmement simple de définir cons. Par exemple en Caml :
1 | let cons tete queue = tete::queue |
Sinon, il faut utiliser le type que l'on a défini soi-même. En C, il faut en plus s'occuper de l'allocation mémoire :
1 2 3 4 5 6 7 8 9 | List *cons(int valeur, List *liste) { List *elem = malloc(sizeof(List)); if (NULL == elem) exit(EXIT_FAILURE); elem->val = valeur; elem->next = liste; return elem; } |
Pour les tableaux, la question est plus délicate. La taille d'un tableau étant fixée à l'avance, il n'est pas possible de rajouter des éléments (tout simplement parce qu'il n'y a pas forcément de place disponible dans la mémoire, sur les bords du tableau, pour pouvoir l'agrandir). La méthode sûre pour ajouter un (ou plusieurs) éléments est de créer un tableau plus grand autre part, qui contienne assez de place pour tous les anciens éléments et le (ou les) nouveau(x), et de recopier les anciens éléments dans le nouveau tableau, avant d'ajouter les nouveaux. Cette méthode demande la création d'un tableau de taille N+1, puis une recopie de chaque élément du tableau, elle est donc en O(N) (où N est la taille du tableau avant insertion), ou encore linéaire. De même, la taille d'un tableau étant fixée à l'avance, il n'est pas possible d'en retirer des cases.
Remarque : dans certains langages, il est possible d'essayer de redimensionner les tableaux sur place dans certains cas, ou bien d'éliminer des éléments qui sont en début ou en fin de tableau. Cela reste assez hasardeux, et nous ne considérerons pas ces opérations.
Taille
Quand il s'agit de calculer la taille de la structure de données, c'est le tableau qui a le beau rôle. En effet, on considère que la taille d'un tableau est toujours connue, donc il n'y a pas de calculs à faire pour l'obtenir : c'est une opération en O(1).
Pour une liste, on ne connaît pas en général la taille d'une liste (surtout si on vient d'ajouter ou d'enlever beaucoup d'éléments en tête de cette liste). Pour calculer la taille d'une liste, on applique l'algorithme suivant :
- si c'est la liste vide, sa taille est 0 ;
- sinon, on calcule la taille de sa queue, et on rajoute 1.
Ainsi, on va parcourir la liste jusqu'à tomber sur la liste vide, en rajoutant 1 pour chaque élément. Cette méthode marche très bien, mais demande un parcours complet de la liste, donc est en O(N) (où N est la taille de la liste).
Remarque : comme pour les tableaux, il serait possible de stocker la taille des listes dans la structure elle-même, au lieu de devoir la calculer à chaque fois : en plus d'avoir tête et queue, on ajouterait à chaque cellule un champ taille qui contiendrait la taille de la liste. Le problème de cette méthode est que l'opération cons devient plus coûteuse : quand on crée une nouvelle cellule pour l'élément à rajouter, il faut y mettre le nouvel élément et la queue comme auparavant, mais ensuite il faut accéder à la première cellule de la queue, pour y lire la taille N de l'ancienne liste, pour pouvoir mettre N+1 dans le champ taille de la nouvelle cellule. Cela ne fait que rajouter une étape (plus précisément, deux lectures de cellules, une addition et une initialisation de champ en plus), donc l'opération reste en O(1), mais cela ralentit quand même sensiblement l'opération, ce qui est gênant quand on utilise beaucoup cons. En pratique, la plupart des gens utilisent beaucoup cons, et ont très peu souvent besoin de la taille de la liste ; cette "optimisation" n'est donc pas intéressante, car elle ralentirait le programme. Encore une fois, on retrouve l'idée centrale, qui est qu'il faut choisir ses structures de données selon l'utilisation qu'on veut en faire, pour que les opérations les plus courantes soient les plus rapides possibles.
Accès à un élément
Comment faire si l'on veut récupérer par exemple le cinquième élément de notre collection (liste ou tableau) ? Pour un tableau, c'est simple : on demande l'élément d'indice 4 (attention au décalage), et on l'obtient immédiatement. Cette opération est en O(1).
Pour une liste, c'est plus difficile : quand on a une liste, on a accès directement à la première cellule, donc on ne connaît que sa tête, et sa queue ; on ne peut donner rapidement que le premier élément. Mais en fait, on peut aussi avoir accès au deuxième : c'est la tête de la queue de la liste  ! Et au troisième : la tête de la queue de la queue de la liste. En fait, on cherche la tête de la queue de la queue de la queue de la queue de la liste. Trop facile.
! Et au troisième : la tête de la queue de la queue de la liste. En fait, on cherche la tête de la queue de la queue de la queue de la queue de la liste. Trop facile.
Voici un algorithme pour récupérer l'élément d'indice n dans une liste :
- si
n = 0(on demande le premier élément), renvoyer l'élément qui est dans le champtête; - sinon, renvoyer l'élément qui est à l'indice
n-1dans la liste qui est dans le champqueue.
Vous pouvez remarquer qu'on considère directement notre liste comme une cellule : si la liste est vide, on ne peut pas y récupérer d'élément, donc c'est une erreur.
Pour accéder à un élément, il faut parcourir toute la liste jusqu'à la position voulue. Pour accéder à l'élément d'indice k il faut donc faire environ k opérations. Quelle est la complexité de l'opération ? Comme expliqué dans la première partie, il faut être pessimiste et considérer la complexité dans le pire des cas : dans le pire des cas, on cherche le dernier élément de la liste, il faut donc la parcourir toute entière. L'opération est donc linéaire, en O(N).
Vous avez sans doute remarqué la grande différence entre le problème de l'accès au premier élément, et l'accès à "n'importe quel" élément. Dans une liste, la première opération est en O(1) (  ) et la deuxième en O(N) (
) et la deuxième en O(N) (  ).
).
Pour bien les différencier, les informaticiens ont un terme spécifique pour dire "l'accès à n'importe quel élément" : ils parlent d'accès arbitraire. De nombreuses structures de données peuvent accéder à certains éléments privilégiés très rapidement, mais sont plus lentes pour l'accès arbitraire. Les tableaux ont la propriété d'avoir un accès arbitraire en temps constant, ce qui est rare et très utile dans certains cas.
Remarque : vous ne connaissiez peut-être pas le terme "accès arbitraire", mais vous avez sûrement déjà rencontré son équivalent anglais, random access. Ou alors, vous ne vous êtes jamais demandé, en tripotant la mémoire vive de votre ordinateur, ce que signifiait RAM : Random Access Memory, mémoire à accès arbitraire.
Le problème de l'accès à une liste ne se limite pas seulement à la lecture de l'élément à une position donnée : on pourrait aussi vouloir rajouter ou enlever un élément à cette position. Ces algorithmes sont proches de celui de lecture, et ont eux aussi une complexité linéaire.
Petite anecdote pour illustrer l'importance de l'étude de la complexité : lorsque nous ne travaillons pas sur ce tutoriel, il nous arrive de jouer. Parmi ces jeux, l'un d'entre eux avait un temps de chargement de 90 secondes dès qu'il fallait générer une nouvelle carte du monde. Un peu surpris, et étant donné que le code source du jeu était disponible, nous avons étudié la fonctionnalité fautive. Le jeu passait 88 secondes à accéder de manière aléatoire aux éléments d'une liste ! En transformant cette liste en simple tableau, le chargement est devenu quasi-instantané.  Les plus curieux peuvent aller étudier le changement effectué qui a été accepté par l'auteur du jeu vidéo en question.
Les plus curieux peuvent aller étudier le changement effectué qui a été accepté par l'auteur du jeu vidéo en question.
Concaténation, filtrage
Concaténation
Imaginons que l'on ait deux groupes d'éléments, stockés dans deux listes (ou deux tableaux) différents, et que l'on veuille les réunir. On veut construire une structure qui est en quelque sorte la "somme" des deux structures de départ. On appelle cette opération la "concaténation" (cela vient du latin pour "enchaîner ensemble").
Pour des tableaux, c'est assez facile : si le premier tableau est A, et le deuxième B, et que l'on note L la taille de A et L' (lire "L prime") la taille de B, on crée un tableau de taille L + L', où l'on recopie tous les éléments de A, puis tous les éléments de B. Cela demande L + L' copies (et la création de L + L' cases) : l'opération est en O(L + L').
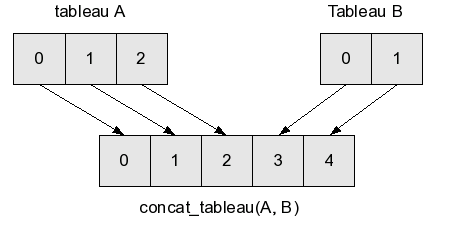
Remarque : j'ai ici donné la complexité en fonction de deux variables, L et L'. J'avais auparavant défini la complexité comme dépendant d'une seule variable, mais c'est un cas particulier. La complexité d'un algorithme peut dépendre de tous les paramètres dont dépend l'algorithme, et pas seulement d'un seul. De plus, la complexité n'a de sens que quand les variables que l'on utilise pour l'exprimer sont bien définies : dire O(N3) ne suffit pas, il faut s'assurer que tout le monde comprend ce que désigne la variable N (même si en général, c'est évident et laissé implicite).
Pour une liste, la situation est un peu différente : comme on peut facilement ajouter un élément en tête de liste, on peut aussi ajouter une suite d'éléments. Il suffit donc d'ajouter tous les éléments de A en tête de la liste B. Cela revient à faire une copie de A devant B. Vous pouvez déjà deviner (l'algorithme sera précisé ensuite) que comme on ajoute L (la taille de A) éléments en tête de B, la complexité sera en O(L).
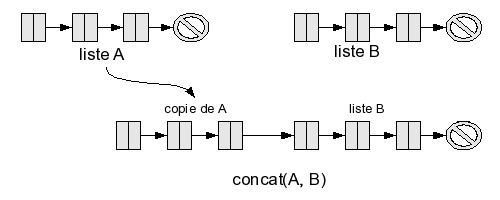
Voilà un algorithme plus détaillé effectuant la concaténation de A et de B :
- si elle est vide, on n'a rien à faire : on renvoie la deuxième liste, B ;
- si c'est une cellule, on procède en deux temps : - on calcule la concaténation de sa queue avec B,
- on rajoute la tête à ce résultat ;
On peut résumer cela par cons(tete(A), concat(queue(A), B)).
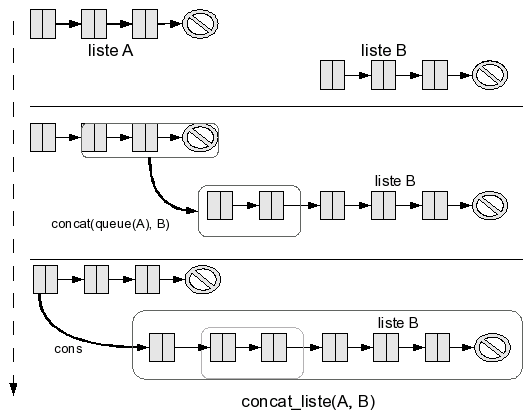
Encore une fois, cette fonction est récursive, je vous invite à vérifier qu'elle marche bien en l'implémentant vous-mêmes dans votre langage préféré. Quelle est sa complexité ? On va appeler la fonction concat une fois sur A, puis sur queue(A), puis sur queue(queue(A)), etc., jusqu'à parvenir à la liste vide. En d'autres termes, on aura appelé concat autant de fois que A a d'éléments. Le reste des opérations (effectuées à chaque appel de concat) est un cons (et la lecture de la tête), donc en O(1). Faire L (où L est la taille de A) fois une opération en O(1), c'est-à-dire L fois une opération en temps constant, met un temps proportionnel à L. C'est en O(L).
Remarque : avec cet algorithme, on recopie (par le cons) chaque cellule de la liste A : la liste B est laissée inchangée, mais on a créé L cellules. Vous avez peut-être remarqué qu'une autre manière de faire serait possible : on pourrait prendre directement la dernière flèche de A (celle qui pointe vers la liste vide), et la modifier pour la faire pointer vers la première cellule de B. Cette méthode a l'avantage de ne pas demander de recopie des cellules de A, mais aussi un inconvénient majeur : elle modifie la liste A. Si vous aviez une variable qui désignait A avant l'opération, elle désigne maintenant concat(A, B). La liste A, en quelque sorte, a été "détruite".
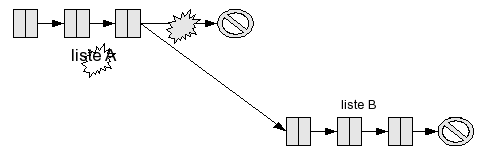
Ce comportement, que l'on appelle un effet de bord, peut donner lieu à des bugs si vous ne faites pas attention (par exemple si vous croyez avoir encore accès à A, alors qu'en fait vous êtes en train de manipuler concat(A, B)). Si l'on élimine la négligence du programmeur (parce que vous êtes sûrement persuadés que vous, vous ne faites pas ce genre d'erreurs - haha !), il peut encore se poser des problèmes délicats dans le cas d'applications multi-thread par exemple (un thread calcule le nombre d'éléments de votre liste, mais juste avant qu'il l'utilise pour faire quelque chose, un autre thread modifie silencieusement la liste en lui ajoutant plein d'éléments à la fin ; la taille calculée par votre premier thread n'est plus valide : boum !).
Globalement, l'algorithme présenté, qui a la propriété de ne pas modifier les listes A et B de départ, est beaucoup plus sûr et pratique à utiliser. Il en existe d'autres formulations, mais elles ont de toute manière toutes la même complexité.
Vous pouvez noter que la concaténation de deux listes ne dépend pas de la taille de la deuxième liste, qui est conservée à l'identique, mais seulement de la première. Pour les tableaux, la concaténation dépend des deux. C'est une différence qui peut être très importante si vous voulez concaténer très souvent de petites listes (ou de petits tableaux) à une grande liste (ou à un grand tableau). Dans le cas des tableaux, cette opération sera très coûteuse puisque vous devrez recopier le grand tableau à chaque fois. En pratique, il est donc assez rare de concaténer des tableaux, alors que l'opération est plus courante pour les listes.
Filtrage
Voici une dernière opération qui se présente régulièrement quand vous manipulez des données : sélectionner une partie d'entre elles. Par exemple "parmi les personnes que je connais, je veux le nom de toutes celles qui parlent allemand". En informatique, on représentera la question "est-ce qu'il parle allemand ou non ?" par une fonction : elle prend une personne en paramètre, et renvoie true (vrai) si elle parle allemand, false (faux) sinon. J'appelle ce genre de fonctions des "fonctions de choix" (on les nomme parfois aussi prédicats). On veut effectuer une opération de filtrage : étant donné une collection (liste ou tableau) contenant des éléments, et une fonction de choix sur ces éléments, vous voulez récupérer seulement les éléments pour lesquels la fonction de choix renvoie true.
Si l'on utilise des tableaux (en particulier si l'on veut que les résultats du filtrage soient stockés dans un tableau), on est confronté à un problème : on ne sait pas a priori quel sera le nombre d'éléments à renvoyer. Vous ne savez pas a priori, sans réfléchir ou leur poser la question, combien de vos connaissances parlent allemand. Il y a plusieurs possibilités. J'en citerai une seule pour l'instant (je parlerai d'une deuxième ensuite, et de toute façon si vous pensiez à une autre, c'est très bien).
La première possibilité consiste à partir d'un tableau de taille 0 (vide, quoi), en l'agrandissant à chaque fois que vous trouvez un nouveau germaniste dans vos connaissances. Comme on l'a vu, agrandir un tableau demande en général autant de recopies qu'il a de cases. À la première personne trouvée, vous ne ferez aucune recopie (créer un tableau de taille 1 pour mettre la personne). À la deuxième, vous ferez une recopie (la première personne trouvée). À la troisième, vous ferez 2 recopies. Au final, si le tableau filtré possède K éléments, il aura été construit en faisant 0, puis 1, puis 2, …, puis K-1 recopies, soit 0 + 1 + 2 + … + (K-1) recopies au total, c'est-à-dire environ K2 /2 recopies. Dans le pire des cas, K est égal à N, la taille du tableau de départ (toutes vos connaissances parlent allemand !), et vous avez environ N2 /2 opérations : cet algorithme est en O(N2 ).
On peut obtenir un algorithme intéressant pour les listes en appliquant exactement cette méthode, mais en utilisant des listes à la place de tableaux : on commence avec une liste vide, et pour chaque élément intéressant (c'est-à-dire qui fait renvoyer true à la fonction de choix), on l'ajoute en tête de la liste (par un cons). Chaque cons est en O(1), et au final on en fait au maximum N. L'algorithme utilisant une liste est donc en O(N). Il est assez frappant de voir qu'en utilisant exactement le même algorithme, on peut obtenir des complexités très différentes simplement en changeant de structure de données. Cela illustre le fait que le choix des structures est important, et que le programmeur doit en être conscient.
Pour sauver l'honneur des tableaux, il faut présenter un autre algorithme avec une complexité moins mauvaise que O(N2). On peut, tout simplement, parcourir notre collection d'éléments à filtrer une première fois pour compter le nombre d'éléments intéressants, créer un tableau de cette taille, puis la parcourir une seconde fois en ajoutant les éléments intéressants dans le tableau. On fait deux parcours, mais le nombre d'opérations reste proportionnel à N, donc cet algorithme est bien en O(N). J'ai sans doute dit plusieurs fois qu'on s'intéresserait seulement à la complexité, mais il est temps de faire une exception (car si on n'en faisait jamais, ça serait pas drôle) : cet algorithme demande deux parcours de la collection de départ, donc même s'il a la même complexité que l'algorithme utilisant des listes, il est beaucoup moins intéressant, et en particulier il sera en général plus lent. Il est de plus un peu moins résistant aux diverses situations bizarres qui pourraient se poser : si le tableau de départ est modifié entre les deux parcours, cela peut poser problème ; de plus, la fonction de choix sera appelée deux fois par élément au lieu d'une, ce qui peut être très embêtant si elle fait des choses bizarres (par exemple si elle stocke les éléments intéressants en refusant les éléments déjà rencontrés). Ce sont des problèmes auxquels il est possible de remédier, mais tout cela implique des complications supplémentaires, et peut-être une dégradation des performances.
Synthèse
Opérations
|
opération |
tableau |
liste |
|---|---|---|
|
accès arbitraire |
O(1) |
O(n) |
|
ajout |
O(n) |
O(1) |
|
taille |
O(1) |
O(n) |
|
concaténation |
O(n+m) |
O(n) |
|
filtrage |
O(n) |
O(n) |

On peut dégager une vue d'ensemble de ces deux structures de données : la liste est une structure à laquelle il est très facile d'ajouter ou d'enlever (par filtrage, par exemple) des éléments, alors que le tableau est très efficace quand le nombre d'éléments ne change pas et qu'on veut l'accès arbitraire.
Selon les situations, vous aurez besoin d'utiliser plutôt l'un ou plutôt l'autre. En règle générale, il est bon d'utiliser une liste quand vous n'avez aucune idée du nombre exact d'éléments que vous allez manipuler (par exemple, si vous faites des filtrages, ou que vous prévoyez de rajouter régulièrement des éléments). En contrepartie, vous n'avez pas d'accès arbitraire : vous pouvez toujours enregistrer certains éléments de la liste dans des variables à part si vous en avez besoin très souvent, mais vous ne pouvez pas aller chercher certains éléments spécifiques en milieu de liste directement : la seule méthode d'accès est le parcours de tous les éléments (ou du moins, de tous les éléments du début de la liste : vous pouvez arrêter le parcours en cours de route).
Il peut être difficile au début de savoir quelle structure de données choisir dans un cas précis. Même si vous avez fait un choix, restez attentifs aux opérations que vous faites. Si par exemple vous vous retrouvez à demander souvent la taille d'une liste, ou à l'inverse à essayer de concaténer fréquemment des tableaux, il est peut-être temps de changer d'avis. Certains langages offrent des facilités pour manipuler les tableaux, et non pour les listes (qu'il faut construire à la main, par exemple en C) : si vous n'avez pas de bibliothèque pour vous faciliter la tâche, privilégiez la structure qui est facile à utiliser (dans de nombreux cas, il est possible d'imiter ce que l'on ferait naturellement avec une liste en utilisant maladroitement un tableau).
Conversions
Enfin, il faut savoir que les choix de structures de données, ce n'est pas pour toute la vie. Les structures de données ne sont qu'un moyen de stocker des informations, et, de même qu'il vous arrive peut-être de temps en temps de réorganiser votre bureau ou votre logement, il est possible de changer d'organisation, c'est-à-dire de passer d'une structure de données à une autre, en conservant les informations stockées.
Exercice : écrire une fonction convertissant une liste en tableau, et une fonction convertissant un tableau en liste. Les deux fonctions doivent être en O(N).
Le passage d'une structure de données à une autre peut être une très bonne idée si votre programme passe par plusieurs phases bien séparées, qui utilisent des opérations très différentes.
Par exemple, vous pouvez commencer votre programme en récoltant de l'information (beaucoup d'ajouts d'éléments, de concaténations, de filtrages pour éliminer les mauvais éléments, etc.), avec ensuite une deuxième moitié du programme consacrée à un traitement lourd des informations récoltées (avec des parcours dans tous les sens, beaucoup d'accès arbitraires, le tout sans ajouter ou enlever d'éléments). Dans ce cas, il est tout naturel d'utiliser au départ une liste, et de la convertir au début de la deuxième phase en un tableau. Vous pouvez ainsi combiner les avantages des deux structures pour votre programme.
Évidemment, la conversion a un coût, et n'est donc intéressante que si vous comptez gagner pas mal en performance en l'effectuant. Inutile de passer sans arrêt d'une structure à une autre, en faisant très peu d'opérations à chaque fois. Tous les programmes ne sont pas découpés en des phases aussi distinctes et les choix seront parfois assez délicats. Encore une fois, c'est à vous d'essayer de deviner ce qui est le plus adapté, et de tester ensuite. N'hésitez pas à essayer plusieurs configurations différentes pour voir ce qui marche le mieux.
Vous verrez dans la suite du cours d'autres structures, aux profils différents, qui pourront être utiles pour les cas intermédiaires. En particulier, il existe des structures hybrides qui permettent d'accéder facilement à un élément particulier (un peu moins rapidement qu'avec un tableau, mais beaucoup plus qu'avec une simple liste), mais aussi d'ajouter ou d'enlever des éléments (un peu moins rapidement qu'en tête de liste, mais beaucoup plus qu'avec un simple tableau). Cependant, ces structures sont en général plus compliquées que les listes et les tableaux.
Attention aux langages de moches 
Une fois que vous avez lu ce chapitre, vous avez (peut-être) tout compris des différences entre l'accès arbitraire en O(1) et l'accès linéaire en O(N), et vous vous apprêtez à faire un massacre dans votre langage de programmation préféré : "je vais pouvoir indexer deux milliards de pages supplémentaires par jour !".
Malheureusement, il arrive que certains langages ne fonctionnent pas exactement comme je l'ai décrit ici. Au lieu d'avoir des structures de données hautement spécialisées, comme les listes et les tableaux, ils préfèrent des données qui se comportent "pas trop mal" sur la plupart des opérations courantes (ou plutôt que les concepteurs du langage ont jugées les plus courantes), quitte à être des structures de données compliquées et inconnues, et à se comporter parfois beaucoup moins bien que vous ne l'espériez. Le problème c'est que ces structures surprises ont aussi l'habitude agaçante de prendre des noms innocents comme "listes" ou "tableaux".
Par exemple, les "listes" de Python sont en fait des tableaux étranges, et les "tableaux" de PHP ne sont pas du tout des tableaux (vous auriez dû vous en douter en remarquant qu'ils proposent des opérations "ajouter au début", "ajouter à la fin", "retirer au début", etc.). D'autres langages encore, souvent ceux que l'on appelle des "langages de scripts", ont des politiques aussi cavalières quant aux structures de données.
Résultat des courses, il faut toujours se méfier avant d'utiliser une structure de données. Essayez de vous renseigner sur la complexité algorithmique des opérations qui vous intéresse, pour vérifier que c'est bien celle à laquelle vous vous attendez. Sur certains algorithmes, passer de O(1) à O(N) pour une opération peut faire très mal !
Il existe une méthode pour repérer les "structures de données à risques", c'est-à-dire celles qui ne sont pas tout à fait de vrais tableaux ou de vraies listes, mais des structures de données hybrides déguisées : leur interface. On a vu par exemple qu'un tableau supporte très mal l'insertion d'élément : si la bibliothèque des "tableaux" de votre langage propose d'insérer et de supprimer des éléments comme si c'était une opération naturelle, alors ce ne sont sans doute pas de vrais tableaux.
Ces langages "de moches" (nom plus ou moins affectueux désignant les langages qui font passer la 'simplicité' de la programmation avant toute chose, y compris la gestion de l'efficacité (algorithmique) la plus élémentaire) permettent parfois d'utiliser les "vraies" structures de données, dans une bibliothèque spécialisée. Par exemple, les listes de Python proposent un accès arbitraire, mais il vaut mieux utiliser (c'est possible) les "vrais" tableaux de la bibliothèque array.
C'est aussi quelque chose que vous devrez prendre en compte si vous créez un jour votre propre bibliothèque de structures de données (eh oui, ça arrive !). Si une opération est trop coûteuse pour votre structure, vous n'êtes pas obligés de la proposer aux utilisateurs (qui pourraient se croire encouragés à l'utiliser) : une fonction de conversion vers une structure plus classique qui supporte efficacement cette opération fera l'affaire. De manière générale, il est important de bien préciser la complexité prévue des opérations que vous offrez aux utilisateurs.