Ce que nous avons vu précédemment est certes utile, mais ne répondra pas à tous nos besoins. Nous avons besoin d'un moyen efficace de stocker des données complexes et d'y accéder. Or, il nous faudrait des années pour concevoir un système de ce style. Imaginez le travail s'il vous fallait développer de A à Z une bibliothèque multimédia qui puisse chercher en moins d'une seconde parmi plus de 100 000 titres une chanson bien précise ! C'est pour cela que nous avons besoin des bases de données, qui sont optimisées pour ce type de traitements.
Les bases de données pour Android sont fournies à l'aide de SQLite. L'avantage de SQLite est qu'il s'agit d'un SGBD très compact et par conséquent très efficace pour les applications embarquées, mais pas uniquement puisqu'on le trouve dans Skype, Adobe Reader, Firefox, etc.
Généralités
Vous comprendrez peut-être ce chapitre même si vous n'avez jamais manipulé de bases de données auparavant. Tant mieux, mais cela ne signifie pas que vous serez capables de manipuler correctement les bases de données pour autant. C'est une vraie science que d'agencer les bases de données et il faut beaucoup plus de théorie que nous n'en verrons ici pour modéliser puis réaliser une base de données cohérente et efficace.
Il vous est possible d'apprendre à utiliser les bases de données et surtout MySQL grâce au cours « Administrez vos bases de données avec MySQL » rédigé par Taguan.
Sur les bases de données
Une base de données est un dispositif permettant de stocker un ensemble d'informations de manière structurée. L'agencement adopté pour organiser les informations s'appelle le schéma.
L'unité de base de cette structure s'appelle la table. Une table regroupe des ensembles d'informations qui sont composés de manière similaire. Une entrée dans une table s'appelle un enregistrement, ou un tuple. Chaque entrée est caractérisée par plusieurs renseignements distincts, appelés des champs ou attributs.
Par exemple, une table peut contenir le prénom, le nom et le métier de plusieurs utilisateurs, on aura donc pour chaque utilisateur les mêmes informations. Il est possible de représenter une table par un tableau, où les champs seront symbolisés par les colonnes du tableau et pour lequel chaque ligne représentera une entrée différente. Regardez la figure suivante, cela devrait être plus clair.
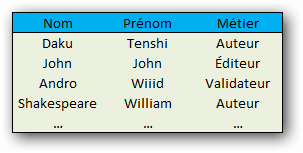
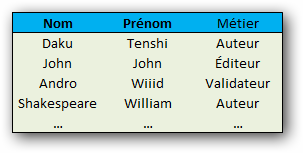
Une manière simple d'identifier les éléments dans une table est de leur attribuer une clé. C'est-à-dire qu'on va choisir une combinaison de champs qui permettront de récupérer de manière unique un enregistrement. Dans la table présentée à la figure suivante, l'attribut Nom peut être une clé puisque toutes les entrées ont un Nom différent. Le problème est qu'il peut arriver que deux utilisateurs aient le même nom, c'est pourquoi on peut aussi envisager la combinaison Nom et Prénom comme clé.
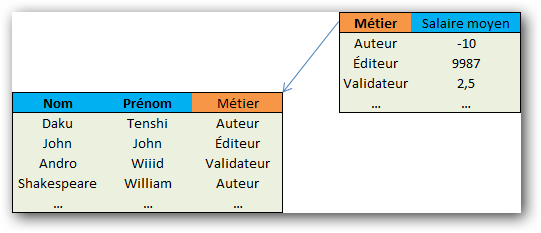
Il n'est pas rare qu'une base de données ait plusieurs tables. Afin de lier des tables, il est possible d'insérer dans une table une clé qui appartient à une autre table, auquel cas on parle de clé étrangère pour la table qui accueille la clé, comme à la figure suivante.
Il est possible d'effectuer des opérations sur une base de données, comme créer des tables, supprimer des entrées, etc. L'opération qui consiste à lire des informations qui se trouvent dans une base de données s'appelle la sélection.
Pour effectuer des opérations sur plusieurs tables, on passe par une jointure, c'est-à-dire qu'on combine des attributs qui appartiennent à plusieurs tables pour les présenter conjointement.
Afin d'effectuer toutes ces opérations, on passe par un langage de requête. Celui dont nous avons besoin s'appelle SQL. Nous verrons un rappel des opérations principales dans ce chapitre.
Enfin, une base de données est destinée à recueillir des informations simples, c'est pourquoi on évite d'y insérer des données lourdes comme des fichiers ou des données brutes. Au lieu de mettre directement des images ou des vidéos, on préfèrera insérer un URI qui dirige vers ces fichiers.
Sur SQLite
Contrairement à MySQL par exemple, SQLite ne nécessite pas de serveur pour fonctionner, ce qui signifie que son exécution se fait dans le même processus que celui de l'application. Par conséquent, une opération massive lancée dans la base de données aura des conséquences visibles sur les performances de votre application. Ainsi, il vous faudra savoir maîtriser son implémentation afin de ne pas pénaliser le restant de votre exécution.
Sur SQLite pour Android
SQLite a été inclus dans le cœur même d'Android, c'est pourquoi chaque application peut avoir sa propre base. De manière générale, les bases de données sont stockées dans les répertoires de la forme /data/data/<package>/databases. Il est possible d'avoir plusieurs bases de données par application, cependant chaque fichier créé l'est selon le mode MODE_PRIVATE, par conséquent les bases ne sont accessibles qu'au sein de l'application elle-même. Notez que ce n'est pas pour autant qu'une base de données ne peut pas être partagée avec d'autres applications.
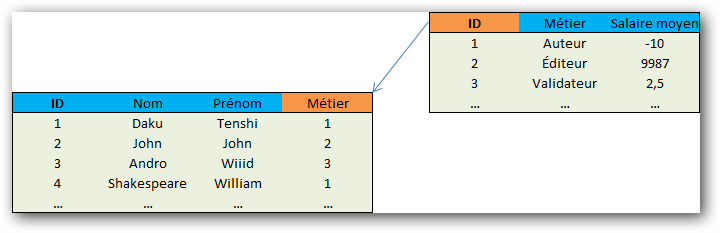
Enfin, pour des raisons qui seront expliquées dans un chapitre ultérieur, il est préférable de faire en sorte que la clé de chaque table soit un identifiant qui s'incrémente automatiquement. Notre schéma devient donc la figure suivante.
Création et mise à jour
La solution la plus évidente est d'utiliser une classe qui nous aidera à maîtriser toutes les relations avec la base de données. Cette classe dérivera de SQLiteOpenHelper. Au moment de la création de la base de données, la méthode de callback void onCreate(SQLiteDatabase db) est automatiquement appelée, avec le paramètre db qui représentera la base. C'est dans cette méthode que vous devrez lancer les instructions pour créer les différentes tables et éventuellement les remplir avec des données initiales.
Pour créer une table, il vous faudra réfléchir à son nom et à ses attributs. Chaque attribut sera défini à l'aide d'un type de données. Ainsi, dans la table Metier de notre exemple, nous avons trois attributs :
ID, qui est un entier auto-incrémental pour représenter la clé ;Métier, qui est une chaîne de caractères ;Salaire, qui est un nombre réel.
Pour SQLite, c'est simple, il n'existe que cinq types de données :
NULLpour les donnéesNULL.INTEGERpour les entiers (sans virgule).REALpour les nombres réels (avec virgule).TEXTpour les chaînes de caractères.BLOBpour les données brutes, par exemple si vous voulez mettre une image dans votre base de données (ce que vous ne ferez jamais, n'est-ce pas ? ).
).
La création de table se fait avec une syntaxe très naturelle :
1 2 3 4 | CREATE TABLE nom_de_la_table ( nom_du_champ_1 type {contraintes}, nom_du_champ_2 type {contraintes}, …); |
Pour chaque attribut, on doit déclarer au moins deux informations :
- Son nom, afin de pouvoir l'identifier ;
- Son type de donnée.
Mais il est aussi possible de déclarer des contraintes pour chaque attribut à l'emplacement de {contraintes}. On trouve comme contraintes :
PRIMARY KEYpour désigner la clé primaire sur un attribut ;NOT NULLpour indiquer que cet attribut ne peut valoirNULL;CHECKafin de vérifier que la valeur de cet attribut est cohérente ;DEFAULTsert à préciser une valeur par défaut.
Ce qui peut donner par exemple :
1 2 3 4 5 | CREATE TABLE nom_de_la_table ( nom_du_champ_1 INTEGER PRIMARY KEY, nom_du_champ_2 TEXT NOT NULL, nom_du_champ_3 REAL NOT NULL CHECK (nom_du_champ_3 > 0), nom_du_champ_4 INTEGER DEFAULT 10); |
Il existe deux types de requêtes SQL. Celles qui appellent une réponse, comme la sélection, et celles qui n'appellent pas de réponse. Afin d'exécuter une requête SQL pour laquelle on ne souhaite pas de réponse ou on ignore la réponse, il suffit d'utiliser la méthode void execSQL(String sql). De manière générale, on utilisera execSQL(String) dès qu'il ne s'agira pas de faire un SELECT, UPDATE, INSERT ou DELETE. Par exemple, pour notre table Metier :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | public class DatabaseHandler extends SQLiteOpenHelper { public static final String METIER_KEY = "id"; public static final String METIER_INTITULE = "intitule"; public static final String METIER_SALAIRE = "salaire"; public static final String METIER_TABLE_NAME = "Metier"; public static final String METIER_TABLE_CREATE = "CREATE TABLE " + METIER_TABLE_NAME + " (" + METIER_KEY + " INTEGER PRIMARY KEY AUTOINCREMENT, " + METIER_INTITULE + " TEXT, " + METIER_SALAIRE + " REAL);"; public DatabaseHandler(Context context, String name, CursorFactory factory, int version) { super(context, name, factory, version); } @Override public void onCreate(SQLiteDatabase db) { db.execSQL(METIER_TABLE_CREATE); } } |
Comme vous l'aurez remarqué, une pratique courante avec la manipulation des bases de données est d'enregistrer les attributs, tables et requêtes dans des constantes de façon à les retrouver et les modifier plus facilement. Tous ces attributs sont public puisqu'il est possible qu'on manipule la base en dehors de cette classe.
Si vous installez la base de données sur un périphérique externe, il vous faudra demander la permission WRITE_EXTERNAL_STORAGE, sinon votre base de données sera en lecture seule. Vous pouvez savoir si une base de données est en lecture seule avec la méthode boolean isReadOnly().
Le problème du code précédent, c'est qu'il ne fonctionnera pas, et ce pour une raison très simple : il faut aussi implémenter la méthode void onUpgrade(SQLiteDatabase db, int oldVersion, int newVersion) qui est déclenchée à chaque fois que l'utilisateur met à jour son application. oldVersion est le numéro de l'ancienne version de la base de données que l'application utilisait, alors que newVersion est le numéro de la nouvelle version. En fait, Android rajoute automatiquement dans la base une table qui contient la dernière valeur connue de la base. À chaque lancement, Android vérifiera la dernière version de la base par rapport à la version actuelle dans le code. Si le numéro de la version actuelle est supérieur à celui de la dernière version, alors cette méthode est lancée.
En général, le contenu de cette méthode est assez constant puisqu'on se contente de supprimer les tables déjà existantes pour les reconstruire suivant le nouveau schéma :
1 2 3 4 5 6 7 | public static final String METIER_TABLE_DROP = "DROP TABLE IF EXISTS " + METIER_TABLE_NAME + ";"; @Override public void onUpgrade(SQLiteDatabase db, int oldVersion, int newVersion) { db.execSQL(METIER_TABLE_DROP); onCreate(db); } |
Opérations usuelles
Récupérer la base
Si vous voulez accéder à la base de données n'importe où dans votre code, il vous suffit de construire une instance de votre SQLiteOpenHelper avec le constructeur SQLiteOpenHelper(Context context, String name, SQLiteDatabase.CursorFactory factory, int version), où name est le nom de la base, factory est un paramètre qu'on va oublier pour l'instant — qui accepte très bien les null — et version la version voulue de la base de données.
On utilise SQLiteDatabase getWritableDatabase() pour récupérer ou créer une base sur laquelle vous voulez lire et/ou écrire. La dernière méthode qui est appelée avant de fournir la base à getWritableDatabase() est la méthode de callback void onOpen(SQLiteDatabase db), c'est donc l'endroit où vous devriez effectuer des opérations si vous le souhaitez.
Cependant, le système fera appel à une autre méthode avant d'appeler onOpen(SQLiteDatabase). Cette méthode dépend de l'état de la base et de la version qui a été fournie à la création du SQLiteOpenHelper :
- S'il s'agit de la première fois que vous appelez la base, alors ce sera la méthode
onCreate(SQLiteDatabase)qui sera appelée. - Si la version fournie est plus récente que la dernière version fournie, alors on fait appel à
onUpgrade(SQLiteDatabase, int, int). - En revanche, si la version fournie est plus ancienne, on considère qu'on effectue un retour en arrière et c'est
onDowngrade(SQLiteDatabase, int, int)qui sera appelée.
L'objet SQLiteDatabase fourni est un objet en cache, constant. Si des opérations se déroulent sur la base après que vous avez récupéré cet objet, vous ne les verrez pas sur l'objet. Il faudra en recréer un pour avoir le nouvel état de la base.
Vous pouvez aussi utiliser la méthode SQLiteDatabase getReadableDatabase() pour récupérer la base, la différence étant que la base sera en lecture seule, mais uniquement s'il y a un problème qui l'empêche de s'ouvrir normalement. Avec getWritableDatabase(), si la base ne peut pas être ouverte en écriture, une exception de type SQLiteException sera lancée. Donc, si vous souhaitez ne faire que lire dans la base, utilisez en priorité getReadableDatabase().
Ces deux méthodes peuvent prendre du temps à s'exécuter.
Enfin, il faut fermer une base comme on ferme un flux avec la méthode void close().
Récupérer un SQLiteDatabase avec l'une des deux méthodes précédentes équivaut à faire un close() sur l'instance précédente de SQLiteDatabase.
Réfléchir, puis agir
Comme je l'ai déjà dit, chacun fait ce qu'il veut dès qu'il doit manipuler une base de données, ce qui fait qu'on se retrouve parfois avec du code incompréhensible ou difficile à mettre à jour. Une manière efficace de gérer l'interfaçage avec une base de données est de passer par un DAO, un objet qui incarne l'accès aux données de la base.
En fait, cette organisation implique d'utiliser deux classes :
- Une classe (dans mon cas
Metier) qui représente les informations et qui peut contenir un enregistrement d'une table. Par exemple, on aura une classeMetierpour symboliser les différentes professions qui peuvent peupler cette table. - Une classe
contrôleur, le DAO pour ainsi dire, qui effectuera les opérations sur la base.
La classe Metier
Très simple, il suffit d'avoir un attribut pour chaque attribut de la table et d'ajouter des méthodes pour y accéder et les modifier :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 | public class Metier { // Notez que l'identifiant est un long private long id; private String intitule; private float salaire; public Metier(long id, String intitule, float salaire) { super(); this.id = id; this.intitule = intitule; this.salaire = salaire; } public long getId() { return id; } public void setId(long id) { this.id = id; } public String getIntitule() { return intitule; } public void setIntitule(String intitule) { this.intitule = intitule; } public float getSalaire() { return salaire; } public void setSalaire(float salaire) { this.salaire = salaire; } } |
La classe DAO
On doit y inclure au moins les méthodes CRUD, autrement dit les méthodes qui permettent l'ajout d'entrées dans la base, la récupération d'entrées, la mise à jour d'enregistrements ou encore la suppression de tuples. Bien entendu, ces méthodes sont à adapter en fonction du contexte et du métier. De plus, on rajoute les constantes globales déclarées précédemment dans la base :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 | public class MetierDAO { public static final String TABLE_NAME = "metier"; public static final String KEY = "id"; public static final String INTITULE = "intitule"; public static final String SALAIRE = "salaire"; public static final String TABLE_CREATE = "CREATE TABLE " + TABLE_NAME + " (" + KEY + " INTEGER PRIMARY KEY AUTOINCREMENT, " + INTITULE + " TEXT, " + SALAIRE + " REAL);"; public static final String TABLE_DROP = "DROP TABLE IF EXISTS " + TABLE_NAME + ";"; /** * @param m le métier à ajouter à la base */ public void ajouter(Metier m) { // CODE } /** * @param id l'identifiant du métier à supprimer */ public void supprimer(long id) { // CODE } /** * @param m le métier modifié */ public void modifier(Metier m) { // CODE } /** * @param id l'identifiant du métier à récupérer */ public Metier selectionner(long id) { // CODE } } |
Il ne s'agit bien entendu que d'un exemple, dans la pratique on essaie de s'adapter au contexte quand même, là je n'ai mis que des méthodes génériques.
Comme ces opérations se déroulent sur la base, nous avons besoin d'un accès à la base. Pour cela, et comme j'ai plusieurs tables dans mon schéma, j'ai décidé d'implémenter toutes les méthodes qui permettent de récupérer ou de fermer la base dans une classe abstraite :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | public abstract class DAOBase { // Nous sommes à la première version de la base // Si je décide de la mettre à jour, il faudra changer cet attribut protected final static int VERSION = 1; // Le nom du fichier qui représente ma base protected final static String NOM = "database.db"; protected SQLiteDatabase mDb = null; protected DatabaseHandler mHandler = null; public DAOBase(Context pContext) { this.mHandler = new DatabaseHandler(pContext, NOM, null, VERSION); } public SQLiteDatabase open() { // Pas besoin de fermer la dernière base puisque getWritableDatabase s'en charge mDb = mHandler.getWritableDatabase(); return mDb; } public void close() { mDb.close(); } public SQLiteDatabase getDb() { return mDb; } } |
Ainsi, pour pouvoir utiliser ces méthodes, la définition de ma classe MetierDAO devient :
1 | public class MetierDAO extends DAOBase |
Ajouter
Pour ajouter une entrée dans la table, on utilise la syntaxe suivante :
1 2 | INSERT INTO nom_de_la_table (nom_de_la_colonne1, nom_de_la_colonne2, …) VALUES (valeur1, valeur2, …) |
La partie (nom_de_la_colonne1, nom_de_la_colonne2, …) permet d'associer une valeur à une colonne précise à l'aide de la partie (valeur1, valeur2, …). Ainsi la colonne 1 aura la valeur 1 ; la colonne 2, la valeur 2 ; etc.
1 | INSERT INTO Metier (Salaire, Metier) VALUES (50.2, "Caricaturiste") |
Pour certains SGBD, l'instruction suivante est aussi possible afin d'insérer une entrée vide dans la table.
1 | INSERT INTO Metier; |
Cependant, avec SQLite ce n'est pas possible, il faut préciser au moins une colonne, quitte à lui passer comme valeur NULL.
1 | INSERT INTO Metier (Salaire) VALUES (NULL); |
En Java, pour insérer une entrée, on utilisera la méthode long insert(String table, String nullColumnHack, ContentValues values), qui renvoie le numéro de la ligne ajoutée où :
tableest l'identifiant de la table dans laquelle insérer l'entrée.nullColumnHackest le nom d'une colonne à utiliser au cas où vous souhaiteriez insérer une entrée vide. Prenez n'importe laquelle.valuesest un objet qui représente l'entrée à insérer.
Les ContentValues sont utilisés pour insérer des données dans la base. Ainsi, on peut dire qu'ils fonctionnent un peu comme les Bundle par exemple, puisqu'on peut y insérer des couples identifiant-valeur, qui représenteront les attributs des objets à insérer dans la base. L’identifiant du couple doit être une chaîne de caractères qui représente une des colonnes de la table visée. Ainsi, pour insérer le métier « Caricaturiste », il me suffit de faire :
1 2 3 4 | ContentValues value = new ContentValues(); value.put(MetierDAO.INTITULE, m.getIntitule()); value.put(MetierDAO.SALAIRE, m.getSalaire()); mDb.insert(MetierDAO.TABLE_NAME, null, value); |
Je n'ai pas besoin de préciser de valeur pour l'identifiant puisqu'il s'incrémente tout seul.
Supprimer
La méthode utilisée pour supprimer est quelque peu différente. Il s'agit de int delete(String table, String whereClause, String[] whereArgs). L'entier renvoyé est le nombre de lignes supprimées. Dans cette méthode :
tableest l'identifiant de la table.whereClausecorrespond auWHEREen SQL. Par exemple, pour sélectionner la première valeur dans la tableMetier, on mettra pourwhereClausela chaîne «id = 1». En pratique, on préférera utiliser la chaîne «id = ?» et je vais vous expliquer pourquoi tout de suite.whereArgsest un tableau des valeurs qui remplaceront les « ? » danswhereClause. Ainsi, siwhereClausevaut «LIKE ? AND salaire > ?» et qu'on cherche les métiers qui ressemblent à « ingénieur avec un salaire supérieur à 1000 € », il suffit d'insérer danswhereArgsunString[]du genre{"ingenieur", "1000"}.
Ainsi dans notre exemple, pour supprimer une seule entrée, on fera :
1 2 3 | public void supprimer(long id) { mDb.delete(TABLE_NAME, KEY + " = ?", new String[] {String.valueOf(id)}); } |
Mise à jour
Rien de très surprenant ici, la syntaxe est très similaire à la précédente :
int update(String table, ContentValues values, String whereClause, String[] whereArgs). On ajoute juste le paramètre values pour représenter les changements à effectuer dans le ou les enregistrements cibles. Donc, si je veux mettre à jour le salaire d'un métier, il me suffit de mettre à jour l'objet associé et d'insérer la nouvelle valeur dans un ContentValues :
1 2 3 | ContentValues value = new ContentValues(); value.put(SALAIRE, m.getSalaire()); mDb.update(TABLE_NAME, value, KEY + " = ?", new String[] {String.valueOf(m.getId())}); |
Sélection
Ici en revanche, la méthode est plus complexe et revêt trois formes différentes en fonction des paramètres qu'on veut lui passer. La première forme est celle-ci :
1 | Cursor query (boolean distinct, String table, String[] columns, String selection, String[] selectionArgs, String groupBy, String having, String orderBy, String limit) |
La deuxième forme s'utilise sans l'attribut limit et la troisième sans les attributs limit et distinct. Ces paramètres sont vraiment explicites puisqu'ils représentent à chaque fois des mots-clés du SQL ou des attributs que nous avons déjà rencontrés. Voici leur signification :
distinct, si vous ne voulez pas de résultats en double.tableest l'identifiant de la table.columnsest utilisé pour préciser les colonnes à afficher.selectionest l'équivalent duwhereClauseprécédent.selectionArgsest l’équivalent duwhereArgsprécédent.group bypermet de grouper les résultats.havingest utile pour filtrer parmi les groupes.order bypermet de trier les résultats. MettreASCpour trier dans l'ordre croissant etDESCpour l'ordre décroissant.limitpour fixer un nombre maximal de résultats voulus.
Pour être franc, utiliser ces méthodes m'agace un peu, c'est pourquoi je préfère utiliser Cursor rawQuery(String sql, String[] selectionArgs) où je peux écrire la requête que je veux dans sql et remplacer les « ? » dans selectionArgs. Ainsi, si je veux tous les métiers qui rapportent en moyenne plus de 1€, je ferai :
1 | Cursor c = mDb.rawQuery("select " + INTITULE + " from " + TABLE_NAME + " where salaire > ?", new String[]{"1"}); |
Les curseurs
Manipuler les curseurs
Les curseurs sont des objets qui contiennent les résultats d'une recherche dans une base de données. Ce sont en fait des objets qui fonctionnent comme les tableaux que nous avons vus précédemment, ils contiennent les colonnes et lignes qui ont été renvoyées par la requête.
Ainsi, pour la requête suivante sur notre table Metier :
1 | SELECT id, intitule, salaire from Metier; |
… on obtient le résultat visible à la figure suivante, dans un curseur.

Les lignes
Ainsi, pour parcourir les résultats d'une requête, il faut procéder ligner par ligne. Pour naviguer parmi les lignes, on peut utiliser les méthodes suivantes :
boolean moveToFirst()pour aller à la première ligne.boolean moveToLast()pour aller à la dernière.boolean moveToPosition(int position)pour aller à lapositionvoulue, sachant que vous pouvez savoir le nombre de lignes avec la méthodeint getCount().
Cependant, il y a mieux. En fait, un Cursor est capable de retenir la position du dernier élément que l'utilisateur a consulté, il est donc possible de naviguer d'avant en arrière parmi les lignes grâce aux méthodes suivantes :
boolean moveToNext()pour aller à la ligne suivante. Par défaut on commence à la ligne -1, donc, en utilisant unmoveToNext()sur un tout nouveauCursor, on passe à la première ligne. On aurait aussi pu accéder à la première ligne avecmoveToFirst(), bien entendu.boolean moveToPrevious()pour aller à l'entrée précédente.
Vous remarquerez que toutes ces méthodes renvoient des booléens. Ces booléens valent true si l'opération s'est déroulée avec succès, sinon false (auquel cas la ligne demandée n'existe pas).
Pour récupérer la position actuelle, on utilise int getPosition(). Vous pouvez aussi savoir si vous êtes après la dernière ligne avec boolean isAfterLast().
Par exemple, pour naviguer entre toutes les lignes d'un curseur, on fait :
1 2 3 4 | while (cursor.moveToNext()) { // Faire quelque chose } cursor.close(); |
Ou encore
1 2 3 4 | for(cursor.moveToFirst(); !cursor.isAfterLast(); cursor.moveToNext()) { // Votre code } cursor.close(); |
Les colonnes
Vous savez déjà à l'avance que vous avez trois colonnes, dont la première contient un entier, la deuxième, une chaîne de caractères, et la troisième, un réel. Pour récupérer le contenu d'une de ces colonnes, il suffit d'utiliser une méthode du style X getX(int columnIndex) avec X le typage de la valeur à récupérer et columnIndex la colonne dans laquelle se trouve cette valeur. On peut par exemple récupérer un Metier complet avec :
1 2 3 4 | long id = cursor.getLong(0); String intitule = cursor.getString(1); double salaire = cursor.getDouble(2); Metier m = new Metier (id, intitule, salaire); |
Il ne vous est pas possible de récupérer le nom ou le type des colonnes, il vous faut donc le savoir à l'avance.
L'adaptateur pour les curseurs
Comme n'importe quel adaptateur, un CursorAdapter fera la transition entre des données et un AdapterView. Cependant, comme on trouve rarement une seule information dans un curseur, on préférera utiliser un SimpleCursorAdapter, qui est un équivalent au SimpleAdapter que nous avons déjà étudié.
Pour construire ce type d'adaptateur, on utilisera le constructeur suivant :
1 | SimpleCursorAdapter (Context context, int layout, Cursor c, String[] from, int[] to) |
… où :
layoutest l'identifiant de la mise en page des vues dans l'AdapterView.cest le curseur. On peut mettrenullsi on veut ajouter le curseur a posteriori.fromindique une liste de noms des colonnes afin de lier les données au layout.tocontient lesTextViewqui afficheront les colonnes contenues dansfrom.
Tout cela est un peu compliqué à comprendre, je le conçois. Alors nous allons faire un layout spécialement pour notre table Metier.
Avant tout, sachez que pour utiliser un CursorAdapter ou n'importe quelle classe qui dérive de CursorAdapter, votre curseur doit contenir une colonne qui s'appelle _id. Si ce n'est pas le cas, vous n'avez bien entendu pas à recréer tout votre schéma, il vous suffit d'adapter vos requêtes pour que la colonne qui permet l'identification s'appelle _id, ce qui donne avec la requête précédente :
SELECT id as _id, intitule, salaire from Metier;.
Le layout peut par exemple ressembler au code suivant, que j'ai enregistré dans cursor_row.xml.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | <?xml version="1.0" encoding="utf-8"?> <LinearLayout xmlns:android="http://schemas.android.com/apk/res/android" android:layout_width="fill_parent" android:layout_height="fill_parent" android:orientation="vertical" > <TextView android:id="@+id/intitule" android:layout_width="fill_parent" android:layout_height="fill_parent" android:layout_weight="50" /> <TextView android:id="@+id/salaire" android:layout_width="fill_parent" android:layout_height="fill_parent" android:layout_weight="50" /> </LinearLayout> |
Ensuite, pour utiliser le constructeur, c'est très simple, il suffit de faire :
1 | SimpleCursorAdapter adapter = new SimpleCursorAdapter (context, R.layout.cursor_row, cursor, new String[]{MetierDAO.Intitule, MetierDAO.Salire}, new int[]{R.id.intitule, R.id.salaire}) |
- Android intègre au sein même de son système une base de données SQLite qu'il partage avec toutes les applications du système (avec des droits très spécifique à chacune pour qu'elle n'aille pas voir chez le voisin).
- La solution la plus évidente pour utiliser une base de données est de mettre en place une classe qui maitrisera les accès entre l'application et la base de données.
- En fonction des besoins de votre application, il est utile de mettre en place une série d'opérations usuelles accessibles à partir d'un DAO. Ces méthodes sont l'ajout, la suppression, la mise à jour et la sélection de données.
- Les curseurs sont des objets qui contiennent les résultats d'une recherche dans une base de données. Ce sont en fait des objets qui fonctionnent comme les tableaux que nous avons vus précédemment sur les chapitres des adaptateurs, ils contiennent les colonnes et les lignes qui ont été renvoyées par la requête.