Les threads sont des fils d'exécution de notre programme. Lorsque nous en créons plusieurs, nous pouvons exécuter des tâches simultanément.
Nous en étions restés à notre animation qui bloque, et je vous avais dit que la solution était d'utiliser un deuxième Thread. Dans ce chapitre, nous allons voir comment créer une (ou plusieurs) nouvelle(s) pile(s) de fonctions grâce à ces fameux threads. Il existe une classe Thread dans Java permettant leur gestion. Vous allez voir qu'il existe deux façons de créer un nouveau thread.
- Une classe héritée de Thread
- Utiliser l'interface Runnable
- Synchroniser ses threads
- Contrôler son animation
- Depuis Java 7 : le pattern Fork/Join
Une classe héritée de Thread
Je vous le répète encore : lorsque vous exécutez votre programme, un thread est lancé ! Dites-vous que le thread correspond à la pile et que chaque nouveau thread créé génère une pile d'exécution. Pour le moment, nous n'allons pas travailler avec notre IHM et allons revenir en mode console. Créez un nouveau projet et une classe contenant la méthode main. Essayez ce code :
1 2 3 4 5 | public class Test { public static void main(String[] args) { System.out.println("Le nom du thread principal est " + Thread.currentThread().getName()); } } |
Vous devriez obtenir ceci :
1 | Le nom du thread principal est main
|
Non, vous ne rêvez pas : il s'agit bien de notre méthode main, le thread principal de notre application !
Voyez un thread comme une machine bien huilée capable d'effectuer les tâches que vous lui spécifiez. Une fois instancié, un thread attend son lancement. Dès que c'est fait, il invoque sa méthode run() qui va lui permettre de connaître les tâches qu'il a à effectuer.
Nous allons maintenant apprendre à créer un nouveau thread. Je l'avais mentionné dans l'introduction, il existe deux manières de faire :
- créer une classe héritant de la classe
Thread; - créer une implémentation de l'interface
Runnableet instancier un objetThreadavec l'implémentation de cette interface.
Comme je vous le disais, nous allons opter pour la première solution. Tout ce que nous avons à faire, c'est redéfinir la méthode run() de notre objet afin qu'il sache ce qu'il doit faire. Puisque nous allons en utiliser plusieurs, autant pouvoir les différencier : nous allons leur donner des noms.
Créons donc une classe gérant tout cela qui contient un constructeur comprenant un String en paramètre pour spécifier le nom du thread. Cette classe doit également comprendre une méthode getName() afin de retourner ce nom. La classe Thread se trouvant dans le package java.lang, aucune instruction import n'est nécessaire. En voici le code :
1 2 3 4 5 6 7 8 9 | public class TestThread extends Thread { public TestThread(String name){ super(name); } public void run(){ for(int i = 0; i < 10; i++) System.out.println(this.getName()); } } |
Testez maintenant ce code plusieurs fois :
1 2 3 4 5 6 7 8 | public class Test { public static void main(String[] args) { TestThread t = new TestThread("A"); TestThread t2 = new TestThread(" B"); t.start(); t2.start(); } } |
Voici quelques captures d'écran de mes tests consécutifs en figure suivante.

Vous pouvez voir que l'ordre d'exécution est souvent aléatoire, car Java utilise un ordonnanceur. Vous devez savoir que si vous utilisez plusieurs threads dans une application, ceux-ci ne s'exécutent pas toujours en même temps ! En fait, l'ordonnanceur gère les threads de façon aléatoire : il va en faire tourner un pendant un certain temps, puis un autre, puis revenir au premier, etc., jusqu'à ce qu'ils soient terminés. Lorsque l'ordonnanceur passe d'un thread à un autre, le thread interrompu est mis en sommeil tandis que l'autre est en éveil.
Notez qu'avec les processeurs multi-coeurs aujourd'hui, il est désormais possible d'exécuter deux tâches exactement en même temps. Tout dépend donc de votre ordinateur.
Un thread peut présenter plusieurs états :
NEW: lors de sa création.RUNNABLE: lorsqu'on invoque la méthodestart(), le thread est prêt à travailler.TERMINATED: lorsque le thread a effectué toutes ses tâches ; on dit aussi qu'il est « mort ». Vous ne pouvez alors plus le relancer par la méthodestart().TIMED_WAITING: lorsque le thread est en pause (quand vous utilisez la méthodesleep(), par exemple).WAITING: lorsque le thread est en attente indéfinie.BLOCKED: lorsque l'ordonnanceur place un thread en sommeil pour en utiliser un autre, il lui impose cet état.
Un thread est considéré comme terminé lorsque la méthode run() est ôtée de sa pile d'exécution. En effet, une nouvelle pile d'exécution contient à sa base la méthode run() de notre thread. Une fois celle-ci dépilée, notre nouvelle pile est détruite !
En fait, le thread principal crée un second thread qui se lance et construit une pile dont la base est sa méthode run() ; celle-ci appelle une méthode, l'empile, effectue toutes les opérations demandées, et une fois qu'elle a terminé, elle dépile cette dernière. La méthode run() prend fin, la pile est alors détruite.
Nous allons modifier notre classe TestThread afin d'afficher les états de nos threads que nous pouvons récupérer grâce à la méthode getState().
Voici notre classe TestThread modifiée :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | public class TestThread extends Thread { Thread t; public TestThread(String name){ super(name); System.out.println("statut du thread " + name + " = " +this.getState()); this.start(); System.out.println("statut du thread " + name + " = " +this.getState()); } public TestThread(String name, Thread t){ super(name); this.t = t; System.out.println("statut du thread " + name + " = " +this.getState()); this.start(); System.out.println("statut du thread " + name + " = " +this.getState()); } public void run(){ for(int i = 0; i < 10; i++){ System.out.println("statut " + this.getName() + " = " +this.getState()); if(t != null) System.out.println("statut de " + t.getName() + " pendant le thread " + this.getName() +" = " +t.getState()); } } public void setThread(Thread t){ this.t = t; } } |
Ainsi que notre main :
1 2 3 4 5 6 7 8 9 10 11 12 13 | public class Test { public static void main(String[] args) { TestThread t = new TestThread("A"); TestThread t2 = new TestThread(" B", t); try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println("statut du thread " + t.getName() + " = " + t.getState()); System.out.println("statut du thread " + t2.getName() + " = " +t2.getState()); } } |
La figure suivante représente un jeu d'essais.

Dans notre classe TestThread, nous avons ajouté quelques instructions d'affichage afin de visualiser l'état courant de nos objets. Mais nous avons aussi ajouté un constructeur supplémentaire prenant un Thread en paramètre afin d'obtenir l'état de notre premier thread lors de l'exécution du second.
Dans le jeu d'essais, vous pouvez voir les différents statuts qu'ont pris les threads. Ainsi, le premier est dans l'état BLOCKED lorsque le second est en cours de traitement, ce qui justifie ce que je vous disais : les threads ne s'exécutent pas en même temps !
Vous pouvez voir aussi que les opérations effectuées par nos threads sont en fait codées dans la méthode run(). Reprenez l'image que j'ai montrée précédemment : « un thread est une machine bien huilée capable d'effectuer les tâches que vous lui spécifiez ». Faire hériter un objet de Thread permet de créer un nouveau thread très facilement. Vous pouvez cependant procéder différemment : redéfinir uniquement ce que doit effectuer le nouveau thread grâce à l'interface Runnable. Dans ce cas, ma métaphore prend tout son sens : vous ne redéfinissez que ce que doit faire la machine, et non pas la machine tout entière !
Utiliser l'interface Runnable
Ne redéfinir que les tâches que le nouveau thread doit effectuer comprend un autre avantage : la classe dont nous disposons n'hérite d'aucune autre ! Eh oui : dans notre test précédent, la classe TestThread ne pourra plus hériter d'une classe, tandis qu'avec une implémentation de Runnable, rien n'empêche notre classe d'hériter de JFrame, par exemple…
Trêve de bavardages : codons notre implémentation de Runnable. Vous ne devriez avoir aucun problème à y parvenir, sachant qu'il n'y a que la méthode run() à redéfinir.
Afin d'illustrer cela, nous allons utiliser un exemple que j'ai trouvé intéressant lorsque j'ai appris à me servir des threads : nous allons créer un objet CompteEnBanque contenant une somme d'argent par défaut (disons 100), une méthode pour retirer de l'argent (retraitArgent()) et une méthode retournant le solde (getSolde()). Cependant, avant de retirer de l'argent, nous vérifierons que nous ne sommes pas à découvert… Notre thread va effectuer autant d'opérations que nous le souhaitons. La figure suivante représente le diagramme de classes résumant la situation.
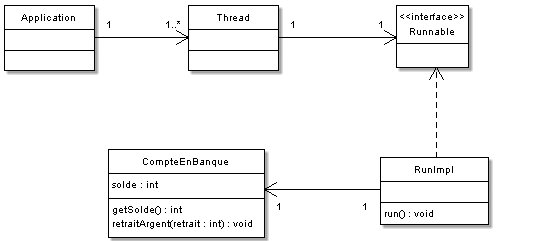
Je résume :
- notre application peut contenir un ou plusieurs objets
Thread; - ceux-ci ne peuvent être constitués que d'un objet de type
Runnable; - dans notre cas, les objets
Threadcontiendront une implémentation deRunnable:RunImpl; - cette implémentation possède un objet
CompteEnBanque.
Voici les codes source…
RunImpl.java
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | public class RunImpl implements Runnable { private CompteEnBanque cb; public RunImpl(CompteEnBanque cb){ this.cb = cb; } public void run() { for(int i = 0; i < 25; i++){ if(cb.getSolde() > 0){ cb.retraitArgent(2); System.out.println("Retrait effectué"); } } } } |
CompteEnBanque.java
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | public class CompteEnBanque { private int solde = 100; public int getSolde(){ if(this.solde < 0) System.out.println("Vous êtes à découvert !"); return this.solde; } public void retraitArgent(int retrait){ solde = solde - retrait; System.out.println("Solde = " + solde); } } |
Test.java
1 2 3 4 5 6 7 | public class Test { public static void main(String[] args) { CompteEnBanque cb = new CompteEnBanque(); Thread t = new Thread(new RunImpl(cb)); t.start(); } } |
Ce qui nous donne la figure suivante.

Rien d'extraordinaire ici, une simple boucle aurait fait la même chose. Ajoutons un nom à notre implémentation et créons un deuxième thread utilisant un deuxième compte. Il faut penser à modifier l'implémentation afin que nous puissions connaître le thread qui travaille :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | public class RunImpl implements Runnable { private CompteEnBanque cb; private String name; public RunImpl(CompteEnBanque cb, String name){ this.cb = cb; this.name = name; } public void run() { for(int i = 0; i < 50; i++){ if(cb.getSolde() > 0){ cb.retraitArgent(2); System.out.println("Retrait effectué par " + this.name); } } } } |
1 2 3 4 5 6 7 8 9 10 11 | public class Test { public static void main(String[] args) { CompteEnBanque cb = new CompteEnBanque(); CompteEnBanque cb2 = new CompteEnBanque(); Thread t = new Thread(new RunImpl(cb, "Cysboy")); Thread t2 = new Thread(new RunImpl(cb2, "Zéro")); t.start(); t2.start(); } } |
Jusqu'ici, rien de perturbant : nous avons utilisé deux instances distinctes de RunImpl utilisant elles-mêmes deux instances distinctes de CompteEnBanque. Mais que se passerait-il si nous utilisions la même instance de CompteEnBanque pour deux threads différents ? Testez plusieurs fois le code que voici :
1 2 3 4 5 6 7 8 9 10 | public class Test { public static void main(String[] args) { CompteEnBanque cb = new CompteEnBanque(); Thread t = new Thread(new RunImpl(cb, "Cysboy")); Thread t2 = new Thread(new RunImpl(cb, "Zéro")); t.start(); t2.start(); } } |
La figure suivante représente deux morceaux de résultats obtenus lors de l'exécution.

Vous pouvez voir des incohérences monumentales ! J'imagine que vous pensiez comme moi que le compte aurait été débité par pas de deux jusqu'à la fin sans obtenir d'aberrations de ce genre, puisque nous utilisons le même objet… Eh bien, non ! Pourquoi ? Tout simplement parce que l'ordonnanceur de Java place les threads en sommeil quand il le désire, et lorsque le thread qui était en sommeil se réveille, il reprend son travail là où il l'avait laissé !
Voyons comment résoudre ce problème.
Synchroniser ses threads
Tout est dans le titre ! En fait, ce qu'il faut faire, c'est indiquer à la JVM qu'un thread est en train d'utiliser des données qu'un autre thread est susceptible d'altérer.
Ainsi, lorsque l'ordonnanceur met en sommeil un thread qui traitait des données utilisables par un autre thread, ce premier thread garde la priorité sur les données et tant qu'il n'a pas terminé son travail, les autres threads n'ont pas la possibilité d'y toucher.
Cela s'appelle synchroniser les threads. Cette opération est très délicate et demande beaucoup de compétences en programmation… Voici à quoi ressemble notre méthode retraitArgent() synchronisée :
1 2 3 4 5 6 7 8 | public class CompteEnBanque { //Le début du code ne change pas public synchronized void retraitArgent(int retrait){ solde = solde - retrait; System.out.println("Solde = " + solde); } } |
Il vous suffit d'ajouter dans la déclaration de la méthode le mot clé synchronized, grâce auquel la méthode est inaccessible à un thread si elle est déjà utilisée par un autre thread. Ainsi, les threads cherchant à utiliser des méthodes déjà prises en charge par un autre thread sont placés dans une « liste d'attente ».
Je récapitule une nouvelle fois, en me servant d'un exemple simple. Je serai représenté par le thread A, vous par le thread B, et notre boulangerie favorite par la méthode synchronisée M. Voici ce qu'il se passe :
- le thread A (moi) appelle la méthode M ;
- je commence par demander une baguette : la boulangère me la pose sur le comptoir et commence à calculer le montant ;
- c'est là que le thread B (vous) cherche aussi à utiliser la méthode M ; cependant, elle est déjà occupée par un thread (moi) ;
- vous êtes donc mis en attente ;
- l'action revient sur moi (thread A) ; au moment de payer, je dois chercher de la monnaie dans ma poche ;
- au bout de quelques instants, je m'endors ;
- l'action revient sur le thread B (vous)… mais la méthode M n'est toujours pas libérée du thread A, vous êtes donc remis en attente ;
- on revient sur le thread A qui arrive enfin à payer et à quitter la boulangerie : la méthode M est maintenant libérée ;
- le thread B (vous) peut enfin utiliser la méthode M ;
- et là, les threads C, D, E et F entrent dans la boulangerie ;
- et ainsi de suite.
Je pense que grâce à cela, vous avez dû comprendre…
Dans un contexte informatique, il peut être pratique et sécurisé d'utiliser des threads et des méthodes synchronisées lors d'accès à des services distants tels qu'un serveur d'applications ou un SGBD (Système de Gestion de Base de Données).
Je vous propose maintenant de retourner à notre animation, qui n'attend plus qu'un petit thread pour fonctionner correctement !
Contrôler son animation
À partir d'ici, il n'y a rien de bien compliqué. Il nous suffit de créer un nouveau thread lorsqu'on clique sur le bouton Go en lui passant une implémentation de Runnable en paramètre qui, elle, va appeler la méthode go() (n'oublions pas de remettre le booléen de contrôle à true).
Voici le code de notre classe Fenetre utilisant le thread en question :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 | import java.awt.BorderLayout; import java.awt.Color; import java.awt.Dimension; import java.awt.Font; import java.awt.event.ActionEvent; import java.awt.event.ActionListener; import javax.swing.JButton; import javax.swing.JFrame; import javax.swing.JLabel; import javax.swing.JPanel; public class Fenetre extends JFrame{ private Panneau pan = new Panneau(); private JButton bouton = new JButton("Go"); private JButton bouton2 = new JButton("Stop"); private JPanel container = new JPanel(); private JLabel label = new JLabel("Le JLabel"); private int compteur = 0; private boolean animated = true; private boolean backX, backY; private int x, y; private Thread t; public Fenetre(){ //Le constructeur n'a pas changé } private void go(){ //La méthode n'a pas changé } public class BoutonListener implements ActionListener{ public void actionPerformed(ActionEvent arg0) { animated = true; t = new Thread(new PlayAnimation()); t.start(); bouton.setEnabled(false); bouton2.setEnabled(true); } } class Bouton2Listener implements ActionListener{ public void actionPerformed(ActionEvent e) { animated = false; bouton.setEnabled(true); bouton2.setEnabled(false); } } class PlayAnimation implements Runnable{ public void run() { go(); } } } |
Voilà, vous avez enfin le contrôle sur votre animation ! Nous allons à présent pouvoir l'agrémenter un peu dans les chapitres suivants.
Depuis Java 7 : le pattern Fork/Join
La version 7 de Java met à disposition des développeurs plusieurs classes qui permettent de mettre en application ce qu'on appelle « le pattern Fork/Join ». Ce dernier n'est rien de plus que la mise en application d'un vieil adage que vous devez connaître : divisez pour mieux régner ! Dans certains cas, il serait bon de pouvoir découper une tâche en plusieurs sous-tâches, faire en sorte que ces sous-tâches s'exécutent en parallèle et pouvoir récupérer le résultat de tout ceci une fois que tout est terminé. C'est exactement ce qu'il est possible de faire avec ces nouvelles classes. Je vous préviens, c'est un peu difficile à comprendre mais c'est vraiment pratique.
Avant de commencer il faut préciser qu'il y a un certain nombre de prérequis à cela :
- la machine qui exécutera la tâche devra posséder un processeur à plusieurs cœurs (2, 4 ou plus) ;
- la tâche doit pouvoir être découpée en plusieurs sous-tâches ;
- s'assurer qu'il y a un réel gain de performance ! Dans certains cas, découper une tâche rend le traitement plus long.
En guise d'exemple, je vous propose de coder une recherche de fichiers (simplifiée au maximum pour ne pas surcharger le code). Voici les classes que nous allons utiliser, pour le moment sans la gestion Fork/Join :
ScanException.java
1 2 3 | public class ScanException extends Exception{ public ScanException(String message){super(message);} } |
FolderScanner.java
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 | import java.io.IOException; import java.nio.file.DirectoryStream; import java.nio.file.Files; import java.nio.file.Path; public class FolderScanner{ private Path path = null; private String filter = "*"; private long result = 0; public FolderScanner(){ } public FolderScanner(Path p, String f){ path = p; filter = f; } /** * Méthode qui se charge de scanner les dossiers de façon récursive * @throws ScanException */ public long sequentialScan() throws ScanException{ //Si le chemin n'est pas valide, on lève une exception if(path == null || path.equals("")) throw new ScanException("Chemin à scanner non valide (vide ou null) !"); System.out.println("Scan du dossier : " + path + " à la recherche des fichiers portant l'extension " + this.filter); //On liste maintenant le contenu du répertoire pour traiter les sous-dossiers try(DirectoryStream<Path> listing = Files.newDirectoryStream(path)){ for(Path nom : listing){ //S'il s'agit d'un dossier, on le scanne grâce à notre objet if(Files.isDirectory(nom.toAbsolutePath())){ FolderScanner f = new FolderScanner(nom.toAbsolutePath(), this.filter); result += f.sequentialScan(); } } } catch (IOException e) { e.printStackTrace();} //Maintenant, on filtre le contenu de ce même dossier sur le filtre défini try(DirectoryStream<Path> listing = Files.newDirectoryStream(path, this.filter)){ for(Path nom : listing){ //Pour chaque fichier correspondant, on incrémente notre compteur result++; } } catch (IOException e) { e.printStackTrace(); } return result; } } |
Et la classe de test : Main.java
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | import java.nio.file.Path; import java.nio.file.Paths; public class Main { public static void main(String[] args) { Path chemin = Paths.get("E:\\Mes Documents"); String filtre = "*.psd"; FolderScanner fs = new FolderScanner(chemin, filtre); try { Long start = System.currentTimeMillis(); Long resultat = fs.sequentialScan(); Long end = System.currentTimeMillis(); System.out.println("Il y a " + resultat + " fichier(s) portant l'extension " + filtre); System.out.println("Temps de traitement : " + (end - start)); } catch (ScanException e) { e.printStackTrace(); } } } |
Lorsque je lance ce code le temps de traitement est vraiment long (j'ai beaucoup de dossiers dans mes documents  ), comme le montre la figure suivante.
), comme le montre la figure suivante.

Nous pouvons voir qu'il est possible de découper le scan de chaque dossier dans une sous-tâche, et c'est exactement ce que nous allons faire. Pour ce faire, nous devons faire hériter notre classe FolderScanner d'une des classes permettant ce découpage. La plateforme Java 7 nous met à disposition deux classes qui héritent de la classe abstraite ForkJoinTask<V> :
RecursiveAction: classe permettant de découper une tâche ne renvoyant aucune valeur particulière. Elle hérite deForkJoinTask<Void>;RecursiveTask<V>: identique à la classe précédente mais retourne une valeur, de type<V>, en fin de traitement. C'est cette classe que nous allons utiliser pour pouvoir nous retourner le nombre de fichiers trouvés.
Nous allons devoir utiliser, en plus de l'objet de découpage, un objet qui aura pour rôle de superviser l'exécution des tâches et sous-tâches afin de pouvoir fusionner les threads en fin de traitement : ForkJoinPool.
Avant de vous présenter le code complet, voici comment ça fonctionne. Les objets qui permettent le découpage en sous-tâches fournissent trois méthodes qui permettent cette gestion :
compute(): méthode abstraite à redéfinir dans l'objet héritant afin de définir le traitement à effectuer ;fork(): méthode qui crée un nouveau thread dans le pool de thread (ForkJoinPool) ;join(): méthode qui permet de récupérer le résultat de la méthodecompute().
Ces classes nécessitent que vous redéfinissiez la méthode compute() afin de définir ce qu'il y a à faire. La figure suivante est un schéma représentant la façon dont les choses se passent.
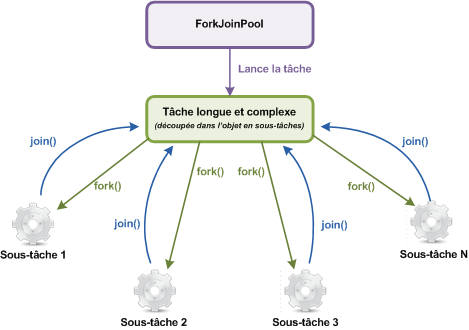
Concrètement, avec notre exemple, voici ce qu'il va se passer :
- nous allons lancer le scan de notre dossier ;
- notre objet qui sert à scanner le contenu va vérifier le contenu pour voir s'il n'y a pas de sous-dossiers ;
- pour chaque sous-dossier, nous allons créer une nouvelle tâche et la lancer ;
- nous allons compter le nombre de fichiers qui correspond à nos critères dans le dossier en cours de scan ;
- nous allons récupérer le nombre de fichiers trouvés par les exécutions en tâche de fond ;
- nous allons retourner le résultat final.
Pour que vous compreniez bien, voici une partie de mon dossier Mes Documents :
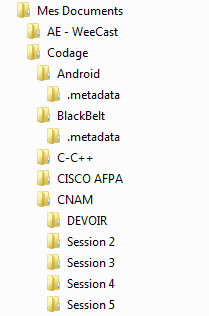
Et voici concrètement ce qu'il va se passer :
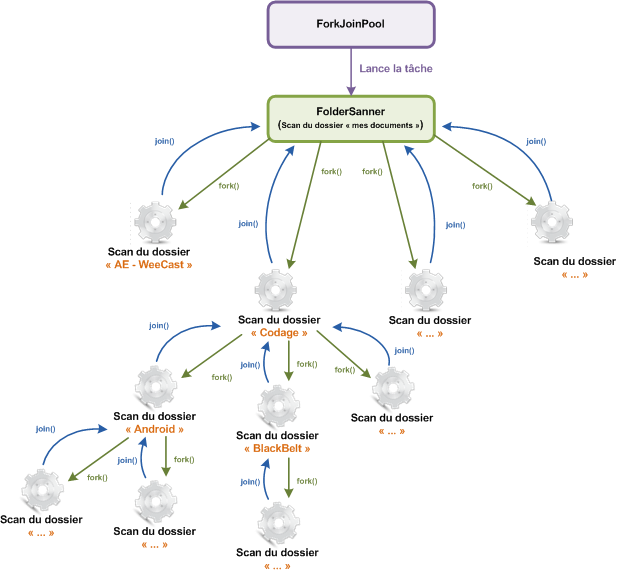
Nous pouvons maintenant voir la partie code.
FolderScanner.java
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 | public class FolderScanner extends RecursiveTask<Long>{ private Path path = null; private String filter = "*"; private long result = 0; public FolderScanner(){ } public FolderScanner(Path p, String f){ path = p; filter = f; } /** * Notre méthode de scan en mode mono thread * @throws ScanException */ public long sequentialScan() throws ScanException{ //Si le chemin n'est pas valide, on lève une exception if(path == null || path.equals("")) throw new ScanException("Chemin à scanner non valide (vide ou null) !"); System.out.println("Scan du dossier : " + path + " à la recherche des fichiers portant l'extension " + this.filter); //On liste maintenant le contenu du répertoire pour traiter les sous-dossiers try(DirectoryStream<Path> listing = Files.newDirectoryStream(path)){ for(Path nom : listing){ //S'il s'agit d'un dossier, on le scan grâce à notre objet if(Files.isDirectory(nom.toAbsolutePath())){ FolderScanner f = new FolderScanner(nom.toAbsolutePath(), this.filter); result += f.sequentialScan(); } } } catch (IOException e) { e.printStackTrace(); } //Maintenant, on filtre le contenu de ce même dossier sur le filtre défini try(DirectoryStream<Path> listing = Files.newDirectoryStream(path, this.filter)){ for(Path nom : listing){ //Pour chaque fichier correspondant, on incrémente notre compteur result++; } } catch (IOException e) { e.printStackTrace(); } return result; } /** * Méthode que nous allons utiliser pour les traitements * en mode parallèle. * @throws ScanException */ public long parallelScan() throws ScanException{ //List d'objet qui contiendra les sous-tâches créées et lancées List<FolderScanner> list = new ArrayList<>(); //Si le chemin n'est pas valide if(path == null || path.equals("")) throw new ScanException("Chemin à scanner non valide (vide ou null) !"); System.out.println("Scan du dossier : " + path + " a la recherche des fichiers portant l'extension " + this.filter); //Nous listons, comme précédemment, le contenu du répertoire try(DirectoryStream<Path> listing = Files.newDirectoryStream(path)){ //On parcourt le contenu for(Path nom : listing){ //S'il s'agit d'un dossier, on crée une sous-tâche if(Files.isDirectory(nom.toAbsolutePath())){ //Nous créons donc un nouvel objet FolderScanner //Qui se chargera de scanner ce dossier FolderScanner f = new FolderScanner(nom.toAbsolutePath(), this.filter); //Nous l'ajoutons à la liste des tâches en cours pour récupérer le résultat plus tard list.add(f); //C'est cette instruction qui lance l'action en tâche de fond f.fork(); } } } catch (IOException e) { e.printStackTrace(); } //On compte maintenant les fichiers, correspondant au filtre, présents dans ce dossier try(DirectoryStream<Path> listing = Files.newDirectoryStream(path, this.filter)){ for(Path nom : listing){ result++; } } catch (IOException e) { e.printStackTrace(); } //Et, enfin, nous récupérons le résultat de toutes les tâches de fond for(FolderScanner f : list) result += f.join(); //Nous renvoyons le résultat final return result; } /** * Méthode qui défini l'action à faire * dans notre cas, nous lan çons le scan en mode parallèles */ protected Long compute() { long resultat = 0; try { resultat = this.parallelScan(); } catch (ScanException e) { e.printStackTrace(); } return resultat; } public long getResultat(){ return this.result; } } |
Et voici maintenant notre classe de test :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | import java.nio.file.Path; import java.nio.file.Paths; import java.util.concurrent.ForkJoinPool; public class Main { public static void main(String[] args) { Path chemin = Paths.get("E:\\Mes Documents"); String filtre = "*.psd"; //Création de notre tâche principale qui se charge de découper son travail en sous-tâches FolderScanner fs = new FolderScanner(chemin, filtre); //Nous récupérons le nombre de processeurs disponibles int processeurs = Runtime.getRuntime().availableProcessors(); //Nous créons notre pool de thread pour nos tâches de fond ForkJoinPool pool = new ForkJoinPool(processeurs); Long start = System.currentTimeMillis(); //Nous lançons le traitement de notre tâche principale via le pool pool.invoke(fs); Long end = System.currentTimeMillis(); System.out.println("Il y a " + fs.getResultat() + " fichier(s) portant l'extension " + filtre); System.out.println("Temps de traitement : " + (end - start)); } } |
Pour vous donner un ordre d'idée, le scan en mode mono thread de mon dossier Mes Documents prend en moyenne 2 minutes alors que le temps moyen en mode Fork/Join est d'environ… 10 secondes ! Pas mal, hein ?
La figure suivante représente l'utilisation de mes processeurs.
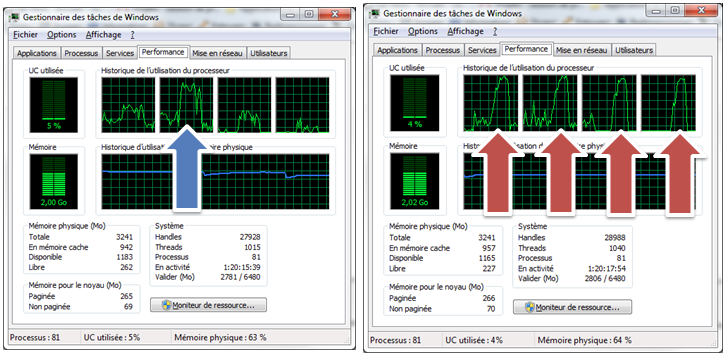
Vous constaterez que l'utilisation de ce mode est très gourmand en ressource processeurs. Il est donc à utiliser avec parcimonie.
Dans cet exemple nous avons créé dynamiquement autant de threads que nécessaires pour traiter nos tâches. Vous n'aurez peut-être pas besoin de faire ceci pour des problèmes où seulement 2 ou 3 sous-tâches suffisent, surtout si vous le savez à l'avance. L'idée maîtresse revient à définir un seuil au delà duquel le traitement se fera en mode Fork/join, sinon, il se fera dans un seul thread (je vous rappelle qu'il se peut que ce mode de fonctionnement soit plus lent et consommateur qu'en mode normal). Voici comment procéder dans ce genre de cas :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 | import java.util.concurrent.ForkJoinPool; import java.util.concurrent.RecursiveTask; public class CalculSuite extends RecursiveTask<Long> { private long debut = 0, fin = 0, resultat; private int SEUIL = 1_000; public CalculSuite(long debut, long fin){ this.debut = debut; this.fin = fin; } protected Long compute() { long nombreDeChoseAFaire = fin - debut; if(nombreDeChoseAFaire < SEUIL){ System.out.println("Passage en mode MonoThread ou le découpage calcul le résultat"); resultat = calculer(); } else{ System.out.println("Passage en mode Fork/Join"); //On découpe la tâche en deux long milieu = nombreDeChoseAFaire/2; CalculSuite calcul1 = new CalculSuite(debut, (debut+milieu)-1); calcul1.fork(); CalculSuite calcul2 = new CalculSuite(debut + milieu, fin); resultat = calcul2.compute() + calcul1.join(); } return resultat; } public long calculer(){ for(long i = debut; i <= fin; i++){ System.out.println(resultat + " + " + i); resultat += i; } return resultat; } public long getResultat(){ return resultat; } public static void main(String[] args){ ForkJoinPool pool = new ForkJoinPool(); CalculSuite calcul = new CalculSuite(0, 100_000); pool.invoke(calcul); System.out.println("Résultat du calcul : " + calcul.getResultat()); } } |
Vous pouvez voir que ce code fonctionne très bien même si son intérêt n'est que pédagogique.
- Un nouveau thread permet de créer une nouvelle pile d'exécution.
- La classe
Threadet l'interfaceRunnablese trouvent dans le packagejava.lang, aucun import spécifique n'est donc nécessaire pour leur utilisation. - Un thread se lance lorsqu'on invoque la méthode
start(). - Cette dernière invoque automatiquement la méthode
run(). - Les opérations que vous souhaitez effectuer dans une autre pile d'exécution sont à placer dans la méthode
run(), qu'il s'agisse d'une classe héritant deThreadou d'une implémentation deRunnable. - Pour protéger l'intégrité des données accessibles à plusieurs threads, utilisez le mot clé
synchronizeddans la déclaration de vos méthodes. - Un thread est déclaré mort lorsqu'il a dépilé la méthode
run()de sa pile d'exécution. - Les threads peuvent présenter plusieurs états :
NEW,RUNNABLE,BLOCKED,WAITING,TIMED_WAITINGetTERMINATED.