Dans cette partie, nous allons voir la théorie résidant derrière le machine learning et plus précisément les arbres de décisions. Restez bien attentifs et n’hésitez pas à relire les passages qui vous semblent compliqués car il est évidemment important de bien saisir ce qui est expliqué ici pour pouvoir comprendre la suite.
Les origines
Je vais commencer par introduire tous les termes un peu compliqués et les concepts qui vont revenir tout au long de ce tutoriel.
1. Mise en situation
Mettons-nous tout alors en situation, et laissez-moi vous exposer en quoi ce que je vous propose est intéressant. Figurez-vous que j’ai un ami qui s’appelle René et qui me demande s’il peut s’inscrire au MIT. Alors comme vous pouvez vous en douter, ce n’est pas moi qui décide de qui peut ou ne peut pas s’inscrire dans cet établissement réputé. Je lui ai donc dit de se référer aux responsables des inscriptions. Jusque là, vous vous demandez pourquoi je vous parle de notre cher René et vous avez tout à fait raison. Mais une petite minute, j’y arrive.
Le MIT avait des problèmes financiers parce qu’il nécessitait des dizaines de personnes préposées aux décisions d’inscriptions car ces derniers étaient extrêmement sollicités et qu’il fallait les payer, mais c’est maintenant une période révolue : tout a été informatisé ! Bien entendu, il faut trouver une manière de savoir comment expliquer à l’ordinateur comment choisir… À nouveau, ça ne va pas vous surprendre, l’ordinateur va l’apprendre tout seul ! Quoi ? Si, ça vous surprend ? Tiens donc… L’ordinateur va se créer une structure interne pour réussir à prendre des décisions. C’est justement ce que nous allons faire nous aussi (quelle coïncidence !).
Il y a bien entendu plusieurs manières pour faire un arbre de décision : on peut gentiment expliquer à l’ordinateur en le programmant étape par étape comment il doit faire pour prendre une décision (c’est la méthode facile) ou alors on peut lui demander de trouver tout seul comment le générer (c’est la méthode compliquée). Je vous laisse deviner laquelle nous allons développer ici. 
Ne perdez pas de vue notre ami René, je vais en reparler dans un instant pour vous expliquer le fonctionnement plus précis d’un arbre de décision. Mais avant ça, je vais devoir vous parler de l’apprentissage automatique !
2. Apprentissage automatique
Commençons par l’apprentissage automatique, plus connu sous son nom anglais : Machine Learning. C’est une branche de l’IA qui consiste à trouver des méthodes qui permettraient la résolution de problèmes compliqués à résoudre avec des algorithmes triviaux. Bon qu’est-ce qu’un algorithme trivial ? Il faudrait déjà commencer par définir ce qu’est un algorithme. Si ça vous intéresse vraiment fort, n’hésitez pas à aller lire le tutoriel sur ce site (ici).
Bon, qu’est-ce qu’un algorithme ?
Un algorithme, c’est une suite finie d’instructions non ambigües exprimant la résolution d’un problème. Voilà, vous êtes contents ?  Qu’est-ce que ça veut dire tout ça ? Bon, allons-y étape par étape.
Une suite finie d’instructions est une liste d’instructions qui est très clairement définie et pour laquelle le nombre d’étapes (instructions) est fini (fini ici est le contraire d’infini).
Passons à la caractéristique de non-ambigüité. Ça veut tout simplement dire que chaque instruction de la liste est très claire sur ce qu’elle fait et ne peut pas être confondue avec une autre.
Qu’est-ce que ça veut dire tout ça ? Bon, allons-y étape par étape.
Une suite finie d’instructions est une liste d’instructions qui est très clairement définie et pour laquelle le nombre d’étapes (instructions) est fini (fini ici est le contraire d’infini).
Passons à la caractéristique de non-ambigüité. Ça veut tout simplement dire que chaque instruction de la liste est très claire sur ce qu’elle fait et ne peut pas être confondue avec une autre.
Et trivial, ça veut dire quoi ?
On va considérer ici qu’un algorithme trivial c’est un algorithme (forcément ) qui est très simple et surtout qui s’exécute en un temps plus qu’acceptable. On parle de complexité polynomiale pour les intéressés. 
De manière générale, l’apprentissage automatique, c’est apprendre à faire mieux dans le futur sur base de ce qui a été expérimenté dans le passé.
Les chercheurs tentent donc de découvrir l’algorithme (ou plus justement la succession d’algorithmes) le plus efficace pour permettre au programme d’apprendre de ce qui lui est donné. Cet algorithme se veut le plus général possible :
Nous cherchons des algorithmes qui peuvent être facilement applicables à une large classe de problèmes d’apprentissage.
Le fondement même de cette branche de l’IA est de trouver une méthode de résolution de problèmes sans que des programmeurs ne doivent adapter l’algorithme en fonction du problème posé. Vous pouvez voir sur la figure suivante le fonctionnement général de l’apprentissage automatique. Les notions et le vocabulaire qui y sont relatifs sont expliqués juste après.

L’apprentissage automatique a un jargon bien particulier que l’on va détailler ici.
Attention, le vocabulaire expliqué ici est un vocabulaire relatif à une branche précise de l’apprentissage automatique : l’apprentissage automatique supervisé. C’est uniquement de celui-ci qu’il sera question ici.
Plus d’informations sur le sujet viendront plus tard dans des cours/articles dédiés.
Ce que l’on va faire, c’est classer (ou classifier) des objets. C’est le principe des algorithmes que je vais vous détailler dans ce cours. Ces objets vont avoir plusieurs caractéristiques (que l’on peut également appeler attributs). En fonction de ces attributs que l’on va explorer et tester, on va finir par attribuer une classe à chaque objet. Chacun de ces objets est appelé exemple. On va donc manipuler des exemples composés d’attributs pour leur attribuer une classe.
Il existe deux types d’exemples : les exemples étiquetés et les exemples non étiquetés. Leur différence est très simple. Les exemples étiquetés sont ceux qui sont pré-classés et qui donc vont être utilisés pour que le programme sache comment classer les exemples suivants. Les exemples suivants, vous l’aurez deviné, sont eux les exemples non étiquetés. La méthode qui va être utilisée pour déterminer comment étiqueter les exemples non étiquetés sur base des exemples étiquetés s’appelle l’algorithme d’apprentissage. Nous allons en voir deux ici : l’algorithme ID3 et son successeur, l’algorithme C4.5. Cet algorithme d’apprentissage (peu importe duquel il est question) va nous permettre d’extraire une règle que l’on appelle concept qui va nous dire comment on fait pour étiqueter un exemple.
Récapitulons :
nous allons créer un programme composé d’un algorithme d’apprentissage qui va nous permettre d’analyser des exemples étiquetés (eux-mêmes composés d’attributs) pour pouvoir classer d’autres exemples mais cette fois-ci des exemples non étiquetés, et ce à l’aide d’un concept.
Pour rendre les choses aussi simples que possible, nous allons considérer qu’il n’y a que deux classes possibles que nous pouvons appeler 0 et 1. Nous allons également supposer qu’il y a toujours moyen de lier l’exemple à son étiquette. En réalité, il est possible que ça ne soit pas le cas, mais c’est tout de même plus simple de vous expliquer comment ça marche si tout se déroule bien ! 
Notez que l’histoire du nombre d’étiquettes réduit à 2 n’est pas tout le temps d’application. Forcément, par soucis d’optimisation, on cherche toujours à limiter le nombre de possibilités et de tournures que peut prendre un problème. On tente donc de réduire le nombre d’étiquettes autant que possible. Mais on peut très bien être confronté à un problème de classification à 3, 4 ou encore 150 classes !
Rassurez-moi, tout le monde est encore vivant à la fin de cette première partie un peu ardue ? 
Revenons-en au déroulement général d’un problème d’apprentissage automatique. Le fonctionnement est le suivant : l’algorithme central est le premier élément de l’image, il est implémenté avant de faire fonctionner le programme. C’est d’ailleurs deux de ces algorithmes que nous allons étudier ici. L’étape suivante est de fournir un set d’exemples étiquetés pour que le programme puisse comprendre (grâce à l’algorithme central) par quel concept (quelle règle) les exemples ont été étiquetés. Une fois le concept extrait, on n’y touche plus, et on soumet de nouveaux exemples, cette fois-ci non étiquetés !, à ce concept afin que le programme fasse une analyse systématique et réussisse à étiqueter lui-même les nouveaux exemples fournis. Donc si vous regardez de plus près la figure 1, vous vous apercevrez qu’il y a présence de deux axes : un axe horizontal qui est le premier expérimenté, et qui n’est expérimenté qu’une seule fois, et puis il y a l’axe vertical qui, quant à lui, ne peut être opéré qu’après avoir opéré l’axe horizontal, et est utilisé plus d’une fois (sinon quel en serait l’intérêt ?).
État des lieux
1. Les arbres de décisions
En anglais decision trees, les arbres de décisions sont utilisés entre autres dans l’apprentissage automatique. Mais attention, c’est loin d’être leur seul domaine d’application ! Ce modèle est appelé arbre car il est composé de nœuds ayant chacun un certain nombre (variable) de fils. Le principe est de partir d’en haut de l’arbre (du nœud père de tous les autres, que l’on appelle racine) et de tester l’attribut en question et de suivre le chemin.
Juste avant d’en voir un exemple, il serait intéressant de donner une définition d’un arbre de décision.
Un arbre de décision est un arbre1 (dirigé) dont les nœuds représentent un choix sur un attribut, les arcs représentent les possibilités pour l’attribut testé et les feuilles représentent les décisions en fonction des compositions d’attributs.
Voici un exemple d’arbre de décision :
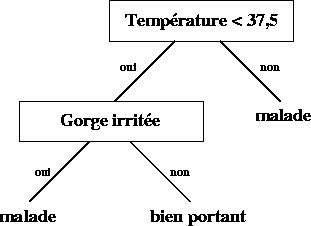
Laissez-moi vous expliquer la méthodologie pour parcourir un arbre de décision en machine learning. Pour ce, il faut déjà savoir à quoi il sert.
Considérons que cet arbre-ci est une méthode systématique pour traiter les cas d’inscriptions au MIT. Vous souvenez-vous de René, mon bon ami ? C’est ici qu’il réintervient : nous allons donc suivre étape par étape le traitement de sa demande d’inscription au MIT.
On commence tout en haut, donc par la question
est diplômé du lycée (ou de l’enseignement secondaire) ?
Ici, deux choix s’offrent à nous comme on peut le voir sur l’image. Deux branches partent de la première case. Ces deux branches sont NON et OUI. René a donc deux possibilités : soit il a un diplôme d’études supérieures, soit il n’en a pas. Jusque-là, tout le monde est d’accord avec moi, non ?
Fort heureusement pour nous (et surtout pour René !), ce dernier a bien fini ses études. On suit donc la branche OUI (celle de droite) et on laisse tomber tout ce qui suit la branche de gauche.
On continue de descendre et on arrive à la question
a plus de 18 ans ?
À nouveau, deux choix s’offrent à nous : soit René a plus de 18 ans, soit il n’a pas plus de 18 ans.
Et pour ceux qui rouspéteraient parce qu’on ne laisse pas à René la possibilité d’avoir 18 ans pile, je leur répondrai qu’il attendra le lendemain pour venir s’inscrire si c’est le cas, na ! 
C’est le jour de chance de notre ami René : il a eu 18 ans la semaine passée. Il peut donc passer sur la branche OUI (la branche de gauche). À nouveau, on oublie le reste des branches (donc uniquement la branche de droite).
On continue de descendre… Et l’ordinateur nous harcèle de questions : il nous demande maintenant
a des parents riches ?
Euh… Bah René vient d’une famille relativement aisée mais mine de rien, on ne peut pas les qualifier de riches. Donc regardons ce que l’arbre nous propose : OUI, MOYEN, ou NON. Choisissons MOYEN parce que sa famille n’est ni pauvre ni riche. Alors on fait encore et toujours le même procédé, on suit la branche MOYEN et on oublie les deux autres. L’ordinateur en redemande :
a droit à une bourse ?
C’est là que ça coince. René est un pauvre étudiant français qui n’a pas droit à avoir une bourse aux États-Unis d’Amérique. On est alors contraints de suivre la branche NON de l’arbre et à nouveau d’oublier le reste.
Maintenant, l’ordinateur ne nous demande plus rien. Mais il nous affiche ceci :
Non
Pourquoi ? C’est assez simple : on a continué sur la branche, mais on ne rencontre plus de nœud. On a rencontré une feuille. C’est le nom que l’on donne à une extrémité d’un arbre. Le fait de tomber sur une feuille nous fait arrêter de chercher vu que l’on vient de recevoir la réponse du MIT. Et cette réponse est non. Je vous laisse réessayer avec d’autres personnes que René qui ont d’autres caractéristiques ou plutôt d’autres attributs. Si ce mot ne vous dit rien, je vous recommande vivement de remonter d’un chapitre et de relire le (§1.1.).
2. ID3
ID3 est un des nombreux algorithmes possibles pour générer un arbre de décision, et c’est également celui qui va être développé dans la première partie de ce cours. Cet algorithme à été développé en 1986 par Ross Quinlan. Il l’a publié dans le magazine Machine Learning parmi d’autres articles.
3. C4.5
C4.5 est en quelque sorte le petit frère d’ID3. C4.5 a également été développé par Ross Quinlan dans les années 1990 et a aussi été publié dans Machine Learning.
Je n’ai pas vraiment détaillé ces deux derniers chapitres car c’est ce que nous allons faire dans toute la suite de ce cours donc ne soyez pas impatients ! 
Il est donc nécessaire que vous ayez bien compris les notions abordées ici car vous en aurez besoin pour suivre la suite de ce cours ! Si vous n’avez pas retenu tout le vocabulaire exposé au point 2, ce n’est pas très grave, vous pourrez y retourner en cas de trou de mémoire. Cependant, si vous n’avez pas saisi ce qu’était un arbre de décision et comment ça s’utilise ce machin là, il est préférable pour vous de relire ce chapitre car la suite sera beaucoup plus ardue sinon.
Quoi qu’il en soit, préparez-vous à entrer dans le vif du sujet avec l’exposition de l’algorithme ID3 !
Maintenant que vous savez ce qu’est un arbre de décision, nous allons pouvoir nous lancer dans la construction d’une telle structure.