
- Une API indiquant l'IP du client en deux lignes avec Nginx
- Permuter deux variables sans en utiliser une troisième
Ceci est le deuxième volet d’une trilogie sur la réalisation d’un petit projet non-trivial en Go, et de son déploiement dans un cluster Kubernetes. Dans l’épisode précédent, nous sommes partis d’une idée formulée sur le serveur Discord de ZdS et avons implémenté, testé et déployé notre bot Discord dans le cloud.
Dans ce billet, nous allons ajouter à ce bot sa killer feature, c’est-à-dire LA fonctionnalité qui va servir à le différencier de tous les autres projets similaires. Autrement dit, nous allons donner à nos utilisateurs une bonne raison d’inviter notre bot xkcd plutôt qu’un autre sur leur serveur ! 
- Ce que nous allons réaliser
- Indexer et rechercher des documents avec bleve
- Indexer xkcd
- Réagir aux mentions
- Persister les données avec Kubernetes
- Testons !
Ce que nous allons réaliser
Si l’on fait une recherche sur top.gg pour trouver un bot qui interagit avec xkcd, nous pouvons remarquer que la plupart des projets qui remontent implémentent pas mal de features similaires les uns par rapport aux autres.
- Tous ces projets (ou presque) permettent de récupérer un xkcd à partir de son numéro, ou bien de récupérer le dernier paru.
- Certains rajoutent une fonctionnalité
random, permettant d’afficher un xkcd au hasard. - Certains permettent de faire des recherches, mais de façon plus ou moins laborieuse.
Cela dit, lorsque l’on y regarde de plus près, les bots les plus complets sont aussi les plus complexes à utiliser. Si nous voulons nous différencier, il faut que nous soignions l’expérience utilisateur et la rendions la plus intuitive possible. Sur Discord, de nombreux bots utilisent une syntaxe avec un préfixe arbitrairement complexe. C’est d’ailleurs ce que nous avons implémenté jusque là, mais est-ce vraiment la façon la plus simple d’interagir avec un bot ?
En ce qui me concerne, je suis partisan d’adopter une logique simple : pour interagir avec notre bot, il faut que ce soit aussi simple que @xkcd <ce que je veux>. Typiquement, ce que nous allons viser dans ce billet :
@xkcd 386doit retourner le xkcd #386,@xkcd latestdoit retourner le tout dernier xkcd,@xkcd randomdoit retourner un xkcd au hasard,@xkcd helpdoit bien sûr retourner un message d’aide.
Pour ce qui est de rechercher un xkcd, il faut que nous soyons capables de répondre de façon intuitive au besoin le plus courant : lorsque quelqu’un se souvient de la punchline ou d’un détail de l’une de ces BD (donc dans les dialogues, le titres ou à la rigueur le texte alternatif), il doit pouvoir le retrouver en décrivant ces mots-clés.
Par exemple si je me souviens de cette fameuse BD à propos des injections SQL, où la mère répond qu’elle surnomme son fils "Bobby tables", je devrais pouvoir retrouver celle-ci en tapant @xkcd bobby tables. Contrairement à certain des bots sus-cités, il est hors de question de confronter l’utilisateur à une liste de résultats qu’il doit parcourir : notre bot doit répondre avec la BD qui correspond le mieux à la recherche, et donner un moyen à l’utilisateur de préciser sa demande si ce n’est pas ce qu’il voulait. En somme, nous avons besoin de gérer la syntaxe classique des moteurs de recherche : @xkcd video games -20 ou @xkcd video games -ferret doit permettre de retrouver ce xkcd à propos des jeux vidéos dont on se souvient, et qui n’est pas le #20 où il est question d’un furet, et où l’un des personnages dit à un moment "Let’s go play video games".
Enfin, par soucis du détail, lorsque le bot ne sait pas quoi répondre, cela ne veut plus dire la même chose qu’avant : ce n’est plus une erreur, mais simplement qu’il n’a rien trouvé de satisfaisant. Pour cette raison, plutôt que de réagir à la commande de l’utilisateur avec un 💩 (sous-entendant que c’est lui qui a fait du caca), il convient de lui indiquer que l’on ne sait pas quoi répondre : 🤷.
Indexer et rechercher des documents avec bleve
Extraire les dialogues d’une BD
Pour indexer une BD, nous allons avoir besoin d’en isoler les dialogues. Souvenez-vous des méta-données que nous retourne xkcd :
{
"month": "2",
"num": 386,
"link": "",
"year": "2008",
"news": "",
"safe_title": "Duty Calls",
"transcript": "[[A stick man is behind computer]]\nVoice outside frame: Are you coming to bed?\nMan: I can't. This is important.\nVoice: What?\nMan: Someone is WRONG on the internet.\n{{title text: What do you want me to do? LEAVE? Then they'll keep being wrong!}}",
"alt": "What do you want me to do? LEAVE? Then they'll keep being wrong!",
"img": "https://imgs.xkcd.com/comics/duty_calls.png",
"title": "Duty Calls",
"day": "20"
}
Si l’on observe de plus près le format du transcript, on remarque que :
- Les lignes décrivant ce qui est dessiné sont encadrées par
[[et]]; - Le texte alternatif figure entre
{{et}}; - Les dialogues sont des lignes au format
Personnage: texte de la réplique, c’est le texte de la réplique qui nous intéresse ; - Les autres lignes sont "de la voix off", elles aussi nous intéressent.
Écrivons une petite méthode pour extraire les répliques d’un Comic :
package xkcd
import (
"bufio"
"fmt"
"strings"
)
// Script parses the transcript and returns all visible text from the image
func (c *Comic) Script() string {
var w strings.Builder
scanner := bufio.NewScanner(strings.NewReader(c.Transcript))
for scanner.Scan() {
line := scanner.Text()
if strings.HasPrefix(line, "{{") || strings.HasPrefix(line, "[[") {
continue
}
split := strings.SplitN(line, ":", 2)
if len(split) == 2 {
line = split[1]
}
fmt.Fprintln(&w, strings.TrimSpace(line))
}
return w.String()
}
Bien, maintenant passons aux choses sérieuses…
La bibliothèque d’indexation qui va bien
Vous aurez compris, nous allons avoir besoin d’incorporer un moteur d’indexation à notre bot. Ça tombe bien, car il en existe un tout beau en Go, qui supporte l’indexation et la recherche de documents arbitraires avec la syntaxe classique que nous venons de décrite plus haut : bleve.
Créons un petit package pour ajouter les fonctionnalités de bleve à notre programme :
package index
import (
"fmt"
"log"
"sync"
"github.com/blevesearch/bleve"
"gitlab.com/neuware/xkcd-bot/pkg/xkcd"
)
var (
path = "xkcd.index"
idx bleve.Index
once sync.Once
)
// open the index, creating it if it doesn't exist
func open() {
var err error
if idx, err = bleve.Open(path); err == nil {
return
}
log.Printf("creating index at %q", path)
m := bleve.NewIndexMapping()
idx, err = bleve.New(path, m)
if err != nil {
log.Fatalf("inex creation failed: %s", err)
}
}
// SetPath sets the path of the current index.
func SetPath(p string) {
path = p
if idx != nil {
open()
}
}
// HasComic returns true if a comic with given ID exists in the current index.
func HasComic(id int) bool {
once.Do(open)
doc, _ := idx.Document(fmt.Sprint(id))
return doc != nil
}
// AddComic adds a comic into the current index.
func AddComic(c *xkcd.Comic) {
once.Do(open)
id := fmt.Sprint(c.Num)
c.Transcript = c.Script()
idx.Index(fmt.Sprint(c.Num), c)
log.Printf("indexed document #%s", id)
}
// A SearchResult is the association of a comic number and its score for the
// search.
type SearchResult struct {
ComicNum string
Score float64
}
// Search performs a full-text search on the current index.
func Search(query string) []SearchResult {
once.Do(open)
results, err := idx.Search(bleve.NewSearchRequest(bleve.NewQueryStringQuery(query)))
if err != nil {
log.Printf("while searching for %q: %s", query, err)
}
res := make([]SearchResult, len(results.Hits))
for i, r := range results.Hits {
res[i] = SearchResult{r.ID, r.Score}
}
return res
}
Je vous vois venir d’ici :
Tu utilises des variables globales ?! Mais c’est mal !
Dans les langages sans namespace comme C, certes, mais en Go c’est plutôt courant, voire idiomatique à en juger par le package net/http. Dans notre programme, nous avons seulement besoin d’indexer un unique type de documents, et nous n’aurons certainement jamais besoin de plus que ça, alors autant nous simplifier la vie, non ?
Pour résumer ce code :
SetPathindique où est sauvegardé l’index que nous voulons utiliser, sur le disque,HasComicretournetruesi l’index contient déjà la BD dont le numéro est passé en argument,AddComicindexe toutes les méta-données d’une BD après en avoir extrait les dialogues,Searchréalise une recherche et retourne une liste de résultats, chacun composé d’un numéro de BD et d’un score de recherche : la liste sera ordonnée avec les résultats les plus pertinents en premier (c’est le comportement par défaut debleve).
Simple et efficace.
Indexer xkcd
Maintenant que nous avons incorporé un moteur d’indexation à notre bot, il est temps de lui faire manger des données. Réfléchissons à la façon la plus maligne de nous y prendre.
Sonder le site pour détecter les nouvelles parutions
Supposons que le bot possède déjà un index bien rempli. Pendant qu’il va tourner, de nouveaux contenus seront publiés. Dans ces conditions, il faut que le bot soit capable de détecter les nouvelles parutions sur xkcd. Pour ce faire, nous allons implémenter un "watcher", qui va récupérer, à intervalles régulier, le dernier xkcd paru, et regarder s’il ne le connait pas encore. Le cas échéant, lorsqu’une nouvelle BD est parue, celui-ci va appeler des callbacks en leur passant les méta-données de la BD.
De la même façon que pour l’indexation, nous allons implémenter ceci sous la forme d’un état privé qui sera global à tout le processus.
package xkcd
import (
"sync"
"time"
)
// Callback is the type of functions that get called when a new comic is published
type Callback func(*Comic)
type watchState struct {
num int
callbacks []Callback
period time.Duration
mtx sync.Mutex
}
// setPeriod sets the polling period
func (w *watchState) setPeriod(p time.Duration) {
w.mtx.Lock()
defer w.mtx.Unlock()
w.period = p
}
// addCallback registers a callback to the watchState.
func (w *watchState) addCallback(cbk Callback) {
w.mtx.Lock()
defer w.mtx.Unlock()
w.callbacks = append(w.callbacks, cbk)
}
// latestNum returns the latest retrieved comic number.
func (w *watchState) latestNum() int {
w.mtx.Lock()
defer w.mtx.Unlock()
return w.num
}
Notre état privé va donc être composé :
- du numéro du dernier xkcd,
- des callbacks à appeler en cas de nouvelle BD,
- de la période à laquelle nous allons sonder le site,
- et d’un mutex pour se protéger contre les accès concurrents.
Les méthodes implémentées ici n’ont rien de particulier, il s’agit de getters et de setters protégés par le mutex. Implémentons maintenant la mise à jour régulière :
// newWatcher creates and starts a new Watcher.
// The watcher polls xkcd.com every minute by default.
func newWatcher() *watchState {
latest, _ := Get(Latest)
w := &watchState{
callbacks: make([]Callback, 0, 1),
period: time.Minute,
num: latest.Num,
}
go func() {
for {
w.checkUpdates()
time.Sleep(w.period)
}
}()
return w
}
// checkUpdates polls xkcd for new strips
func (w *watchState) checkUpdates() {
w.mtx.Lock()
defer w.mtx.Unlock()
c, err := Get(Latest)
if err != nil {
log.Println("while polling xkcd for updates:", err)
}
if w.num != 0 && c.Num != w.num {
log.Printf("new xkcd: #%d (%s)", c.Num, c.SafeTitle)
w.num = c.Num
for _, cbk := range w.callbacks {
// Copy comic contents to avoid side effects
tmp := *c
cbk(&tmp)
}
}
}
La partie la plus tricky, ici, c’est celle que j’ai surligné. Lorsque l’on crée un watcher, on lance un appel périodique à la méthode checkUpdates dans une goroutine séparée. Vous remarquerez que je n’ai pas pris la peine de programmer l’arrêt de cette goroutine puisque nous avons uniquement besoin que celle-ci tourne tant que le bot est en marche. Si ce package xkcd avait été destiné à être distribué indépendamment du bot, il aurait fallu le faire, mais en ce qui nous concerne pour ce projet, il ne sert à rien de résoudre un problème qui n’est pas le nôtre.
Maintenant, il ne nous reste plus qu’à implémenter nos fonctions publiques :
var (
watcher *watchState
once sync.Once
)
func initWatcher() {
watcher = newWatcher()
}
// SetPeriod sets the poll period
func SetWatchPeriod(p time.Duration) {
once.Do(initWatcher)
watcher.setPeriod(p)
}
// OnNewComic adds a function to be called when a new xkcd comic is detected.
func OnNewComic(cbk Callback) {
once.Do(initWatcher)
watcher.addCallback(cbk)
}
// LatestNum returns the latest xkcd number.
func LatestNum() int {
once.Do(initWatcher)
return watcher.latestNum()
}
Ainsi :
SetWatchPeriodpermet de modifier la période à laquelle on interroge xkcd,OnNewComicenregistre un callback qui sera appelé avec les dernières publications,LatestNumretourne le numéro du dernier xkcd paru, sans avoir besoin de faire un appel au site, ce qui va nous permettre d’économiser quelques appels superflus.
Ces trois fonctions démarrent le watcher si celui-ci n’existe pas encore (c’est à cela que servent les lignes once.Do(initWatcher)).
L’indexation initiale
Quand le bot va démarrer pour la première fois, il va falloir qu’il se mette à indexer tout le contenu existant. Quand il va (re-)démarrer (supposons après une longue coupure), il va également falloir qu’il rattrape tout ce qu’il a raté depuis la dernière fois qu’il a fonctionné. Cela revient donc à :
- Récupérer le tout dernier xkcd au démarrage dont le numéro est
N, - Itérer de
1àNet indexer toutes les BD qui ne sont pas déjà présentes dans l’index.
Lorsque cette boucle sera terminée, l’index sera à jour.
Il faut faire très attention ici : cette mise à jour risque de résulter en de très nombreux appels au site d’xkcd, particulièrement la première fois que le bot sera lancé. Afin de nous comporter en gens civilisés, il est bon de ne pas faire d’appel au site pour récupérer des infos que nous possédons déjà et de mettre un délai entre deux appels au site. Espacer nos appels d’une seconde est suffisant. Cela signifie que la toute première passe d’indexation va prendre 40 minutes à la louche (le site comporte 2383 strips à l’heure où sont écrites ces lignes).
func updateIndex() {
log.Println("updating the index")
latest := xkcd.LatestNum()
for num := 1; num <= latest; num++ {
if index.HasComic(num) {
continue
}
c, err := xkcd.Get(fmt.Sprint(num))
if err != nil {
log.Printf("couldn't get #%d: %s", num, err)
continue
}
index.AddComic(c)
time.Sleep(time.Second)
}
log.Printf("search index up to date")
}
L’indexation sera donc démarrée de la façon suivante :
func startIndexing(path string) {
index.SetPath(path)
xkcd.OnNewComic(index.AddComic)
// start updating the index in the background
go updateIndex()
}
Mettre tout bout à bout
Notre bot a maintenant besoin de prendre 3 paramètres de configuration :
- Son token,
- Le chemin de son index dans le système de fichiers,
- La période à laquelle nous voulons détecter les nouvelles publications.
La façon idiomatique de nous y prendre, c’est de créer une structure Config qui contient ces valeurs, et que l’on passera en argument de la fonction Run. Voici comment celle-ci est désormais adaptée :
package bot
import (
"fmt"
"log"
"os"
"os/signal"
"syscall"
"time"
"github.com/bwmarrin/discordgo"
"gitlab.com/neuware/xkcd-bot/pkg/xkcd"
)
type Config struct {
Token string
IndexPath string
WatchPeriod time.Duration
}
// Run runs the discord bot
func Run(cfg *Config) error {
dg, err := discordgo.New("Bot " + cfg.Token)
if err != nil {
return fmt.Errorf("couldn't create discordgo session: %w", err)
}
dg.AddHandler(onMessageCreate)
err = dg.Open()
if err != nil {
return fmt.Errorf("couldn't open connection: %w", err)
}
defer dg.Close()
sc := make(chan os.Signal, 1)
signal.Notify(sc, syscall.SIGINT, syscall.SIGTERM, os.Interrupt, os.Kill)
log.Println("Up and running. Press Ctrl-C to exit.")
xkcd.SetWatchPeriod(cfg.WatchPeriod)
startIndexing(cfg.IndexPath)
<-sc
return nil
}
Aucune difficulté particulière ici.
Adapter le démarrage du bot
Mettons enfin à jour notre main pour prendre en compte ces nouvelles valeurs de configuration. Le bot va maintenant lire les variables d’environnement suivantes :
BOT_TOKEN: le token Discord,WATCH_PERIOD: la période de raffraichissement (1 minute par défaut),INDEX_PATH: le chemin de l’index.
Je le place dans une balise spoiler.
app/main.go (Afficher/Masquer)package main
import (
"flag"
"log"
"os"
"time"
"gitlab.com/neuware/xkcd-bot/pkg/bot"
)
const (
defaultWatchPeriod = time.Minute
defaultIndexPath = "./xkcd.index"
)
var (
token string
indexPath string
watchPeriod time.Duration
)
func init() {
flag.StringVar(&token, "t", os.Getenv("BOT_TOKEN"), "Bot token")
p := os.Getenv("INDEX_PATH")
if p == "" {
p = defaultIndexPath
}
flag.StringVar(&indexPath, "index", p, "Index path")
var period time.Duration
if d, err := time.ParseDuration(os.Getenv("WATCH_PERIOD")); err == nil {
period = d
} else {
period = defaultWatchPeriod
}
flag.DurationVar(&watchPeriod, "p", period, "Watch period")
flag.Parse()
}
func main() {
err := bot.Run(&bot.Config{
Token: token,
IndexPath: indexPath,
WatchPeriod: watchPeriod,
})
if err != nil {
log.Fatal(err)
}
}
Réagir aux mentions
La dernière chose qu’il nous reste à faire avant de déployer le bot, c’est de le rendre capable de réagir lorsque l’on s’adresse directement à lui. En soi, ce n’est pas bien difficile, mais il y a des choses qui ne s’inventent pas.
Il faut savoir que lorsque l’on mentionne quelqu’un sur Discord, cela peut prendre l’une des deux formes suivantes (où 1234567 est à remplacer par l’ID de la personne):
<@1234567><@!1234567>
Ensuite, et nous pourrons le vérifier en testant le bot, à partir du moment où les documents sont indexés avec le numéro du xkcd comme identifiant unique, il est bon de savoir qu'une recherche sur le numéro d’un xkcd remontera forcément le document correspondant en première position. Cela veut dire que nous n’avons pas besoin de créer un cas particulier pour chercher un xkcd en fonction de son ID. Cool, non ? 
En dehors de cela, aucune difficulté. Vous remarquerez que le code suivant rajoute également, par rapport au précédent billet, la commande random pour récupérer un xkcd au hasard (ce qui nous impose d’initialiser le générateur de nombres aléatoires) :
package bot
import (
"fmt"
"log"
"math/rand"
"strings"
"time"
"github.com/bwmarrin/discordgo"
"gitlab.com/neuware/xkcd-bot/pkg/index"
"gitlab.com/neuware/xkcd-bot/pkg/xkcd"
)
const prefix = "xkcd!"
func getCommand(dg *discordgo.Session, content string) (string, bool) {
mention := "<@" + dg.State.User.ID + "> "
nmention := "<@!" + dg.State.User.ID + "> "
switch {
case strings.HasPrefix(content, prefix):
return content[len(prefix):], true
case strings.HasPrefix(content, mention):
return content[len(mention):], true
case strings.HasPrefix(content, nmention):
return content[len(nmention):], true
}
return "", false
}
func onMessageCreate(dg *discordgo.Session, m *discordgo.MessageCreate) {
if m.Author.ID == dg.State.User.ID {
return
}
cmd, ok := getCommand(dg, m.Content)
if !ok {
return
}
var err error
switch cmd {
case "help":
dg.ChannelMessageSend(
m.ChannelID,
fmt.Sprint(
"Commands:"+
"\n* `latest`: Show the latest xkcd"+
"\n* `random`: Pick a random xkcd"+
"\n\nOtherwise, I'll show you the xkcd strip that best matches your query."+
" You can give me a comic number, or its title, or search by keywords."+
"\nI also support advanced syntax. e.g: `video games -ferret`"+
" searches for a comic that talks about video games,"+
" but not the one with the ferret.",
),
)
case "latest":
err = showXKCD(dg, m.ChannelID, xkcd.Latest)
case "random":
err = showRandomXKCD(dg, m.ChannelID)
default:
res := index.Search(cmd)
if len(res) > 0 {
err = showXKCD(dg, m.ChannelID, res[0].ComicNum)
} else {
err = fmt.Errorf("search for %q didn't yield any result", cmd)
}
}
if err != nil {
dg.MessageReactionAdd(m.ChannelID, m.ID, "🤷")
log.Printf("Error processing command %q: %s", cmd, err)
}
}
func showRandomXKCD(dg *discordgo.Session, channelID string) error {
return showXKCD(dg, channelID, fmt.Sprint(rand.Int()%xkcd.LatestNum()+1))
}
func showXKCD(dg *discordgo.Session, channelID, xkcdID string) error {
c, err := xkcd.Get(xkcdID)
if err != nil {
return err
}
date, _ := c.Date()
_, err = dg.ChannelMessageSendEmbed(
channelID,
&discordgo.MessageEmbed{
URL: c.URL(),
Type: discordgo.EmbedTypeImage,
Title: c.SafeTitle,
Description: c.Alt,
Image: &discordgo.MessageEmbedImage{URL: c.Img},
Footer: &discordgo.MessageEmbedFooter{
Text: fmt.Sprintf("#%d (%s)", c.Num, date.Format("2006-01-02")),
},
},
)
return err
}
func init() {
rand.Seed(time.Now().UnixNano())
}
Persister les données avec Kubernetes
Mettre à jour l’image Docker
Nous n’avons rien à changer au niveau des Dockerfile du précédent billet. Poussons simplement la nouvelle image :
$ make image
$ make publish
Mettre à jour le déploiement
Au niveau du déploiement, notre bot est maintenant un petit peu plus compliqué à gérer proprement.
En effet, si nous le déployons de la même façon que la dernière fois, cela ne posera a priori aucun problème et, une fois passées les 40 minutes d’indexation, celui-ci fonctionnera tout à fait normalement. Cependant, lorsque nous le redémarrerons, toutes les données qu’il avait indexées seront perdues, et il faudra qu’il aspire à nouveau les métadonnées sur le site d’xkcd… Pour éviter cela, nous avons besoin que les données écrites par notre programme sur son système de fichiers soient persistantes. C’est là qu’intervient une nouvelle abstraction de Kubernetes : le Persistent Volume Claim.
Concrètement, lorsqu’un pod a besoin d’écrire ou de lire des données qui doivent lui survivre, il est possible de demander à Kubernetes : « Réserve-moi un espace de telle taille sur un disque ». Celui-ci va alors se débrouiller pour nous fournir un "espace disque", ou plutôt, un volume avec les propriétés que nous lui demandons, que nous pouvons monter dans les conteneurs de manière à ce que ceux-ci puissent lire ou écrire dedans.
Après un test en local, j’ai pu déterminer qu’un index sur tous les xkcd depuis la création du site nécessite 40Mio. Je vais donc ici réclamer un volume avec une petite marge (100Mio) à Kubernetes :
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: xkcd-index
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 100Mi
Cette configuration lui dit "débrouille-toi pour me donner le volume que tu veux, mais je veux qu’il fasse au moins 100Mio, et je te garantis qu’un seul pod à la fois cherchera à y accéder en lecture et en écriture".
$ kubectl apply -f deploy/volume.yml
persistentvolumeclaim/xkcd-index created
Maintenant, adaptons le fichier de déploiement, de manière à ce que notre bot stocke son index dans ce volume (et configurons-le, au passage, pour qu’il sonde le site toutes les heures en quête d’une nouvelle publication) :
apiVersion: apps/v1
kind: Deployment
metadata:
name: xkcd-bot
spec:
replicas: 1
selector:
matchLabels:
app: xkcd-bot
template:
metadata:
labels:
app: xkcd-bot
spec:
containers:
- name: bot
image: neuware/xkcd-bot
env:
- name: BOT_TOKEN
valueFrom:
secretKeyRef:
name: bot-secret
key: token
- name: INDEX_PATH
value: /var/lib/xkcd.index
- name: WATCH_PERIOD
value: 1h
volumeMounts:
- mountPath: /var/lib/xkcd.index
name: xkcd-index-storage
readOnly: false
volumes:
- name: xkcd-index-storage
persistentVolumeClaim:
claimName: xkcd-index
Appliquons cette configuration :
$ kubectl apply -f deploy/deployment.yml
deployment.apps/xkcd-bot configured
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
xkcd-bot-5fbd9cc49c-6xm59 1/1 Running 0 19s
Et voilà ! Notre déploiement est mis à jour, le pod a été automatiquement recréé avec sa nouvelle image, sa nouvelle configuration, et son volume de données. Jetons un oeil à ses logs :
$ kubectl logs -f xkcd-bot-5fbd9cc49c-6xm59
2020/11/11 13:59:47 Up and running. Press Ctrl-C to exit.
2020/11/11 13:59:47 updating the index
2020/11/11 13:59:57 indexed comic #1
2020/11/11 13:59:58 indexed comic #2
2020/11/11 13:59:59 indexed comic #3
...
Bien, allons prendre un café (et écrivons ce billet) le temps qu’il finisse de créer son index, avant de le tester.
Testons !
Allez, l’heure du grand test a sonné !
Pour rappel, vous pouvez vous-même tester mon instance du bot en l’invitant sur votre serveur.
Afficher un xkcd aléatoire
C’est une fonctionnalité que l’on n’avait pas implémentée dans le précédent billet, vérifions que ça fonctionne :
Bon… je ne vais pas spammer avec des captures d’écran, on voit bien ici que deux appels successifs retournent deux strips au hasard.
Et la recherche alors ?
Essayons avec l’exemple dont j’ai parlé au début. Le bot arrive-t’il à retrouver le xkcd sur les injections SQL si je lui demande bobby tables ?
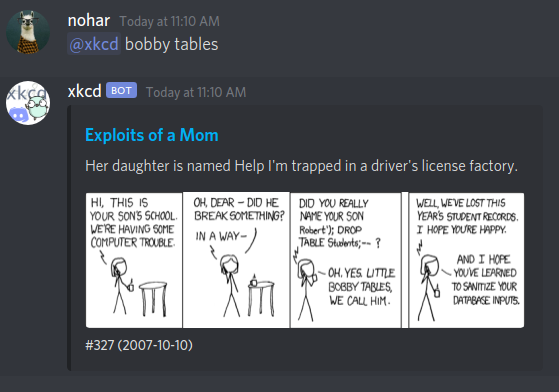
Victoire ! \o/
Essayons maintenant une recherche plus compliquée. "Je veux le xkcd qui parle des jeux vidéo là"…
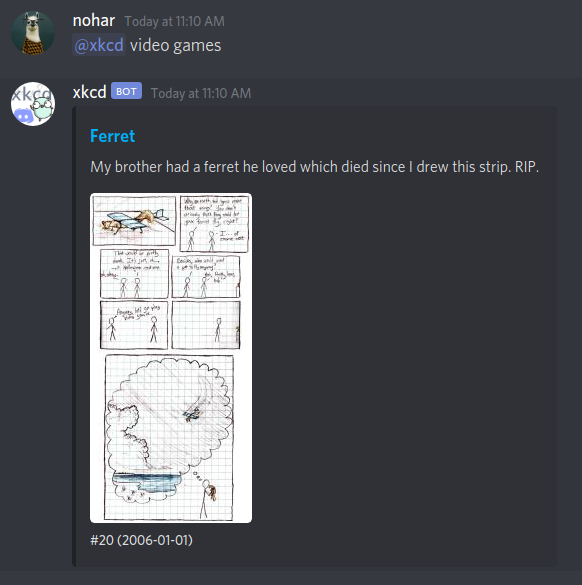
Non, pas celui sur le furet…
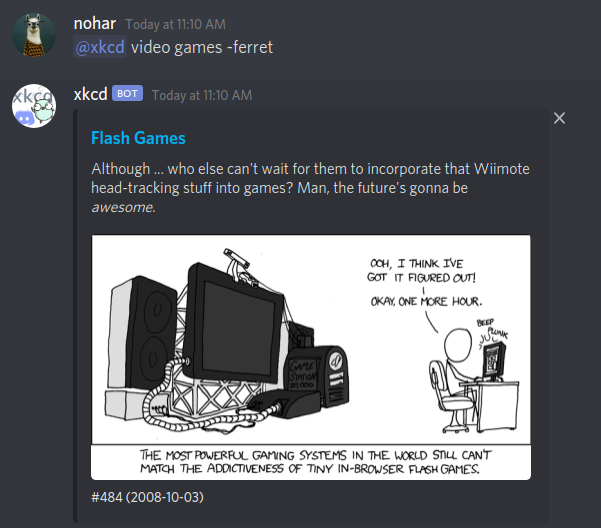
Voilà, celui-là.
Au fait, on peut toujours les rechercher par leur ID ?
Essayons, demandons-lui le numéro 456 pour voir.
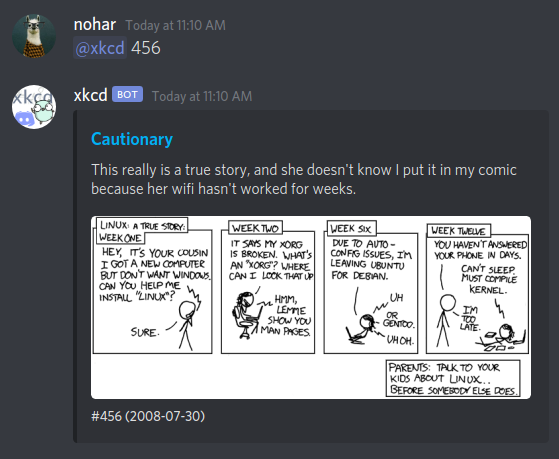
Bon, je pense que l’on peut conclure que tout fonctionne comme on s’y attend.
Voilà qui conclut notre second épisode.
Dans le prochain billet, nous allons nous éloigner des fonctionnalités du bot, et nous mettrons à instrumenter celui-ci, de manière à pouvoir surveiller son fonctionnement comme il se doit sur tout projet un minimum sérieux.
Ce sera pour nous l’occasion de découvrir la notion de service dans Kubernetes, et d’acquérir quelques bons réflexes sur l’observabilité d’un système.
