Ce billet présente une façon rigolote d’implémenter une arborescence grâce aux nombres premiers. La technique marche mais elle n’a pas été spécialement prévue pour fonctionner sérieusement en production.
Avec une base de données relationnelle il n’est pas toujours possible d’implémenter et de manipuler des données de nature récursive (comme des arbres) aisément. La modélisation à base d’auto-références est possible, mais la manipulation s’en retrouve quelque peu alourdie, d’autant plus quand les CTE récursives ne sont pas supportées.
Ce billet présente un exemple vraisemblable qui fera office de fil conducteur : l’implémentation d’un système de commentaires dans une BDD, et sa manipulation en SQL. Chaque commentaire peut avoir un ou plusieurs enfants, il s’agit des réponses à ce commentaire. Les enfants peuvent à leur tour avoir des réponses, et ainsi de suite. Il apparaît donc des fils (ou threads) de commentaires, à la façon de HN, Lobste.rs ou encore Reddit.
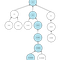
Représentation des nœuds
L’approche est la suivante : chaque commentaire (matérialisé par une ligne, ou row) se passe de référence (au sens SQL) et utilise plutôt un entier qui encode d’un seul coup tous ses ancêtres, pourvu qu’on en fasse la décomposition en facteurs premiers. Ce nombre est désigné par parents.
Voici l’allure possible d’une telle table (simplifiée) :
id | parents | text
---+----------+----------------------------------------
2 | 1 |
3 | 2 | First comment
5 | 2 | Second comment
7 | 2 | Third comment
11 | 10 | First comment on the second comment
13 | 6 | First comment on the first comment
17 | 6 | Second comment on the first comment
19 | 14 | Comment on third comment
23 | 266 | Comment on comment on third comment
29 | 10 | Second comment on the second comment
31 | 290 | Comment on the second comment on the second comment
37 | 8990 | Comment on comment on the second comment on the second comment
41 | 332630 | Second comment on comment on comment on the second comment on the second comment
43 | 13637830 | Comment on second comment on comment on comment on the second comment on the second comment
47 | 332630 | First comment on comment on comment on the second comment on the second comment
Chaque commentaire est désigné par une paire (id, parents) qui suit deux règles :
idest un nombre premier et est attribué de façon unique à chaque commentaire ;parentsest le produit du parent direct du commentaire donné.
Il est maintenant possible de comprendre en quoi parents encode non seulement un parent direct, mais aussi tous les ancêtres d’un commentaire : la décomposition de parents donne en effet la liste de tous les ID des ancêtres. Le contenu de la table est intuitivement représenté par le schéma suivant :

Retrouver les parents
Retrouvons le fil ascendant du commentaire d’ID 47 dont voici la ligne dans la table :
id | parents | text
---+----------+-----------------------------------------------
47 | 332630 | First comment on comment on comment on the...
La décomposition de parents est . Ses parents sont donc les commentaires portant respectivement les ID 2, 5, 29, 31 et 37. La requête suivante permet de les obtenir :
SELECT * FROM comment WHERE id IN (2, 5, 29, 31, 37);
id | parents | text
---+---------+----------------------------------------------------------------
2 | 1 |
5 | 2 | Second comment
29 | 10 | Second comment on the second comment
31 | 290 | Comment on the second comment on the second comment
37 | 8990 | Comment on comment on the second comment on the second comment
Le parcours se représente graphiquement comme cela :

La décomposition en facteurs premiers peut être exécutée dans le code applicatif qui appelle la base de données. Mais il serait bien entendu confortable de définir une fonction SQL pour exécuter une requête telle que : SELECT * FROM comment WHERE id IN PrimeFactors(332630);.
Pour compter le nombre total de commentaire(s) dans le fil, il suffira d’un COUNT.
Retrouver les enfants
Retrouver les enfants directs d’un commentaire désigné par (id, parents) revient à retrouver tous les commentaires de forme (_, parents × id). Les enfants du commentaire d’ID 5, de paire (5, 2), sont ainsi les commentaires qui ont leur colonne parents sur , soit en SQL :
SELECT * from comment WHERE parents = 5 * 2;
id | parents | text
---+---------+--------------------------------------
11 | 10 | First comment on the second comment
29 | 10 | Second comment on the second comment
Il s’agit bien des commentaires d’ID 11 et 29.
Insertion d’un nouveau commentaire
L’insertion d’un nouveau commentaire, vraisemblablement avec un parent connu (fût-il la racine), n’est pas aussi simple.
Les bases de données permettent généralement d’attribuer de nouvels ID générés au fur et à mesure des insertions, sans que l’applicatif appelant n’ait à s’en soucier. La BDD garantit l’unicité de chaque ID et les incrémente correctement, même en cas de deux INSERT concurrents.
Bien entendu, il ne serait pas envisageable qu’il n’en soit pas de même avec notre système d’attribution d’ID premiers. Il faut ruser et trouver une façon.
Voici une proposition d’implémentation : avoir une table de nombres premiers pré-calculés et indexé (ici jusqu’à 100 000 non inclus, ce qui donne 9592 ID à attribuer en tout), lesquels serviront à calculer les futurs ID.
SELECT * FROM primes;
n
----
2
3
5
7
11
13
17
...
99929
99961
99971
99989
99991
(9592 rows)
Avec la table primes, il est possible, en une transaction, de trouver un nouvel ID et de l’attribuer en vue de l’insertion, comme ceci, par exemple :
-- Trouver le prochain en se basant sur l'existant
WITH newid AS (
SELECT n
FROM primes
WHERE n > (SELECT max(id) FROM comment)
LIMIT 1;
) -- Puis l'utiliser dans l'INSERT
INSERT INTO comment
(id, parents, text) VALUES
((SELECT n FROM newid), :parents, :text);
Moins de 10 000 ID possibles, cela peut sembler peu. Mais rappelons que notre table est ici volontairement simpliste pour clarifier le propos principal. Dans une implémentation réelle, il n’y aurait non pas qu’un seul espace de commentaire, mais plutôt un espace de commentaire pour chaque contenu (via clé étrangère sur le contenu commenté, dans la table).
id | parents | content_id | text
---+----------+----------------------------------------
2 | 1 | |
3 | 2 | 42 | ...
5 | 2 | 42 | ...
3 | 2 | 69 | ...
L’identifiant de référence ne serait alors plus juste id mais plutôt le couple (id, content_id), qu’il est possible d’indexer et de mettre sous contrainte UNIQUE avec une BDD sérieuse. Chaque contenu aurait ainsi une capacité de 9592 commentaires maximum dans son espace commentaire, ce qui semble raisonnable.
Remarques
Comme vu, cette approche simplifie grandement certaines manipulations, mais elle n’est pas exempte de quelques complications en retour.
Il convient aussi de mettre en garde quant à une autre faiblesse de l’approche : la cohérence structurelle n’est plus garantie, puisque les références gérées ne sont pas exploitées.
Enfin, même si le parcours ascendant sur tous les ancêtres est possible en une seule requête simple, on remarque que le parcours descendant, lui, n’offre pas un tel luxe. Seuls les enfants directs sont accessibles simplement (mais ils le sont tous, en une seule requête).
L’approche présentée a surtout le mérite d’être amusante.
Référence
Serhiy Morozov, Hossein Saiedian and Hanzhang Wang (Janvier 2014). Reusable Prime Number Labeling Scheme for Hierarchical Data Representation in Relational Database. Journal of Computing and Information Technology. p.3, sect. 2. (DOI: 10.2498/cit.1002310)
(le papier est librement téléchargeable sur le site du journal)


