
- Des arbres avec SQL et les nombres premiers
- Comment est-ce qu’on codait un jeu vidéo au milieu des années 90 ?
Comment sont structurés les fichiers PNG ? Je me suis posé cette question et ai voulu y répondre en écrivant un fichier PNG (presque) entièrement à la main !
Écrire un fichier PNG valide à la main, c’est plus facile avec le mode d’emploi. Le format PNG est très bien documenté : il fait l’objet d’un standard ISO, également disponible publiquement sur le site du W3C.
Avec des notions de bases sur les octets, bits, notation binaires et hexadécimales, cette spécification est la seule chose (avec un peu de patience) dont on a besoin pour écrire un fichier PNG à la main. Tout ce qui est mentionné ici peut être vérifié en recherchant l’information dans la spécification. C’est parti !
- Structure générale
- Le chunk le plus facile : IEND
- Un peu moins simple : le chunk IHDR
- Plus compliqué : le chunk IDAT
- Le fichier complet
Structure générale
Structure du fichier
Structure
La structure des fichiers PNG est plutôt simple. La spécification décrit un fichier PNG comme étant composé de ce qu’on appelle la signature PNG, suivie d’une suite de chunks (terme que je ne traduirais pas). Un fichier est donc de la forme suivante :
[signature][chunk][chunk]...[chunk]
Signature PNG
La signature d’un fichier PNG est une simple suite constante de huit octets : 0x89 0x50 0x4E 0x47 0x0D 0x0A 0x1A 0x0A.
Ces caractères ne sont pas choisis par hasard, mais pour des raisons technico-historiques. Ils permettent d’identifier le type de fichier de manière aussi univoque que possible, tout en favorisant la détection de certains types d’erreurs de transmission communes et éviter des soucis de manipulation par certains programmes. Il y a un mélange délibéré d’octets non-ASCI et ASCII, qui fait apparaître notamment la séquence de caractères « PNG », visible en un coup d’œil avec un éditeur de texte (faites le test chez vous !).
Pour en savoir plus sur la raison de ce choix précis, consultez la section 12.12 de ce document justifiant les choix de conception du format.
Chunks
Tout le reste du fichier après la signature est une série de chunks. Pour un fichier minimal, on peut se contenter de trois chunks :
- d’abord un chunk IHDR (pour image header), qui contient des informations sur la taille de l’image, son mode de couleurs, le nombre de bits par sample et les paramètres de l’algorithme utilisés pour l’encodage ;
- ensuite, un chunk IDAT (pour image data), qui contient les données concernant les pixels ;
- enfin, un chunk IEND (pour image end), qui marque la fin du fichier.
Comme nous souhaitons être minimaliste, notre fichier aura précisément cette structure :
[signature][chunk IHDR][chunk IDAT][chunk IEND]
Structure des chunks
Un chunk quelconque a la structure suivante :
- d’abord, un champ de 4 octets indiquant la longueur du champ de données (ci-après) ;
- ensuite, un champ de 4 octets indiquant le type du chunk ;
- puis le champ de données, dont la structure dépend du type ;
- enfin un CRC portant sur la concaténation du champ de type et de celui de données et servant à la vérification d’intégrité.
Le champ de données peut être omis dans le cas où la longueur est zéro : on a alors que trois champs.
Dans le cas normal, on a ainsi :
[LENGTH (4 octets)][CHUNK TYPE (4 octets)][CHUNK DATA (LENGTH octets)][CRC 4 octets]
Et dans le cas où la longueur est nulle :
[LENGTH (4 octets)][CHUNK TYPE (4 octets)][CRC 4 octets]
Le chunk le plus facile : IEND
On commence par la fin, parce que le chunk le plus facile à écrire est le chunk de type IEND. S’il est si simple, c’est qu’il n’a pas de données du tout ! Il est donc composé seulement de sa longueur sur quatre octets, de quatre octets pour son type et de la somme de contrôle sur 4 octets.
Champ LENGTH
La longueur est nulle, on a donc les quatre octets suivants pour le champ LENGTH : 0x00 0x00 0x00 0x00.
Champ TYPE
Les quatre octets du champ type (imposés par la spécification) consistent en la chaîne « IEND » encodée en ASCII : 0x49 0x45 0x4E 0x44.
Champ CRC
Le champ CRC est calculé avec l’algorithme CRC-32 paramétré comme indiqué dans la spécification PNG. Une manière de faire le calcul est d’utiliser Python, dont le module zlib implémente ce calcul avec la fonction crc32.1 Alternativement, la spécification propose une implémentation de référence en C. J’ai opté pour la solution avec Python, et on trouve que la somme de contrôle doit valoir : 0xAE 0x42 0x60 0x82.
Résumé
En assemblant les champs LENGTH, TYPE et CRC, on a la suite d’octets qui compose le dernier chunk du fichier :
0x00 0x00 0x00 0x00 0x49 0x45 0x4E 0x44 0xAE 0x42 0x60 0x82
- En une ligne, après avoir importé la fonction
crc32depuis le modulezlib:{:08x}".format(crc32(b"\x49\x45\x4e\x44")).↩
Un peu moins simple : le chunk IHDR
Champ LENGTH
Le champ IHDR a un champ de données, dont il faut indiquer la longueur. Pour ce type de champ, la longueur du champ de donnée est fixée à 13 octets. Le champ LENGTH sera donc constitué des quatre octets suivants : 0x00 0x00 0x00 0x0D.
Champ CHUNK TYPE
Encore une fois, le type est simplement les quatre octets ASCII encodant la chaîne correspondant au type, c’est-à-dire « IHDR ». On aura donc pour le champ CHUNK TYPE les octets suivants : 0x49 0x48 0x44 0x52.
Champ CHUNK DATA
Pour un fichier minimaliste, le plus petit qu’on puisse avoir est 1x1 pixel (0 pixel est interdit). Ensuite, le mode de couleur le plus simple est celui en niveau de gris avec 8 bits par pixels, où il n’y a pas besoin de gérer les différents canaux de couleur et chaque octet représente un pixel. Ces informations suffisent pour remplir le champ CHUNK DATA.
Le champ CHUNK DATA est formé de la suite d’octets suivante (qui fait bien 13 octets) :
- la largeur de l’image sur 4 octets, ce qui donne :
0x00 0x00 0x00 0x01; - la hauteur de l’image sur 4 octets, ce qui donne :
0x00 0x00 0x00 0x01; - la profondeur de bits sur 1 octet, on a choisi 8 bits par pixels :
0x08; - le type de couleur sur 1 octet ; pour le niveau de gris, il faut indiquer
0x00; - la méthode de compression1 sur 1 octet ; pas le choix ici :
0x00; - la méthode de filtrage2 sur 1 octet ; pas le choix encore :
0x00; - enfin la méthode d’entrelaçage3 sur 1 octet ; pour indiquer qu’on n’entrelace pas :
0x00.
Champ CRC
Enfin, on calcule le CRC sur la concaténation des champs CHUNK TYPE et CHUNK DATA 4 et on obtient : 0x3A 0x7E 0x9B 0x55.
Résumé
En résumé, ce chunk est composé de la suite d’octets suivantes :
0x00 0x00 0x00 0x0D 0x49 0x48 0x44 0x52 0x00 0x00 0x00 0x01 0x00 0x00 0x00 0x01 0x08 0x00 0x00 0x00 0x00 0x3A 0x7E 0x9B 0x55
- La méthode de compression est deflate, même si dans ce billet, le fichier produit esquive la compression en utilisant la possibilité d’avoir des données littérales.↩
- PNG permet de filtrer (réversiblement) les données des pixels avant la compression. Cela permet d’améliorer la compression pour certaines images.↩
- L’entrelaçage est une technique permettant un affichage progressif de l’image lors de son chargement, et assez peu utile dans le monde moderne. Encore plus inutile quand l’image ne comporte qu’un seul pixel.↩
- De manière similaire au chunk précédent.↩
Plus compliqué : le chunk IDAT
Le champ IDAT de notre image a pour noble rôle de décrire l’unique pixel de notre image.
Champ LENGTH
Il n’est pas possible à ce stade de déterminer la longueur du champ CHUNK DATA. Mais comme j’écris depuis le futur, j’en annonce dors et déjà la longueur : 13 octets. On aura les 4 octets suivants comme premiers octets du chunk : 0x00 0x00 0x00 0x0D.
Champ CHUNK TYPE
Comme toujours, le champ CHUNK TYPE est l’encodage en ASCII du nom du type, à savoir « IDAT » : 0x49 0x44 0x41 0x54.
Champ CHUNK DATA
Données à compresser
Le champ CHUNK DATA est constitué du résultat de la compression des données décrivant l’image. Le format PNG structure les pixels en scanline. Nous en avons qu’une seule, ayant un unique pixel. Chaque scanline est précédée d’un octet indiquant un paramètre pour la méthode de filtrage. Je choisis de faire un pixel blanc (0xFF dans notre encodage avec une profondeur de 8 bits par pixel) et d’utiliser le type de filtrage "pas de filtrage", encodé sur un octet par 0x00. La séquence qu’on doit comprimer est alors : 0x00 0xFF.
Données comprimées au format « zlib »
Le format des données comprimées sont décrites dans la spécification du format zlib. Il y a un certain nombre de paramètres à stocker dont le détail est laborieux, mais conceptuellement simple.
Une structure « zlib » a la forme suivante :
+---+---+=====================+---+---+---+---+
|CMF|FLG|...compressed data...| ADLER32 |
+---+---+=====================+---+---+---+---+
Autrement dit, on a un octet CMF, un octet FLG, des données compressées et 4 octets pour un code ADLER32. Détaillons tout cela.
CMF et FLG
La structure commence par :
- l’octet CMF qui contient des infos sur la méthode de compression ;
- l’octet FLG qui contient des données supplémentaires.
Ces deux octets sont eux-mêmes constitués de champs de bits (détaillées dans la spécification). Pour CMF :
- les 4 bits les plus à gauche sont la largeur de la fenêtre utilisée pour la compression : on ne s’en sert pas, mettons zéro :
0b0000; - les 4 bits les plus à droite sont la méthode de compression (valant obligatoirement 8 pour PNG) :
0b1000;
Pour FLG :
- les deux bits les plus à gauche indique le niveau de compression : on ne s’en sert pas, mettons zéro :
0b00 - le bit suivant indique la présence d’un dictionnaire : on ne s’en sert pas, mise à zéro :
0b0.- le dernier champ de 5 bits est un champ de contrôle dont la valeur doit permettre à la concaténation de CMF et FLG vue comme un entier 16 bits d’être un multiple de 31 ; en faisant le travail à la calculatrice, on trouve que la bonne valeur est
0b11101(le nombre sur 16 bits est alors 2077, un multiple de 31).
- le dernier champ de 5 bits est un champ de contrôle dont la valeur doit permettre à la concaténation de CMF et FLG vue comme un entier 16 bits d’être un multiple de 31 ; en faisant le travail à la calculatrice, on trouve que la bonne valeur est
On concatène tout ça, les deux octets CMF et FLG sont donc : 0x08 0x1D.
Données "compressées"
Après cet en-tête, il faut encoder les données selon l'algorithme deflate. Cet algorithme prévoit des segments de données littérales, ce qui simplifie bien la vie.
Le format deflate fonctionne par bloc. On aura qu’un seul bloc, qui commence par l’en-tête suivant sur un octet :
- le bit le plus à droite à 1 pour indiquer qu’il s’agit du dernier bloc (il n’y a qu’un, c’est nécessairement le dernier) ;
- les deux bits suivants à 0 pour indiquer qu’il s’agit de données non comprimées ;
- les bits suivants peuvent être laissés à zéro, ils ne sont pas utilisés dans notre cas.
L’octet vaut donc : 0x01.
L’en-tête est suivi par le corps du bloc de la forme suivante :
0 1 2 3 4...
+---+---+---+---+================================+
| LEN | NLEN |... LEN bytes of literal data...|
+---+---+---+---+================================+
On aura juste deux octets de données littérales, à savoir 0x00 0xFF (les données à "comprimer"), comme indiqué avant.
Cette information nous permet de remplir les deux premiers champs :
- LEN : la longueur des données sur deux octets, et qui doit valoir 2 ;
- NLEN : le complément à 1 de LEN.
Ces deux champs sont codés sur deux octets, mais avec l’octet de poids faible en premier. Autrement dit, pour coder 2, on ne doit pas inscrire 0x00 0x02, mais 0x02 0x00, qui sera notre champ LEN.
En binaire, cela correspond à Ob00000010 0b00000000. Le complément à 1 de ce nombre est alors 0b11111101 0b11111111, ou en hexadécimal : 0xFD 0xFF, qui sera notre champ NLEN.
Pour résumé, on a donc notre bloc de données deflate, formé de la concaténation de l’en-tête, de LEN, NLEN et les deux octets de données littérales : 0x01 0x02 0x00 0xFD 0xFF 0x00 0xFF.
Code ADLER32
Pour compléter notre structure zlib, il faut calculer un code ADLER32, qui permet de vérifier la bonne décompression des données. Il se calcule sur les données non-compressées et il est possible de le calculer avec le module zlib de Python1 (ou alternativement avec l’implémentation de référence donnée dans la spécification de zlib). On obtient : 0x01 0x01 0x01 0x00.
On peut recoller tous nos octets pour obtenir le champ CHUNK DATA : 0x08 0x1D 0x01 0x02 0x00 0xFD 0xFF 0x00 0xFF 0x01 0x01 0x01 0x00.
CRC32
Enfin, on concatène le type et les données pour obtenir le CRC du chunk. C’est similaire à la fois d’avant. On obtient le CRC : 0xD3 0x61 0xCE 0x4C.
Résumé
On peut recoller tous les morceaux pour ce chunk :
0x00 0x00 0x00 0x0D 0x49 0x44 0x41 0x54 0x08 0x1D 0x01 0x02 0x00 0xFD 0xFF 0x00 0xFF 0x01 0x01 0x01 0x00 0xD3 0x61 0xCE 0x4C
- One-liner après avoir importé
zlib:{:08x}".format(zlib.adler32(b"\x00\xff")).↩
Le fichier complet
On peut désormais recoller la signature et les chunks dans l’ordre pour obtenir le fichier complet. Sur chaque ligne, ce qui précède # est un commentaire pour faciliter la lecture de l’assemblage.
signature # 0x89 0x50 0x4E 0x47 0x0D 0x0A 0x1A 0x0A
IHDR # 0x00 0x00 0x00 0x0D 0x49 0x48 0x44 0x52 0x00 0x00 0x00 0x01 0x00 0x00 0x00 0x01 0x08 0x00 0x00 0x00 0x00 0x3A 0x7A 0x9B 0x55
IDAT # 0x00 0x00 0x00 0x0D 0x49 0x44 0x41 0x54 0x08 0x1D 0x01 0x02 0x00 0xFD 0xFF 0x00 0xFF 0x01 0x01 0x01 0x00 0xD3 0x61 0xCE 0x4C
IEND # 0x00 0x00 0x00 0x00 0x49 0x45 0x4E 0x44 0xAE 0x42 0x60 0x82
Pour tester la justesse de tout ça, rien de mieux qu’écrire le fichier ! N’importe quel éditeur hexadécimal avec les bonnes fonctionnalités fait l’affaire. Je n’en avais pas avant d’écrire ce billet et après avoir rapidement testé différents éditeurs, j’ai jeté mon dévolu sur Okteta.
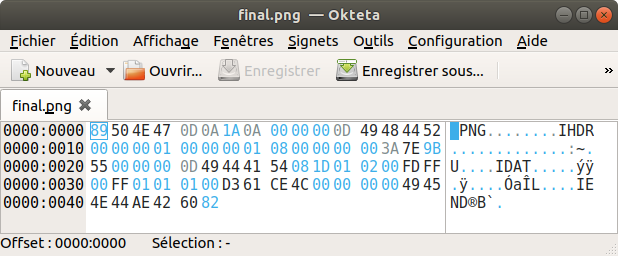
Le fichier fonctionne correctement avec GIMP et ma visionneuse d’image habituelle, arborant fièrement son unique pixel blanc !
L’import d’image du site laisse le fichier intact, vous pouvez donc en profiter directement dans votre navigateur.
Références
- La spécification officielle du format PNG sur le site du W3C.
- Une page intéressante justifiant certains choix de conception.
- La spécification du format zlib, utilisée par le format PNG.
- La spécification de l’algorithme deflate utilisé par zlib (et donc PNG).




{kind=link}