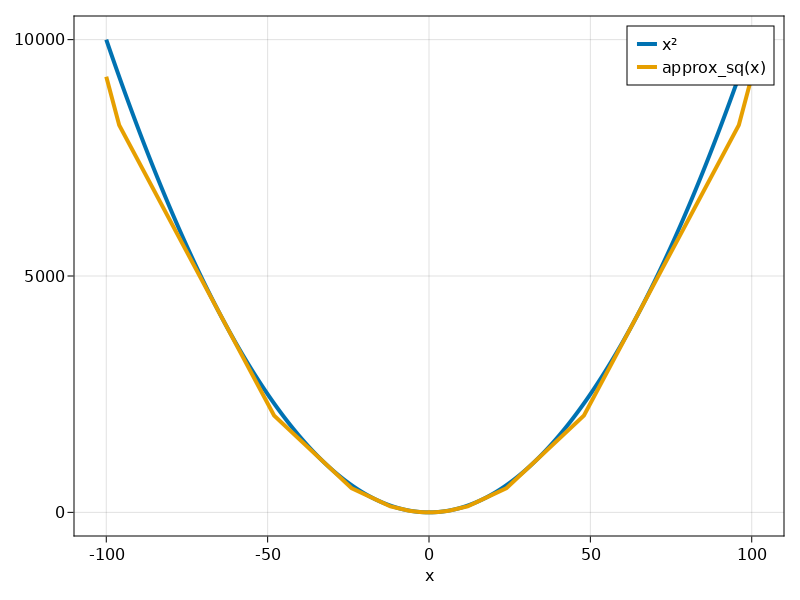
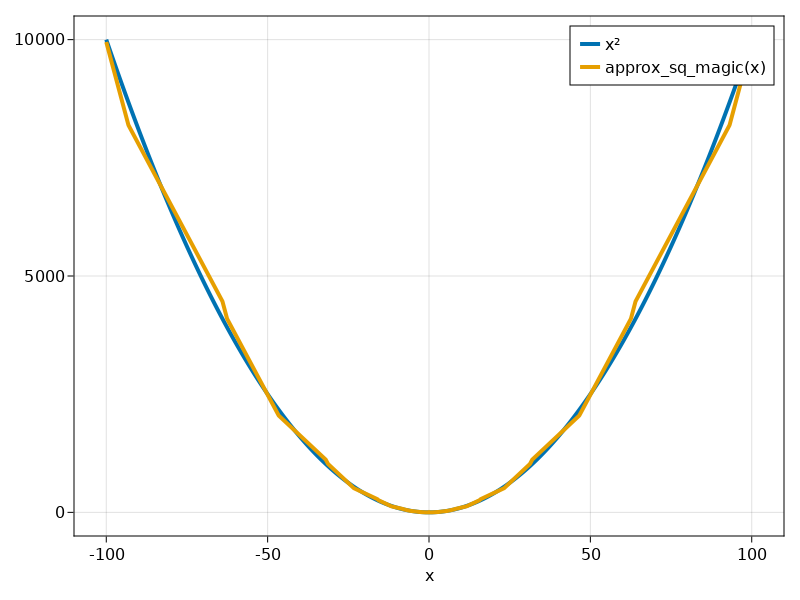
build/TestSquare.ino.elf: file format elf32-avr
Disassembly of section .text:
00000000 <__vectors>:
0: 0c 94 35 00 jmp 0x6a ; 0x6a <__ctors_end>
4: 0c 94 5d 00 jmp 0xba ; 0xba <__bad_interrupt>
8: 0c 94 5d 00 jmp 0xba ; 0xba <__bad_interrupt>
c: 0c 94 5d 00 jmp 0xba ; 0xba <__bad_interrupt>
10: 0c 94 5d 00 jmp 0xba ; 0xba <__bad_interrupt>
14: 0c 94 5d 00 jmp 0xba ; 0xba <__bad_interrupt>
18: 0c 94 5d 00 jmp 0xba ; 0xba <__bad_interrupt>
1c: 0c 94 5d 00 jmp 0xba ; 0xba <__bad_interrupt>
20: 0c 94 5d 00 jmp 0xba ; 0xba <__bad_interrupt>
24: 0c 94 5d 00 jmp 0xba ; 0xba <__bad_interrupt>
28: 0c 94 5d 00 jmp 0xba ; 0xba <__bad_interrupt>
2c: 0c 94 5d 00 jmp 0xba ; 0xba <__bad_interrupt>
30: 0c 94 5d 00 jmp 0xba ; 0xba <__bad_interrupt>
34: 0c 94 5d 00 jmp 0xba ; 0xba <__bad_interrupt>
38: 0c 94 5d 00 jmp 0xba ; 0xba <__bad_interrupt>
3c: 0c 94 5d 00 jmp 0xba ; 0xba <__bad_interrupt>
40: 0c 94 48 02 jmp 0x490 ; 0x490 <__vector_16>
44: 0c 94 5d 00 jmp 0xba ; 0xba <__bad_interrupt>
48: 0c 94 16 02 jmp 0x42c ; 0x42c <__vector_18>
4c: 0c 94 f0 01 jmp 0x3e0 ; 0x3e0 <__vector_19>
50: 0c 94 5d 00 jmp 0xba ; 0xba <__bad_interrupt>
54: 0c 94 5d 00 jmp 0xba ; 0xba <__bad_interrupt>
58: 0c 94 5d 00 jmp 0xba ; 0xba <__bad_interrupt>
5c: 0c 94 5d 00 jmp 0xba ; 0xba <__bad_interrupt>
60: 0c 94 5d 00 jmp 0xba ; 0xba <__bad_interrupt>
64: 0c 94 5d 00 jmp 0xba ; 0xba <__bad_interrupt>
00000068 <__ctors_start>:
68: 9b 03 fmulsu r17, r19
0000006a <__ctors_end>:
6a: 11 24 eor r1, r1
6c: 1f be out 0x3f, r1 ; 63
6e: cf ef ldi r28, 0xFF ; 255
70: d8 e0 ldi r29, 0x08 ; 8
72: de bf out 0x3e, r29 ; 62
74: cd bf out 0x3d, r28 ; 61
00000076 <__do_copy_data>:
76: 11 e0 ldi r17, 0x01 ; 1
78: a0 e0 ldi r26, 0x00 ; 0
7a: b1 e0 ldi r27, 0x01 ; 1
7c: e0 e6 ldi r30, 0x60 ; 96
7e: f9 e0 ldi r31, 0x09 ; 9
80: 02 c0 rjmp .+4 ; 0x86 <__do_copy_data+0x10>
82: 05 90 lpm r0, Z+
84: 0d 92 st X+, r0
86: a0 34 cpi r26, 0x40 ; 64
88: b1 07 cpc r27, r17
8a: d9 f7 brne .-10 ; 0x82 <__do_copy_data+0xc>
0000008c <__do_clear_bss>:
8c: 21 e0 ldi r18, 0x01 ; 1
8e: a0 e4 ldi r26, 0x40 ; 64
90: b1 e0 ldi r27, 0x01 ; 1
92: 01 c0 rjmp .+2 ; 0x96 <.do_clear_bss_start>
00000094 <.do_clear_bss_loop>:
94: 1d 92 st X+, r1
00000096 <.do_clear_bss_start>:
96: a0 3f cpi r26, 0xF0 ; 240
98: b2 07 cpc r27, r18
9a: e1 f7 brne .-8 ; 0x94 <.do_clear_bss_loop>
0000009c <__do_global_ctors>:
9c: 10 e0 ldi r17, 0x00 ; 0
9e: c5 e3 ldi r28, 0x35 ; 53
a0: d0 e0 ldi r29, 0x00 ; 0
a2: 04 c0 rjmp .+8 ; 0xac <__do_global_ctors+0x10>
a4: 21 97 sbiw r28, 0x01 ; 1
a6: fe 01 movw r30, r28
a8: 0e 94 a8 04 call 0x950 ; 0x950 <__tablejump2__>
ac: c4 33 cpi r28, 0x34 ; 52
ae: d1 07 cpc r29, r17
b0: c9 f7 brne .-14 ; 0xa4 <__do_global_ctors+0x8>
b2: 0e 94 92 02 call 0x524 ; 0x524 <main>
b6: 0c 94 ae 04 jmp 0x95c ; 0x95c <_exit>
000000ba <__bad_interrupt>:
ba: 0c 94 00 00 jmp 0 ; 0x0 <__vectors>
000000be <Print::write(unsigned char const*, unsigned int)>:
be: af 92 push r10
c0: bf 92 push r11
c2: cf 92 push r12
c4: df 92 push r13
c6: ef 92 push r14
c8: ff 92 push r15
ca: 0f 93 push r16
cc: 1f 93 push r17
ce: cf 93 push r28
d0: df 93 push r29
d2: 6c 01 movw r12, r24
d4: 7b 01 movw r14, r22
d6: 8b 01 movw r16, r22
d8: 04 0f add r16, r20
da: 15 1f adc r17, r21
dc: eb 01 movw r28, r22
de: 5e 01 movw r10, r28
e0: ae 18 sub r10, r14
e2: bf 08 sbc r11, r15
e4: c0 17 cp r28, r16
e6: d1 07 cpc r29, r17
e8: 59 f0 breq .+22 ; 0x100 <Print::write(unsigned char const*, unsigned int)+0x42>
ea: 69 91 ld r22, Y+
ec: d6 01 movw r26, r12
ee: ed 91 ld r30, X+
f0: fc 91 ld r31, X
f2: 01 90 ld r0, Z+
f4: f0 81 ld r31, Z
f6: e0 2d mov r30, r0
f8: c6 01 movw r24, r12
fa: 09 95 icall
fc: 89 2b or r24, r25
fe: 79 f7 brne .-34 ; 0xde <Print::write(unsigned char const*, unsigned int)+0x20>
100: c5 01 movw r24, r10
102: df 91 pop r29
104: cf 91 pop r28
106: 1f 91 pop r17
108: 0f 91 pop r16
10a: ff 90 pop r15
10c: ef 90 pop r14
10e: df 90 pop r13
110: cf 90 pop r12
112: bf 90 pop r11
114: af 90 pop r10
116: 08 95 ret
00000118 <HardwareSerial::availableForWrite()>:
118: fc 01 movw r30, r24
11a: 53 8d ldd r21, Z+27 ; 0x1b
11c: 44 8d ldd r20, Z+28 ; 0x1c
11e: 25 2f mov r18, r21
120: 30 e0 ldi r19, 0x00 ; 0
122: 84 2f mov r24, r20
124: 90 e0 ldi r25, 0x00 ; 0
126: 82 1b sub r24, r18
128: 93 0b sbc r25, r19
12a: 54 17 cp r21, r20
12c: 10 f0 brcs .+4 ; 0x132 <HardwareSerial::availableForWrite()+0x1a>
12e: cf 96 adiw r24, 0x3f ; 63
130: 08 95 ret
132: 01 97 sbiw r24, 0x01 ; 1
134: 08 95 ret
00000136 <HardwareSerial::read()>:
136: fc 01 movw r30, r24
138: 91 8d ldd r25, Z+25 ; 0x19
13a: 82 8d ldd r24, Z+26 ; 0x1a
13c: 98 17 cp r25, r24
13e: 61 f0 breq .+24 ; 0x158 <HardwareSerial::read()+0x22>
140: a2 8d ldd r26, Z+26 ; 0x1a
142: ae 0f add r26, r30
144: bf 2f mov r27, r31
146: b1 1d adc r27, r1
148: 5d 96 adiw r26, 0x1d ; 29
14a: 8c 91 ld r24, X
14c: 92 8d ldd r25, Z+26 ; 0x1a
14e: 9f 5f subi r25, 0xFF ; 255
150: 9f 73 andi r25, 0x3F ; 63
152: 92 8f std Z+26, r25 ; 0x1a
154: 90 e0 ldi r25, 0x00 ; 0
156: 08 95 ret
158: 8f ef ldi r24, 0xFF ; 255
15a: 9f ef ldi r25, 0xFF ; 255
15c: 08 95 ret
0000015e <HardwareSerial::peek()>:
15e: fc 01 movw r30, r24
160: 91 8d ldd r25, Z+25 ; 0x19
162: 82 8d ldd r24, Z+26 ; 0x1a
164: 98 17 cp r25, r24
166: 31 f0 breq .+12 ; 0x174 <HardwareSerial::peek()+0x16>
168: 82 8d ldd r24, Z+26 ; 0x1a
16a: e8 0f add r30, r24
16c: f1 1d adc r31, r1
16e: 85 8d ldd r24, Z+29 ; 0x1d
170: 90 e0 ldi r25, 0x00 ; 0
172: 08 95 ret
174: 8f ef ldi r24, 0xFF ; 255
176: 9f ef ldi r25, 0xFF ; 255
178: 08 95 ret
0000017a <HardwareSerial::available()>:
17a: fc 01 movw r30, r24
17c: 91 8d ldd r25, Z+25 ; 0x19
17e: 22 8d ldd r18, Z+26 ; 0x1a
180: 89 2f mov r24, r25
182: 90 e0 ldi r25, 0x00 ; 0
184: 80 5c subi r24, 0xC0 ; 192
186: 9f 4f sbci r25, 0xFF ; 255
188: 82 1b sub r24, r18
18a: 91 09 sbc r25, r1
18c: 8f 73 andi r24, 0x3F ; 63
18e: 99 27 eor r25, r25
190: 08 95 ret
00000192 <Serial0_available()>:
192: 83 e5 ldi r24, 0x53 ; 83
194: 91 e0 ldi r25, 0x01 ; 1
196: 0e 94 bd 00 call 0x17a ; 0x17a <HardwareSerial::available()>
19a: 21 e0 ldi r18, 0x01 ; 1
19c: 89 2b or r24, r25
19e: 09 f4 brne .+2 ; 0x1a2 <Serial0_available()+0x10>
1a0: 20 e0 ldi r18, 0x00 ; 0
1a2: 82 2f mov r24, r18
1a4: 08 95 ret
000001a6 <serialEventRun()>:
1a6: 80 e0 ldi r24, 0x00 ; 0
1a8: 90 e0 ldi r25, 0x00 ; 0
1aa: 89 2b or r24, r25
1ac: 29 f0 breq .+10 ; 0x1b8 <serialEventRun()+0x12>
1ae: 0e 94 c9 00 call 0x192 ; 0x192 <Serial0_available()>
1b2: 81 11 cpse r24, r1
1b4: 0c 94 00 00 jmp 0 ; 0x0 <__vectors>
1b8: 08 95 ret
000001ba <HardwareSerial::_tx_udr_empty_irq()>:
1ba: fc 01 movw r30, r24
1bc: a4 8d ldd r26, Z+28 ; 0x1c
1be: a8 0f add r26, r24
1c0: b9 2f mov r27, r25
1c2: b1 1d adc r27, r1
1c4: a3 5a subi r26, 0xA3 ; 163
1c6: bf 4f sbci r27, 0xFF ; 255
1c8: 2c 91 ld r18, X
1ca: 84 8d ldd r24, Z+28 ; 0x1c
1cc: 90 e0 ldi r25, 0x00 ; 0
1ce: 01 96 adiw r24, 0x01 ; 1
1d0: 8f 73 andi r24, 0x3F ; 63
1d2: 99 27 eor r25, r25
1d4: 84 8f std Z+28, r24 ; 0x1c
1d6: a6 89 ldd r26, Z+22 ; 0x16
1d8: b7 89 ldd r27, Z+23 ; 0x17
1da: 2c 93 st X, r18
1dc: a0 89 ldd r26, Z+16 ; 0x10
1de: b1 89 ldd r27, Z+17 ; 0x11
1e0: 8c 91 ld r24, X
1e2: 83 70 andi r24, 0x03 ; 3
1e4: 80 64 ori r24, 0x40 ; 64
1e6: 8c 93 st X, r24
1e8: 93 8d ldd r25, Z+27 ; 0x1b
1ea: 84 8d ldd r24, Z+28 ; 0x1c
1ec: 98 13 cpse r25, r24
1ee: 06 c0 rjmp .+12 ; 0x1fc <HardwareSerial::_tx_udr_empty_irq()+0x42>
1f0: 02 88 ldd r0, Z+18 ; 0x12
1f2: f3 89 ldd r31, Z+19 ; 0x13
1f4: e0 2d mov r30, r0
1f6: 80 81 ld r24, Z
1f8: 8f 7d andi r24, 0xDF ; 223
1fa: 80 83 st Z, r24
1fc: 08 95 ret
000001fe <HardwareSerial::write(unsigned char)>:
1fe: ef 92 push r14
200: ff 92 push r15
202: 0f 93 push r16
204: 1f 93 push r17
206: cf 93 push r28
208: df 93 push r29
20a: ec 01 movw r28, r24
20c: 81 e0 ldi r24, 0x01 ; 1
20e: 88 8f std Y+24, r24 ; 0x18
210: 9b 8d ldd r25, Y+27 ; 0x1b
212: 8c 8d ldd r24, Y+28 ; 0x1c
214: 98 13 cpse r25, r24
216: 1a c0 rjmp .+52 ; 0x24c <HardwareSerial::write(unsigned char)+0x4e>
218: e8 89 ldd r30, Y+16 ; 0x10
21a: f9 89 ldd r31, Y+17 ; 0x11
21c: 80 81 ld r24, Z
21e: 85 ff sbrs r24, 5
220: 15 c0 rjmp .+42 ; 0x24c <HardwareSerial::write(unsigned char)+0x4e>
222: 9f b7 in r25, 0x3f ; 63
224: f8 94 cli
226: ee 89 ldd r30, Y+22 ; 0x16
228: ff 89 ldd r31, Y+23 ; 0x17
22a: 60 83 st Z, r22
22c: e8 89 ldd r30, Y+16 ; 0x10
22e: f9 89 ldd r31, Y+17 ; 0x11
230: 80 81 ld r24, Z
232: 83 70 andi r24, 0x03 ; 3
234: 80 64 ori r24, 0x40 ; 64
236: 80 83 st Z, r24
238: 9f bf out 0x3f, r25 ; 63
23a: 81 e0 ldi r24, 0x01 ; 1
23c: 90 e0 ldi r25, 0x00 ; 0
23e: df 91 pop r29
240: cf 91 pop r28
242: 1f 91 pop r17
244: 0f 91 pop r16
246: ff 90 pop r15
248: ef 90 pop r14
24a: 08 95 ret
24c: f6 2e mov r15, r22
24e: 0b 8d ldd r16, Y+27 ; 0x1b
250: 10 e0 ldi r17, 0x00 ; 0
252: 0f 5f subi r16, 0xFF ; 255
254: 1f 4f sbci r17, 0xFF ; 255
256: 0f 73 andi r16, 0x3F ; 63
258: 11 27 eor r17, r17
25a: e0 2e mov r14, r16
25c: 8c 8d ldd r24, Y+28 ; 0x1c
25e: 8e 11 cpse r24, r14
260: 0c c0 rjmp .+24 ; 0x27a <HardwareSerial::write(unsigned char)+0x7c>
262: 0f b6 in r0, 0x3f ; 63
264: 07 fc sbrc r0, 7
266: fa cf rjmp .-12 ; 0x25c <HardwareSerial::write(unsigned char)+0x5e>
268: e8 89 ldd r30, Y+16 ; 0x10
26a: f9 89 ldd r31, Y+17 ; 0x11
26c: 80 81 ld r24, Z
26e: 85 ff sbrs r24, 5
270: f5 cf rjmp .-22 ; 0x25c <HardwareSerial::write(unsigned char)+0x5e>
272: ce 01 movw r24, r28
274: 0e 94 dd 00 call 0x1ba ; 0x1ba <HardwareSerial::_tx_udr_empty_irq()>
278: f1 cf rjmp .-30 ; 0x25c <HardwareSerial::write(unsigned char)+0x5e>
27a: eb 8d ldd r30, Y+27 ; 0x1b
27c: ec 0f add r30, r28
27e: fd 2f mov r31, r29
280: f1 1d adc r31, r1
282: e3 5a subi r30, 0xA3 ; 163
284: ff 4f sbci r31, 0xFF ; 255
286: f0 82 st Z, r15
288: 9f b7 in r25, 0x3f ; 63
28a: f8 94 cli
28c: 0b 8f std Y+27, r16 ; 0x1b
28e: ea 89 ldd r30, Y+18 ; 0x12
290: fb 89 ldd r31, Y+19 ; 0x13
292: 80 81 ld r24, Z
294: 80 62 ori r24, 0x20 ; 32
296: cf cf rjmp .-98 ; 0x236 <HardwareSerial::write(unsigned char)+0x38>
00000298 <HardwareSerial::flush()>:
298: cf 93 push r28
29a: df 93 push r29
29c: ec 01 movw r28, r24
29e: 88 8d ldd r24, Y+24 ; 0x18
2a0: 88 23 and r24, r24
2a2: b9 f0 breq .+46 ; 0x2d2 <HardwareSerial::flush()+0x3a>
2a4: aa 89 ldd r26, Y+18 ; 0x12
2a6: bb 89 ldd r27, Y+19 ; 0x13
2a8: e8 89 ldd r30, Y+16 ; 0x10
2aa: f9 89 ldd r31, Y+17 ; 0x11
2ac: 8c 91 ld r24, X
2ae: 85 fd sbrc r24, 5
2b0: 03 c0 rjmp .+6 ; 0x2b8 <HardwareSerial::flush()+0x20>
2b2: 80 81 ld r24, Z
2b4: 86 fd sbrc r24, 6
2b6: 0d c0 rjmp .+26 ; 0x2d2 <HardwareSerial::flush()+0x3a>
2b8: 0f b6 in r0, 0x3f ; 63
2ba: 07 fc sbrc r0, 7
2bc: f7 cf rjmp .-18 ; 0x2ac <HardwareSerial::flush()+0x14>
2be: 8c 91 ld r24, X
2c0: 85 ff sbrs r24, 5
2c2: f2 cf rjmp .-28 ; 0x2a8 <HardwareSerial::flush()+0x10>
2c4: 80 81 ld r24, Z
2c6: 85 ff sbrs r24, 5
2c8: ed cf rjmp .-38 ; 0x2a4 <HardwareSerial::flush()+0xc>
2ca: ce 01 movw r24, r28
2cc: 0e 94 dd 00 call 0x1ba ; 0x1ba <HardwareSerial::_tx_udr_empty_irq()>
2d0: e9 cf rjmp .-46 ; 0x2a4 <HardwareSerial::flush()+0xc>
2d2: df 91 pop r29
2d4: cf 91 pop r28
2d6: 08 95 ret
000002d8 <micros>:
2d8: 3f b7 in r19, 0x3f ; 63
2da: f8 94 cli
2dc: 80 91 45 01 lds r24, 0x0145 ; 0x800145 <timer0_overflow_count>
2e0: 90 91 46 01 lds r25, 0x0146 ; 0x800146 <timer0_overflow_count+0x1>
2e4: a0 91 47 01 lds r26, 0x0147 ; 0x800147 <timer0_overflow_count+0x2>
2e8: b0 91 48 01 lds r27, 0x0148 ; 0x800148 <timer0_overflow_count+0x3>
2ec: 26 b5 in r18, 0x26 ; 38
2ee: a8 9b sbis 0x15, 0 ; 21
2f0: 05 c0 rjmp .+10 ; 0x2fc <micros+0x24>
2f2: 2f 3f cpi r18, 0xFF ; 255
2f4: 19 f0 breq .+6 ; 0x2fc <micros+0x24>
2f6: 01 96 adiw r24, 0x01 ; 1
2f8: a1 1d adc r26, r1
2fa: b1 1d adc r27, r1
2fc: 3f bf out 0x3f, r19 ; 63
2fe: ba 2f mov r27, r26
300: a9 2f mov r26, r25
302: 98 2f mov r25, r24
304: 88 27 eor r24, r24
306: bc 01 movw r22, r24
308: cd 01 movw r24, r26
30a: 62 0f add r22, r18
30c: 71 1d adc r23, r1
30e: 81 1d adc r24, r1
310: 91 1d adc r25, r1
312: 42 e0 ldi r20, 0x02 ; 2
314: 66 0f add r22, r22
316: 77 1f adc r23, r23
318: 88 1f adc r24, r24
31a: 99 1f adc r25, r25
31c: 4a 95 dec r20
31e: d1 f7 brne .-12 ; 0x314 <micros+0x3c>
320: 08 95 ret
00000322 <Print::write(char const*) [clone .part.2] [clone .constprop.9]>:
322: fc 01 movw r30, r24
324: 01 90 ld r0, Z+
326: 00 20 and r0, r0
328: e9 f7 brne .-6 ; 0x324 <Print::write(char const*) [clone .part.2] [clone .constprop.9]+0x2>
32a: 31 97 sbiw r30, 0x01 ; 1
32c: af 01 movw r20, r30
32e: 48 1b sub r20, r24
330: 59 0b sbc r21, r25
332: bc 01 movw r22, r24
334: 83 e5 ldi r24, 0x53 ; 83
336: 91 e0 ldi r25, 0x01 ; 1
338: 0c 94 5f 00 jmp 0xbe ; 0xbe <Print::write(unsigned char const*, unsigned int)>
0000033c <Print::printNumber(unsigned long, unsigned char) [clone .constprop.5]>:
33c: 8f 92 push r8
33e: 9f 92 push r9
340: af 92 push r10
342: bf 92 push r11
344: 0f 93 push r16
346: 1f 93 push r17
348: cf 93 push r28
34a: df 93 push r29
34c: cd b7 in r28, 0x3d ; 61
34e: de b7 in r29, 0x3e ; 62
350: a1 97 sbiw r28, 0x21 ; 33
352: 0f b6 in r0, 0x3f ; 63
354: f8 94 cli
356: de bf out 0x3e, r29 ; 62
358: 0f be out 0x3f, r0 ; 63
35a: cd bf out 0x3d, r28 ; 61
35c: 19 a2 std Y+33, r1 ; 0x21
35e: 42 30 cpi r20, 0x02 ; 2
360: 08 f4 brcc .+2 ; 0x364 <Print::printNumber(unsigned long, unsigned char) [clone .constprop.5]+0x28>
362: 4a e0 ldi r20, 0x0A ; 10
364: 8e 01 movw r16, r28
366: 0f 5d subi r16, 0xDF ; 223
368: 1f 4f sbci r17, 0xFF ; 255
36a: 84 2e mov r8, r20
36c: 91 2c mov r9, r1
36e: b1 2c mov r11, r1
370: a1 2c mov r10, r1
372: a5 01 movw r20, r10
374: 94 01 movw r18, r8
376: 0e 94 86 04 call 0x90c ; 0x90c <__udivmodsi4>
37a: e6 2f mov r30, r22
37c: b9 01 movw r22, r18
37e: ca 01 movw r24, r20
380: ea 30 cpi r30, 0x0A ; 10
382: f4 f4 brge .+60 ; 0x3c0 <Print::printNumber(unsigned long, unsigned char) [clone .constprop.5]+0x84>
384: e0 5d subi r30, 0xD0 ; 208
386: d8 01 movw r26, r16
388: ee 93 st -X, r30
38a: 8d 01 movw r16, r26
38c: 23 2b or r18, r19
38e: 24 2b or r18, r20
390: 25 2b or r18, r21
392: 79 f7 brne .-34 ; 0x372 <Print::printNumber(unsigned long, unsigned char) [clone .constprop.5]+0x36>
394: 90 e0 ldi r25, 0x00 ; 0
396: 80 e0 ldi r24, 0x00 ; 0
398: 10 97 sbiw r26, 0x00 ; 0
39a: 19 f0 breq .+6 ; 0x3a2 <Print::printNumber(unsigned long, unsigned char) [clone .constprop.5]+0x66>
39c: cd 01 movw r24, r26
39e: 0e 94 91 01 call 0x322 ; 0x322 <Print::write(char const*) [clone .part.2] [clone .constprop.9]>
3a2: a1 96 adiw r28, 0x21 ; 33
3a4: 0f b6 in r0, 0x3f ; 63
3a6: f8 94 cli
3a8: de bf out 0x3e, r29 ; 62
3aa: 0f be out 0x3f, r0 ; 63
3ac: cd bf out 0x3d, r28 ; 61
3ae: df 91 pop r29
3b0: cf 91 pop r28
3b2: 1f 91 pop r17
3b4: 0f 91 pop r16
3b6: bf 90 pop r11
3b8: af 90 pop r10
3ba: 9f 90 pop r9
3bc: 8f 90 pop r8
3be: 08 95 ret
3c0: e9 5c subi r30, 0xC9 ; 201
3c2: e1 cf rjmp .-62 ; 0x386 <Print::printNumber(unsigned long, unsigned char) [clone .constprop.5]+0x4a>
000003c4 <Print::println(char const*) [clone .constprop.6]>:
3c4: cf 93 push r28
3c6: df 93 push r29
3c8: 0e 94 91 01 call 0x322 ; 0x322 <Print::write(char const*) [clone .part.2] [clone .constprop.9]>
3cc: ec 01 movw r28, r24
3ce: 82 e1 ldi r24, 0x12 ; 18
3d0: 91 e0 ldi r25, 0x01 ; 1
3d2: 0e 94 91 01 call 0x322 ; 0x322 <Print::write(char const*) [clone .part.2] [clone .constprop.9]>
3d6: 8c 0f add r24, r28
3d8: 9d 1f adc r25, r29
3da: df 91 pop r29
3dc: cf 91 pop r28
3de: 08 95 ret
000003e0 <__vector_19>:
3e0: 1f 92 push r1
3e2: 0f 92 push r0
3e4: 0f b6 in r0, 0x3f ; 63
3e6: 0f 92 push r0
3e8: 11 24 eor r1, r1
3ea: 2f 93 push r18
3ec: 3f 93 push r19
3ee: 4f 93 push r20
3f0: 5f 93 push r21
3f2: 6f 93 push r22
3f4: 7f 93 push r23
3f6: 8f 93 push r24
3f8: 9f 93 push r25
3fa: af 93 push r26
3fc: bf 93 push r27
3fe: ef 93 push r30
400: ff 93 push r31
402: 83 e5 ldi r24, 0x53 ; 83
404: 91 e0 ldi r25, 0x01 ; 1
406: 0e 94 dd 00 call 0x1ba ; 0x1ba <HardwareSerial::_tx_udr_empty_irq()>
40a: ff 91 pop r31
40c: ef 91 pop r30
40e: bf 91 pop r27
410: af 91 pop r26
412: 9f 91 pop r25
414: 8f 91 pop r24
416: 7f 91 pop r23
418: 6f 91 pop r22
41a: 5f 91 pop r21
41c: 4f 91 pop r20
41e: 3f 91 pop r19
420: 2f 91 pop r18
422: 0f 90 pop r0
424: 0f be out 0x3f, r0 ; 63
426: 0f 90 pop r0
428: 1f 90 pop r1
42a: 18 95 reti
0000042c <__vector_18>:
42c: 1f 92 push r1
42e: 0f 92 push r0
430: 0f b6 in r0, 0x3f ; 63
432: 0f 92 push r0
434: 11 24 eor r1, r1
436: 2f 93 push r18
438: 8f 93 push r24
43a: 9f 93 push r25
43c: ef 93 push r30
43e: ff 93 push r31
440: e0 91 63 01 lds r30, 0x0163 ; 0x800163 <Serial+0x10>
444: f0 91 64 01 lds r31, 0x0164 ; 0x800164 <Serial+0x11>
448: 80 81 ld r24, Z
44a: e0 91 69 01 lds r30, 0x0169 ; 0x800169 <Serial+0x16>
44e: f0 91 6a 01 lds r31, 0x016A ; 0x80016a <Serial+0x17>
452: 82 fd sbrc r24, 2
454: 1b c0 rjmp .+54 ; 0x48c <__vector_18+0x60>
456: 90 81 ld r25, Z
458: 80 91 6c 01 lds r24, 0x016C ; 0x80016c <Serial+0x19>
45c: 8f 5f subi r24, 0xFF ; 255
45e: 8f 73 andi r24, 0x3F ; 63
460: 20 91 6d 01 lds r18, 0x016D ; 0x80016d <Serial+0x1a>
464: 82 17 cp r24, r18
466: 41 f0 breq .+16 ; 0x478 <__vector_18+0x4c>
468: e0 91 6c 01 lds r30, 0x016C ; 0x80016c <Serial+0x19>
46c: f0 e0 ldi r31, 0x00 ; 0
46e: ed 5a subi r30, 0xAD ; 173
470: fe 4f sbci r31, 0xFE ; 254
472: 95 8f std Z+29, r25 ; 0x1d
474: 80 93 6c 01 sts 0x016C, r24 ; 0x80016c <Serial+0x19>
478: ff 91 pop r31
47a: ef 91 pop r30
47c: 9f 91 pop r25
47e: 8f 91 pop r24
480: 2f 91 pop r18
482: 0f 90 pop r0
484: 0f be out 0x3f, r0 ; 63
486: 0f 90 pop r0
488: 1f 90 pop r1
48a: 18 95 reti
48c: 80 81 ld r24, Z
48e: f4 cf rjmp .-24 ; 0x478 <__vector_18+0x4c>
00000490 <__vector_16>:
490: 1f 92 push r1
492: 0f 92 push r0
494: 0f b6 in r0, 0x3f ; 63
496: 0f 92 push r0
498: 11 24 eor r1, r1
49a: 2f 93 push r18
49c: 3f 93 push r19
49e: 8f 93 push r24
4a0: 9f 93 push r25
4a2: af 93 push r26
4a4: bf 93 push r27
4a6: 80 91 41 01 lds r24, 0x0141 ; 0x800141 <timer0_millis>
4aa: 90 91 42 01 lds r25, 0x0142 ; 0x800142 <timer0_millis+0x1>
4ae: a0 91 43 01 lds r26, 0x0143 ; 0x800143 <timer0_millis+0x2>
4b2: b0 91 44 01 lds r27, 0x0144 ; 0x800144 <timer0_millis+0x3>
4b6: 30 91 40 01 lds r19, 0x0140 ; 0x800140 <timer0_fract>
4ba: 23 e0 ldi r18, 0x03 ; 3
4bc: 23 0f add r18, r19
4be: 2d 37 cpi r18, 0x7D ; 125
4c0: 58 f5 brcc .+86 ; 0x518 <__vector_16+0x88>
4c2: 01 96 adiw r24, 0x01 ; 1
4c4: a1 1d adc r26, r1
4c6: b1 1d adc r27, r1
4c8: 20 93 40 01 sts 0x0140, r18 ; 0x800140 <timer0_fract>
4cc: 80 93 41 01 sts 0x0141, r24 ; 0x800141 <timer0_millis>
4d0: 90 93 42 01 sts 0x0142, r25 ; 0x800142 <timer0_millis+0x1>
4d4: a0 93 43 01 sts 0x0143, r26 ; 0x800143 <timer0_millis+0x2>
4d8: b0 93 44 01 sts 0x0144, r27 ; 0x800144 <timer0_millis+0x3>
4dc: 80 91 45 01 lds r24, 0x0145 ; 0x800145 <timer0_overflow_count>
4e0: 90 91 46 01 lds r25, 0x0146 ; 0x800146 <timer0_overflow_count+0x1>
4e4: a0 91 47 01 lds r26, 0x0147 ; 0x800147 <timer0_overflow_count+0x2>
4e8: b0 91 48 01 lds r27, 0x0148 ; 0x800148 <timer0_overflow_count+0x3>
4ec: 01 96 adiw r24, 0x01 ; 1
4ee: a1 1d adc r26, r1
4f0: b1 1d adc r27, r1
4f2: 80 93 45 01 sts 0x0145, r24 ; 0x800145 <timer0_overflow_count>
4f6: 90 93 46 01 sts 0x0146, r25 ; 0x800146 <timer0_overflow_count+0x1>
4fa: a0 93 47 01 sts 0x0147, r26 ; 0x800147 <timer0_overflow_count+0x2>
4fe: b0 93 48 01 sts 0x0148, r27 ; 0x800148 <timer0_overflow_count+0x3>
502: bf 91 pop r27
504: af 91 pop r26
506: 9f 91 pop r25
508: 8f 91 pop r24
50a: 3f 91 pop r19
50c: 2f 91 pop r18
50e: 0f 90 pop r0
510: 0f be out 0x3f, r0 ; 63
512: 0f 90 pop r0
514: 1f 90 pop r1
516: 18 95 reti
518: 26 e8 ldi r18, 0x86 ; 134
51a: 23 0f add r18, r19
51c: 02 96 adiw r24, 0x02 ; 2
51e: a1 1d adc r26, r1
520: b1 1d adc r27, r1
522: d2 cf rjmp .-92 ; 0x4c8 <__vector_16+0x38>
00000524 <main>:
524: 78 94 sei
526: 84 b5 in r24, 0x24 ; 36
528: 82 60 ori r24, 0x02 ; 2
52a: 84 bd out 0x24, r24 ; 36
52c: 84 b5 in r24, 0x24 ; 36
52e: 81 60 ori r24, 0x01 ; 1
530: 84 bd out 0x24, r24 ; 36
532: 85 b5 in r24, 0x25 ; 37
534: 82 60 ori r24, 0x02 ; 2
536: 85 bd out 0x25, r24 ; 37
538: 85 b5 in r24, 0x25 ; 37
53a: 81 60 ori r24, 0x01 ; 1
53c: 85 bd out 0x25, r24 ; 37
53e: 80 91 6e 00 lds r24, 0x006E ; 0x80006e <__DATA_REGION_ORIGIN__+0xe>
542: 81 60 ori r24, 0x01 ; 1
544: 80 93 6e 00 sts 0x006E, r24 ; 0x80006e <__DATA_REGION_ORIGIN__+0xe>
548: 10 92 81 00 sts 0x0081, r1 ; 0x800081 <__DATA_REGION_ORIGIN__+0x21>
54c: 80 91 81 00 lds r24, 0x0081 ; 0x800081 <__DATA_REGION_ORIGIN__+0x21>
550: 82 60 ori r24, 0x02 ; 2
552: 80 93 81 00 sts 0x0081, r24 ; 0x800081 <__DATA_REGION_ORIGIN__+0x21>
556: 80 91 81 00 lds r24, 0x0081 ; 0x800081 <__DATA_REGION_ORIGIN__+0x21>
55a: 81 60 ori r24, 0x01 ; 1
55c: 80 93 81 00 sts 0x0081, r24 ; 0x800081 <__DATA_REGION_ORIGIN__+0x21>
560: 80 91 80 00 lds r24, 0x0080 ; 0x800080 <__DATA_REGION_ORIGIN__+0x20>
564: 81 60 ori r24, 0x01 ; 1
566: 80 93 80 00 sts 0x0080, r24 ; 0x800080 <__DATA_REGION_ORIGIN__+0x20>
56a: 80 91 b1 00 lds r24, 0x00B1 ; 0x8000b1 <__DATA_REGION_ORIGIN__+0x51>
56e: 84 60 ori r24, 0x04 ; 4
570: 80 93 b1 00 sts 0x00B1, r24 ; 0x8000b1 <__DATA_REGION_ORIGIN__+0x51>
574: 80 91 b0 00 lds r24, 0x00B0 ; 0x8000b0 <__DATA_REGION_ORIGIN__+0x50>
578: 81 60 ori r24, 0x01 ; 1
57a: 80 93 b0 00 sts 0x00B0, r24 ; 0x8000b0 <__DATA_REGION_ORIGIN__+0x50>
57e: 80 91 7a 00 lds r24, 0x007A ; 0x80007a <__DATA_REGION_ORIGIN__+0x1a>
582: 84 60 ori r24, 0x04 ; 4
584: 80 93 7a 00 sts 0x007A, r24 ; 0x80007a <__DATA_REGION_ORIGIN__+0x1a>
588: 80 91 7a 00 lds r24, 0x007A ; 0x80007a <__DATA_REGION_ORIGIN__+0x1a>
58c: 82 60 ori r24, 0x02 ; 2
58e: 80 93 7a 00 sts 0x007A, r24 ; 0x80007a <__DATA_REGION_ORIGIN__+0x1a>
592: 80 91 7a 00 lds r24, 0x007A ; 0x80007a <__DATA_REGION_ORIGIN__+0x1a>
596: 81 60 ori r24, 0x01 ; 1
598: 80 93 7a 00 sts 0x007A, r24 ; 0x80007a <__DATA_REGION_ORIGIN__+0x1a>
59c: 80 91 7a 00 lds r24, 0x007A ; 0x80007a <__DATA_REGION_ORIGIN__+0x1a>
5a0: 80 68 ori r24, 0x80 ; 128
5a2: 80 93 7a 00 sts 0x007A, r24 ; 0x80007a <__DATA_REGION_ORIGIN__+0x1a>
5a6: 10 92 c1 00 sts 0x00C1, r1 ; 0x8000c1 <__DATA_REGION_ORIGIN__+0x61>
5aa: e0 91 63 01 lds r30, 0x0163 ; 0x800163 <Serial+0x10>
5ae: f0 91 64 01 lds r31, 0x0164 ; 0x800164 <Serial+0x11>
5b2: 82 e0 ldi r24, 0x02 ; 2
5b4: 80 83 st Z, r24
5b6: e0 91 5f 01 lds r30, 0x015F ; 0x80015f <Serial+0xc>
5ba: f0 91 60 01 lds r31, 0x0160 ; 0x800160 <Serial+0xd>
5be: 10 82 st Z, r1
5c0: e0 91 61 01 lds r30, 0x0161 ; 0x800161 <Serial+0xe>
5c4: f0 91 62 01 lds r31, 0x0162 ; 0x800162 <Serial+0xf>
5c8: 80 e1 ldi r24, 0x10 ; 16
5ca: 80 83 st Z, r24
5cc: 10 92 6b 01 sts 0x016B, r1 ; 0x80016b <Serial+0x18>
5d0: e0 91 67 01 lds r30, 0x0167 ; 0x800167 <Serial+0x14>
5d4: f0 91 68 01 lds r31, 0x0168 ; 0x800168 <Serial+0x15>
5d8: 86 e0 ldi r24, 0x06 ; 6
5da: 80 83 st Z, r24
5dc: e0 91 65 01 lds r30, 0x0165 ; 0x800165 <Serial+0x12>
5e0: f0 91 66 01 lds r31, 0x0166 ; 0x800166 <Serial+0x13>
5e4: 80 81 ld r24, Z
5e6: 80 61 ori r24, 0x10 ; 16
5e8: 80 83 st Z, r24
5ea: e0 91 65 01 lds r30, 0x0165 ; 0x800165 <Serial+0x12>
5ee: f0 91 66 01 lds r31, 0x0166 ; 0x800166 <Serial+0x13>
5f2: 80 81 ld r24, Z
5f4: 88 60 ori r24, 0x08 ; 8
5f6: 80 83 st Z, r24
5f8: e0 91 65 01 lds r30, 0x0165 ; 0x800165 <Serial+0x12>
5fc: f0 91 66 01 lds r31, 0x0166 ; 0x800166 <Serial+0x13>
600: 80 81 ld r24, Z
602: 80 68 ori r24, 0x80 ; 128
604: 80 83 st Z, r24
606: e0 91 65 01 lds r30, 0x0165 ; 0x800165 <Serial+0x12>
60a: f0 91 66 01 lds r31, 0x0166 ; 0x800166 <Serial+0x13>
60e: 80 81 ld r24, Z
610: 8f 7d andi r24, 0xDF ; 223
612: 80 83 st Z, r24
614: 85 e1 ldi r24, 0x15 ; 21
616: 91 e0 ldi r25, 0x01 ; 1
618: 0e 94 e2 01 call 0x3c4 ; 0x3c4 <Print::println(char const*) [clone .constprop.6]>
61c: 0e 94 6c 01 call 0x2d8 ; 0x2d8 <micros>
620: 6b 01 movw r12, r22
622: 7c 01 movw r14, r24
624: c0 92 4b 01 sts 0x014B, r12 ; 0x80014b <timestart>
628: d0 92 4c 01 sts 0x014C, r13 ; 0x80014c <timestart+0x1>
62c: e0 92 4d 01 sts 0x014D, r14 ; 0x80014d <timestart+0x2>
630: f0 92 4e 01 sts 0x014E, r15 ; 0x80014e <timestart+0x3>
634: c9 ee ldi r28, 0xE9 ; 233
636: d3 e0 ldi r29, 0x03 ; 3
638: 60 e0 ldi r22, 0x00 ; 0
63a: 70 e0 ldi r23, 0x00 ; 0
63c: 80 e0 ldi r24, 0x00 ; 0
63e: 90 e4 ldi r25, 0x40 ; 64
640: 21 97 sbiw r28, 0x01 ; 1 <--- La boucle for pour les flottants
642: 29 f0 breq .+10 ; 0x64e <main+0x12a>
644: 9b 01 movw r18, r22
646: ac 01 movw r20, r24
648: 0e 94 c8 03 call 0x790 ; 0x790 <__mulsf3>
64c: f9 cf rjmp .-14 ; 0x640 <main+0x11c> <-- Fin de la boucle for
64e: 28 ee ldi r18, 0xE8 ; 232
650: 33 e0 ldi r19, 0x03 ; 3
652: 30 93 4a 01 sts 0x014A, r19 ; 0x80014a <i+0x1>
656: 20 93 49 01 sts 0x0149, r18 ; 0x800149 <i>
65a: 60 93 4f 01 sts 0x014F, r22 ; 0x80014f <x>
65e: 70 93 50 01 sts 0x0150, r23 ; 0x800150 <x+0x1>
662: 80 93 51 01 sts 0x0151, r24 ; 0x800151 <x+0x2>
666: 90 93 52 01 sts 0x0152, r25 ; 0x800152 <x+0x3>
66a: 0e 94 6c 01 call 0x2d8 ; 0x2d8 <micros>
66e: 6c 19 sub r22, r12
670: 7d 09 sbc r23, r13
672: 8e 09 sbc r24, r14
674: 9f 09 sbc r25, r15
676: 4a e0 ldi r20, 0x0A ; 10
678: 0e 94 9e 01 call 0x33c ; 0x33c <Print::printNumber(unsigned long, unsigned char) [clone .constprop.5]>
67c: 84 e2 ldi r24, 0x24 ; 36
67e: 91 e0 ldi r25, 0x01 ; 1
680: 0e 94 e2 01 call 0x3c4 ; 0x3c4 <Print::println(char const*) [clone .constprop.6]>
684: 8f e2 ldi r24, 0x2F ; 47
686: 91 e0 ldi r25, 0x01 ; 1
688: 0e 94 e2 01 call 0x3c4 ; 0x3c4 <Print::println(char const*) [clone .constprop.6]>
68c: 80 e0 ldi r24, 0x00 ; 0
68e: 90 e0 ldi r25, 0x00 ; 0
690: a0 e0 ldi r26, 0x00 ; 0
692: b0 e4 ldi r27, 0x40 ; 64
694: 80 93 4f 01 sts 0x014F, r24 ; 0x80014f <x>
698: 90 93 50 01 sts 0x0150, r25 ; 0x800150 <x+0x1>
69c: a0 93 51 01 sts 0x0151, r26 ; 0x800151 <x+0x2>
6a0: b0 93 52 01 sts 0x0152, r27 ; 0x800152 <x+0x3>
6a4: 0e 94 6c 01 call 0x2d8 ; 0x2d8 <micros>
6a8: 6b 01 movw r12, r22
6aa: 7c 01 movw r14, r24
6ac: c0 92 4b 01 sts 0x014B, r12 ; 0x80014b <timestart>
6b0: d0 92 4c 01 sts 0x014C, r13 ; 0x80014c <timestart+0x1>
6b4: e0 92 4d 01 sts 0x014D, r14 ; 0x80014d <timestart+0x2>
6b8: f0 92 4e 01 sts 0x014E, r15 ; 0x80014e <timestart+0x3>
6bc: 29 ee ldi r18, 0xE9 ; 233
6be: 33 e0 ldi r19, 0x03 ; 3
6c0: 21 50 subi r18, 0x01 ; 1
6c2: 31 09 sbc r19, r1; <---- boucle for pour le bidouillage
6c4: d1 f0 breq .+52 ; 0x6fa <main+0x1d6>
6c6: 80 91 4f 01 lds r24, 0x014F ; 0x80014f <x>
6ca: 90 91 50 01 lds r25, 0x0150 ; 0x800150 <x+0x1>
6ce: a0 91 51 01 lds r26, 0x0151 ; 0x800151 <x+0x2>
6d2: b0 91 52 01 lds r27, 0x0152 ; 0x800152 <x+0x3>
6d6: 88 0f add r24, r24
6d8: 99 1f adc r25, r25
6da: aa 1f adc r26, r26
6dc: bb 1f adc r27, r27
6de: 88 56 subi r24, 0x68 ; 104 <--- Bien caché
6e0: 98 48 sbci r25, 0x88 ; 136 <--- Vous avez
6e2: a4 47 sbci r26, 0x74 ; 116 <--- La constante
6e4: bf 43 sbci r27, 0x3F ; 63 <--- magique
6e6: bf 77 andi r27, 0x7F ; 127
6e8: 80 93 4f 01 sts 0x014F, r24 ; 0x80014f <x>
6ec: 90 93 50 01 sts 0x0150, r25 ; 0x800150 <x+0x1>
6f0: a0 93 51 01 sts 0x0151, r26 ; 0x800151 <x+0x2>
6f4: b0 93 52 01 sts 0x0152, r27 ; 0x800152 <x+0x3>
6f8: e3 cf rjmp .-58 ; 0x6c0 <main+0x19c> <--- fin de la boucle for
6fa: 88 ee ldi r24, 0xE8 ; 232
6fc: 93 e0 ldi r25, 0x03 ; 3
6fe: 90 93 4a 01 sts 0x014A, r25 ; 0x80014a <i+0x1>
702: 80 93 49 01 sts 0x0149, r24 ; 0x800149 <i>
706: 0e 94 6c 01 call 0x2d8 ; 0x2d8 <micros>
70a: 6c 19 sub r22, r12
70c: 7d 09 sbc r23, r13
70e: 8e 09 sbc r24, r14
710: 9f 09 sbc r25, r15
712: 4a e0 ldi r20, 0x0A ; 10
714: 0e 94 9e 01 call 0x33c ; 0x33c <Print::printNumber(unsigned long, unsigned char) [clone .constprop.5]>
718: 84 e2 ldi r24, 0x24 ; 36
71a: 91 e0 ldi r25, 0x01 ; 1
71c: 0e 94 e2 01 call 0x3c4 ; 0x3c4 <Print::println(char const*) [clone .constprop.6]>
720: c0 e0 ldi r28, 0x00 ; 0
722: d0 e0 ldi r29, 0x00 ; 0
724: 20 97 sbiw r28, 0x00 ; 0
726: f1 f3 breq .-4 ; 0x724 <main+0x200>
728: 0e 94 c9 00 call 0x192 ; 0x192 <Serial0_available()>
72c: 88 23 and r24, r24
72e: d1 f3 breq .-12 ; 0x724 <main+0x200>
730: 0e 94 00 00 call 0 ; 0x0 <__vectors>
734: f7 cf rjmp .-18 ; 0x724 <main+0x200>
00000736 <_GLOBAL__sub_I___vector_18>:
736: e3 e5 ldi r30, 0x53 ; 83
738: f1 e0 ldi r31, 0x01 ; 1
73a: 13 82 std Z+3, r1 ; 0x03
73c: 12 82 std Z+2, r1 ; 0x02
73e: 88 ee ldi r24, 0xE8 ; 232
740: 93 e0 ldi r25, 0x03 ; 3
742: a0 e0 ldi r26, 0x00 ; 0
744: b0 e0 ldi r27, 0x00 ; 0
746: 84 83 std Z+4, r24 ; 0x04
748: 95 83 std Z+5, r25 ; 0x05
74a: a6 83 std Z+6, r26 ; 0x06
74c: b7 83 std Z+7, r27 ; 0x07
74e: 84 e0 ldi r24, 0x04 ; 4
750: 91 e0 ldi r25, 0x01 ; 1
752: 91 83 std Z+1, r25 ; 0x01
754: 80 83 st Z, r24
756: 85 ec ldi r24, 0xC5 ; 197
758: 90 e0 ldi r25, 0x00 ; 0
75a: 95 87 std Z+13, r25 ; 0x0d
75c: 84 87 std Z+12, r24 ; 0x0c
75e: 84 ec ldi r24, 0xC4 ; 196
760: 90 e0 ldi r25, 0x00 ; 0
762: 97 87 std Z+15, r25 ; 0x0f
764: 86 87 std Z+14, r24 ; 0x0e
766: 80 ec ldi r24, 0xC0 ; 192
768: 90 e0 ldi r25, 0x00 ; 0
76a: 91 8b std Z+17, r25 ; 0x11
76c: 80 8b std Z+16, r24 ; 0x10
76e: 81 ec ldi r24, 0xC1 ; 193
770: 90 e0 ldi r25, 0x00 ; 0
772: 93 8b std Z+19, r25 ; 0x13
774: 82 8b std Z+18, r24 ; 0x12
776: 82 ec ldi r24, 0xC2 ; 194
778: 90 e0 ldi r25, 0x00 ; 0
77a: 95 8b std Z+21, r25 ; 0x15
77c: 84 8b std Z+20, r24 ; 0x14
77e: 86 ec ldi r24, 0xC6 ; 198
780: 90 e0 ldi r25, 0x00 ; 0
782: 97 8b std Z+23, r25 ; 0x17
784: 86 8b std Z+22, r24 ; 0x16
786: 11 8e std Z+25, r1 ; 0x19
788: 12 8e std Z+26, r1 ; 0x1a
78a: 13 8e std Z+27, r1 ; 0x1b
78c: 14 8e std Z+28, r1 ; 0x1c
78e: 08 95 ret
00000790 <__mulsf3>: <-- L'implémentation de la multiplication des flottants
790: 0e 94 db 03 call 0x7b6 ; 0x7b6 <__mulsf3x>
794: 0c 94 4c 04 jmp 0x898 ; 0x898 <__fp_round>
798: 0e 94 3e 04 call 0x87c ; 0x87c <__fp_pscA>
79c: 38 f0 brcs .+14 ; 0x7ac <__mulsf3+0x1c>
79e: 0e 94 45 04 call 0x88a ; 0x88a <__fp_pscB>
7a2: 20 f0 brcs .+8 ; 0x7ac <__mulsf3+0x1c>
7a4: 95 23 and r25, r21
7a6: 11 f0 breq .+4 ; 0x7ac <__mulsf3+0x1c>
7a8: 0c 94 35 04 jmp 0x86a ; 0x86a <__fp_inf>
7ac: 0c 94 3b 04 jmp 0x876 ; 0x876 <__fp_nan>
7b0: 11 24 eor r1, r1
7b2: 0c 94 80 04 jmp 0x900 ; 0x900 <__fp_szero>
000007b6 <__mulsf3x>:
7b6: 0e 94 5d 04 call 0x8ba ; 0x8ba <__fp_split3>
7ba: 70 f3 brcs .-36 ; 0x798 <__mulsf3+0x8>
000007bc <__mulsf3_pse>:
7bc: 95 9f mul r25, r21
7be: c1 f3 breq .-16 ; 0x7b0 <__mulsf3+0x20>
7c0: 95 0f add r25, r21
7c2: 50 e0 ldi r21, 0x00 ; 0
7c4: 55 1f adc r21, r21
7c6: 62 9f mul r22, r18
7c8: f0 01 movw r30, r0
7ca: 72 9f mul r23, r18
7cc: bb 27 eor r27, r27
7ce: f0 0d add r31, r0
7d0: b1 1d adc r27, r1
7d2: 63 9f mul r22, r19
7d4: aa 27 eor r26, r26
7d6: f0 0d add r31, r0
7d8: b1 1d adc r27, r1
7da: aa 1f adc r26, r26
7dc: 64 9f mul r22, r20
7de: 66 27 eor r22, r22
7e0: b0 0d add r27, r0
7e2: a1 1d adc r26, r1
7e4: 66 1f adc r22, r22
7e6: 82 9f mul r24, r18
7e8: 22 27 eor r18, r18
7ea: b0 0d add r27, r0
7ec: a1 1d adc r26, r1
7ee: 62 1f adc r22, r18
7f0: 73 9f mul r23, r19
7f2: b0 0d add r27, r0
7f4: a1 1d adc r26, r1
7f6: 62 1f adc r22, r18
7f8: 83 9f mul r24, r19
7fa: a0 0d add r26, r0
7fc: 61 1d adc r22, r1
7fe: 22 1f adc r18, r18
800: 74 9f mul r23, r20
802: 33 27 eor r19, r19
804: a0 0d add r26, r0
806: 61 1d adc r22, r1
808: 23 1f adc r18, r19
80a: 84 9f mul r24, r20
80c: 60 0d add r22, r0
80e: 21 1d adc r18, r1
810: 82 2f mov r24, r18
812: 76 2f mov r23, r22
814: 6a 2f mov r22, r26
816: 11 24 eor r1, r1
818: 9f 57 subi r25, 0x7F ; 127
81a: 50 40 sbci r21, 0x00 ; 0
81c: 9a f0 brmi .+38 ; 0x844 <__mulsf3_pse+0x88>
81e: f1 f0 breq .+60 ; 0x85c <__mulsf3_pse+0xa0>
820: 88 23 and r24, r24
822: 4a f0 brmi .+18 ; 0x836 <__mulsf3_pse+0x7a>
824: ee 0f add r30, r30
826: ff 1f adc r31, r31
828: bb 1f adc r27, r27
82a: 66 1f adc r22, r22
82c: 77 1f adc r23, r23
82e: 88 1f adc r24, r24
830: 91 50 subi r25, 0x01 ; 1
832: 50 40 sbci r21, 0x00 ; 0
834: a9 f7 brne .-22 ; 0x820 <__mulsf3_pse+0x64>
836: 9e 3f cpi r25, 0xFE ; 254
838: 51 05 cpc r21, r1
83a: 80 f0 brcs .+32 ; 0x85c <__mulsf3_pse+0xa0>
83c: 0c 94 35 04 jmp 0x86a ; 0x86a <__fp_inf>
840: 0c 94 80 04 jmp 0x900 ; 0x900 <__fp_szero>
844: 5f 3f cpi r21, 0xFF ; 255
846: e4 f3 brlt .-8 ; 0x840 <__mulsf3_pse+0x84>
848: 98 3e cpi r25, 0xE8 ; 232
84a: d4 f3 brlt .-12 ; 0x840 <__mulsf3_pse+0x84>
84c: 86 95 lsr r24
84e: 77 95 ror r23
850: 67 95 ror r22
852: b7 95 ror r27
854: f7 95 ror r31
856: e7 95 ror r30
858: 9f 5f subi r25, 0xFF ; 255
85a: c1 f7 brne .-16 ; 0x84c <__mulsf3_pse+0x90>
85c: fe 2b or r31, r30
85e: 88 0f add r24, r24
860: 91 1d adc r25, r1
862: 96 95 lsr r25
864: 87 95 ror r24
866: 97 f9 bld r25, 7
868: 08 95 ret
0000086a <__fp_inf>:
86a: 97 f9 bld r25, 7
86c: 9f 67 ori r25, 0x7F ; 127
86e: 80 e8 ldi r24, 0x80 ; 128
870: 70 e0 ldi r23, 0x00 ; 0
872: 60 e0 ldi r22, 0x00 ; 0
874: 08 95 ret
00000876 <__fp_nan>:
876: 9f ef ldi r25, 0xFF ; 255
878: 80 ec ldi r24, 0xC0 ; 192
87a: 08 95 ret
0000087c <__fp_pscA>:
87c: 00 24 eor r0, r0
87e: 0a 94 dec r0
880: 16 16 cp r1, r22
882: 17 06 cpc r1, r23
884: 18 06 cpc r1, r24
886: 09 06 cpc r0, r25
888: 08 95 ret
0000088a <__fp_pscB>:
88a: 00 24 eor r0, r0
88c: 0a 94 dec r0
88e: 12 16 cp r1, r18
890: 13 06 cpc r1, r19
892: 14 06 cpc r1, r20
894: 05 06 cpc r0, r21
896: 08 95 ret
00000898 <__fp_round>:
898: 09 2e mov r0, r25
89a: 03 94 inc r0
89c: 00 0c add r0, r0
89e: 11 f4 brne .+4 ; 0x8a4 <__fp_round+0xc>
8a0: 88 23 and r24, r24
8a2: 52 f0 brmi .+20 ; 0x8b8 <__fp_round+0x20>
8a4: bb 0f add r27, r27
8a6: 40 f4 brcc .+16 ; 0x8b8 <__fp_round+0x20>
8a8: bf 2b or r27, r31
8aa: 11 f4 brne .+4 ; 0x8b0 <__fp_round+0x18>
8ac: 60 ff sbrs r22, 0
8ae: 04 c0 rjmp .+8 ; 0x8b8 <__fp_round+0x20>
8b0: 6f 5f subi r22, 0xFF ; 255
8b2: 7f 4f sbci r23, 0xFF ; 255
8b4: 8f 4f sbci r24, 0xFF ; 255
8b6: 9f 4f sbci r25, 0xFF ; 255
8b8: 08 95 ret
000008ba <__fp_split3>:
8ba: 57 fd sbrc r21, 7
8bc: 90 58 subi r25, 0x80 ; 128
8be: 44 0f add r20, r20
8c0: 55 1f adc r21, r21
8c2: 59 f0 breq .+22 ; 0x8da <__fp_splitA+0x10>
8c4: 5f 3f cpi r21, 0xFF ; 255
8c6: 71 f0 breq .+28 ; 0x8e4 <__fp_splitA+0x1a>
8c8: 47 95 ror r20
000008ca <__fp_splitA>:
8ca: 88 0f add r24, r24
8cc: 97 fb bst r25, 7
8ce: 99 1f adc r25, r25
8d0: 61 f0 breq .+24 ; 0x8ea <__fp_splitA+0x20>
8d2: 9f 3f cpi r25, 0xFF ; 255
8d4: 79 f0 breq .+30 ; 0x8f4 <__fp_splitA+0x2a>
8d6: 87 95 ror r24
8d8: 08 95 ret
8da: 12 16 cp r1, r18
8dc: 13 06 cpc r1, r19
8de: 14 06 cpc r1, r20
8e0: 55 1f adc r21, r21
8e2: f2 cf rjmp .-28 ; 0x8c8 <__fp_split3+0xe>
8e4: 46 95 lsr r20
8e6: f1 df rcall .-30 ; 0x8ca <__fp_splitA>
8e8: 08 c0 rjmp .+16 ; 0x8fa <__fp_splitA+0x30>
8ea: 16 16 cp r1, r22
8ec: 17 06 cpc r1, r23
8ee: 18 06 cpc r1, r24
8f0: 99 1f adc r25, r25
8f2: f1 cf rjmp .-30 ; 0x8d6 <__fp_splitA+0xc>
8f4: 86 95 lsr r24
8f6: 71 05 cpc r23, r1
8f8: 61 05 cpc r22, r1
8fa: 08 94 sec
8fc: 08 95 ret
000008fe <__fp_zero>:
8fe: e8 94 clt
00000900 <__fp_szero>:
900: bb 27 eor r27, r27
902: 66 27 eor r22, r22
904: 77 27 eor r23, r23
906: cb 01 movw r24, r22
908: 97 f9 bld r25, 7
90a: 08 95 ret
0000090c <__udivmodsi4>:
90c: a1 e2 ldi r26, 0x21 ; 33
90e: 1a 2e mov r1, r26
910: aa 1b sub r26, r26
912: bb 1b sub r27, r27
914: fd 01 movw r30, r26
916: 0d c0 rjmp .+26 ; 0x932 <__udivmodsi4_ep>
00000918 <__udivmodsi4_loop>:
918: aa 1f adc r26, r26
91a: bb 1f adc r27, r27
91c: ee 1f adc r30, r30
91e: ff 1f adc r31, r31
920: a2 17 cp r26, r18
922: b3 07 cpc r27, r19
924: e4 07 cpc r30, r20
926: f5 07 cpc r31, r21
928: 20 f0 brcs .+8 ; 0x932 <__udivmodsi4_ep>
92a: a2 1b sub r26, r18
92c: b3 0b sbc r27, r19
92e: e4 0b sbc r30, r20
930: f5 0b sbc r31, r21
00000932 <__udivmodsi4_ep>:
932: 66 1f adc r22, r22
934: 77 1f adc r23, r23
936: 88 1f adc r24, r24
938: 99 1f adc r25, r25
93a: 1a 94 dec r1
93c: 69 f7 brne .-38 ; 0x918 <__udivmodsi4_loop>
93e: 60 95 com r22
940: 70 95 com r23
942: 80 95 com r24
944: 90 95 com r25
946: 9b 01 movw r18, r22
948: ac 01 movw r20, r24
94a: bd 01 movw r22, r26
94c: cf 01 movw r24, r30
94e: 08 95 ret
00000950 <__tablejump2__>:
950: ee 0f add r30, r30
952: ff 1f adc r31, r31
954: 05 90 lpm r0, Z+
956: f4 91 lpm r31, Z
958: e0 2d mov r30, r0
95a: 09 94 ijmp
0000095c <_exit>:
95c: f8 94 cli
0000095e <__stop_program>:
95e: ff cf rjmp .-2 ; 0x95e <__stop_program>