
- VPAT/WCAG les acronymes qui rendent votre site accessible
- rétrospective sur la mise en page en console
Mise en garde : je ne suis absolument pas un expert de la programmation concurrente lock-free. Ce billet présente surtout une implémentation que j’ai faite en guise d’exercice pour en apprendre plus sur le sujet. Le code que j’écris cache peut-être des bugs subtils que mon œil naïf ne saurait encore voir. Si vous en décelez une, dites-le moi s’il vous plaît !
Pour en apprendre plus sur la programmation lock-free (code concurrent sans système de verrouillage, souvent de type mutex/futex), j’ai décidé d’écrire un générateurs de Snowflake ID qui marche dans une situation de haute concurrence.
En l’essence, un Snowflake ID est un entier sur 64 bits qui embarque un timestamp sur ses premiers bits (les plus significatifs), suivis d’un numéro de séquence sur les derniers bits restants. La version originale de Twitter inclut aussi un identifiant de machine entre le timestamp et le numéro de séquence, mais j’ai implémenté une version plus simple définie comme suit :
- 48 premiers bits : timestamp Unix en millisecondes
- 16 derniers bits : numéro de séquence, allant de 0 à 65 535 (0xffff)
Cette version est similaire à celle que Mastodon implémente.
Les Snowflake ID ont des propriétés qui les rendent intéressantes si l’on veut les implémenter avec un algorithme thread-safe. Ils doivent être uniques et générés dans un ordre strictement croissant parmi tous les workers qui en veulent. Cela signifie qu’il est nécessaire de maintenir un état interne et de le protéger des accès non sérialisés qui pourraient le corrompre et invalider les propriétés définies.
Version Mutex
Voici une première version qui utilise une mutex. Elle servira de base de comparaison et permet d’illustrer l’algorithme de génération d’un Snowflake ID. Le code est en Go, mais il reste lisible pour les non-pratiquants de Go.
État interne :
type IDGen struct {
mu sync.Mutex
ts int64 // Dernier timestamp en usage
seq int64 // Dernier numéro de séquence pour ce timestamp
}
Cette fonction assure les accès sérialisés grâce à la mutex. Quand le verrou est actif, on peut ainsi mettre à jour l’état du timestamp ts et du numéro de séquence seq en une opération conceptuellement atomique. C’est le cas facile, la version lock-free ne donnera pas ce luxe.
func (g *IDGen) NewID() int64 {
ts := time.Now().UnixMilli()
g.mu.Lock()
// Réinitialiser seq et ts si le timestamp a avancé dans le temps
if ts > g.ts {
g.seq = 0
g.ts = ts
}
seq := g.seq
g.seq++
g.mu.Unlock()
// Pour la rigueur.
// Ma machine met 25ns pour générer un ID, soit 40k IDs/ms.
// On ne devrait pas atteindre cette valeur dans la pratique.
if seq > 0xffff {
return -1
}
// 48 bits de poids fort : timestamp
// 16 bits de poids faible : séquence
id := (ts << 16) | seq
return id
}
Est-ce rapide ?
Sur ma machine (Intel(R) Core(TM) i7-1255U en mode performance), cela met environ 35 nanosecondes sans aucune contention. Il y a donc une pénalité de 10 ns comparée à la version sans aucune protection (non thread-safe) qui met 25 ns.
La version Lock-Free
Cette version n’utilise plus de mutex du tout. À la place, elle utilise deux instructions atomiques :
AddInt64(*v, delta)incrémente et ré-affecte*v += deltaet retourne cette nouvelle valeur.CompareAndSwapInt64(*v, old, new)ré-affecte*v = new, mais à la condition que*v == oldau moment où l’on effectue l’opération, c’est-à-dire sans qu’un autre thread n’eût mis à jour*vpendant ce temps.
Ce que font ces deux opérations est plus clair avec le code, pas de panique.
Mais ici il devient difficile de gérer la mise à jour de deux variables (le timestamp et la séquence) de façon cohérente avec les instructions atomiques. Je travaille donc avec une seule valeur : un entier id qui encode aussi bien le timestamp que la séquence et sur lequel on peut opérer :
type IDGen struct {
id int64 // Deux en un : ts + seq
}
Remarques sur le code
Avant de voir le nouveau code, voici quelques éléments à rappeler pour bien le comprendre :
Le timestamp s’extrait en faisant id >> 16.
Incrémenter l’ID entier, c’est incrémenter son numéro de séquence placé sur les bits de poids faible, en supposant que l’on n’atteigne pas le cas limite où la séquence dépasse 0xffff. On peut donc utiliser AddInt64 directement sur l’ancien ID généré.
Puisque que CompareAndSwapInt64(*v, old, new) peut échouer, il nous faut une boucle pour ré-essayer jusqu’au succès, d’où le for.
On considère que le temps ne peut aller qu’en avant (le retour d’un appel à time.Now() ne saurait être strictement inférieur à un précédent).
Allez, place au code !
func (g *IDGen) NewID() int64 {
for { // boucle infinie, en Go
ts := time.Now().UnixMilli()
candidateID := atomic.AddInt64(&g.id, 1)
if ts == candidateID>>16 {
// On a eu un ID incrémenté et le timestamp est toujours
// sur la même milliseconde. C'est bon, on a notre ID.
return candidateID
}
// Cas où le timestamp a changé depuis la dernière génération d'ID.
// On doit alors le ré-initiation avec le nouveau timestamp et
// repartie avec seq = 0.
// Si aucun autre thread n'a touché g.id, alors il devrait
// être encore égal à candidateID retourné par AddInt64 plus haut.
if atomic.CompareAndSwapInt64(&g.id, candidateID, ts<<16) {
// Succès, on a notre nouvel ID. Pas besoin de OR, car seq = 0
return ts << 16
}
// Échec... On dirait qu'un autre thread a touché g.id entre temps.
// Il faut ré-essayer.
}
}
Est-ce rapide ?
Dans un cas sans aucune contention, cette version met 29 ns (pour rappel, la version mutex met 35 ns et la version sans protection en met 25 ns).
Mutex vs. Lock-free en cas de haute concurrence
Passons aux choses intéressantes.
L’intérêt de ces algorithmes lock-free, c’est d’être efficaces dans des situations de haute concurrence, quand la contention peut augmenter de façon non triviale. Alors testons la rapidité de nos algorithmes avec ce mode.
Pour chaque run, c workers vont générer 10 000 ID de façon concurrente. J’ai fait tourner chaque benchmark 1000 fois et j’ai pris la moyenne (en microsecondes). J’ai laissé le CPU refroidir entre chaque run.
Résultats :
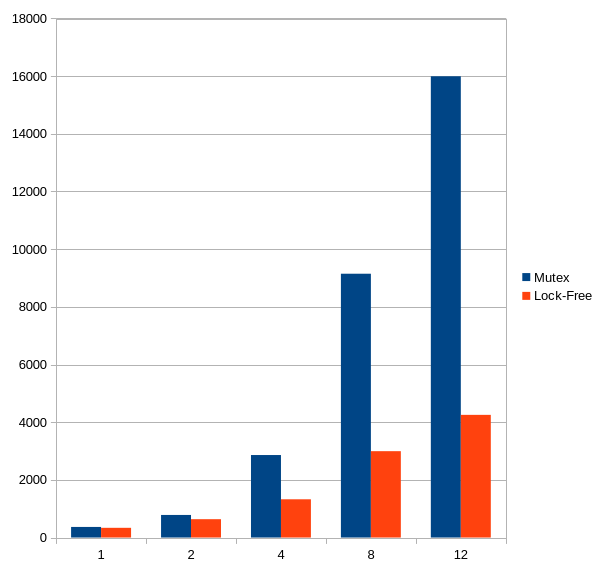
Quand le niveau de concurrence est bas les deux versions sont semblables. Dès que l’on passe à 4, la différence commence à s’affirmer plus franchement, quand la contention est supposément bien plus haute. Au delà de ce niveau, la version mutex se vautre juste.
Je ne suis pas allé au dessus de 12 workers, je n’ai que 12 cores.
Conclusion
Si le niveau de contention attendu est bas, voire proche de 0 la plupart du temps, alors il n’est certainement pas nécessaire d’aller sur autre chose que de la mutex. Les mutex modernes (futex) sont en réalité assez rapides dans ces cas-ci. Rappelez-vous : la pénalité n’est que de 10 ns dans un cas sans contention. La version lock-free, quant à elle, est difficile à concevoir et à comprendre. Honnêtement je ne suis pas sûr d’avoir géré les petits cas subtiles pouvant mener à des bugs pernicieux, et j’ai dû faire quelques présupposés pour valider cette version.
Mais l’exercice était rigolo.
Autre
Ce billet est la traduction en français de l’original en anglais, rédigé en préparation au défi de l’Avent.
Crédits de l’image de la vignette : domaine public, source : https://commons.wikimedia.org/wiki/File:Snowflakeschapte00warriala-p11-p21-p29-p39.jpg





{kind=link}