- Statistiques d'avril 2024
- MailDev: la solution pour tester les mails générés par votre application web
Au boulot, un collègue a commencé à noter s’il prenait de la vinaigrette ou de la mayonnaise avec sa salade.
Depuis le début de la semaine, voici ce qu’il a consigné:
| Lundi | Mardi | Mercredi | Jeudi |
|---|---|---|---|
| Vinaigrette | Mayonnaise | Vinaigrette |
Que peut-on prédire pour demain sur base de ces observations ? Intuitivement, on pourrait se dire qu’il a 2 chances sur 3 (66%) de reprendre de la vinaigrette.
Mais est-ce qu’il est possible de faire mieux ? Exprimer, par exemple, que la probabilité qu’il reprenne de la vinaigrette est de 66% avec un intervalle de confiance de plus ou moins 20% ?
Bernouilli
Ce genre d’expériences où chaque jour correspond à une nouvelle expérience, indépendante de la veille et où le résultat est binaire (vinaigrette ou mayonnaise) est qualifié de processus de Bernouilli.
Ici, au lieu d’avoir une distribution de Bernouilli connue (probabilité d’avoir vinaigrette = % et mayonnaise = (1 - %) = q%), celle-ci est inconnue. L’expérience est également répétée fois; on se retrouve plutôt dans le cas d’une distribution Binomiale à paramètres inconnus.
Pour rappel, la probabilité d’avoir exactement 'succès’ au bout de expériences et est donné par la formule suivante:
Le problème devient inverse. Pour quelle valeur de , la probabilité de nos observations est-elle maximale ? Quelle est la valeur la plus probable pour afin d’obtenir nos résultats. C’est une approche qu’on qualifie d'inférence bayésienne.
En essayant d’optimiser la valeur de par les techniques de maximum likelihood estimator ou celles des moments, nous arrivons à un estimateur qui est également optimal1:
Cela fait sens que le meilleur estimateur de la probabilité que nous avons soit le rapport du nombre de succès () sur le nombre de tentatives réalisées ().
Un intervalle de confiance sur une distribution binomiale peut être donnée par une approximation de la (distribution) normale, aussi appelé "intervale de Wald"2. On a que:
où est le quantile de la distribution normale (95% = 1.96). On retrouve bien la relation étroite qu’entretient la distribution normale et binomiale dans cette relation.
Beta distribution
Mais est-il possible de modéliser la distribution de probabilité la plus probable pour un connu dans le cadre d’une loi binomiale ?
On cherche une distribution telles que:
- elle soit définie entre 0 et 1 (ce sont des probabilités que l’on cherche);
- positive;
- l’intégrale doit être égale à 1;
- la moyenne devrait être proche de notre ;
- ainsi que l’erreur ;
- chaque élément est indépendant et identiquement distribué;
La distribution qui correspond à ces propriétés est la distribution Beta:
Plusieurs remarques:
- est la fonction "Gamma", la généralisation de la fonction exponentielle ();
- est la fonction "Beta", qui peut s’interpréter comme la généralisation des coefficients binomiaux;
- est généralement considéré comme le nombre de succès "+ 1", est le nombre d’échecs () "+ 1". Ces "+ 1" apparaissent notamment à cause de la définition de ces fonctions et ;
- On peut remarquer une très grande symétrie dans cette définition et celle de la Binomiale;
Cette distribution possède plusieurs bonnes propriétés:
- . Si l’on remplace les valeurs de et par nos observations, nous obtenons: qui, lorsque tend vers l’infini, retombe sur notre ;
- . Avec nos valeurs, on a: et à la limite: qui est ce que l’on recherchait;
- Le mode est exactement notre , ce qui tombe bien puisque c’est là où la probabilité est maximale. La moyenne peut être très légèrement décalée par rapport au mode à cause du côté où penche la queue;
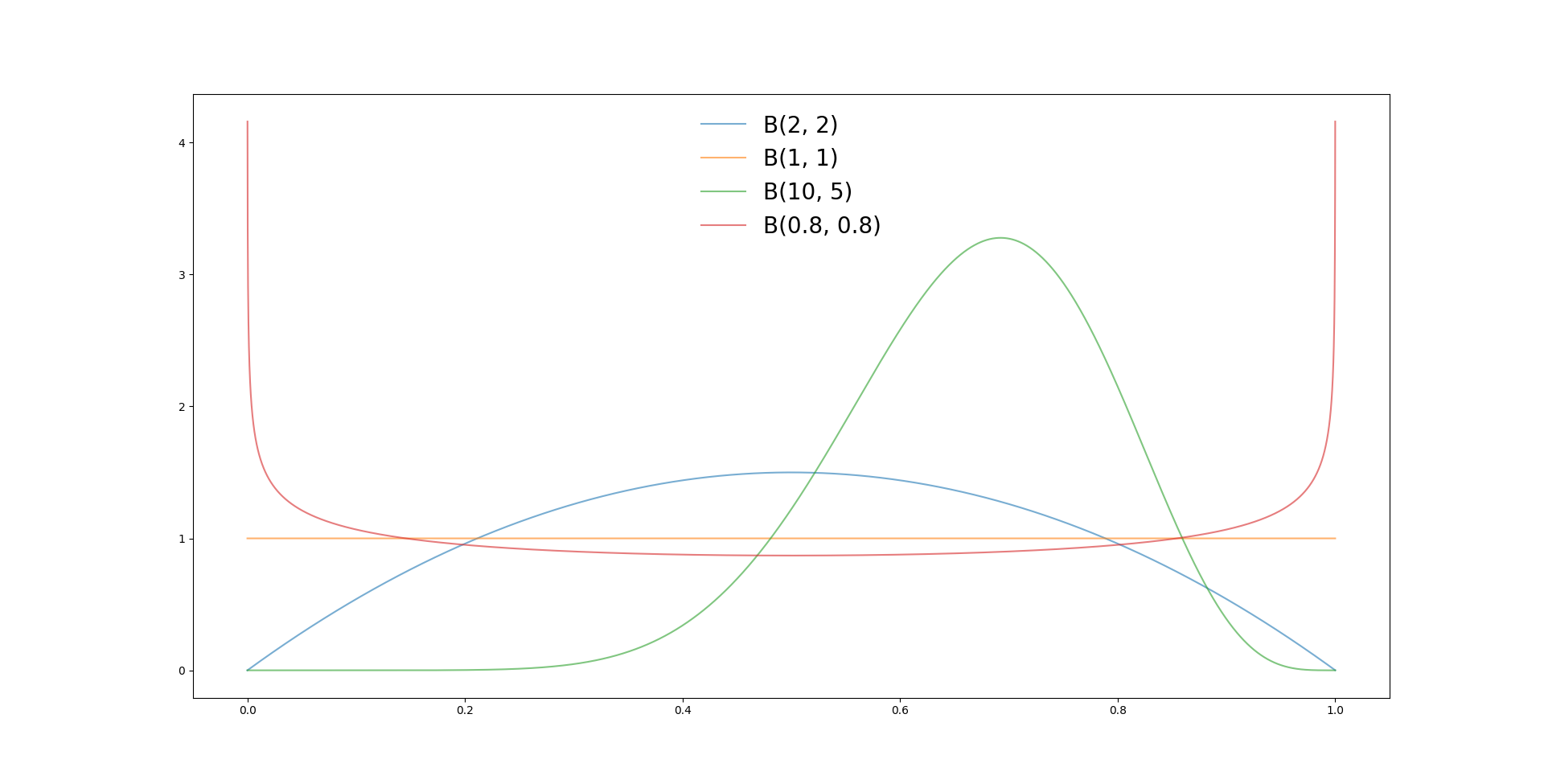
Par exemple, nous voyons que:
- Pour , comme il n’y a eu ni succès, ni échec, la distribution est constante sur tout le domaine. Aucune probabilité n’est préférée a priori;
- Pour , on voit la courbe se centrer à la moitié mais avoir une base relativement large ();
- Pour , on commence à pencher vers une probabilité vers 2/3 et l’on observe un pic bien plus resserré pour cette valeur;
- Lorsque l’on met des valeurs de ou inférieure à 1, les probabilités deviennent très polarisées, très extrêmes;
Vous reconnaîtrez que c’est un outil puissant de statistique a priori, qui permet une analyse bien plus puissante que la donnée brute par elle-même.
Dirichlet distribution
Il est naturel de se demander comment ce concept peut être étendu. Une direction possible est d’étudier sa généralisation à plusieurs variables.
Supposons que vous effectuiez un relevé des causes d’admission à l’hôpital. Vous savez que les gens peuvent se retrouver dans l’une des catégories. Vous vous demandez à quel point ses résultats sont représentatifs de la population. Est-il possible d’obtenir également des marges d’erreur sur notre échantillon ?
On peut définir la distribution de Dirichlet Dir():
où
Cela peut sembler extrêmement barbare à première vue, mais décomposons les morceaux:
- , on définit comme la somme de nos valeurs , nos observations.
- , on retrouve une génération des coefficients multi-nomiaux.
- , toutes nos probabilités .
Attention qu’il faut que toutes nos probabilités soit comprises entre 0 et 1 et que leur somme soit égale à 1 ().
On peut effectuer deux observations:
- Si , on retombe bien sur la distribution Beta.
- Cet ensemble de forme ce qu’on appelle un simplex, la généralisation d’un triangle sur plusieurs dimensions.
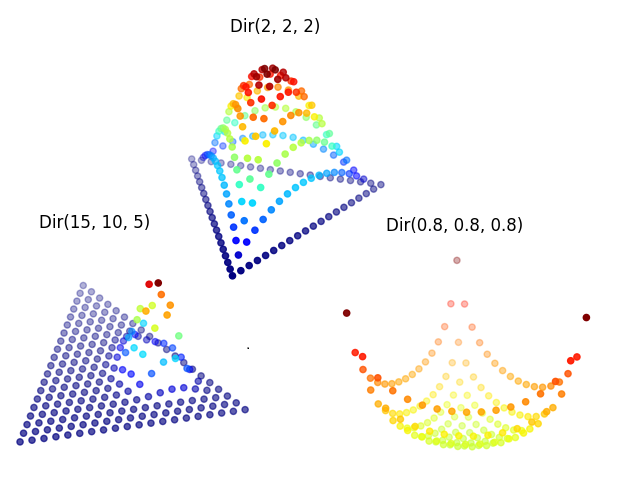
Attention que ces trois distributions font toute l’hypothèse que les évènements sont indépendants et identiquement distribués.
Si l’on pioche au sein d’une boîte contenant un nombre fini de balles, sans remplacement, on obtient:
- Binomiale -> Hypergéométrique
- Beta -> Beta-binomiale
- Dirichlet -> Dirichlet-multinomiale
À noter qu’il y a tout un ensemble de subtilités qui peuvent s’adjoindre à ces notions. Par exemple, il existe la distribution categorical quand les observations peuvent faire partie de catégories. S’intéresse-t-on aux distributions a priori et non a posteriori, sur un échantillon ou sur toute la population ?
Bref, je voulais surtout présenter comment une tentative de réponse à la question des marges d’erreurs sur les résultats obtenus et comment avoir une meilleure idée des paramètres sous-jacents du modèle sur base d’un résultat.