Salut Zeste de Savoir ! Je viens vous partager un projet sur lequel je travaille depuis avril 2019, ArkScript.
Pour la petite histoire : après les échecs de Kafe, j’ai voulu me remettre le pied à l’étrier en me lançant sur un petit langage lisp like, interprété. De là est né Ark (renommé plus tard en ArkScript, cf la discussion sur reddit). Puis je me suis dit "et si cette fois-ci, je le compilais vraiment ce langage?" et au lieu de me lancer dans la VM avant de faire le compilo, j’ai fait les choses proprement, et voilà où nous en sommes.
ArkScript reprend la philosophie originelle de Kafe "scripting de jeux vidéos", mais c’est tout, les autres points sont bien différents. Petit à petit cette philosophie a évolué en "un langage facile à utiliser pour scripter n’importe quel projet en C++".
Concepts et objectifs
En bref :
un langage immuable par défaut (passage par valeur),
un langage fortement et dynamiquement typé,
pas de références cachées à la Python avec les listes,
très peu de mots clés (9),
des closures à capture explicite,
privilégier les features avant les performances,
élimination de dépendance cycliques,
processeur de macros Turing Complete,
élimination de dead code,
de l’asynchrone avec n’importe quelle fonction,
ArkScript est inspiré de Lisp (entre autre pour la facilité à le parser), tout est immuable par défaut, et tout est passé par valeur. Cela représente un coût à l’exécution, coût que je suis prêt à payer (cependant toutes les fonctions travaillant sur des listes évitent le plus possible les copies, sans pour autant impliquer des références cachées comme le ferait Python). L’objectif du projet n’est pas d’être plus performant que du C bien fait, mais de privilégier les features (même si j’ai travaillé un peu sur les performances pour ne pas rester en rade), de manière à être plus productif quand on code avec ce langage.
Je voulais que le langage tourne sur VM pour le gain de performance comparé à une interprétation d’un arbre, et pour la portabilité: on compile une fois un code Ark et il marche partout tant que la VM est installée.
Le parsing se veut très simple, étant un lisp like il n’y a pas grand chose à faire. La partie la plus complexe, c’est le couple compilateur/VM, car il faut faire pas mal de choses pour fournir un langage haut niveau. On a donc de l’élimination de dépendances cycliques au parsing, de la réduction d’expressions constantes par le compilateur ainsi que de l’élimination de dead code (au scope global uniquement) et des expression statements (ce qui permet de ne pas polluer la VM avec des valeurs inutilisées). Le tout est saupoudré d’un processeur de macros Turing Complete (on peut faire des macros récursives, co-récursives, etc).
Le langage est dynamiquement et fortement typé, et autorise les listes hétérogènes. De plus, il n’y a aucune référence cachée que l’utilisateur peut manipuler, ce que je trouve très important pour conserver cet aspect d’immuabilité quand on déclare une variable avec let. En interne, côté VM, des références sont utilisées mais n’atteindront jamais l’utilisateur telle quelle et verront leur valeur copiée au moment voulu (copy on write) uniquement.
Enfin, ArkScript se veut concis et n’a que 9 mots clés à offrir: let, mut et set pour les constantes/variables, begin pour les blocks, if et while pour le contrôle de flux, del pour vider la mémoire manuellement (ArkScript profite également du RRID du langage d’implémentation, le C++), import qui permet d’importer du code Ark et des binaires qui utilisent une API spéciale (par exemple pour charger la SFML, manipuler la console…), et fun pour déclarer une fonction ou closure (à capture explicite).
Le langage se veut petit pour être utilisable dans un projet sans plomber la taille de celui-ci, la machine virtuelle tient sur moins de 3000 lignes (en comptant tous les fichiers des dossiers VM/). Voir ce benchmark d’octobre 2020 qui compare ArkScript 3.0.13 à d’autres langages dont ChaiScript, Lua et Python.
Un écosystème de plugins
Le langage se veut extensible, et pour ça il expose une API pour créer facilement un plugin C++, qui peut être chargé par la machine virtuelle, par exemple pour :
Un petit exemple qui utilises les closures avec la capture explicite (via la notation &capture), le closure field reading (dot notation) pour simuler de l’orienté objet (sans possibilité de modifier l’objet de l’extérieur, tout est en lecture seule quand on n’est pas dans la closure):
(let create-human (fun (name age weight) {
# functions can be invoked in the closure scope
(let set-age (fun (new-age) (set age new-age)))
# this will be our "constructor"
(fun (&set-age &name &age &weight) ())}))
(let bob (create-human"Bob"0144))
(let john (create-human"John"1215))
(print bob.age)
(bob.set-age10)
(print bob.age)
(print john.age)
La fonction d’Ackermann Péter qui me sert pour mes benchmarks comme elle est récursive non primitive, donc pas optimisable par un compilateur, très pratique pour tester l’implémentation d’un langage:
(let ackermann (fun (m n) {
(if (> m 0)
(if (=0 n)
(ackermann (- m 1) 1)
(ackermann (- m 1) (ackermann m (- n 1))))
(+1 n) )}))
(print (ackermann36))
Les releases sont disponibles ici (la lib standard est fournie avec chaque release, ainsi que les modules en .arkm).
une équipe qui grossi ! J’étais seul quand j’ai fait le premier post, et maintenant nous sommes 6
un code plus clair, qui sépare exécution (VM) et données (State)
un REPL (la sauvegarde de scope est en train d’être faite par un de nos contributeurs)
une bibliothèque standard qui grossi de jour en jour
des améliorations notables en terme de performance
toujours plus de détections d’erreurs, essentiellement sur les importations cycliques, mais aussi des erreurs plus claires au runtime
Le langage est désormais suffisamment mature pour que l’on puisse coder un forEach directement en ArkScript, sans toucher au code C++, et ça c’est beau quand même
(let forEach (fun (L code) {
(mut i 0)
(while (< i (len L)) {
(mut element (@ L i))
(code)
(set i (+1 i))})}))
(forEach [1234] '{
(print element)})
Déjà, une migration sur https://github.com/ArkScript-lang/ ! Dans le futur plus de dépôts vont s’y retrouver dont un gestionnaire de modules pour ArkScript qui est envisagé depuis un moment maintenant. Les modules ont été migrés sur un dépôt séparé pour plus de visibilité.
L’API a suffisamment évolué pour permettre l’appels de fonctions Ark depuis un module (mis en œuvre dans le module HTTP qui permet de faire des requêtes get/put/delete et bien d’autres, mais aussi de mettre en œuvre des serveurs web (toujours en développement)).
Qui lance un serveur qui affichera we got: 'test', it worked! (pour le moment le seul argument passé est un "test", dans le futur on peut imaginer envoyer les valeurs d’une requête GET par exemple.
En espérant bientôt vous revoir, et pourquoi vous reparler sur le serveur discord du projet si vous souhaitez contribuer !
Mais je suis porteur de beaucoup de bonnes nouvelles
Tout d’abord, le projet est maintenant dans une organisation dédiée: https://github.com/ArkScript-lang, sur laquelle on a donc le langage en lui même, les modules de bases (en C++), ArkDoc (un doxygen maison pour documenter du code ArkScript), le code source du site de présentation et de la documentation.
Ensuite, nous sommes maintenant 10 à travailler sur ArkScript, dont 3 contributeurs très actifs.
Les avancées sur le projet concernent essentiellement des mises à jour interne à la machine virtuelle et au compilateur, pour la rendre plus rapide (d’où la prolifération de branches orientées optimisations). Une bonne nouvelle est qu’une allocation de liste de 1000 éléments (125 essais) prenait 75µs, seulement 15µs maintenant, et l’usage mémoire global a été diminué. Le compilateur est bien plus rapide également, compiler 10k lignes de code ArkScript prend 14 secondes, contre plusieurs minutes auparavant (le couple lexer/parser va être amélioré pour faire descendre ce nombre encore plus bas).
La lib standard a légèrement été modifiée pour des conventions de nommage et de code mais rien de nouveau de ce côté, justement on attend vos retours, vos cas d’usages, vos questions sur le langage pour l’améliorer!
Alors n’hésitez pas à essayer le langage, il est suffisamment stable pour être utilisé en lieu et place de Lua ou Python par exemple!
Tiens ça m’intéresse ça les perfs de ton lexer, t’es à combien et t’utilise quelle méthode ?
Jsuis à 286ms pour 6M de lignes et une sortie de 2M de tokens.
J’en suis très loin, pour 10k lignes de code ArkScript tout le processus lexer / parser / compiler prend 14 secondes, je vais écrire des benchmarks pour voir.
Actuellement on bosse sur une amélioration du REPL (outil en ligne de commande pour tester ArkScript vite fait, comme l’interpréteur Python) avec coloration et complétion, et on nettoie les projets pour éviter qu’un git clone ne traine 6000 dépendances inutiles avec lui.
Jusqu’ici on a pu améliorer les performances de la VM de façon significative en diminuant la taille de Ark::Value, le type de base traité par la VM, et on retravaille le site web et la documentation (le wiki étant voué à disparaitre). On a également (enfin) un dépot séparé pour les benchmarks: https://github.com/ArkScript-lang/benchmarks, n’hésitez pas à y contribuer !
(06/07/2024) Ce post inclut un élément de syntaxe disparu dans la v4 (str:format %% est devenu {}, en suivant la syntaxe de fmtlib.dev)
Salut !
On a donc un nouvel interpréteur (REPL) qui a de la persistance entre chaque ligne tapée (avant chaque morceau de code exécuté était oublié dès qu’on tapait un nouveau code), de la coloration et de l’auto complétion, le tout en utilisant la lib replxx (en C).
Ensuite, j’ai récemment ajouté l’élimination de dead code (au scope global uniquement) pendant la compilation, on a un lexer fait maison sans regex et bien plus rapide (et qui gère enfin les séquences d’échappement, bien que je doive trouver un moyen de faire fonctionner les séquences \u \U et \x), un meilleur chargement des plugins (dynamique et non statique désormais, donc on peut faire de l’importation conditionnelle en fonction de l’OS par exemple).
Aussi, niveau usage mémoire, les plugins ajoutant des objets à ArkScript (eg une fenêtre SFML) peuvent désormais voir ces objets détruits en bonne et due forme quand le scope dans lequel est l’objet est détruit.
Niveau fonctionnement interne, la nouvelle string s’est dotée d’une fonction de formatage template, donc str:format a également été impacté. Eg: (str:format "test % something %% %% 0x%x the end %% ok" 256 "hello" -12345 3735928559) donnera test something hello -12345 0xdeadbeef the end %% ok. Si on donne trop d’arguments et pas assez de séquences %%, ils ne seront pas utilisés, si on en donne pas assez, les %% resteront tels quels, permettant de faire un formatage en plusieurs étapes. Ainsi exit les segfault/undefined behavior sur un printf("%s hello %i", "world").
Niveau lib std, elle a bougé sur un nouveau dépôt pour qu’on puisse l’update sans toucher au dépôt principal, on est en train de faire une grosse passe de documentation et renommage pour clarifier pas mal de choses, avec des noms de variables de type namespace:fonction, eg: list:reverse. Tant qu’on n’a pas de macro, le namespace sera obligatoire et non modifiable, car il fait parti à 100% du nom de la variable/constante.
Niveau erreurs, on a de meilleurs messages d’erreurs pour indiquer où on s’est trompé (au lexing et parsing, compilation et VM également).
Au lexing/parsing on aura quelque chose comme:
main:007> (if)
class Ark::ParseError: ParseError: no more token to consume
On line 1:59, got TokenType::Grouping
1 | (if)
| ^
2 | no more token to consume
Ark::State::doString failed
Dans la VM, on a de meilleurs messages quand une variable est inconnue / inutilisable ou quand on a des soucis d’importation:
main:001> (print a)
unbound variable: a
At IP: 2, PP: 0
main:001> (let a 12) (print (a))
Can't call 'a': it isn't a Function but a Number
At IP: 11, PP: 0
main:012> (import "blabla")
could not load plugin: blabla
At IP: 44, PP: 0
main:013> (import "blabla.ark")
class std::runtime_error: While processing file FILE, couldn't import blabla.ark: file not found
Ark::State::doString failed
Après quelques mois sans nouvelles, je reviens pour la hacktoberfest.
Jusqu’ici le bilan est plutôt positif, on a des contributeurs qui travaillent bien sur le package manager, nuclear (en Python), et on a reçu quelques PR sur le langage lui même (correctifs de bugs surtout).
Niveau versions, on a sorti la 3.0.12 récemment, qui amène son plus gros lot de nouveautés.
Changelog:
Added
using a macro to define the default filename (when none is given, eg when loading bytecode files or from the REPL)
PLUGIN <const id> instruction to load plugin dynamically and not when the VM boots up
updated search paths for (import "lib.ark"), looking in ./, lib/std/ and lib/
added a case to display NOT instructions in the bytecode reader
T& as<T>() in usertype
enhanced error message when calling a non-function object
eliminating unused global scope variables in the compiler
adding a new feature enabled by default: FeatureRemoveUnusedVars (not enabled for the REPL | for obvious reasons)
added replxx as a submodule
added custom destructor to the user type, called when a scope is destroyed and when we use (del obj)
added a GVL (global virtual machine lock) to be able to use the VM in a multithreaded context
dockerfile + specific github action to build and push stable and nightly docker images, thanks to @yardenshoham
added guards to the bytecode reader to stop reading if we’re missing an entry point; now telling the user about it
Changed
updated the string module to benefit from the new format member function
updated the logger to remove fmt/format
changed the argument order for Ark::State
renamed the cache directory __arkscript__
operator @ can now handle negative indexes to get elements from the end of the given container
the standard library is now in another repository
moved the modules to lib/ext
the value of CODE_SEGMENT_START is again 0x03 (because we removed the plugin table)
renamed isDir? to dir? for consistency
the lexer is no longer using regexes but a char after char method
an ArkScript program is no longer a single bloc, but can be composed of multiple bloc, thus we don’t need to use a single big {} or (begin) bloc for all the program
enhancing lexer and parser error messages
else clause in if constructions is now optional
updating error messages in the VM
updated the repl to add auto completion, coloration and persistance by @PierrePharel
moving the parser, lexer and AST node to Compiler/ from Parser/
better import error messages at parsing
format can now handle any value type
updated the tests to use the new standard library, and testing every VM instruction and builtins (we didn’t test everything before, this way we can be sure we don’t break anything in the VM after each update)
renaming builtins to add a namespace to them (math:, sys:, str:, list: and such)
firstOf, tailOf and headOf now returns [] or "" instead of nil when they have nothing to do
adding a brand new scoping system, lighter, more powerful
str:find now returns the index where the substring was found
str:removeAt was fixed to throw an error when the index is strictly equal to the length of the string (can not work since accessing elements in string is 0-index based)
Removed
removed fmt/format from our dependencies
PLUGIN_TABLE was removed to use the PLUGIN instruction
not_() from usertype
removed Parser/Utf8Converter
A par ça, on est en train de stabiliser quelques modules, qui seront installables via le package manager, on rajoute des tests (toujours plus car trop c’est jamais assez), et on table sur un rewrite complet de la VM pour aller vers de nouvelles pistes d’optimisations.
En gros tout va pour le mieux, on attire des contributeurs et des utilisateurs, et ça c’est génial
(06/07/2024) Ce post inclut un élément de syntaxe disparu dans la v4 (macro: !{name val} -> ($ name val))
Hello, ça faisait longtemps, me revoilà avec de bonnes nouvelles!
On bosse toujours beaucoup sur le langage avec au programme: de l’UTF8 (pour les strings et peut être les identifiers), très bientôt des macros avec gestion des arguments variadiques, diverses optimisations, et on est train d’agrandir la lib standard et les modules.
Les deux ans du projet c’est fin avril, d’ici là j’espère avoir fini le support des macros qui devront permettre de faire autant voir plus que le préprocesseur C:
!{name 12}
!{if (= name 12)
!{a (...args) (print args)}
!{a (...args) (print "no")}}
!{foo (a b c) {(let a 12) (let b 12) (let c 12)}}
Avec possibilité d’appeler une macro depuis une autre pour un peu plus de piment.
Une des plus belles optimisation est un passage (en interne) sur une stack linéaire unique plutôt qu’une stack de stack, ce qui nous a fait passé de 90ms à 55ms sur Ackermann Péter (3, 6), un test de récursion extrêmement gourmand. On reste loin de Python mais le but n’est pas de le rattraper/dépasser, simplement d’être suffisant rapide pour être utilisable convenablement.
Bonjour, cela faisait longtemps que je n’avais pas posté ici, j’ai trop négligé la communication pour me concentrer sur le code et les cours.
Les avancées
Depuis le dernier message, le projet a subit moulte refacto:
210 fichiers modifiés,
11’273 lignes ajoutées,
8’065 lignes supprimées (pas assez à mon goût)
Dans les grandes lignes, le projet a été remanié pour faciliter son intégration dans d’autres projets, et également envisager un publication sur les dépôts d’Arch Linux. Nous avons rajouté de nombreux tests, que ce soit dans le langage ou en C++, pour pouvoir continuer à garantir le fonctionnement du langage et de son intégration dans des projets en C++ (une interface C est envisagée).
Je me dois également de dire que le macro processor fonctionne depuis que j’avais annoncé son existence. Beaucoup de bugs y ont été trouvé, mais un nouveau développeur nous a rejoint et nous a grandement aidé pour les résoudre, en améliorant la structure du dit macro processor.
Grande nouveauté aussi, l’intégration de fonctions qui travaillent explicitement par référence: append!, concat! et pop! (et leurs équivalents sans !). Ces fonctions sont utilisées pour travailler sur des listes, qui sont autrement copiées autant de fois que nécessaire quand on utilise les versions safe (sans !), qui retournent toutes une nouvelle liste créée à partir de leurs arguments. Les fonctions unsafe (dans le sens "casse l’immutabilité du langage") prennent en argument des références sur objets mutables (donc (append! [1 2] 3) est invalide), modifie leur argument (le premier, les autres peuvent être des copies/références (non) mutables) in place et retourne toujours nil.
Aussi, nous avons fait le grand saut et défini un clang-format pour avoir un code formatté de manière unique, et facilement lisible par toute l’équipe (qui varie entre 4 et 6 personnes qui sont là de manière permanente). La CI a été revue et nous permet maintenant de générer des binaires pour Windows, Linux, et MacOS, sachant qu’un InnoSetup est créé pour les versions Windows désormais.
Notre génération de documentation, ArkDoc a été entièrement recodé en Python et nous permet de sortir plusieurs formats (HTML, Markdown (encore en cours, mais en soit ce n’est pas trop compliqué, si un jour je m’y mets)) : https://arkscript-lang.dev/std/ (qui redirige en théorie vers la dernière version de la documentation).
Ce qui est prévu pour le futur
un refactor de la machine virtuelle, pour permettre un ajout plus simple de parallélisme
l’élimination d’un side-effect d’une VM à pile : le trashing: (while true 1) va pousser la valeur 1 sur la pile à l’infini et on peut l’empêcher en modifiant notre compilateur mais ça n’est pas trivial
améliorer notre REPL (plus de contrôles, accès à la documentation directement)
amélioration des erreurs de type pour aider l’utilisateur
réécriture du package manager, qui n’a jamais été testé ni utilisé bien qu’il soit considéré comme "fini"
On a encore (et toujours) beaucoup de travail, mais on approche de quelque chose qu’on pourrait considérer comme "fini" (plus dans le sens "complet, qui marche bien" que "terminé" cependant).
Le projet est toujours vivant, je manquais simplement de contenu pour faire un nouveau post ici.
Entre aujourd’hui et le dernier post, en prenant compte uniquement de la branche de dev, un petit refacto du projet est passé :
88 fichiers modifiés,
3093 lignes ajoutées,
1991 supprimées
J’ai bien précisé la branche de dev, parce qu’une petite nouvelle est apparue, qui vise spécifiquement la prochaine grosse release, ArkScript 4.0 ! Au programme on a :
de meilleures erreurs de types (déjà disponibles en 3.1.3),
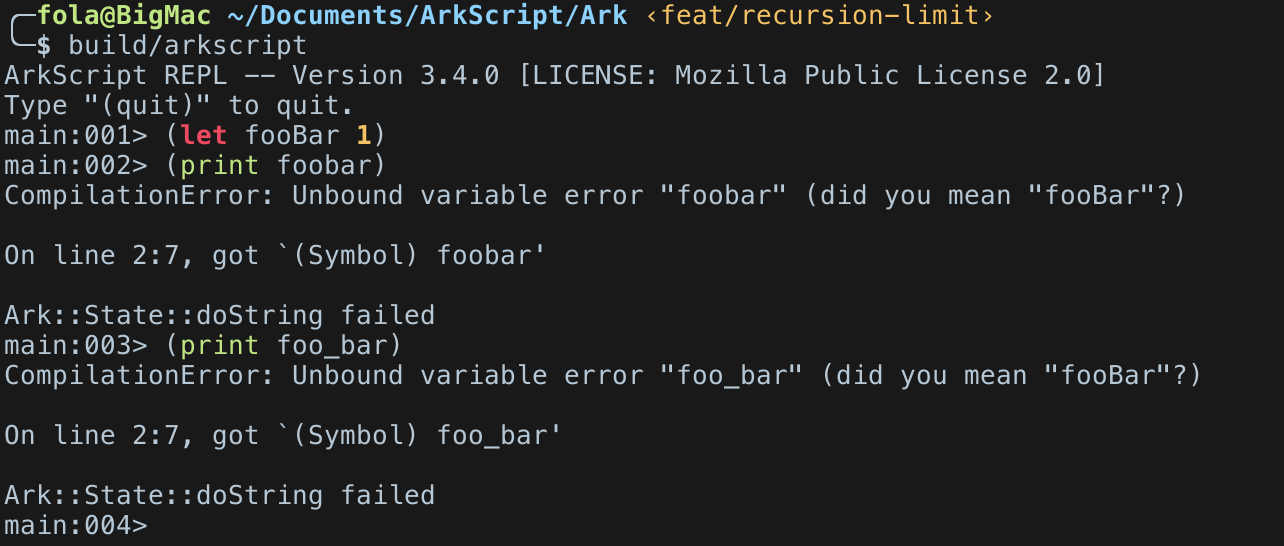
la suggestion de symboles proches quand on tombe sur un unbound symbol pendant la compilation (3.2.0),
la conversion de closures en chaine de caractères avec leurs champs,
l’ajout d’async/await en tant que builtins,
la gestion des unused expressions qui polluaient la stack (dont je parlais dans le précédent post, disponible en 3.2.0),
l’optimisation de tail call (3.2.0) quand une fonction s’appelle elle-même (sera généralisé en 4.0),
plein de correctifs de petits bugs ennuyeux
On peut voir le travail effectué depuis l’an passé comme du nettoyage et un peu d’house keeping, les vacances étant arrivées pour une partie de l’équipe, le développement ralenti un peu. Cependant on prévoit des améliorations géniales pour le reste de l’année, entre la génération d’un AST sous forme de JSON (utile pour faire un LSP, écrire des tests pour le lexer/parser/optimiseur/macro processeur, pour avoir un nouveau backend qui transpile en WASM ou autre…), du fuzzing pour détecter le plus d’erreurs possibles dans l’implémentation du langage.
La documentation du langage continue d’évoluer et de s’améliorer, si vous avez des remarques, des questions ou mêmes des suggestions n’hésitez pas !
(let size 1000)
(let data (list:fill size 1)) # une liste de remplie de mille 1
(let sum (fun (a b src) {
(mut acc 0)
(while (< a b) {
(set acc (+ acc (@ src a)))
(set a (+1 a))})
acc
}))
(let workers [
(async sum 0 (/ size 4) data)
(async sum (/ size 4) (/ size 2) data)
(async sum (/ size 2) (- size (/ size 4)) data)
(async sum (- size (/ size 4)) size data)])
(let res-async
(list:reduce
(list:map
workers
(fun (w) (await w)))
(fun (a b) (+ a b))))
proposition de variable et coloration des erreurs
(let make (fun (a b c)
(fun (&a&b&c) ())))
(let foo (make123))
(print foo) # output: (.a=1 .b=2 .c=3), avant: Closure<4>
functionName: needs argumentCount argument(s), got actualArgumentCount.
-> arg1Name (wanted type) was arg1Value (of type arg1Type)
-> arg2Name (wanted type) was arg2Value (of type arg2Type)
Depuis le dernier message, j’ai pris du temps pour travailler sur les messages d’erreurs du langage, pour mieux aider les utilisateurs quand une erreur survient, ainsi que plus de warnings à la compilation:
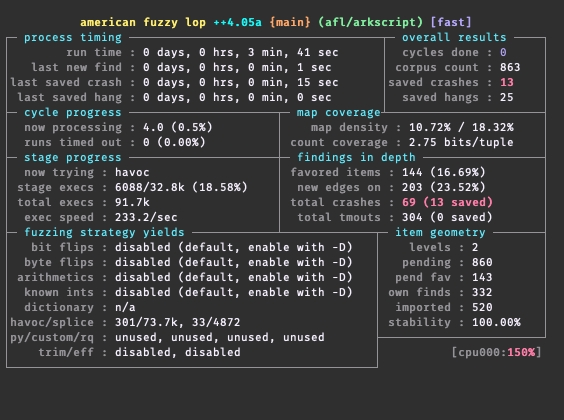
J’ai commencé la chasse aux bugs en intégrant AFL++, un fuzzer très pratique qui m’a remonté pas mal de bouts de code capables de faire planter le lexer, parser, macro processor, rarement le compilateur, et de temps en temps la machine virtuelle. Bref, que de la joie, mon appart est bien chauffé au moins, et j’ai du travail jusqu’à la fin de l’année.
une instance du fuzzer en action
Pour donner quelques chiffres:
6 instances du fuzzer ont tourné, chacune pendant 1 heure
le load average est monté à 12 (sur un Xeon à 8 coeurs/16 threads c’est pas mal)
l’usage de RAM était capé à 64MB par instance
une moyenne de 500 crash remontés par instance
une moyenne de 1000 hangs remontés par instance (il est fort pour générer des (while true ()) et similaire)
la température CPU qui a grimpé de 45° à 80°, et celle de mon appart de +2° (qui a besoin de chauffage ?)
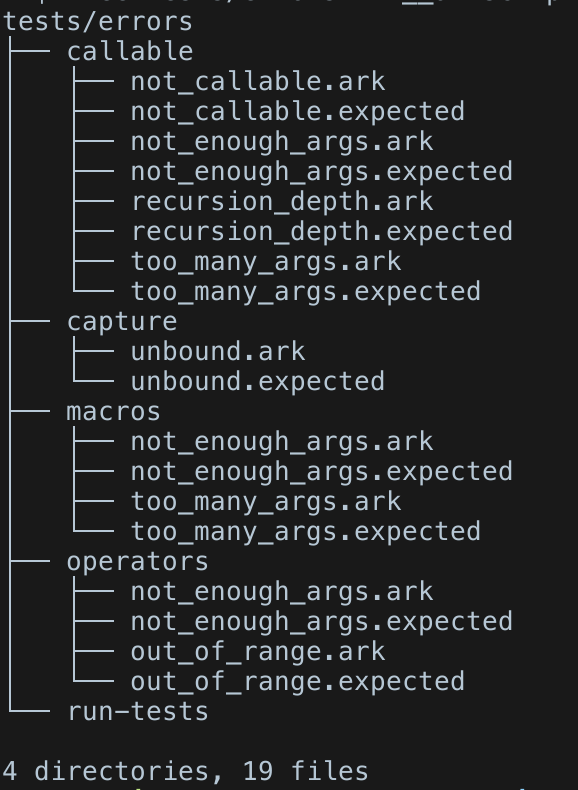
J’ai dû fixer une petite dizaine de bugs grâce à ça, c’est fastidieux mais très intéressant. En partant des crash remontés, j’ai donc commencé une collection de "code qui plante mais ça doit être détecté".
quelques tests d’échecs
Et un test est un couple de deux fichiers:
# input.ark
(())
# input.expected
TypeError: A Nil isn't a callable
Côté avancement sur la v4, j’ai réécrit des bouts du compilateur et nettoyé le code pour le rendre plus simple à lire, et terminé l’intégration du nouveau format de bytecode, où chaque instruction est sur 4 bytes ce qui rend le peeking bien plus facile.
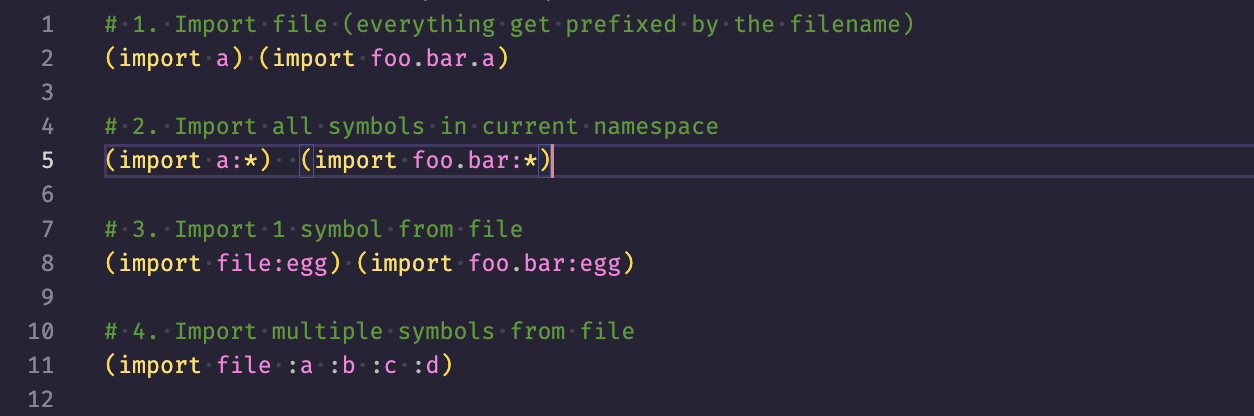
Une nouvelle syntaxe pour les imports est également prévue:
Les plus attentifs auront remarqué que cette syntaxe va empêcher l’inclusion de scripts de dossiers parents, ce qui était actuellement possible avec un (import "../file.ark"). Je pense que c’est un moindre mal qui poussera à réfléchir un peu plus à la structure d’un projet, mais pour autant ça ne devrait pas être catastrophique.
Cependant, cette nouvelle syntaxe n’est pas figée dans le marbre. Bien que le sens actuel de (import folder.foo.bar) soit "importe folder/foo/bar.ark depuis le dossier du script actuel", il est possible que cela soit réévalué pour suivre les packages à la Scala.
Ainsi, si on exécute main.ark, qui import foo/bar.ark, et que ce dernier veut faire un (import bacon.yellow.color), on chercherait bacon/yellow/color.ark à partir du dossier d’exécution de main.ark et non du dossier où est présent bar.ark.
En dehors de ces améliorations de la QoL, cela fait bientôt deux semaines que je travaille à l’élaboration d’un nouveau parser pour le langage, dont vous pouvez trouver la source sur GitHub: https://github.com/SuperFola/parser-combinators. En effet le lexer/parser actuel est difficilement maintenable, presque impossible à faire évoluer sans casser quelque chose, et sûrement bourré de bugs que je n’ai pas encore trouvé.
C’est pour ça que j’ai tenté une approche parser combinators, et le résultat est là, 2 fois moins de code, 2 fois plus simple à lire, des performances que je considère comme correcte (je dois mesurer le parser actuel pour pouvoir comparer cependant). Pour couronner le tout, 0 warning (Wall, Wextra, Wconversion, Wshadow et pedantic, je suis fou), 0 fuite de mémoire, des tests dans tous les sens et bientôt du fuzzing.
Running ./build/bench
Run on (8 X 24.121 MHz CPU s)
CPU Caches:
L1 Data 64 KiB
L1 Instruction 128 KiB
L2 Unified 4096 KiB (x8)
Load Average: 1.29, 1.69, 1.91
------------------------------------------------------------
Benchmark Time CPU Iterations
------------------------------------------------------------
Simple - 39 nodes 0.067 ms 0.067 ms 103688
Medium - 83 nodes 0.395 ms 0.395 ms 17430
Big - 665 nodes 31.9 ms 31.8 ms 224
Cela fait maintenant 581 jours que je n’ai pas donné de nouvelles ici. Entre temps, c’est environ 21880 lignes ajoutées et 18238 supprimées dans divers refacto, réparties en 202 commits (l’année 2023 a été très vide, le travail a repris en début d’année 2024)!
Un parser? Encore?
Pour reprendre la fin du dernier message, le nouveau parser a été intégré à ArkScript de façon définitive, et l’ancien décommissionné. L’intégration a été plus facile que prévue si mes souvenirs sont bons, beaucoup de code laid et dur à maintenir ayant disparu.
Et par dessus le marché, ces derniers mois j’ai pu optimiser un peu plus ce parser, qui prenait un temps fou à calculer la position du curseur dans le fichier (pas si facile que garder un compteur comme on revient souvent en arrière, cf le monstre qui aide à positionner les sauts de ligne). Ce qui nous donne les perf suivantes:
---------------------------------------------------------------------------
Benchmark Time CPU Iterations
---------------------------------------------------------------------------
New parser - Simple - 39 nodes/0 0.045 ms 0.045 ms 15421 nodesAvg=92.526k nodesRate=132.633k/s uselessLines/sec=265.266k/s
New parser - Medium - 83 nodes/1 0.126 ms 0.126 ms 5514 nodesAvg=55.14k nodesRate=79.4941k/s uselessLines/sec=198.735k/s
New parser - Big - 665 nodes/2 1.66 ms 1.66 ms 422 nodesAvg=8.018k nodesRate=11.4657k/s uselessLines/sec=191.9k/s
(sur exactement le même matérial, un Mac M1 Pro à 8 coeurs et 32Go de RAM)
La syntaxe des macros évolue
Auparavant on avait une syntaxe pas très belle et pas logique:
!{name 12}
!{if cond then else}
!{func (arg arg2) body}
Maintenant on utilise la même syntaxe que le reste du langage avec un token magique, $:
($ name 12)
($if cond then else)
($ func (arg arg2) body)
Et on a de nouvelles primitives comme $repr pour obtenir une string d’un noeud au compile time, symcat pour concaténer des symboles (utile dans des macros récursives définissant des variables temporaires), argcount pour avoir le nombre d’arguments d’une fonction. (il va falloir uniformiser les noms pour qu’ils commencent tous par $, c’est dans mon backlog).
Note
On pourrait utiliser un pattern matching pour extraire le nombre d’arguments d’un noeud, mais ça reste quelque chose de complexe à implémenter, et pour le moment le besoin ne s’en fait pas assez sentir. Ce qui est sûr c’est que ça serait vachement cool à implémenter, ne serait-ce que pour l’expérience, mais vu l’état du macro processor, ça va attendre encore un peu.
Toujours plus de benchmarks
Comme j’aime les nombres et stats en tout genre, j’ai décidé d’ajouter plus de benchmarks l’an passé, avec des bench pour la VM que je peux lancer sur ma machine, et sortir des CSV. Ajouter une pincée de Python et je peux suivre les évolutions de perf à chaque commit si je le souhaite, pour traquer de potentielles régressions. Plutôt cool non?
On peut voir l’évolution entre plusieurs commits ici, avec les pertes en ms et % entre chaque commit et la base (le 0–684ea758), successivement:
Pas trop mal, mais j’aimerai automatiser tout ça… C’est pourquoi maintenant des benchmarks sont lancés par la CI à chaque commit sur dev. Rassurez vous, je ne regarde pas le temps, les environnements de CI étant non reproductibles, mais les ratios entre ArkScript et d’autres langages, et on peut visualiser le tout sur le site : https://arkscript-lang.dev/benchmarks.html.
Le passage en C++20
Par la suite, je me suis dit qu’il était grand temps de passer en C++20 (aussi parce que je voulais intégrer boost-ext/ut qui est en C++20), et j’ai pris sur moi de moderniser le code (ranges & views, ça rend le code bien plus clair).
En même temps, je suis finalement passé sur CLion, et je crois bien que ce fut la meilleure décision de ma vie. L’intégration avec clangd est bien meilleure que VSCode et IntelliSense, même si CLion mange la RAM comme je mange des donuts… (promis, ce post n’est pas sponso, simplement avoir un debugger qui ne me montre pas juste l’asm, ça change la vie ; et pouvoir placer des breakpoints aussi).
Le plus dur dans cette migration aura été d’adapter la CI pour avoir des compilateurs supportant le C++20 (le support de gcc < 13 et clang < 15 a donc été droppé).
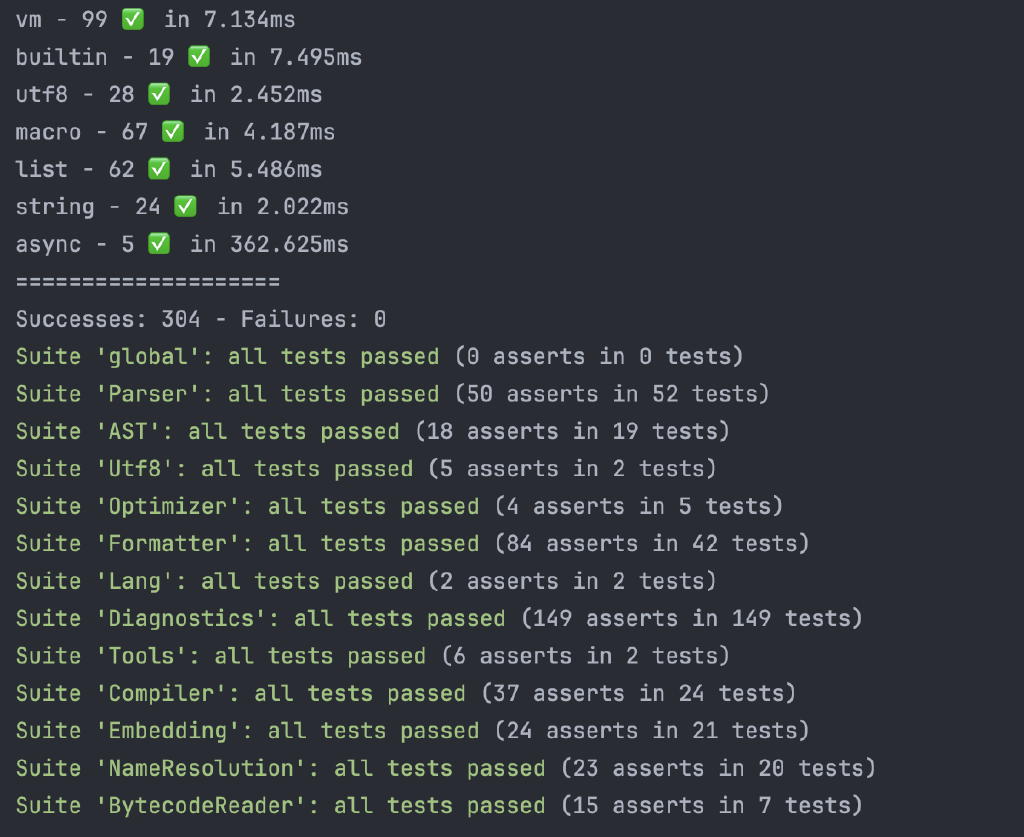
Des tests, en veux tu en voilà
Ayant la tête dans la CI, je me suis aussi mis à écrire beaucoup de tests, en C++ cette fois, pour tester le parser, le bytecode reader, la VM, l’embedding VM+State, … et honnêtement c’est tout con et facile à lire, regardez moi cette simplicité :
Pour un output très clair et un error reporting (quand ça plante, ce qui maintenant arrive rarement) sympa:
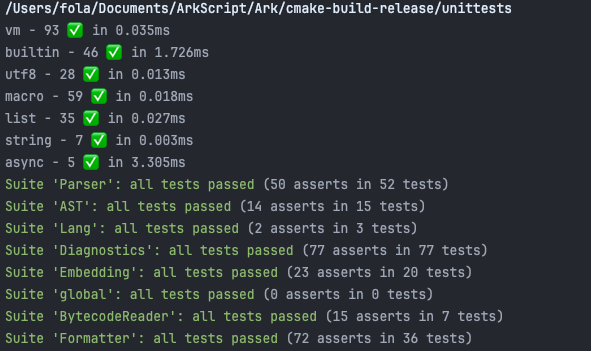
Suite 'global': all tests passed (0 asserts in 0 tests)
Suite 'BytecodeReader': all tests passed (15 asserts in 7 tests)
Suite 'AST': all tests passed (14 asserts in 15 tests)
Suite 'VM': all tests passed (18 asserts in 15 tests)
Suite 'Parser': all tests passed (50 asserts in 52 tests)
Suite '*hidden*': all tests passed (64 asserts in 32 tests)
Fuzzing
J’ai aussi continué le fuzzing, et je suis content de vous dire que je fuzz approximativement 3 fois plus vite qu’avant grâce à un meilleur parser et des optimisations bien ciblées (et toujours alimentées avant par des benchmarks et du profiling) !
A l’heure où j’écris, il me reste ~64 erreurs (dont certaines se recoupent, d’où l’utilité du script python pour trier rapidement les fausses erreurs (aka ArkScript qui remonte une erreur) et les vraies erreurs (un sanitizer qui remonte un problème), en étant parti de 400+ erreurs en 4 heures de fuzz testing!
Grâce aux fuzzers, la base de tests s’enrichit également, car on teste aussi les erreurs et leur reporting maintenant, pour s’assurer qu’on ne fait pas réapparaitre une erreur et que tout est toujours géré correctement : https://github.com/ArkScript-lang/Ark/tree/79bfe1f596b5a17ed4a684191adf0addd3507d25/tests/errors (organisés par catégorie d’erreur, avec un fichier .ark et un .expected pour le bout de message d’erreur que l’on attend, j’en suis plutôt fier).
De meilleurs rapports de tests pour ArkScript
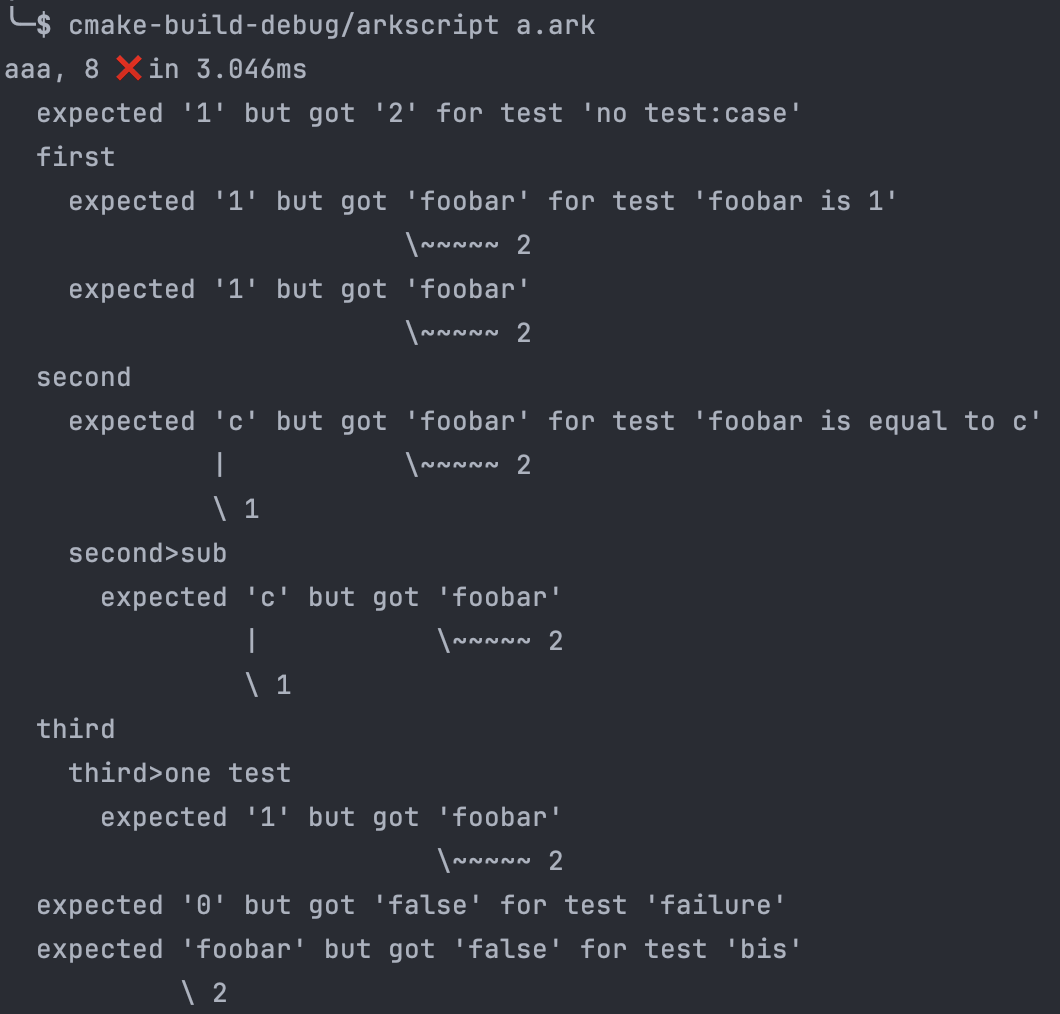
Je n’aimais pas avoir des assert en ArkScript, car les tests plantaient immédiatement. Il fallait les corriger un à un et le reporting était laid, puis tout relancer. Inspiré par mockito en Scala, j’ai donc conçu une lib de tests en ArkScript, pour ArkScript. Voyez donc:
(import std.Testing)
(test:suite aaa {
(mut foobar 2)
(test:eq12"no test:case")
(test:case"given an explicit expected value" {
(test:eq1 foobar "foobar is 1")
(test:eq1 foobar)})
(test:case"given a computed expected value" {
(let c 1)
(test:eq c foobar "foobar is equal to c")
(test:case"nested case"
(test:eq c foobar))})})
Ce qui reporte ceci :
Exécuter du code ArkScript… en ligne?
Quoi de mieux qu’un playground pour tester le langage, au lieu de cloner le repo et compiler le projet sur sa machine?
Actuellement on se balade avec trois sites différents (quatre avec le playground), et ça ne me plait pas :
le site vitrine, /, avec des tutoriels, des guidelines, des exemples
la documentation C++ du projet, /impl, pour les mainteneurs et contributeurs/contributrices externes (et… la documentation des modules codés en C++?? hélas oui)
la documentation de la lib standard, /std
et le playground, évidemment
J’ai donc commencé il y a quelques mois un travail de report de toute la doc sur le site "principal" dans /, ainsi dans /impl seulement la doc de l’implémentation restera. Les tutoriels, guides d’intégration ou encore de création de modules sont tous sur le site principal ! Une seule interface, plus simple à gérer et maintenir pour moi (la page des liens : https://arkscript-lang.dev/documentation.html).
A terme, la documentation des modules sera elle absorbée via ArkDoc, notre outil de génération de documentation à partir de commentaires dans le code ArkScript (et C++, les builtins sont documentées avec le même outil ; en le modifiant un peu on devrait pouvoir documenter les modules avec aussi).
Un formateur de code
Les lecteurs et lectrices avisé.es auront peut être remarqué qu’un test était marqué *hidden* un peu plus haut… il s’agit de la suite de tests du formateur de code d’ArkScript !
C’est donc officiel, la CLI s’est doté d’un outil pouvant reformaté un fichier en place ou en dry-run (auquel cas le formatage qui se serait fait est simplement écrit dans la console). Il est très opinionated et pas du tout configurable, à la gofmt : comme ça pas de chichi, tout le monde devra fonctionner de la même manière.
Dès que je me serais assuré que celui-ci est stable et n’avale pas les commentaires par erreur, je formaterai l’ensemble du code ArkScript du projet avec (exemples, lib standard, tests…)! N’hésitez pas à le tester et à faire des retours, c’est de loin le bout de code le plus complexe du projet, malgré sa petite taille (environ 500 lignes à tout casser).
J’espère pouvoir écrire un article à ce sujet, le sujet est très intéressant et plus compliqué qu’il n’y parait (shameless plug, j’ai maintenant un blog en dehors de toute plateforme comme dev.to ou substack).
Le mot de la fin?
Petit sneak peak de tout ce que je veux encore faire sur ce projet (une tâche abattue en fait en général pousser deux, ou plus) :
le Notion d’ArkScript
Je me rends aussi compte que j’ai tendance à faire des posts très longs, j’espère qu’ils vous plaisent/plairont autant que ça me plait de les écrire ; il est vrai que poster une fois tous les 4 mois (ou plutôt 18 mois dans le cas présent) aide à la rédaction de posts aussi longs, il y a matière à discuter !
Pendant ces 90 derniers jours, c’est 795 fichiers qui ont été modifiés, pour 3105 insertions et 9135 suppressions (nettoyage de jeu de données pour les fuzzers), en seulement 97 commits (je suis en train de retravailler le tout dernier, on en reparle bientôt).
Quelqu’un a dit… macros?
Les macros sont bien pratiques, pour améliorer la syntaxe, créer des DSL comme celui utilisé pour les tests:
(test:suite list {
(test:case "append and return a new list" {
(test:eq (append a 4) [1 2 3 4])
(test:eq a [1 2 3])
(test:eq (append a a) [1 2 3 [1 2 3]])
(test:eq a [1 2 3]) })})
Sauf qu’un besoin est vite apparu, étant donné que test:suite, test:case et test:eq (et dérivés) sont des macros, tous leurs arguments se retrouvent évalués (si possible) par le macro processor. Y compris un (@ (list 1 2 3) 0) qui retournerait… le builtin list et non 1.
On manque d’un système de quoting / unquoting / quasiquoting ! Et c’est un assez gros impact sur la syntaxe, que je ne suis pas encore prêt à faire, souhaitant garder le langage le plus simple possible. Une solution intermédiaire fut d’introduire une nouvelle macro qui stoppe l’évaluation dans une macro, en prenant un bloc de code et en le collant tel quel dans le code: ($paste node).
Tous les arguments de test:eq sont donc passés dans des $paste pour éviter une évaluation non souhaitée, et tout va pour le mieux !
Le nom $paste est provisoire, je n’ai pas trouvé mieux pour le moment. N’hésitez pas si vous avez des suggestions.
Tooling, en veux tu en voilà
Développer un langage, c’est bien. S’assurer qu’il fonctionne comme convenu à tout instant, c’est mieux. Pour ça, on a des tests, mais on peut faire bien plus que ça ! Comme des benchmarks pour traquer les régressions de performances, et du fuzzing pour de la détection automatique de bugs. On peut même guider l’écriture de tests avec des analyses du code, comme du coverage. Vous vous en doutez peut être, j’ai fait les 3 (4 si on compte les tests).
Je vous avais déjà parlé des benchmarks et de mon script pour calculer les différences en perf entre différent commit, maintenant on mesure aussi les performances du parser et du compilateur.
New parser - Simple - 39 nodes/0 0.045 ms 0.045 ms 15467 nodesAvg=92.802k nodesRate=132.546k/s uselessLines/sec=287.183k/s
New parser - Medium - 83 nodes/1 0.130 ms 0.129 ms 5405 nodesAvg=54.05k nodesRate=77.3058k/s uselessLines/sec=193.265k/s
New parser - Big - 665 nodes/2 1.74 ms 1.73 ms 405 nodesAvg=7.695k nodesRate=10.958k/s uselessLines/sec=183.402k/s
Welder - Simple - 39 nodes/0 0.164 ms 0.164 ms 4207
Welder - Medium - 83 nodes/1 0.309 ms 0.308 ms 2249
Welder - Big - 665 nodes/2 5.33 ms 5.32 ms 130
Si on compare avec les performances du parser dans le post précédent, on reste dans l’attendu, quelques variations légères mais rien de catastrophique. Les nouvelles statistiques sont celles du welder, qui chaine le parser, import solver, macro processor, ast optimizer, name and scope resolver et compilateur. Six différentes passes une à une, pas trop mauvais en soit de pouvoir compiler un fichier de 319 lignes et 665 noeuds en 5ms!
Petit apparté sur le compilateur
Les plus attentifs auront remarqué deux choses : "name and scope resolver" et "six différentes passes".
Il y a peu j’ai découpé le compilateur en une suite de passes, qui prennent un AST et sortent un AST (hormis pour le parser qui prend un fichier et sort un AST, et le compilateur qui prend un AST et sort du bytecode), et une nouvelle est apparue, sortie du compilateur : la résolution de nom et de scopes.
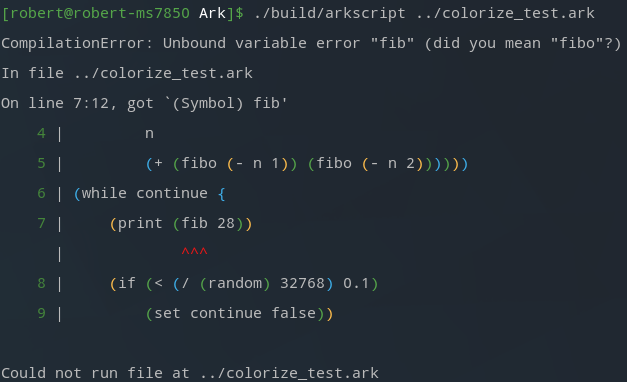
Elle s’occupe de vérifier que l’on utilise que des variables déclarées et valides (on ne peut pas nommer une variable "print" ou tout autre builtin), et propose des alternatives dans les messages d’erreur si besoin (eg fog -> foo?) en se basant sur les variables existantes et une distance de Leveinshtein. La résolution des scopes, peut détecter des variables dites unbound, qui existent plus tard et sont référencées avant leur utilisation.
Encore du tooling
ArkScript a enfin du coverage ! Ça semble tout simple, et ça l’est quand on comprend comment le mettre en place. Le plus dur du travail a été de consolider les tests en un seul exécutable pour pouvoir faire le coverage en coup. Sans ça il faut s’amuser à joindre des fichiers .gcda et/ou .gcno de ce que j’ai compris, et je ne voulais pas m’ennuyer avec ça (en plus ça simplifie énormément le lancement des tests, plus besoin de script bash compliqué, un seul target unittests qui lance toutes les suites).
./unittests
Deux nouvelles suites pour ce faire : Lang (les unittests en ArkScript), et Diagnostics (la validation des messages d’erreur, découpés en deux catégories : runtime et compile time).
Pour un coverage actuel de 73%. Not bad, mais peut mieux faire. Dans les jours et semaines à venir je vais ajouter des tests pour augmenter la couverture de tests, bien que 100% de coverage ne veuille pas dire qu’on a pas de bug, juste que le code est exécuté (les 100% de coverage ne sont pas un but, ni atteignable ni souhaitable).
Formatons du code
Le formatteur de code ArkScript étant devenu plus stable, on a maintenant une action github pour vérifier que du code est formatté correctement dans la CI.
Toujours moins de.. bugs?
Une bonne nouvelle, c’est que grace au fuzzing j’ai pu corriger moulte bugs :
des crash dans le macro processor dû à une évaluation récursive sans borne,
des caractères utf8 invalides lu par le parser qui généraient des crash,
des futures qu’on ne pouvait pas await plusieurs fois,
et pas mal d’autres que vous pouvez retrouver ici : Changelog.md, pour un total de 25 bugs déjà corrigés, qui ont maintenant leur test dédié pour éviter les régressions
Le mot de la fin?
Je suis en train de travailler sur une petite optimisation (guidé par de nombreux benchmarks et beaucoup de scepticisme), du computed goto dans la machine virtuelle. Pour le moment, j’observe un gain de 10% de performance sur les tests les plus gourmands, toujours sur la même machine (MacBook Pro M1, 8 coeurs).
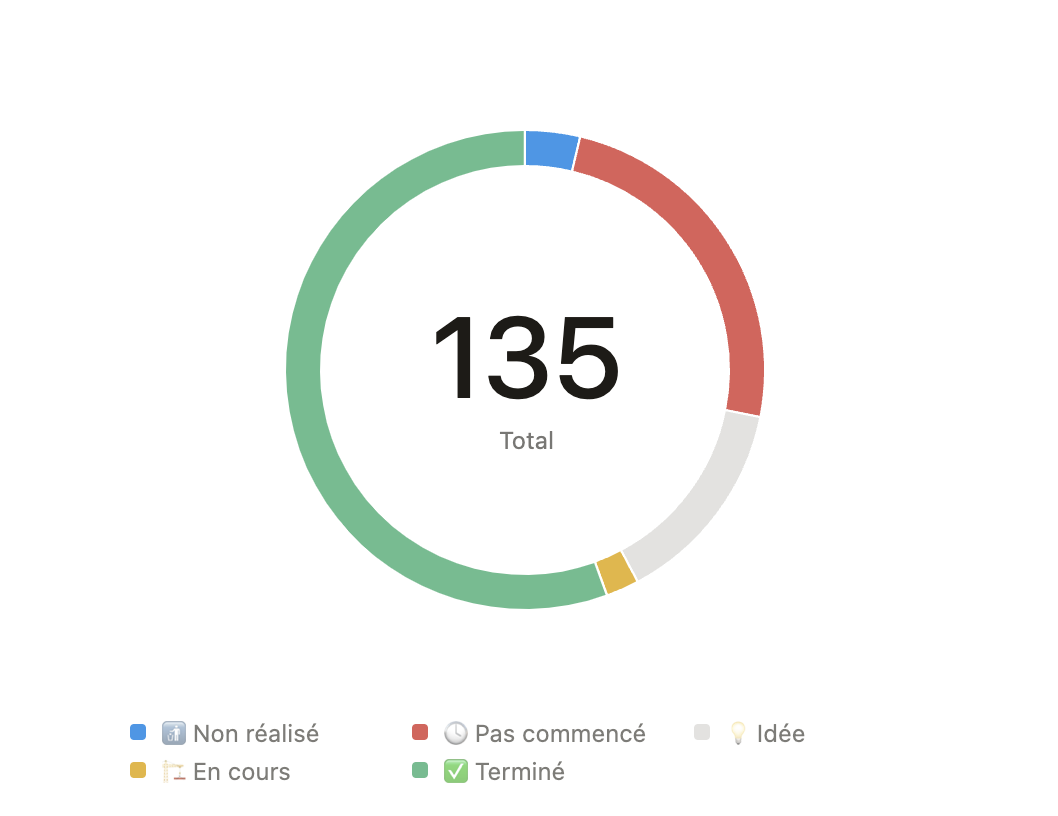
Tâches enregistrées
A l’heure actuelle, 75 tâches sont réalisées, 3 en cours, 19 ont besoin de plus de détails (toujours à l’état d’idée) et 33 sont à faire (et 5 ont été abandonnées). Une tâche de faite en fait naitre environ 1 ou 2 autres, mais on y arrive petit à petit.
Si tout continu tel quel, on se revoit le 24 décembre pour la prochaine update. Sinon, bonne fin d’année et à 2025 !
J’aime bien le concept de $asis (ou peut être $as-is), comme on stoppe l’évaluation (au lieu de désévaluer)! Je le rajoute dans mon bloc note, j’ai envie de repasser sur tous les noms bientôt avant de publier la v4 officielle.
Hello there! Dans les derniers 90 jours, il y a eu 841 fichiers modifiés, 9323 insertions, et 5070 suppressions, dans 106 commits. Le but premier était d’intégrer une IR mais j’ai été side tracked, et bien plus de choses ont été faites!
Intermediate Representation
Le compilateur il produit maintenant des instructions dans une nouvelle représentation intermédiaire (IR), qui est ensuite compilée en bytecode pour la VM !
Pourquoi cette étape supplémentaire, me direz-vous ? Je voulais pouvoir ajouter des super-instructions, qui consistent à fusionner certaines instructions pour en faire plus en une seule. L’introduction d’une IR facile à manipuler semble être une bonne solution pour cette tâche. Nous pourrions avoir une instruction LOAD_CONST_STORE, pour éviter de pousser sur la pile puis de la sortir, et bien d’autres petites améliorations de ce type.
L’introduction de cette IR n’a rien changé, car il est basé à 96% sur le jeu d’instructions. La petite différence est la façon dont nous devons gérer les jump : puisque nous voulons être en mesure de fusionner les instructions, les offset de jump peuvent changer. Si cela vous intéresse, lisez Implementing an IR for ArkScript. Le compilateur produit maintenant des IR entities, que l’IR compiler transforme en bytecode.
Cette IR ressemble à ça lorsqu’elle est vidée (utile pour l’analyse, mieux que de comparer des codes d’octets) :
L’une des optimisations sur lesquelles je voulais travailler, comme je l’ai dit plus tôt, était d’implémenter des super instructions, c’est-à-dire de fusionner deux ou plusieurs instructions ensemble. À ce jour, ces instructions sont les suivantes:
charger plusieurs valeurs à la fois sur la pile
charger une valeur et la stocker dans une variable
copier une variable dans une autre
incrémenter / décrémenter une variable par n
stocker la queue / tête d’une liste dans une variable
charger un builtin i et l’appeler avec n arguments déjà sur la pile
J’ai également fini d’implémenter les computed gotos, ce qui a permis d’améliorer les performances globales de 10 à 15% ! Pour ceux qui ne le savent pas, les computed gotos sont comme un while-switch, qui lit les instructions l’une après l’autre, les exécute, et loop back, mais c’est mieux pour le CPU car cela aide le prédicteur de branches. Ainsi, le code est plus rapide car le prédicteur de branches a plus de facilité à apprendre les jumps entre les instructions.
Dans les benchmarks suivants, nous comparons avec : une ligne de base, puis des computed computes, puis des super instructions + computed gotos ({id_benchmark}-{id_commit}) :
Dans l’ensemble, c’est une série d’améliorations de performance assez décente ! Pour l’instant, je vais arrêter de travailler sur des refactors et des optimisations aussi importants, et me concentrer sur de nouveaux builtins, en améliorant la bibliothèque standard, la documentation, la couverture des tests…
Coverage!
Ce qui constitue une bonne transition pour cette section ! J’ai travaillé sur de nouvelles fonctionnalités, plus d’optimisations, mais cela ne m’a pas empêché d’ajouter cinq nouvelles suites de tests et environ 90 tests supplémentaires !
./unittests
Les nouvelles suites de tests:
Optimizer teste l’opti d’AST (dead code elimination)
Utf8 teste la lib utf8 (codage/décodage des codepoints)
Tools teste les outils C++ (eg l’implé du calcul de la distance de Leveinshtein)
Compiler teste l’IR optimizer en générant juste l’IR et en la comparant avec ce qui est attendu
NameResolution teste la résolution de namespace, le masquage de variable, leur préfixage…
La plus grosse suite de tests à avoir été mise à jour est Diagnostics, avec plus de 70 nouveaux tests! L’objectif est de valider la génération (et la détection) de messages d’erreurs. J’en ai profité pour corriger un vieux bug dans le calcul du numéro de ligne & colonne dans le parser, ce qui fait que les erreurs sont enfin soulignées correctement:
# before
At a @ 2:91 | (let a [])
2 | (pop! a 1)
| ^
3 |
MutabilityError: Can not modify the constant list `a' using `pop!'
# after
At a @ 2:71 | (let a [])
2 | (pop! a 1)
| ^
3 |
MutabilityError: Can not modify the constant list `a' using `pop!'
Grâce à tout ce travail, le coverage est passé de 73% à 79%!
Enfin terminé le système d’imports!
Cette section a été un peu spoilée tout à l’heure lorsque j’ai parlé de la résolution des noms… Il s’agit du nouveau système d’importation ! Oui, celui sur lequel j’ai commencé à travailler fin 2022 !
Nous pouvons enfin importer des symboles à partir de fichiers (aussi appelés « packages » maintenant), importer des fichiers avec préfixe, ou simplement importer quelques noms à partir d’un fichier :
# import all, with a prefix
(import std.List)
(list:map [1 2 3] print)
# import only a few symbols
(import std.Math :even)
(print (even 5)) # false
# import all symbols without a prefix
(import std.String:*)
(print (reverse "hello")) # olleh
Pour l’instant, les fichiers sont importés « à la Python », vous spécifiez un package qui est résolu à partir de votre répertoire courant. Par exemple, (import foo.bar.egg) chercherait $CWD/foo/bar/egg.ark, $CWD étant le répertoire de travail courant du script. La bibliothèque standard bénéficie d’un traitement spécial, vous pouvez écrire std.List, std.Math… à partir de n’importe quel endroit et importer n’importe quoi de la bibliothèque standard.
Tout le travail a été fait dans la passe de résolution des noms, qui est maintenant faite juste après le traitement des macros, de sorte que tous les noms sont calculés (certains noms de variables peuvent être créés par des macros). Si vous voulez en savoir plus sur le fonctionnement interne de cette monstruosité, j’ai écrit un article à ce sujet !
TL;DR : Une fois que les fichiers ont été analysés, et que l'Import Solver a résolu les imports et les a mergées, nous nous retrouvons avec un seul grand AST, avec des noeuds Namespace (plusieurs imports d’un même fichier sont fusionnées ensemble). Ensuite, une nouvelle passe du compilateur, la Name Resolution, peut enregistrer tous les symboles avec leur préfixe (s’ils sont dans un namespace), et les remplacer dans une autre visite AST avec leur nom pleinement qualifié (de cette façon, on évite les conflits de noms).
Les préfixes de package sont calculés avec le nom du package en lowercase, par exemple (import std.List) aura le préfixe list.
L’AST optimizer est de retour!
Pour vous jouer un mauvais tour
L’AST optimizer a été désactivé avant (ou pendant, je ne me souviens plus) la réécriture du compilateur faite en septembre~ 2024, parce que j’avais besoin d’une réécriture, et il fonctionnait parfois, parfois non, pour des raisons inconnues (l’algorithme qui marquait et supprimait le code inutilisé était simplement mauvais).
Il compte maintenant toutes les utilisations de symboles, de sorte que lorsque nous visitons les déclarations supérieures (ainsi que tous les noeuds d’espace de noms, résultant en l’inclusion d’un fichier), nous pouvons les supprimer si nous savons qu’ils ne sont mentionnés qu’une seule fois (seule la déclaration utilise le symbole).
J’ai également ajouté une élimination de base du code mort, de sorte que nous pouvons :
supprimer (if false then)
remplacer (if true then [else]) par then
remplacer (if false then else) par else
supprimer (while false body)
C’est juste une base pour l’instant, dans le futur j’aimerais pouvoir réduire les expressions afin de pouvoir éliminer plus de code mort au moment de la compilation, par exemple (if (= 0 1) then) ne peut pas encore être éliminé par l'Optimiseur.
Advent of code
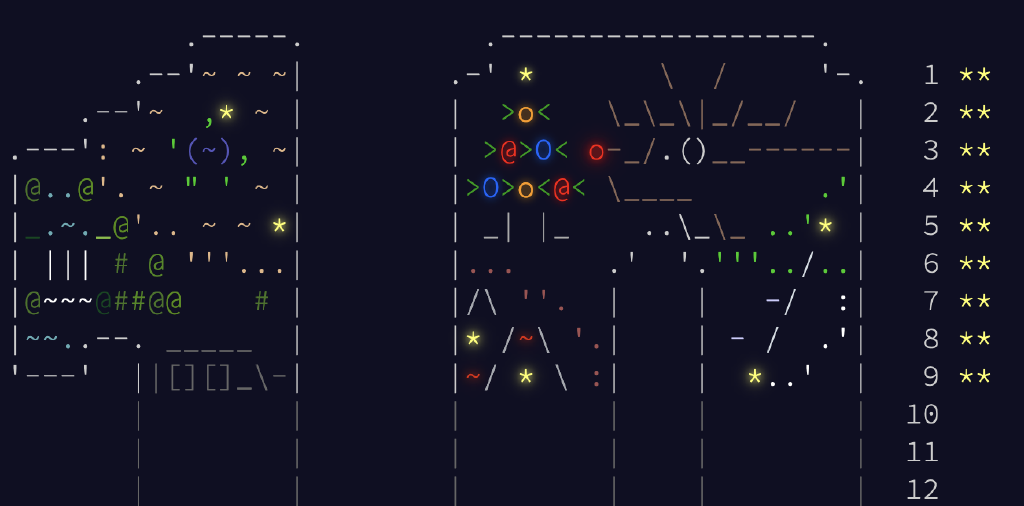
Cette année, j’ai commencé le challenge de compléter l’Advent of code en ArkScript (vous pouvez consulter mes solutions sur GitHub)!
My contribution to this year’s Advent of Code ; looks like a cute camel? Or maybe a snake
Je me suis arrêté assez tôt (9e jour à l’heure où j’écris ces lignes), mais cela a été très instructif, car j’ai trouvé beaucoup de choses à améliorer. Je n’ai eu recours à Python que lorsque je ne savais pas comment résoudre un problème et que j’ai eu la flemme de chercher en ligne, d’exécuter le script, de vérifier la réponse, puis de voir comment je la traduirais en ArkScript.
Les choses qui ont été améliorées :
string:find prend maintenant un troisième argument optionnel, startIndex
string:setAt est une nouvelle fonction pour modifier une chaîne à une position donnée et remplacer un caractère, ce qui renvoie une copie de la chaîne originale, comme list:setAt
@= et @@= sont des opérateurs qui modifient les chaînes et les listes à la place !
@= travaille sur des indexables à une dimension comme les chaînes et les listes : (@= lst 1 5) remplace l’élément à la position 1 par 5
@@= fonctionne sur des indexables à deux dimensions comme les listes de listes ou les listes de chaînes de caractères : (@@= lst 1 2 false) remplacerait l’élément à la ligne 1, colonne 2 par false
un scope dédié autour des boucles, de sorte que nous pouvons créer des variables à l’intérieur du corps de la boucle sans qu’elles ne fuient après la boucle
@@, sur lequel je travaille encore actuellement, pour obtenir un élément à l’intérieur d’un indexable à deux dimensions (liste de listes ou liste de chaînes).
Améliorations de listes
J’ai aussi beaucoup amélioré string:split, qui prend une string et un délimiteur (char ou string) pour découper la chaine d’entrée. L’implémentation fonctionnait mais après l’avoir utilisée et mesuré ses performances lors de l’advent of code… découper 1000 lignes en une liste avec \n comme séparateur prenait 10 seconds (sur un Mac M1 Pro)!
C’est facile de mesure la performance du code en ArkScript sans casser le code, grâce à une macro:
On avait l’habitude d’itérer à travers la chaîne, de supprimer des morceaux de l’entrée et de les copier dans une liste de sortie, d’exécuter string:find à nouveau sur notre entrée… ce qui impliquait beaucoup de copies, et ce n’est pas bon ! La nouvelle version ne met pas à jour la chaîne d’entrée, et n’implique pas string:slice (qui implique encore plus de copies, caractère par caractère) :
# @brief Split a string in multiple substrings in a list, given a separator
# @param _string the string to split
# @param _separator the separator to use for splitting
# @details Returns a list of strings. Example :
# =begin
# (import std.String)
# (let message "hello world, I like boats")
# (let splitted (split message " "))
(let split (fun (_string _separator) {
- (assert (!= "" _separator) "Separator of split can not be empty")- (assert (>= (len _separator) 1) "Separator length must be at least 1")-- (mut _index (string:find _string _separator))- (mut _previous 0)- (mut _output [])+ (mut _at (string:find _string _separator))
(let _seplen (len _separator))
-- (while (!= _index -1) {- (set _output (append _output (slice _string 0 (- _index _previous))))- (set _string (slice _string (+ _index _seplen) (- (len _string) _index _seplen)))- (set _index (string:find _string _separator)) })-- (if (empty? _string)+ (let _strlen (len _string))+ (mut _output [])+ (mut _last "")++ (mut _i 0)+ (while (< _i _strlen) {+ (if (< _i _at)+ {+ (set _last (+ _last (@ _string _i)))+ (set _i (+ 1 _i))+ }+ {+ (append! _output _last)+ (set _last "")+ (set _i (+ _at _seplen))+ (set _at (string:find _string _separator _i))+ (if (= -1 _at)+ (set _at _strlen)) })})++ (if (empty? _last)
_output
- (append _output _string)) }))+ {+ (append! _output _last)+ _output })}))
J’ai également modifié la bibliothèque standard pour utiliser des modifications de listes en place au lieu de copier et remplacer des listes, afin de rendre l’ensemble plus facile à utiliser (personne n’aime attendre 10 secondes pour qu’une chaîne de caractères soit scindée !)
(append data 5) crée et retourne une nouvelle liste, tandis que (append! data 5) met à jour la liste en place. La même chose se passe pour concat/concat!, pop/pop!, list:setAt/@= (& @@=).
Les boucles
Le code suivant donnait une erreur de compilation parce qu’on redéfinissait une constante (foo) avec let, mais plus maintenant.
(let foo 5)
(mut i 0)
(while (< i 5) {
(let foo (* i 7))
(print (= foo 5))
(set i (+1 i)) })
(print (=5 foo))
false est affiché 5 fois (une fois par tour de boucle), parce que foo = 7i, puis true est affiché comme on récupère foodu scope courant. La définition dans la boucle est considérée comme différente.
Une nouvelle pré-release!
Avec toutes ces nouvelles fonctionnalités et améliorations, une nouvelle version a été publiée ! On s’approche de plus en plus d’une v4 officielle.
C’est aussi amusant de voir combien de fois chaque version a été publiée (voir GithubProjectStats). Il semble que la version Linux (construite avec GCC 14) soit la plus populaire jusqu’à présent, avec 321 téléchargements au total pour toutes les versions ! La version la plus populaire est la 4.0.0–9 avec 292 téléchargements, puis la deuxième semble être la 3.5.0 avec 140 téléchargements.
Code age
Pour les curieux et curieuses, voici le graphe de l’âge du code d’ArkScript!
On peut voir une base solide de code de 2019, avec des refactor par ci par là (quand la couleur d’une année diminue fortement), mais en général pas de très grands bouleversements.
Tâches terminées
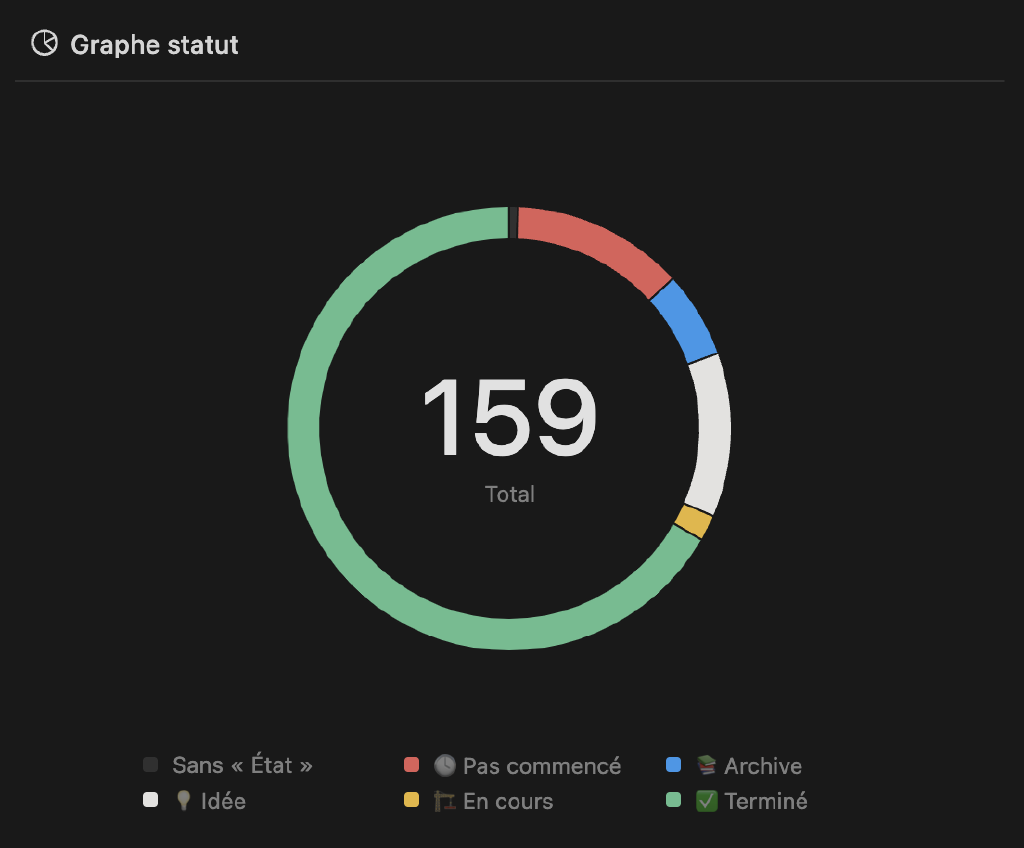
Tasks tracker
Depuis la dernière mise à jour, nous sommes passés de 135 tâches enregistrées à 159 (24 nouvelles). 106 tâches sont maintenant terminées (+31), 3 sont en cours, 19 ont besoin de plus de détails (toujours au stade de l’idée) et 20 doivent encore être réalisées (et 10 ont été abandonnées).
Je pense prendre un peu de recul par rapport au projet, ayant beaucoup travaillé dessus ces derniers temps, je sens que j’ai besoin de me reposer, de sortir la tête de l’eau. Passez de bonnes fêtes de fin d’année, et rendez-vous en 2025 !
Connectez-vous pour pouvoir poster un message.
Connexion
Pas encore membre ?
Créez un compte en une minute pour profiter pleinement de toutes les fonctionnalités de Zeste de Savoir. Ici, tout est gratuit et sans publicité.
Créer un compte