
Hello,
Je sens que je suis face à un problème classique, mais impossible de trouver de l'état de l’art à ce sujet, probablement faute à avoir pile poil les bons mots clés.
J’ai des chaines de transformation avec des résultats intermédiaires qui sont cachés sur disque, et même si le produit intermédiaire n’est plus là, et qu’il y un produit plus avancé dans les transformations, ça me va très bien, inutile de régénérer le produit intermédiaire.
Avec des gros mots, cela donne que j’ai un Graphe Acyclique Direct (DAG), qu’il est déjà réduit. Voire même si j’ai bien compris, j’ai un joli polytree…
Mon objectif est d’enregistrer les tâches de transformations qu’il reste à réaliser, et de ne pas refaire ce qui n’est plus utile. Mon impression est qu’avec une approche naïvo-simple où je trie topologiquement mon DAG, si j’enregistre directement mes tâches, je vais me retrouver à faire des trucs inutiles alors que je devrais pouvoir être capable de simplifier en amont — typiquement si je suis la démarche de ce notebook, ou l'exemple de base chez Dask.
Un petit dessin pour illustrer la situation.
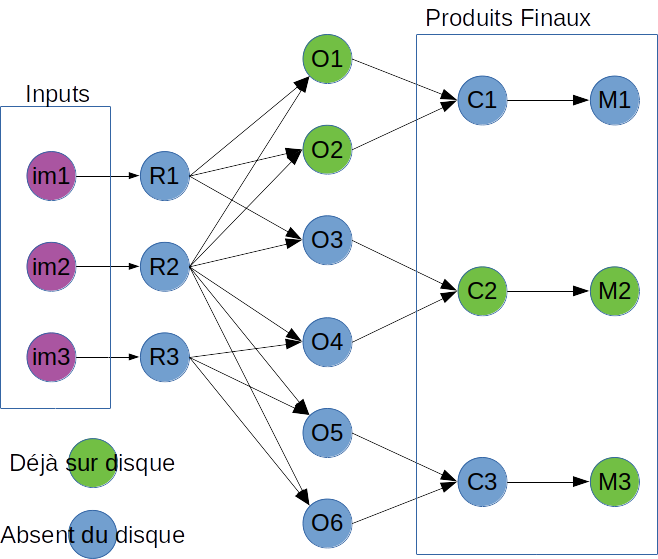
Avec les hypothèses suivantes:
im_isert à produireR_i- La production de O1 nécessite R1 et R2
- (à partir de mes images d’inputs je suis capable de générer le graphe générique complet)
- en vert sont les choses qui sont déjà produites et sur disque
- en bleu les choses qui ne sont pas là (jamais été là, ou effacé, peu importe)
- Le produits finaux sont nécessaires,
- les trucs du milieu n’ont pas besoin d’être produits, voire c’est mieux de l’éviter s’ils ne servent plus.
- (le nettoyage est hors périmètre)
Ce qui veut dire que :
- C1, M1 et C3 doivent être produits ici.
- toutes les dépendances de C1 sont là (O1 et O2), donc il ne faut pas déclencher le calcul de leurs tâches amont, en particulier R1
- C2 et M2 sont là, donc nul besoin de déclencher O3 ni O4, et donc vraiment pas besoin de R1
- C3 doit être produit, donc O5 et O6 aussi et donc R2 et R3 — même s’ils n’étaient pas nécessaires pour C1 ou C2.
C’est à dire qu’après simplifications, mon nouveau DAG devrait être
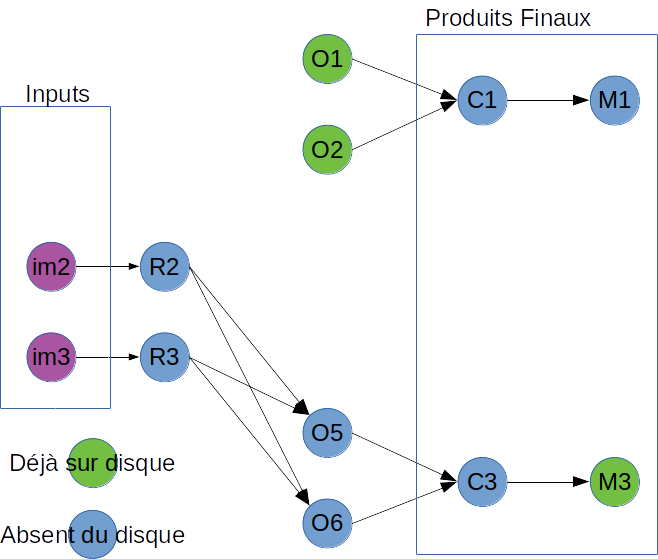
J’ai raté/oublié quoi d’évident, ou (super?) connu ?

