
- Kje,
Bonjour,
suite a la zep-05 concernant la refonte du traitement markdown, il a été choisi d'utiliser pandoc pour tout les resultats (html, pdf et ebook) contrairement au cas actuel (zmarkdown pour le html, pandoc pour le reste). Cela nous oblige a ré-developper nos extensions du markdown dans pandoc. Le dev est en cours.
Je fais ce sujet pour notifier, au fur et a mesure, les conséquences que va avoir ce changement.
Étapes de transitions
La migration va commencer par l'arriver d'une version personnalisé de Pandoc. Celle-ci va apporter le support de certaines de nos extensions dans le parseur d'entrée et son rendu PDF. Vous allez donc voir le rendu PDF s'améliorer au fur et a mesure. une fois toutes les extensions supportés par Pandoc, deux voies s'offrent à nous :
- Apporter ce support dans le format ebook, terminer par le html puis migrer le site vers cette solution.
- Apporter ce support dans le format html, migrer le site puis finir par le support des ebooks.
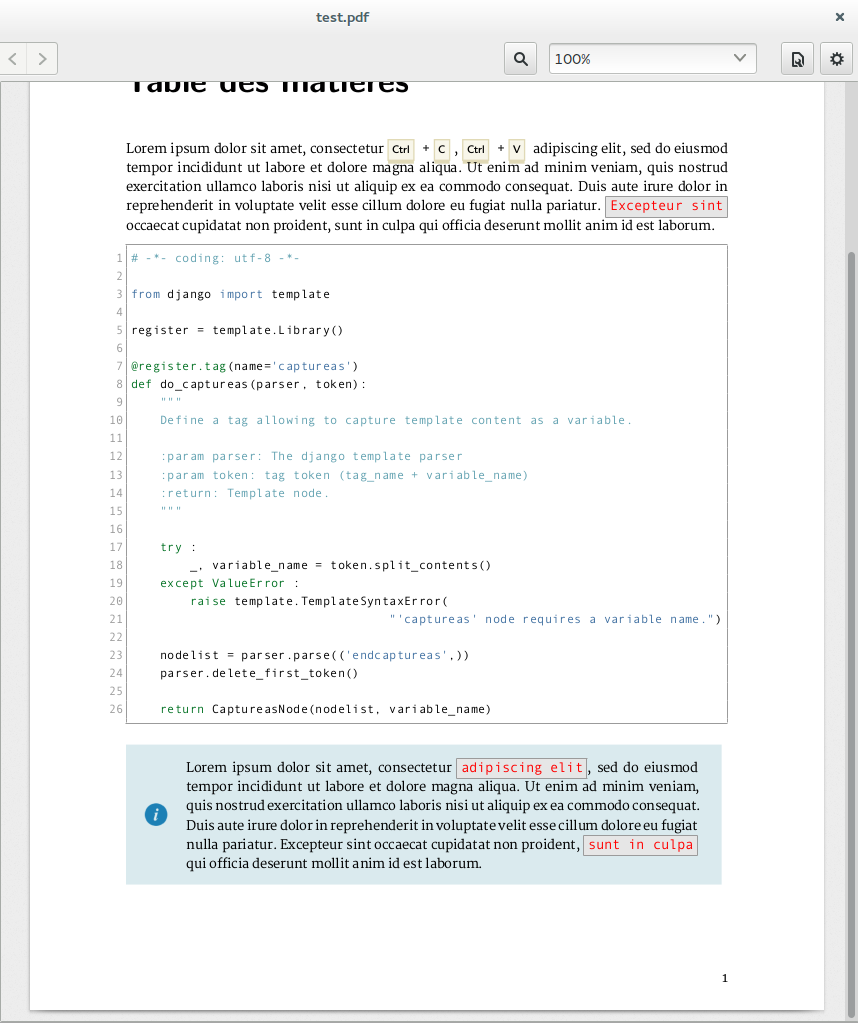
Pour vous donner une idée, voici ce que donne le rendu pdf sur ma branche de dev.
Incompatibilités
La version Pandoc en développement est calibré pour coller au mieux au comportement du markdown actuel pour faciliter la transition. Certaines caractéristiques de Pandoc pourrait nous permettre d'améliorer l'expérience utilisateur et/ou rajouter des fonctionnalités mais ces modifications arriveront une fois le site migré, pour faire des transitions par étapes. Cependant certaines incompatibilités vont rester. On va perdre quelques fonctionnalités, en gagner d'autres, en gagner beaucoup à terme et d'autres utiliseront une syntaxe différente. Je fais un petit état des lieux.
Fusion de cellules dans les tableaux en grille
Comme vous devez le savoir, nous supportons actuellement deux type de tableaux. Ceux sous forme de grille (grid_tables sous Pandoc) supportaient, sous certaines conditions, la fusion de cellules. Ceci n'est pas supporté par Pandoc et son développement risque de prendre du temps. Il est donc conseiller de considérer la fusion de celulles comme une fonctionnalité déprécié, elle ne sera probablement pas disponible à la mise en production de pandoc pour le HTML. Actuellement ces fusions de cellules sont déjà problématique car non dispo pour le rendu pdf. A éviter donc.
Alignement dans les tableaux simples
L'autre syntaxe, dite simple chez nous, pipe_tables sous Pandoc, des tableaux est plus avancé sous Pandoc. Elle est plus souple sur la syntaxe et permet de spécifier l'alignement des colonnes. Je ne pense pas désactiver cette possibilité donc nous pourrons l'utiliser quand la migration sera faite.
Légendes et sources
Actuellement il est possible d'ajouter une légende sur les tableaux, les figures, les vidéos et les équations et la source des citations. Ces éléments vont être repris. Cependant Pandoc supporte déjà les légendes des tableaux avant ou apres le tableaux. Je ne pense pas le désactiver donc il sera possible de spécifier la légende avant. Je pense du coup, pour plus de cohérence, étendre ce principe aux autres éléments : il sera donc possible de légender avant ou apres l'élément concerné.
Coloration syntaxique
Actuellement nous utilisons pygment pour le rendu html, et celui intégré à Pandoc pour les ebooks et PDF. Les possibilités à notre disposition sont :
- Pygment pour tous les formats
- Pandoc pour tous les formats
- listing pour Latex/PDF seulement
Les deux premiers nous permettraient d'éviter d'avoir plusieurs moteurs différents pour la même chose ce qui minimise la maintenance (un langage a rajouté ne se fait qu'à un endroit, détection des mots clés identiques, etc.). Malheureusement ils posent tous deux un gros problème : lors de l'export PDF il n'y a pas la possibilité de gérer le wrapping des codes. Autrement dit, sur un PDF calibré comme mon screenshot plus haut, toute ligne de plus de 80 caractères dépasserait du cadre et de la page. J'ai cherché longtemps et il n'y a aucune façon de régler ça.
La solution la plus raisonnable est donc d'utiliser un systeme pour le HTML (celui intégré à Pandoc, pygment ou a la limite un système en JS) et le package listing pour le Latex/Pdf qui gère lui même la mise en forme du code. On aura donc deux systèmes de rendus mais on aura plus de textes qui dépassent de partout.
Options de colorations
Actuellement il est possible de spécifier le langage d'un code, pour avoir la coloration, le chiffre de début de numérotation et une liste de lignes a mettre en surbrillance. Ces fonctionnalités seront encore supportés mais avec une syntaxe légèrement différente. Ces deux derniers éléments sont actuellement peu utilisé, je ne pense donc pas qu'il soit pertinent et utile de backporter notre syntaxe.
Améliorations futures
Avec l'utilisation de Pandoc, on pourra facilement activer des fonctionnalités déjà dispo. Voici une liste d'extensions qui me semblent pertinent et facile a ajouter :
Mineurs :
- Ne plus forcer la présence d'un saut de lignes pour avoir une liste qui suit un paragraphe
- Permettre d'échapper un caractère de fin de ligne pour produire un
br - Permettre d'échapper un espace pour produire un espace insécable.
- Ajout d'ancrage sur les titres et permettre les liens interne à un document
Majeurs :
- Listes de définitions
- Liste d'exemples (Une liste qui peut se répartir sur tout un document, chaque numérotation de ce type de liste reprend où était arrêtée la précédente et où il est possible de faire référence au numéros dans le texte)
- Coloration des codes inlines
- Notes de bas de pages inlines
- Gestion des bibliographies
Ensuite il sera toujours possible de rajouter de nouvelles fonctionnalités.
Conclusion
C'est un bon aperçu de la transition. Je mettrai ça a jour si je vois d'autres incompatibilités.






{kind=link}