- etne,
Bonjour à tous,
Je m’excuse par avance de la longueur de ce message.
Voilà maintenant 4 mois que nous travaillons (une équipe de 4 élèves dont moi-même) sur notre projet de fin d’étude, la détection temps-réels d’obstacles par nuage de points. Je suis en charge du développement du logiciel, qui est réalisé en C++17. Pour vous donner un peu de contexte au projet, en voici une brève description :
Piloter un rover lunaire à distance est complexe car le pilote ne peut pas regarder toutes les caméras en même temps. Notre projet doit donc streamer la vue frontale et si un obstacle est détecté dans les 180° alors il faut incruster la vue de cette obstacle à la vue frontale afin que le pilote soit prévenu de la présence de l’obstacle. Je vous ai joins une image pour vous faire une idée de l’interface que l’on a actuellement :
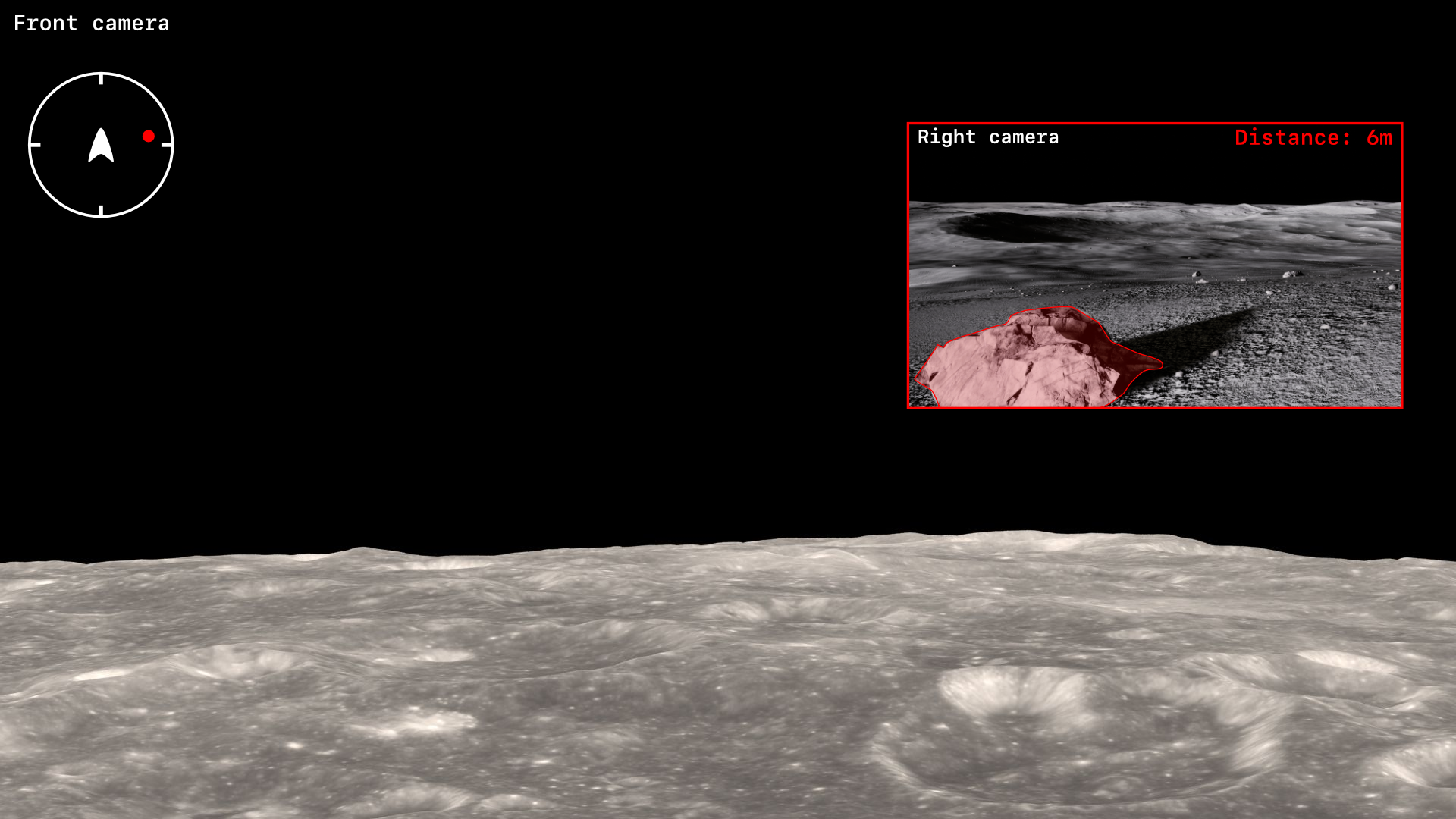
Le logiciel est donc purement un système d’alerte et de prévention et non un système qui doit piloter le rover. Aujourd’hui ce logiciel est codé et fonctionnel, je suis vraiment très satisfait d’en être arrivé là.
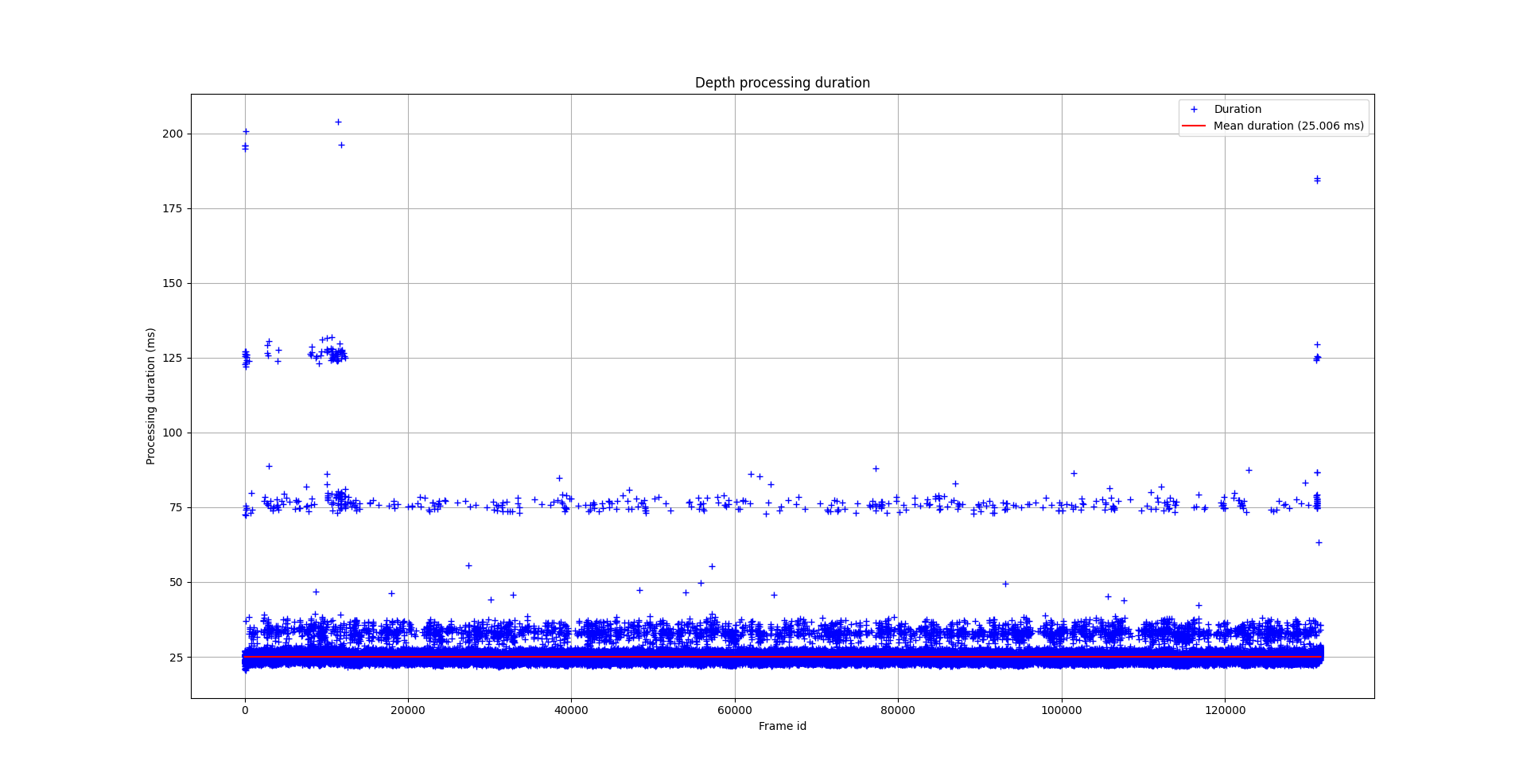
Seulement voilà, il faut maintenant améliorer, car on est loin d’atteindre les performances désirées. Sur mon PC (i7 6700HQ @ 2.60GHz, GTX 980M 4GB), j’arrive à traiter en moyenne une dizaine de nuages de points par seconde, afin d’avoir du vrai temps réel il faudrait que je monte à une trentaine de nuages de points par seconde. Et là n’est pas le pire… Le logiciel est sensé tourner sur une Raspberry Pi 4 et honnêtement j’ai de plus en plus de doute sur la faisabilité de la chose, je pense que la RPi4 n’est pas assez puissante. Je vous explique succinctement le fonctionnement du logiciel :
Pour capturer les nuages de points et la vidéo, nous utilisons une caméra stéréoscopique Intel RealSense D435. Avec la librairie librealsense2 nous récupérons deux flux, le nuage de points à l’instant x et la vidéo à l’instant x. On les sépare et en fonction du type de flux:
- Si c’est un nuage de points, on l’ajoute à une variable qui va être lue par le thread qui va le traiter. Tant que ce nuage de points n’est pas traité, on ignore les nouveaux nuages de points (donc on traite que les nuages de points lorsque le précédent est terminé et que le thread est libre). Si des obstacles sont détectés, ils sont ajoutés à une liste. Pour le traitement, nous utilisons les filtres de la librealsense pour nettoyer et réduire le nombre de point (filtre: threshold pour enlever les points plus loin que 10 mètres et decimation pour réduire le nombre de point), puis avec la PointCloudLibrary nous voxelisons le nuage de points et enfin nous appliquons une clusterisation, un cluster étant un obstacle. Ça fonctionne à merveille.
- Si c’est un flux vidéo, on l’ajoute à une queue où, dans un autre thread, on regarde si on a des obstacles dans la liste. Si oui, on les encadre dans la vidéo, si non on laisse la vidéo telle quelle. La frame traitée est ensuite ajoutée à une queue.
On a enfin un dernier thread qui, avec GStreamer, regarde la queue des frames traitées et quand une nouvelle frame est là, il l’envoie vers le serveur de réception qui s’occupe de l’affichage à l’utilisateur.
Ce qu’on peut remarquer là c’est que les nuages de points et la vidéo sont complètement désynchronisés. Si un obstacle est détecté sur le nuage de points de l’instant x, il sera encadré sur la vidéo de l’instant x+t, t étant le temps de traitement du nuage de points (en moyenne 100–200 ms). Ce n’est pas du tout un problème au vus de la vitesse du rover, au contraire, ça nous permet de garder une vitesse de stream fluide et de ne traiter des points clouds que lorsqu’on le peut. Le logiciel a donc 4 threads:
- Le thread principal qui récupère les données et les dispatch
- Le thread de traitement du nuage de points
- Le thread du traitement de la vidéo et de l’incrustation des obstacles si détectés
- Le thread d’envoi de la vidéo finale
Le seul qui utilise son cœur à 100% est le thread du traitement de nuage de points, les autres tournent autour de 30%.
Bref, voici mes questions :
- Comment mesurer concrètement la performance de mon logiciel ? J’ai bien fait un flamegraph, mais je ne vois rien de choquant.
- L’organisation de mon logiciel est-elle bonne ? Je sais qu’il n’y a pas d’organisation parfaite, mais je me dis que faire un thread par nuage de points pourrait peut-être améliorer mes performances, comment le savoir avant de tester ?
- La Raspberry Pi 4 est-elle pas assez puissante pour ce genre d’application ou en optimisant correctement mon logiciel je peux m’approcher des performances voulues ? Peut-être pas 30, mais 15 nuages de points par seconde serait déjà incroyable.
Je sais que sans le code, ni même le projet devant vous il est difficile de répondre à ces questions, j’ai essayé de vous donner un maximum de détails. Si certains points vous semblent encore obscurs, n’hésitez pas à demander.
Je vous remercie d’avoir lu jusqu’ici ! Et merci d’avance pour vos retours.
Etne.