Hello,
Je pense que le point évoqué par Næ est assez central. Considérer la notion de transformée de Fourier comme acquise est tout à fait acceptable vu que ce n’est pas le sujet de ce tutoriel. Mais pourquoi alors épiloguer sur la définition de celle discrète, si ce n’est pour introduire, soit des applications pratiques ou un contexte historique. Rien n’empêcherait de résoudre le problème de manière purement symbolique et de calculer le résultat de la transformée à la demande en suivant d’autres algorithmes d’évaluation d’intégrales par exemple.
Il faudrait peut-être parler à la fin des différences entre les algorithmes proposés, que ce soit l’officiel FFTW! ou le dernier FFT4. Peut-être que la perte de temps vient du "padding" rajouter par FFTW ou du changement de format dans les données (voir la ligne: real.(b[1:end÷2]) ≈ c[1:2:end] && imag.(b[1:end÷2]) ≈ c[2:2:end]). Quid de leur stabilité numérique, de leur erreur intrinsèque, de complexité asymptotique (ne pas répondre O(NlogN) =) )
Sinon, voici les remarques purement textuelles:
Nous utiliserons la suivante : pour une fonction f, sa transformée de Fourier f chapeau est
J’aurais rajouté un: "défini par/comme suit:"
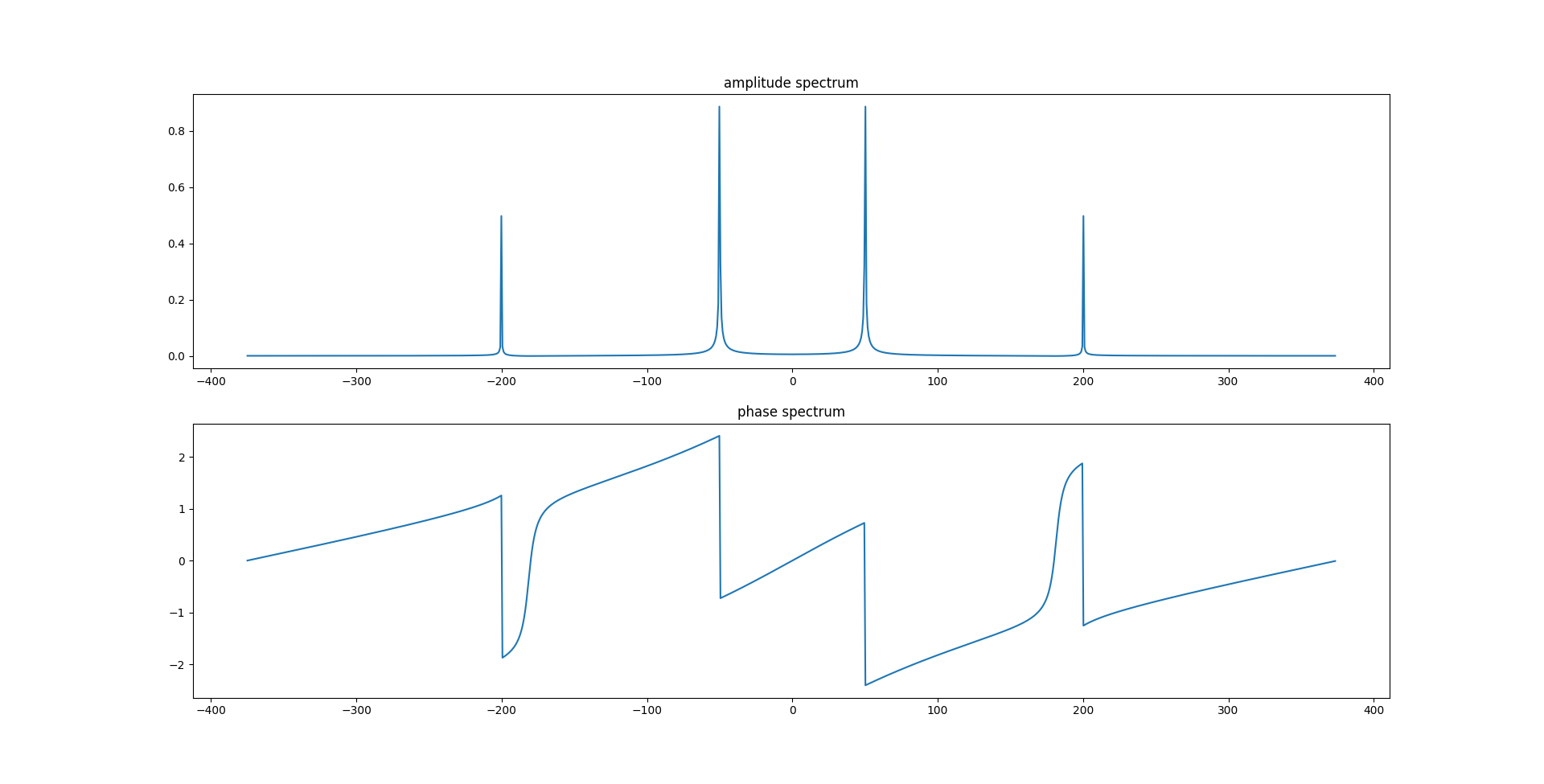
Comme on l’a vu, la transformée de Fourier est définie de manière continue.
Non, on ne l’a pas vu ensemble =)
Or, notre ordinateur ne dispose que d’une taille finie de mémoire, donc pour représenter un signal quelconque, nous ne pouvons utiliser qu’un nombre fini de valeurs.
L’implication du "donc" est hors-sujet. Il faudrait reformuler du style "Or, pour représenter un signal quelconque, notre ordinateur ne dispose que d’une taille finie de mémoire"
On échantillonne (ou discrétise) le signal à analyser, c’est à dire que l’on stocke la valeur du signal pour une suite de valeurs de sa variable.
J’essayerais d’éviter la confusion entre la valeur de la variable, et l’"évaluation" (la valeur ou un autre terme) de la transformée.
Avec \deltaδ la distribution de Dirac.
Éventuellement rajouter la définition de la fonction de Dirac.
g = ш_T X f
Personnellement, je ne suis pas fan de symbole "X", j’aurais préféré un "*".
Le choix du fenêtrage n’est absolument pas anodin, et peut mener à des problèmes innatendus si on l’ignore.
Inattendus
alors sa transformée de Fourier inverse se périodique de période 1/νs
Se périodique ? Ca m’a fait penser à "rotationer" =)
On peut donc implémenter relativement ce calcul !
Mais oui c’est clair !
Dans le code julia un symbole @.
Je ne sais pas lire Julia mais c’est quoi "@." alors qu’il y a une précision sur le "+/- égale"
Notre implémentation est donc vraiment lente et possède une empreinte mémoire très élevée par comparaison avec l’implémentation de référence ! Pour améliorer cela, nous allons implémenter la transformée de Fourier rapide.
Peut-être préciser que le facteur est 5000 ?
Cela qu’en calculant deux transformées de Fourier de longueur N/2,
Mais oui c’est clair !
cela dessine naturelement une implémentation récursive de la FFT.
naturellement
La seule subtilité est qu’il ne faut réaliser l’inversion qu’une fois par case
Cela m’a fait buggé le mot "case" parce qu’il s’agit du premier emploi du terme sans spécifier ce qu’il désigne.
(cela signifie que le compilateur place les quelques variables intermédiaires dans des registres du compilateur)
Quelques doutes sur cette affirmation. Il y a des chances que le stack - une partie de la mémoire - soit employé, non ?
Afin d’économiser de l’espace de stockage, on peut penser à utiliser cette moitié de tableau pour stocker noss nombres complexes.
Outre la type "nos" nombres complexes. La phrase juste avant précise qu’on s’intéresse (le plus souvent) aux signaux réels alors pourquoi conserver des nombres complexes ? La suite des phrases n’est pas cohérente.
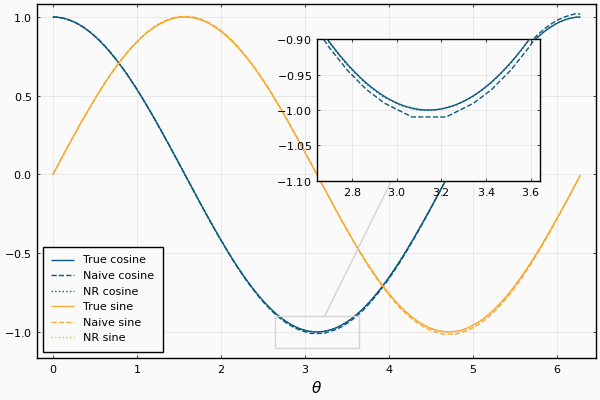
Numerical Recipes on peut lire (section 5.4 "Recurrence Relations and Clenshaw’s Recurrence Formula", page 219 de la troisième édition)
Petite référence du livre =) Que ce soit dans l’introduction ou dans le texte.
my_fft_4(x)
Inversion des benchmarks par rapport à tous ceux présentés précédemment.
Im et Re
Je conforte ce que dit Næ, l’écriture gothique est illisible. J’ai du mal à interpréter la formule de récurrence des termes.