
Salut !
Je travaille actuellement sur un projet pour mes études en machine learning.
J’ai un dataset d’un site e-commerce, j’ai pu faire une analyse exploratoire, le feature engineering et le clustering avec K-Means pour déterminer des groupes de personnes en suivant une RFM.
Désormais, je dois vérifier la stabilité temporelle de ma solution de clustering.
J’ai un dataset avec les colonnes suivante :
customer_id,(days)last_purchase,total_orders,total_spend
Grâce à (days)last_purchase, je calcule le timestamp de la dernière commande passé par le client en partant d’aujourd’hui.
Je l’ajoute et finis donc avec les colonnes suivantes :
customer_id,(days)last_purchase,total_orders,total_spend, last_order_timestamp
Ensuite, je poursuis en créant d’autres dataset par mois (exemple toutes les commandes de Janvier dans le dataframe january, ainsi de suite pour les autres mois)
J’ai ainsi un dataframe avec les commandes du mois correspondant sur tout les mois de l’années (12 dataframe). J’ai également le dataframe contenant toute les commandes.
Mon objectif est de calculer la stabilité du clustering et j’ai vu qu’il existait la méthode ARI.
Mais je ne suis pas sûr de bien comprendre ce que je dois faire étape par étape.
Pour l’instant, je fais comme suit :
data['order_purchase_timestamp'] = 'none'
for i, row in data.iterrows():
data.loc[i, ['order_purchase_timestamp']] = (datetime.now() - timedelta(days=row['(days)last_purchase'])).strftime("%d/%m/%Y")
def kmean_process_date(data_period, data_init):
kmeans = KMeans(n_clusters=5,init='k-means++').fit(data_period)
kmeans2 = KMeans(n_clusters=5,n_init=1,init='random').fit(data_init)
return adjusted_rand_score(kmeans2.labels_, kmeans.labels_)
all_dates = {
"01/01/2022": "02/01/2022",
"02/01/2022": "03/01/2022",
"03/01/2022": "04/01/2022",
"04/01/2022": "05/01/2022",
"05/01/2022": "06/01/2022",
"06/01/2022": "07/01/2022",
"07/01/2022": "08/01/2022",
"08/01/2022": "09/01/2022",
"09/01/2022": "10/01/2022",
"10/01/2022": "11/01/2022",
"11/01/2022": "12/01/2022"
}
mesurate_ari_by_month = {}
def calculate_kmean_by_month():
for key in all_dates:
data_temp = pd.DataFrame({})
start_date = key
end_date = all_dates[key]
for i in range(0, len(data)):
is_in_period = datetime.strptime(start_date, "%d/%m/%Y") < datetime.strptime(data.at[i, 'order_purchase_timestamp'], '%d/%m/%Y') < datetime.strptime(end_date, "%m/%d/%Y")
if is_in_period:
data_var = data.loc[[i]]
data_temp = pandas.concat([data_temp, data_var])
data_period = pd.DataFrame({ '(days)last_purchase': data_temp['(days)last_purchase'], 'total_orders': data_temp['total_orders'], 'total_spend': data_temp['total_spend'] })
data_init = pd.DataFrame({ '(days)last_purchase': data['(days)last_purchase'], 'total_orders': data['total_orders'], 'total_spend': data['total_spend'] })
mesurate_ari_by_month[start_date] = kmean_process_date(data_period, data_init[0:len(data_period)])
calculate_kmean_by_month()
Cela me donne un graphique sous cette forme :
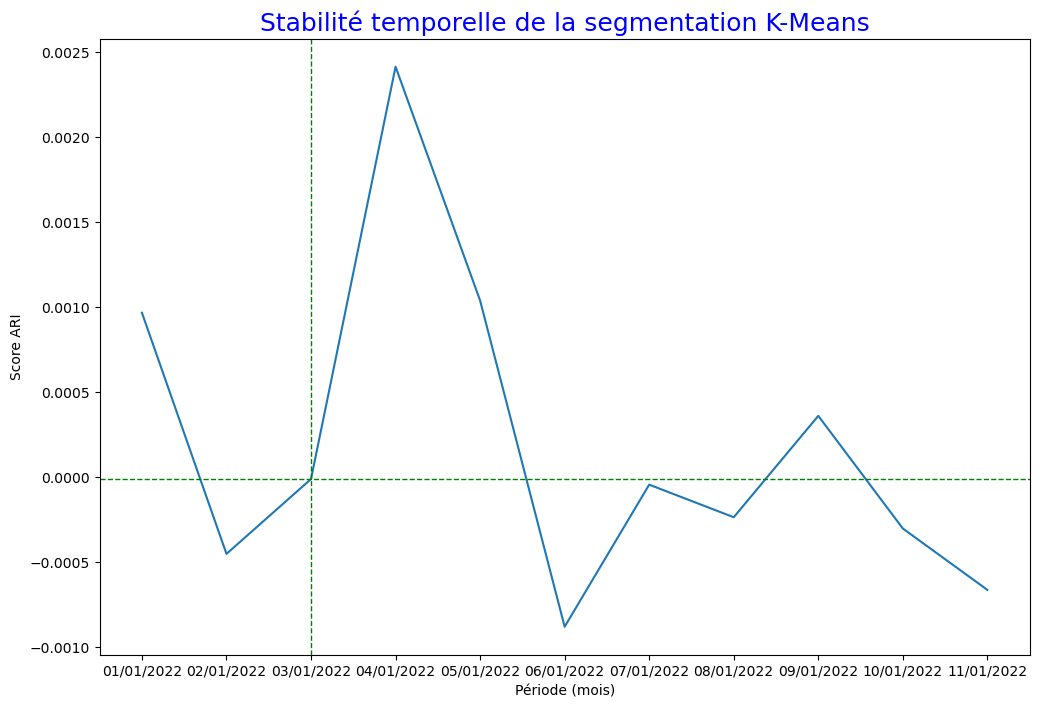
Mais je suis certains de ne pas avoir bien compris comment l’utiliser (malgré mes recherches)
Le repo est disponible ici
Merci à tous