Maintenant qu’on a vu tout ça, il nous reste à pratiquer un peu !
Lorsqu’on consulte un document, que ce soit un fichier texte (code source par exemple) ou une page web, il faut la lire avec le bon encodage. Sinon, les valeurs seront mal interprétées. Par exemple, si on encode ce texte en UTF-8 :
l'événement du siècle
et qu’on le lit en latin-1, on verra ceci :
l'événement du siècle
Splendide, non ? Vous avez déjà dû croiser ce genre d’erreurs… Pour l’expliquer,
souvenons-nous qu’UTF-8 encode certains caractères, dont les lettres accentuées,
sur deux octets ; ici la lettre é donne les octets 0xC3 et 0xA9. Or, latin-1
encode tous ses caractères sur un octet. Les octets 0xC3 et 0xA9 sont donc
interprétés séparément, et donnent les caractères à et ©, respectivement.
Notons que tous les autres caractères sont lus correctement, car ils
appartiennent à la base commune ASCII. On voit maintenant l’intérêt de cette
compatibilité : même avec un mauvais encodage, le texte reste globalement
lisible.
Réciproquement, si ce texte était encodé en latin-1 et qu’on tentait de le lire en UTF-8, on aurait sans doute quelque chose comme :
l'�v�nement du si�cle
car la séquence d’octets 0xE9.0x67, qui code év en latin-1, est invalide en
UTF-8.
Ces deux cas de figure sont faciles à reconnaître, et représentent une grande
partie des problèmes qui surviennent en pratique. Cependant, le diagnostic peut
être plus difficile quand il s’agit de deux encodages dans lesquels tous les
caractères font la même taille (le fameux dollar $ devenu livre £).
Déterminer l’encodage d’un fichier est donc crucial, et compliqué par la diversité des encodages existants. Or, les renseignements associés à un fichier (sa date de création par exemple) n’indiquent rien sur son encodage. On doit donc tenter de le deviner. Les programmes (navigateur web, éditeur de texte…) emploient des algorithmes qui analysent le contenu du fichier. Ces algorithmes sont efficaces la plupart du temps, mais peuvent échouer. Une détection incorrecte explique l’affichage bizarre de certains documents.
Un moyen plus simple serait d’inclure cette indication directement dans le contenu du fichier, au tout début pour diminuer les risques de perturbation. On utilise pour cela la base de compatibilité ASCII. On verra une application de cette idée avec les pages HTML.
Lire & écrire avec le bon encodage
Commençons par apprendre à régler manuellement l’encodage si jamais la détection automatique échoue.
Lire une page web
La plupart du temps, lire une page web ne pose aucun souci car son encodage est précisé dans son code source. Il arrive toutefois que ce ne soit pas fait, ou mal fait, et que le navigateur échoue à le deviner. Par exemple :
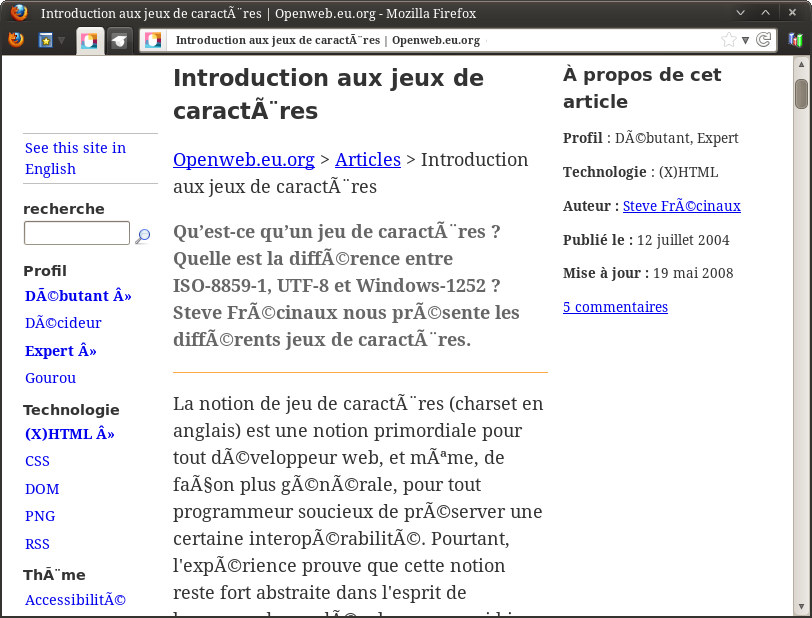
Exemple de page lue avec un mauvais encodage
C’est moche. C’est désagréable à lire. Heureusement, on peut y remédier manuellement. Tout navigateur qui se respecte permet de jongler entre les encodages. Pour Firefox, le menu est caché sous « Affichage » :
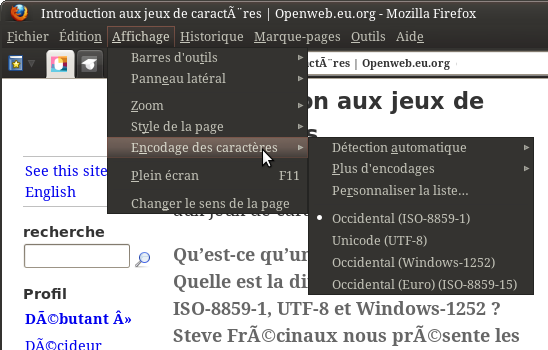
Menu des encodages dans Firefox
Pour l’instant, le navigateur est en « détection automatique », ce qui a conduit à l’utilisation incorrecte d’ISO-8859-1 (latin-1). On peut en changer. Ici, la page est probablement en UTF-8 (ça ressemble à l’erreur vue en introduction), donc on essaie cet encodage. On choisit l’option correspondante dans le menu, et…
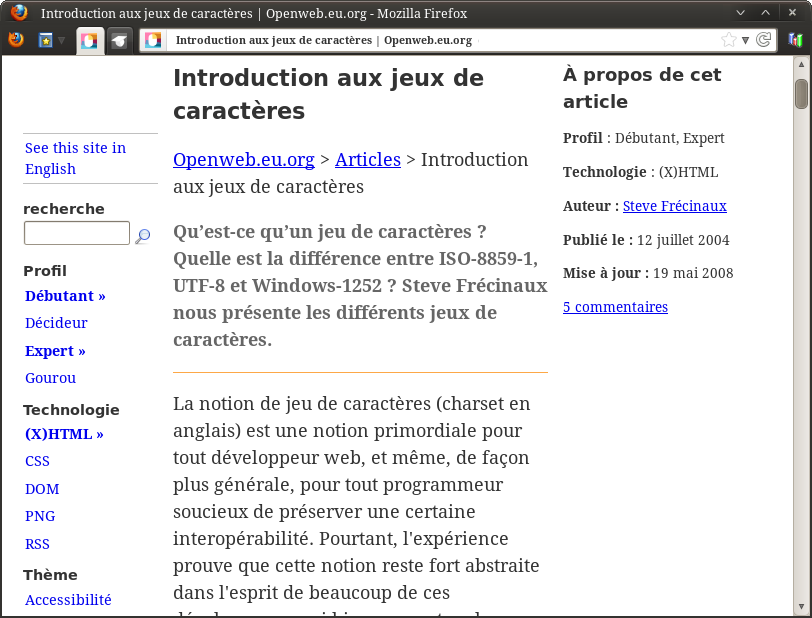
Tadaam !
La page s’affiche correctement. C’est du beau boulot.
Éditer un fichier
On va maintenant voir comment gérer l’encodage de nos fichiers. Tout éditeur de texte digne de ce nom permet de le faire de façon précise… mais commençons par le Bloc-Notes de Windows. Ouvrons le Bloc-Notes, tapons un peu de texte avec des accents, puis enregistrons.
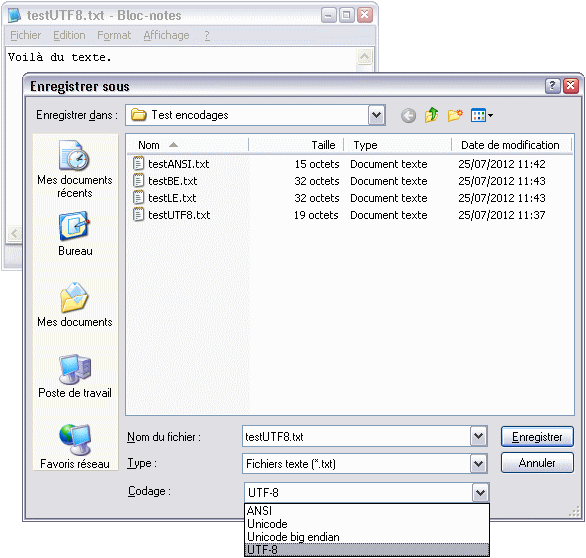
Boîte de dialogue d’enregistrement du Bloc-Notes
Le Bloc-Notes permet au premier enregistrement de choisir l’encodage du fichier. Le choix est assez limité cependant : « ANSI » (Windows-1252), « Unicode » (UTF-16LE), « Unicode big endian » (UTF-16BE), ou UTF-8. Comme exercice, vous pouvez vous amuser à vérifier que les tailles des fichiers affichées sur ma capture sont correctes, sachant que mon texte comporte quinze caractères et que le Bloc-Notes ajoute automatiquement une BOM pour tous les encodages Unicode (qui fait deux octets en UTF-16 et trois octets en UTF-8).
Le Bloc-Notes est vraiment très limité. Ainsi on ne peut pas choisir le latin-9 par exemple. De plus, rien n’indique l’encodage du fichier sur lequel on travaille, et on ne peut pas en changer après coup.
Si vous programmez, vous utilisez certainement un éditeur plus avancé. Comme les navigateurs web, la plupart incluent un menu pour passer d’un encodage à un autre. Toujours sous Windows, voici l’exemple de Notepad++ (ici j’ai rouvert les fichiers que je viens de créer avec le Bloc-Notes) :
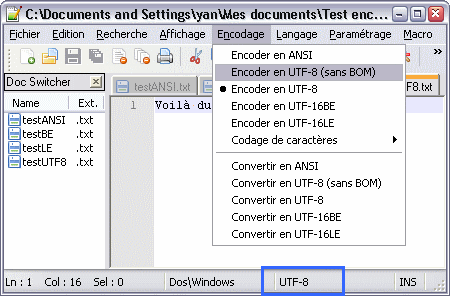
Le menu des encodages dans Notepad++
Première remarque, Notepad++ détecte automatiquement l’encodage et l’indique dans la barre de statut (en bas, encadré en bleu). C’est déjà mieux. En passant, remarquons la mention « Dos\Windows ». Elle indique le style utilisé pour les fins de ligne. On avait vu qu’il existait plusieurs conventions, selon les OS. Ici, notre fichier utilise le style Windows, c’est-à-dire CRLF.
Ensuite, le menu « Encodage » permet de changer en direct l’encodage utilisé. Comme dans les navigateurs web, les options « Encoder en xxx » changent l’interprétation des octets existants ; en plus, elles déterminent le codage des caractères nouvellement insérés. Pour modifier l’encodage d’un fichier, il ne faut pas cliquer sur « Encoder en xxx », car cela n’adapte pas le contenu existant ; pour ça, il faut faire « Convertir en xxx ».
Enfin, on a quand même plus de choix que dans le Bloc-Notes !
Après cet aperçu, faites un tour dans la configuration de votre éditeur. Il y a certainement des options qui nous intéressent.
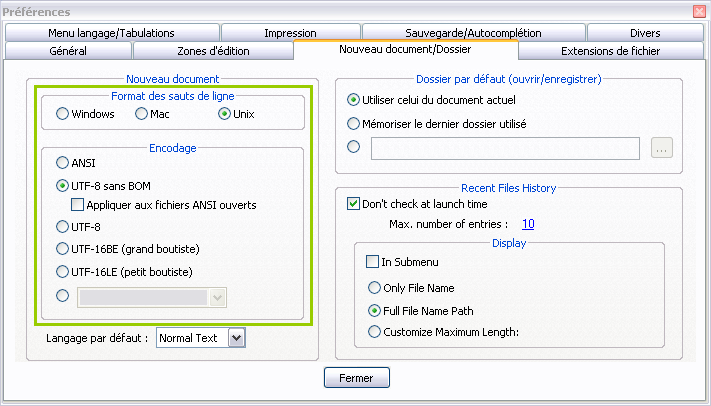
Fenêtre de configuration de Notepad++
Ici, j’ai encadré la partie intéressante en vert. On peut choisir l’encodage (et le format des fins de ligne) qui sera utilisé par défaut lors de la création d’un nouveau fichier.
Avec ou sans BOM ?
Remarquons qu’il y a deux encodages UTF-8. L’une porte la mention « (sans BOM) », ce qui signifie que l’autre est un « UTF-8 avec BOM ». On a déjà parlé de la BOM, ce caractère Unicode spécial placé tout au début d’un fichier pour en indiquer le boutisme. Cette technique est utilisée pour l’UTF-16 et l’UTF-32. En revanche, elle est inutile en UTF-8 puisqu’on n’a pas de problème de boutisme. Pire, elle peut rendre des fichiers invalides pour certains programmes. C’est par exemple le cas des pages web, comme on verra plus tard. Pourtant, certains éditeurs dont le fameux Bloc-Notes la rajoutent automatiquement même en UTF-8, car ça les aide à détecter l’encodage du fichier. C’est une pratique déconseillée. Dans votre éditeur favori, choisissez toujours la version sans BOM si vous avez le choix.
Ici, nettoyons notre fichier de cette hérésie avec Notepad++. Pour ça, on fait simplement « Convertir en UTF-8 (sans BOM) » et on enregistre. Dans les paramètres, on choisit aussi l’UTF-8 sans BOM par défaut.
Convertir un fichier
On peut aussi convertir un fichier sans passer par un éditeur. C’est par exemple
la fonction d’iconv, programme en ligne de commande disponible
sur les unixoïdes (il a donné son nom à l’API standard, intégrée à
la glibc, qui fait la même chose). Il s’utilise comme ça :
1 | $ iconv [-f DEPUIS] [-t VERS] |
les formats DEPUIS et VERS pouvant être omis pour utiliser la locale
actuelle. Par exemple :
1 2 | $ echo "déjà" | iconv -t utf16 | hexdump -C 00000000 ff fe 64 00 e9 00 6a 00 e0 00 0a 00 |..d...j.....| |
On observe la BOM (U+FEFF) qui nous dit que l’encodage est petit-boutiste, et les octets nuls insérés après chaque octet de latin-1.
Attention, pour modifier un fichier en place, il ne faut surtout pas faire :
1 | $ commande < fichier > fichier
|
car cela effacerait le contenu du fichier… Il faut passer par un fichier temporaire. De toute façon, il est plus prudent de vérifier le résultat avant d’écraser le fichier.
Il existe aussi le programme recode, qui s’utilise de façon
similaire :
1 | $ recode [DEPUIS][..VERS] |
Sa spécificité est qu’il ne gère pas seulement les encodages textuels (le sujet de cet article), mais plus généralement divers types de codages (ce que le logiciel nomme « surfaces »), qui peuvent se superposer. Cela inclut les formats de fin de ligne (LF, CR ou CRLF) et les « encodages de transfert » (Base64, Quoted-Printable…) utilisés notamment par les courriels.
Par exemple, pour convertir le texte en UTF-16, coder les octets obtenus avec Quoted-Printable, puis appliquer le format de fin de ligne CR-LF au tout :
1 2 3 | $ echo "déjà" | recode ..utf16/QP/CRLF | hexdump -C 00000000 3d 46 45 3d 46 46 3d 30 30 64 3d 30 30 3d 45 39 |=FE=FF=00d=00=E9| 00000010 3d 30 30 6a 3d 30 30 3d 45 30 3d 30 30 0d 0a |=00j=00=E0=00..| |
Observons que chaque octet qui ne correspond pas à un caractère affichable de
l’ASCII est codé par =XX (Quoted-Printable), et que la fin de ligne est codée
par la séquence 0x0D, 0x0A (CR-LF).
recode a aussi une foncton très pratique pour examiner du texte !
1 2 3 4 5 6 7 8 9 10 11 12 13 | $ echo "déjà, 한" | recode ..dump UCS2 Mné Description 0064 d lettre minuscule latine d 00E9 e' lettre minuscule latine e accent aigu 006A j lettre minuscule latine j 00E0 a! lettre minuscule latine a accent grave 002C , virgule 0020 SP espace 1112 hangûl tch'ôsong hiûh 1161 hangûl djoungsong a 11AB hangûl djôngsong niûn 000A LF interligne (lf) |
Corriger un encodage mixte
Il arrive qu’un fichier mélange plusieurs encodages, comme l’UTF-8 et le latin-1. Ce peut être le cas d’un fichier texte récupéré sur Internet, ou de la base de données d’un site web. Démonstration :
1 2 3 | $ cat test ligne encodée en UTF-8 ligne encodée en latin-1 |
Normalement, ma console qui est en UTF-8 devrait plutôt afficher :
1 2 3 | $ cat test ligne encodée en UTF-8 ligne encod�e en latin-1 |
mais elle utilise un mode spécial pour afficher quand même les caractères encodés en latin-1 : lorsqu’une séquence d’octets n’est pas de l’UTF-8 valide, elle est relue comme du latin-1. Cette astuce est utilisée par de nombreux logiciels, dont la plupart des clients IRC1. On peut la considérer comme pratique, ou commme nuisible parce qu’elle masque les erreurs.
Bref. On peut vérifier que le fichier mélange effectivement les deux encodages :
1 2 3 4 5 | $ cat test | hexdump -C 00000000 6c 69 67 6e 65 20 65 6e 63 6f 64 c3 a9 65 20 65 |ligne encod..e e| 00000010 6e 20 55 54 46 2d 38 0a 6c 69 67 6e 65 20 65 6e |n UTF-8.ligne en| 00000020 63 6f 64 e9 65 20 65 6e 20 6c 61 74 69 6e 2d 31 |cod.e en latin-1| 00000030 0a |.| |
C’est bien une erreur, qui fait planter des programmes plus stricts :
1 2 3 4 5 6 7 8 | $ cat test | iconv -f utf8 ligne encodée en UTF-8 ligne encod iconv: séquence d'échappement non permise à la position 35 $ cat test | recode utf8.. ligne encodée en UTF-8 ligne encod recode: Entrée invalide dans « UTF-8..CHAR » |
iconv peut ignorer les erreurs, mais ce n’est pas idéal :
1 2 3 | $ cat test | iconv -f utf8 -t //IGNORE ligne encodée en UTF-8 ligne encode en latin-1 |
Il faut corriger un tel fichier. Il ne semble pas y avoir de programme répandu pour ça, mais ce n’est pas difficile à coder. Vous pouvez par exemple jeter un œil à ce script en Perl ou à celui-ci en OCaml.
1 2 3 4 5 | $ cat test | fix-mixed-utf8 | hexdump -C 00000000 6c 69 67 6e 65 20 65 6e 63 6f 64 c3 a9 65 20 65 |ligne encod..e e| 00000010 6e 20 55 54 46 2d 38 0a 6c 69 67 6e 65 20 65 6e |n UTF-8.ligne en| 00000020 63 6f 64 c3 a9 65 20 65 6e 20 6c 61 74 69 6e 2d |cod..e en latin-| 00000030 31 0a |1.| |
Ou alors, ce script interactif (suggéré par Taurre) qui demande l’encodage d’origine de chaque ligne et convertit tout en UTF-8 :
1 2 3 4 5 6 7 8 | #!/bin/sh last=utf8 while read line ; do echo "$line" | od -c -w256 >&2 read -p "Quel encodage ? [$last] " code </dev/tty >&2 last="${code:-$last}" echo "$line" | iconv -f "$last" -t utf8 done |
Exemple d’utilisation :
1 2 3 4 5 6 7 | $ ./convert-mixed.sh < test > test-corrigé 0000000 l i g n e e n c o d 303 251 e e n U T F - 8 \n 0000030 Quel encodage ? [utf8] 0000000 l i g n e e n c o d 351 e e n l a t i n - 1 \n 0000031 Quel encodage ? [utf8] latin1 |
-
En effet, IRC n’offre aucun moyen de préciser l’encodage des messages, alors qu’en pratique il met en contact des gens qui en utilisent de toutes les sortes… ↩
Déclarer l’encodage
Comme évoqué en introduction, plutôt que de se reposer sur une détection automatique, certains types de documents permettent — voire requièrent — de préciser leur encodage directement dans le texte du fichier. On va voir l’exemple des pages HTML et des documents LaTeX.
HTTP, HTML & XML
Au passage, notons ce tutoriel pour migrer son site web de latin-1 vers UTF-8.
Pour le web, les serveurs HTTP peuvent indiquer l’encodage avec un champ d’en-tête :
1 | Content-Type: text/html; charset=‹ENCODAGE› |
D’ailleurs, cet en-tête fournit aussi le type MIME du document (page HTML, fichier CSS, image PNG…).
Toutefois, cette technique nécessite un serveur (ce qu’on n’a pas pour consulter un fichier local) et empêche de fournir avec le même serveur des fichiers avec des encodages différents (cas d’un serveur mutualisé).
À la place, pour les pages HTML, on peut renseigner l’encodage… directement dans
le fichier HTML. Ça semble bizarre puisqu’en théorie, on ne peut pas encore lire
le fichier. Mais le socle ASCII vient à notre secours : quel que soit
l’encodage, si on n’utilise que les caractères de l’ASCII, on pourra lire sans
problème. On utilise une balise <meta http-equiv /> (dans <head/>) qui est
l’équivalent de l’en-tête HTTP.
1 | <meta http-equiv="Content-Type" content="text/html; charset=‹ENCODAGE›" /> |
En HTML5, cette balise a été simplifiée en :
1 | <meta charset="‹ENCODAGE›"/> |
Elle doit se trouver au tout début de <head/> afin de ne pas perturber la
détection, et parce que le navigateur relit le fichier depuis le début dès qu’il
l’a rencontrée. Seul le strict nécessaire doit précéder cette balise, avec
uniquement des caractères ASCII (donc pas de BOM en UTF-8 !).
Mauvais (il y a des caractères non-ASCII dans le commentaire) :
1 2 3 4 5 | <html> <head> <!-- ligne nécessaire pour spécifier l’encodage : --> <meta http-equiv="Content-Type" content="text/html; charset=UTF-8" /> … |
Bon :
1 2 3 4 | <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=UTF-8" /> … |
On peut trouver ici les noms d’encodage autorisés
(insensibles à la casse). Les plus intéressants pour nous sont ISO-8859-1
(alias latin-1) et UTF-8. Facile !
Dans les langages XML en général (dont HTML), on peut également renseigner l’encodage dans le prologue XML, une sorte de balise spéciale optionnelle qui doit être placée sur la toute première ligne du fichier.
1 | <?xml version="1.0" encoding="‹ENCODAGE›" ?>
|
À propos, XML (donc HTML) permet d’insérer un caractère Unicode arbitraire,
même s’il n’existe pas dans l’encodage du code source : pour insérer le point
de code U+CODE, la syntaxe est ODE; (&…; est la syntaxe des entités
XML, # signifie « nombre » et x signifie « hexadécimal »).
Un mécanisme similaire existe dans de nombreux langages, par exemples \CODE
en CSS ou \uCODE en C.
LaTeX
L’encodage est très important avec LaTeX. Comme en HTML, il faut déclarer avec
quel encodage est enregistré le fichier en le précisant en paramètre du paquet
inputenc :
1 | \usepackage[‹ENCODAGE›]{inputenc} |
(latin1 ou utf8 pour les plus courants). Les fichiers éventuellement inclus
avec la commande \input doivent être enregistrés avec le même encodage, mais
il n’y a pas besoin de le déclarer à nouveau.
Programmer
Enfin, lorsqu’on crée un programme, il faut bien sûr faire attention à l’encodage du texte qu’on manipule !
Le langage C
Le langage C est bas niveau. En C, on manipule directement les octets, avec le
type char. En particulier, un char est un octet, pas un caractère.
C’est le type wchar_t qui permet de stocker un caractère
arbitraire2.
La gestion des encodages en C de façon portable est excessivement compliquée si l’on se contente de la norme. En effet, le C est un vieux langage, créé dans les années 1970 lorsqu’on n’utilisait encore que des pages de code sur un byte. Tout était plus simple. Avec le développement d’encodages plus complexes, il a fallu adapter la norme… et comme d’habitude, le comité a décidé de ne pas normaliser grand-chose (pour ne pas trop contraindre les implémenteurs et pour garder la bibliothèque standard minimaliste).
Voici une synthèse des types disponibles et des encodages associés ; évidemment, la norme laisse ces derniers non spécifiés, donc dans ce tableau figurent les valeurs usuelles.
|
Type des chaînes |
Taille d’un caractère |
Jeu de caractère & encodage |
Version |
|---|---|---|---|
|
|
nombre variable de (1 |
déterminé par la « locale » (donc dynamique)
|
C89 |
|
|
exactement un (= 1, 2 ou 4 octets, selon le système) |
dépend du système
|
C99 |
|
|
exactement un |
dépend du système, prévu pour UTF-16 |
C11 |
|
|
exactement un |
dépend du système, prévu pour UTF-32 |
C11 |
Table: Types et encodages en C
Ces encodages sont ceux utilisés par les fonctions de la bibliothèque standard, telles les fonctions de conversion, mais bien sûr on fait ce qu’on veut de nos octets.
La console de Windows crée une difficulté supplémentaire puisqu’au lieu de la
nouvelle page de code 1252, elle utilise toujours l’ancienne (850 ou 437) par
défaut. Un logiciel qui respecte la locale écrira en Windows-1252 et ses
accents s’afficheront mal dans la console. Pour y remédier, demander à
l’utilisateur de faire CHCP 1252 ou, mieux, ajuster soi-même l’encodage de
la console avec les fonctions setConsoleOutputCP et GetACP définies dans
<windows.h>.
Bref, pour un résultat portable et sans prise de tête, il est avisé d’utiliser une bibliothèque tierce. L’implémentation de référence est la bibliothèque ICU, extrêmement complète. Également, j’ai déjà évoqué l’API iconv intégrée à POSIX, pour les conversions d’encodages.
Je ne m’étendrai pas plus sur le sujet. Si vous voulez pousser plus loin, j’ai donné des mots-clés pour guider vos recherches. Pour plus de détail sur la norme C à ce sujet, lisez donc ceci, c’est un bon moyen de se rendre compte à quel point c’est l’enfer…
Autres langages
Les langages de plus haut niveau, ou tout simplement plus récents, peuvent mieux prendre en charge Unicode et les conversions d’encodages.
Par exemple, en Java, la classe String utilise l’UTF-16. De
plus, des fonctionnalités supplémentaires pour contrôler plus finement l’Unicode
sont fournies par le package Java.text.
De même, Python permet de gérer Unicode et les encodages facilement. De plus, Unicode est devenu le défaut en Python 3.
- La classe
unicode(renomméestren Python 3…) est un texte Unicode décodé. C’est ce qu’il faut utiliser partout en interne, Unicode étant universel. - La classe
str(renomméebyteen Python 3) est un texte encodé suivant un certain encodage. Il ne faut l’utiliser que pour les entrées et sorties.
En Python 2, u"déjà" est un objet de type unicode tandis que "déjà" est un
objet de type str. Les méthodes .encode(…) et .decode(…) permettent de
passer de l’un à l’autre ; elles prennent en paramètre l’encodage du texte
str.
En OCaml, la maigre bibliothèque standard ne prend pas en charge Unicode (jusqu’à récemment, la norme du langage utilisait latin-1), mais de nombreuses bibliothèques tierces le font, comme Camomile (intégrée à Batteries) ou Uutf.
-
Eh oui, la norme demande que les caractères soient de taille fixe, mais Windows a choisi UTF-16 restreint au BMP, comme on l’a déjà vu quand on a présenté UTF-16. Ceci permet un gain de mémoire par rapport à UTF-32. ↩
-
La norme appelle « jeu étendu » (extended character set) l’ensemble de caractères supporté par le système. ↩
-
La norme parle d’« encodage multi-octet » (multibyte encoding). ↩
-
La norme parle de « caractères larges » (wide characters). ↩