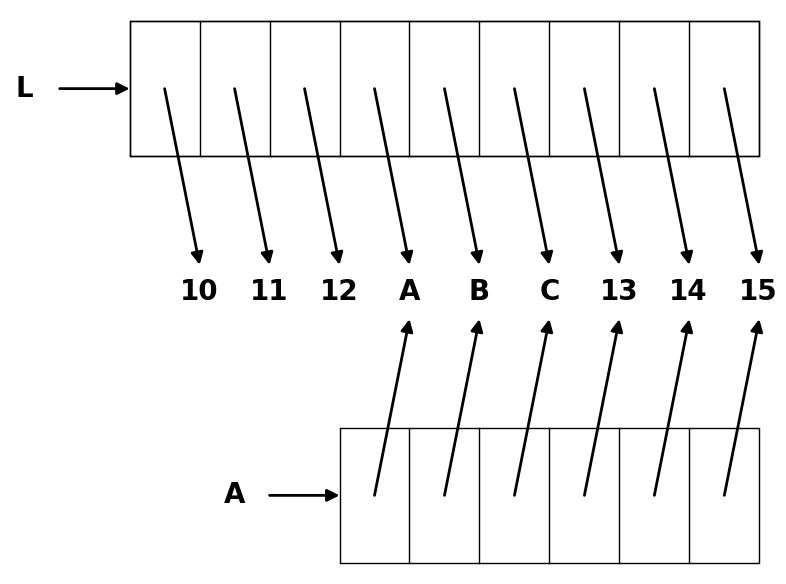
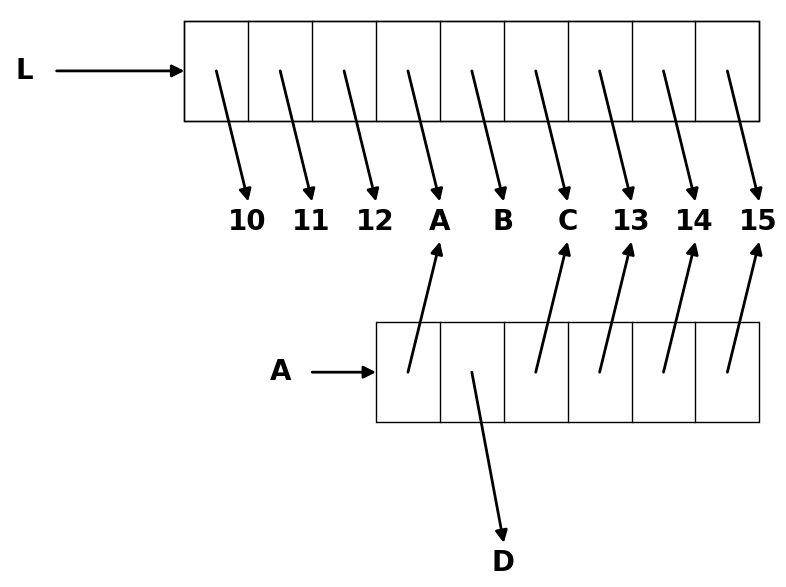
Le terme anglais de slice est associé à l’idée de découpage (une part de gâteau ou de pizza). En programmation, et en Python en particulier, un slice permet le découpage de structures de données séquentielles, typiquement les chaînes de caractères ou les listes.
Les slices sont des expressions du langage Python qui vous permettent en une ligne de code d’extraire des éléments d’une liste ou d’une chaîne. Deux exemples :
- Vous avez une variable
datequi référence une date sous le format jj/mm/aaaa et vous voulez extraire juste le mois de cette date. Avec un slice, vous l’obtiendrez juste avec ceci :date[3:5]. - Vous voulez savoir si un fichier est un fichier python (donc si son nom se termine par l’extension .py) alors vous aurez juste à écrire
nom[-3:]=='.py'et on pourrait, aussi simplement, généraliser au test de n’importe quelle extension de fichier.
L’intérêt des slices est essentiellement la concision et la souplesse de leur syntaxe et le fait qu’elles économisent beaucoup de code (des instructions for ou if, des créations de listes intermédiaires, de la gestion d’indices, etc).
Ce tutoriel est assez long car il se veut complet sur le sujet, il entre dans les détails et donne beaucoup d’exemples, accessibles et moins accessibles. Toutefois, une fois compris le formalisme des slices, la notion est simple et limitée et 80% de l’usage réel des slices se résume dans le tableau à la fin de la section 1. Le coeur du document est constitué des deux premières sections. Le reste doit être considéré comme avancé et marginal.
La version utilisée sera Python 3. L’essentiel s’adapte à Python 2 même s’il y a quelques différences pour les slices personnalisés.
Les prérequis
L’essentiel de la 1e section est très élémentaire et abordable si on a déjà manipulé des listes ou des chaînes. Les indices négatifs d’une séquence sont expliqués. Seul un des exemples est un peu élaboré (fonction, méthode str.join, liste en compréhension).
La section 2 est aussi d’un niveau assez élémentaire mais sera peut-être moins abordable que la précédente, rien que parce que les opérations d’écriture possibles sont réalisables sans slice, ce qui interrogera le débutant sur la pertinence d’utiliser des slices. Le code des deux exemples d’application est assez concis et pas forcément immédiatement lisible par un débutant mais les notions utilisées sont assez basiques (fonction, addition et itération de listes, instructions for et if, listes en compréhension imbriquées).
La section 3 concerne les slices avancées et est beaucoup moins abordable. Il faut avoir pratiqué la POO, et déjà utilisé des méthodes spéciales (surcharges d’opérateur), éventuellement l’héritage de classe built-in (pour la première illustration). L’illustration 2 utilise sans rappel des méthodes de la classe standard date.
Les annexes concernent des questions variées : il s’agit de questions marginales, ou de compléments ou de précisions détaillées sur des notions abordées dans les trois sections du document.
Je remercie Vayel et yosh de leur relecture. Ce dernier a permis de rectifier une erreur dans la version bêta. Merci également à jido dont la lecture attentive a permis de détecter et de corriger une erreur dans l’activité Extraction de diagonales, cf. son commentaire. Enfin, lewoudar m’a signalé un lapsus (28 février au lieu de 29 dans la dernière partie).
Le logo est basé sur une image d’accès libre fournie par openclipart et retouchée par Diégo que je remercie.
Slices en lecture
Slices avec deux indices
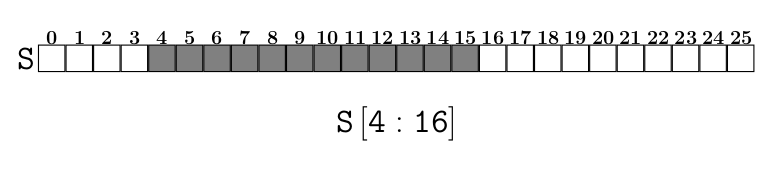
Soit S une séquence, par exemple une chaîne ou une liste. Une expression de la forme S[4:16] est un slice dans sa syntaxe de base. Cette syntaxe utilise deux indices, ici les indices 4 (indice de début du slice) et 16 (indice de fin du slice).
Voici un exemple typique de slice de base :
alpha = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
print(alpha[4:16])
EFGHIJKLMNOP
alpha[4:16] est un slice et désigne la chaîne extraite de la chaîne alpha dont les éléments sont situés :
- à droite de l’élément d’indice 4,
- strictement à gauche de l’élément d’indice 16, autrement dit jusqu’à l’indice 15 inclus
ce qui graphiquement donne :
Plus généralement,
Si i et j sont des indices positifs, la syntaxe S[i:j] désigne la séquence, de même nature que S, formée des éléments S[k] où k vérifie . Noter l’intervalle entier semi-fermé : le terme d’indice de droite n’est jamais inclus dans le slice obtenu.
Un slice peut être vide :
alpha = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
s = alpha[10:8]
print(len(s))
0
Si un slice t est construit à partir d’une séquence s alors t est de même type que s, autrement dit si s est une chaîne alors t est aussi une chaîne, si s est une liste alors t est une liste, etc.
Voici justement un exemple de slice de base construit sur une liste :
L = [65, 31, 9, 32, 81, 82, 46, 12]
print(L[2:6])
[9, 32, 81, 82]
Les slices s’appliquent essentiellement à des chaînes, des listes et des tuples.
En revanche, les slices étant construits à partir d’indices entiers, ils n’ont pas de sens pour des structures de données non ordonnées comme des dictionnaires ou des ensembles.
Dans un slice, des espaces autour du symbole deux-points peuvent ou non être insérées, et on pourra, si on est pointilleux, suivre les recommandations de la PEP 8. Ainsi, on écrira plutôt L[2:6] que L[2 : 6].
Application : segmenter un numéro de téléphone
Vous voulez segmenter une chaîne de caractères à intervalles réguliers par un séparateur donné ; typiquement, pour un numéro de téléphone, 0942371804 devient 09-42-37-18-04.
Si s est la chaîne, on la découpe en tranches de longueur la période p avec un slice de la forme s[k*p:(k+1)*p] qu’on place ensuite dans une liste en compréhension dont on rassemble les éléments tout en insérant le séparateur avec la méthode join. D’où le code suivant :
def insert_sep(s, sep, period):
return sep.join([s[k*period:(k+1)*period] for k in range(len(s)//period)])
tel="0942371804"
print(tel, "->", insert_sep(tel, '-',2))
0942371804 -> 09-42-37-18-04
Indices négatifs
Un indice strictement négatif dans une liste permet d’accéder à la liste en se référant à la fin de la liste. Par exemple, L[-5] désigne le 5e élément de L à partir de la fin.
Dans le cas d’une séquence de longueur 8 (c’est juste un exemple), voici une visualisation de la correspondance entre indices négatifs et indices positifs :
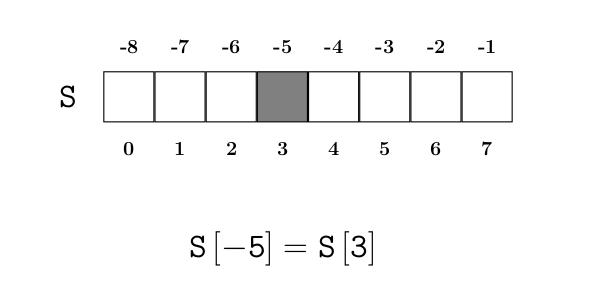
Exemple de code :
L = [65, 31, 9, 32, 81, 82, 46, 12]
print(L[-5])
print(L[-1])
print(L[-2])
32
12
46
Commentaire de code
- Lignes 3 et 6 : le 5ème élément avant la fin.
- Lignes 4 et 7 : le dernier élément de la liste.
- Lignes 5 et 8 : l’avant-dernier élément de la liste.
Les indices d’un slice peuvent être des entiers négatifs, la signification étant exactement la même que pour des indices positifs :
alpha = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
s = alpha[5:-3]
print(s)
s = alpha[-5:24]
print(s)
s = alpha[-5:-1]
print(s)
FGHIJKLMNOPQRSTUVW
VWX
VWXY
Dépassement et omission d’indice
À la différence des séquences, les slices tolèrent le dépassement d’indice, à droite ou à gauche (avec un indice négatif) : les portions du slice qui « dépassent» à droite ou à gauche sont ignorées. Exemples :
alpha = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
print(alpha[20:50])
print(alpha[-50:8])
UVWXYZ
ABCDEFGH
Commentaire de code
- Ligne 2 : comme
50 > len(alpha) = 26, c’est comme si on avait écrits = alpha[20:26]. - Lignes 3 : la chaîne est en fait identique à
alpha[-26:8].
D’autre part, quand un slice se réfère à une des deux extrémités de la séquence, un raccourci syntaxique permet d’omettre l’indice de début ou de fin. Par exemple, le slice s[:j] est synonyme de s[0:j] (que l’indice soit positif ou non).
Voici des exemples typiques :
alpha = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
# Les 5 premiers
print(alpha[:5])
# Les 5 derniers
print(alpha[-5:])
# Tous sauf les 5 premiers
print(alpha[5:])
# Tous sauf les 5 derniers
print(alpha[:-5])
ABCDE
VWXYZ
FGHIJKLMNOPQRSTUVWXYZ
ABCDEFGHIJKLMNOPQRSTU
Il est même possible d’ignorer les deux indices. Le slice s[:] est alors défini comme s[0:n] où n est la longueur de s :
L = [81, 42, 31, 12]
M = L[:]
print(L)
print(M)
[81, 42, 31, 12]
[81, 42, 31, 12]
Le slice s[:] crée ce qu’on appelle une copie superficielle de s.
Slices étendus
La syntaxe des slices admet une extension autorisant un 3e entier entre les crochets : s[i:j:k]. Cet entier k désigne un pas (step en anglais), comme quand on compte par pas de k, par exemple de 3 en 3.
Exemple :
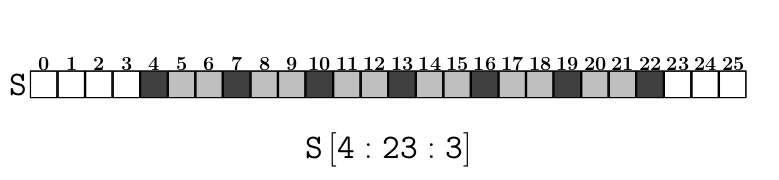
alpha = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
s = alpha[4:23:3]
print(s)
EHKNQTW
Commentaire de code
- Lignes 2 et 4 :
sest la chaîne formée des éléments de la chaînealphad’indices allant de 3 par 3 entre l’indice 4 inclus et l’indice 23 exclu.
L’exemple ci-dessus en visuel :
Le pas d’un slice ne peut être nul sinon une exception est levée. D’autre part, si dans le slice s[i:j:k], l’entier k est négatif, on compte de -k en -k en arrière à partir de la position d’indice i. Par exemple :
alpha = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
s = alpha[23:4:-3]
print(s)
XUROLIF
Comme pour les slices avec deux indices, les indices peuvent être négatifs et/ou absents. Voici des formes très utilisées en pratique :
L = [10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25]
# de 5 en 5 depuis l'indice 4
# -> [14, 19, 24]
print(L[4::5])
# de 3 en 3 entre le 5ème et le 2ème avant la fin
# -> 15, 18, 21]
print(L[5:-2:3])
# extraire de 5 en 5
# -> [10, 15, 20, 25]
print(L[::5])
# extraire de 5 en 5 à partir de la fin
# -> [25, 20, 15, 10]
print(L[::-5])
# éléments d'indices pairs
# -> [10, 12, 14, 16, 18, 20, 22, 24]
pairs = L[::2]
print(pairs)
# éléments d'indices impairs
# -> [11, 13, 15, 17, 19, 21, 23, 25]
impairs = L[1::2]
print(impairs)
Un cas particulier très pratique est l’inversion de séquence avec un slice de pas valant :
alpha = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
s = alpha[23:4:-1]
print(s)
XWVUTSRQPONMLKJIHGF
En particulier, s[::-1] renvoie la séquence complète inversée :
alpha = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
s = alpha[::-1]
print(s)
ZYXWVUTSRQPONMLKJIHGFEDCBA
ce qui permet d’écrire une fonction de détection de palindrome :
def isPalindrome(s):
return s == s[::-1]
print(isPalindrome("aziza"))
True
Tableau des idiomes sur les slices
Le tableau résume ce que l’on utilise des slices dans 80% de la pratique.
| Action | Code | Exécution (s = "ABCDEFGHIJKL") |
|---|---|---|
| Extraction | s[2:7] |
CDEFG |
| Les 4 premiers | s[:4] |
ABCD |
| Les 4 derniers | s[-4:] |
IJKL |
| Tous sauf les 4 premiers | s[4:] |
EFGHIJKL |
| Tous sauf les 4 derniers | s[:-4] |
ABCDEFGH |
| Partitionner | s[:3], s[3:7], s[7:] |
('ABC', 'DEFG', 'HIJKL') |
| De 3 en 3 | s[::3] |
ADGJ |
| De 3 en 3 à partir de la fin | s[::-3] |
LIFC |
| Les indices pairs | s[::2] |
ACEGIK |
| Les indices impairs | s[1::2] |
BDFHJL |
| Copie superficielle | s[::] |
ABCDEFGHIJKL |
| Copie à l’envers | s[::-1] |
LKJIHGFEDCBA |
Slices en écriture
La syntaxe des slices permet aussi de modifier une liste suivant une tranche :
L = [10, 11, 12, 13, 14, 15, 16, 17, 18, 19]
T = "ABCD"
L[2:8] = T
print(L)
[10, 11, 'A', 'B', 'C', 'D', 18, 19]
Si L est une liste et si M un itérable quelconque alors l’affectation L[i:j] = M est effectuée ainsi :
- tous les éléments de
Laux positionsrange(i, j)sont retirés de la listeL; - les éléments de l’itérable
Msont insérés à partir de l’endroit où les éléments ont été retirés.
Pour ne pas se tromper d’indice, remarquer que l’indice du 1e élément inséré est exactement le 1e indice du slice :
L = [10, 11, 12, 13, 14, 15, 16, 17, 18, 19]
T = "ABCD"
g = 2
L[g:8] = T
print(L[g])
A
Voici, résumé en code, quelques actions de complétion ou de suppression :
# Insérer sans supprimer
L = [10, 11, 12, 13, 14, 15]
L[3:3] = "ABC"
print(L)
# -> [10, 11, 12, 'A', 'B', 'C', 13, 14, 15]
# Étendre L
L = [10, 11, 12, 13, 14, 15]
L[len(L):] = "ABC"
print(L)
# [10, 11, 12, 13, 14, 15, 'A', 'B', 'C']
# Effacer une tranche
L = [10, 11, 12, 13, 14, 15]
L[1:4] = []
print(L)
# -> [10, 14, 15]
# Suppression d'une tranche avec del
L = [10, 11, 12, 13, 14, 15]
del L[1:4]
print(L)
# -> [10, 14, 15]
Des modifications de listes sont également possibles avec des slices étendus. Résumé en code :
# Remplacer
L = [10, 11, 12, 13, 14, 15, 16, 17, 18, 19]
print(L[1:8:2]) # -> [11, 13, 15, 17]
L[1:8:2] = "ABCD"
print(L)
# -> [10, 'A', 12, 'B', 14, 'C', 16, 'D', 18, 19]
# Supprimer
L = [10, 11, 12, 13, 14, 15, 16, 17, 18, 19]
del L[1:8:2]
print(L)
# -> [10, 12, 14, 16, 18, 19]
La taille du slice et la taille du remplacement doivent correspondre sinon une exception est levée :
L = [10, 11, 12, 13, 14, 15, 16, 17, 18, 19]
L[1:8:2] = "ABC"
print(L)
ValueError: attempt to assign sequence of size 3 to extended slice of size 4
Application : le crible d’Ératosthène
Un exemple d’application remarquable de la modification d’une liste avec des slices est le crible d’Ératosthène.
Le crible d'Ératosthène permet de lister tous les nombres premiers entre 1 et où est donné. Le principe de ce crible est que l’on part d’une liste L des entiers entre 0 et et on crible L (autrement dit, on raye de L) les multiples de pour certains bien choisis en sorte que, à la fin du criblage de L, il ne reste plus que des nombres premiers dans L. En pratique, l’implémentation informatique est un peu différente car
- au lieu d’utiliser la liste
Ldes entiers entre 0 et on utilise une listecribleindexée de 0 à (cf. le code ci-dessous), contenant des booléens et qui indiquent, à chaque indice , si l’entier est premier (True) ou non (False) ; - pour cribler, on change un
TrueenFalsedans la liste.
Naturellement, le fait de cribler des multiples de dans une liste fournit une utilisation presque idéale des slices étendus.
Voici le crible avec des slices en action :
def eratosthene_slice(n):
crible=[False,False]+[True]*(n-1)
for d in range(int(n**0.5)+1):
if crible[d]:
crible[d*d::d]=[False]*(n//d -d+1)
return crible
c=eratosthene_slice(50)
for i in range(len(c)):
if c[i]:
print(i, end= ' ')
print()
2 3 5 7 11 13 17 19 23 29 31 37 41 43 47
Commentaire de code
- Lignes 1–6 : La fonction renvoie une liste qui sera le crible d’Ératosthène indiquant les entiers premiers entre 0 et (inclus).
- Ligne 2 : la liste qui va être criblée. Ce n’est pas la liste des entiers jusqu’à mais une liste de booléens indexée de 0 à (et contenant donc entiers).
- Ligne 2 : au départ, tout le monde est considéré comme premier, sauf 0 et 1 d’où les deux premiers
Falsede la liste. - Ligne 3 : toute l’efficacité de la méthode du crible est dans la racine carrée .
- Ligne 4–5 : on peut montrer que l’exécution ne passe la condition
ifque sidest premier. - Ligne 5 : c’est ici le cœur du programme, là où intervient le criblage et le slice. Comme tout multiple de
d(distinct ded) est, bien entendu, non premier, il faut basculer àFalsetous les booléens situés aux indices multiples de entre et . Pourquoi pas avant ? Parce ces multiples ont déjà été rayés à une étape précédente de la bouclefor. - Ligne 5 : un point délicat du programme ; pour avoir la bonne taille du slice cible, il faut soigneusement compter le nombre de multiples de tels que et on trouve assez facilement
n//d -d+1. - Ligne 9 : pour rendre le code plus accessible,
enumeraten’a pas été utilisé.
Extraction de diagonales
On se donne un tableau 2D de lignes et de colonnes et on demande de déterminer le contenu d’une diagonale donnée. On va se limiter aux diagonales descendantes. Pour se repérer, la diagonale principale, celle qui commence en haut à gauche, est indexée par 0. Ensuite chaque diagonale en-dessous de (ou égale à) la diagonale principale est repérée par un indice dans range(n), et au-dessus, par un indice de range(p). Par exemple, dans la grille ci-dessous :

la diagonale d’indice 3 au-dessus de la diagonale principale est : B, E, O, E, U, S :

Pour déterminer le contenu d’une diagonale, il suffit de remarquer que, si on convertit le tableau 2D (disons T) en son équivalent 1D (disons L) suite à un parcours par lignes, chaque élément de la diagonale cherchée est placé à des indices de L qui sont régulièrement espacés, plus précisément de . Ensuite, après un éventuel petit calcul, on détermine quand il faut s’arrêter dans L pour ne pas sortir du tableau T. D’où le code :
T =[
'REABRASES',
'ENCRENENT',
'OCTOCORDE',
'RAVAUDERA',
'CHICORIUM',
'EPARTIRAS',
'RENIERONS',
'ALTERANTE',
'SASSASSES']
L = [c for line in T for c in line]
n = len(T)
p = len(T[0])
# Diagonales au-dessus de la diagonale principale
for k in range(p):
diago = L[k:p*min(n,p-k):p+1]
print(' '.join(diago))
print()
# Diagonales en-dessous de la diagonale principale
for k in range(n):
diago = L[k*p:p*min(n,p+k):p+1]
print(' '.join(diago))
R N T A O I O T S
E C O U R R N E
A R C D I A S
B E O E U S
R N R R M
A E D A
S N E
E T
S
R N T A O I O T S
E C V C T R N E
O A I R E A S
R H A I R S
C P N E A
E E T S
R L S
A A
S
Commentaire de code
- Ligne 12 : extraction (« applatissement ») du tableau 2D ligne par ligne en une liste
L. - Lignes 18–20 et 24–26 :
kreprésente l’indice de la diagonale que l’on va afficher. Rappel : l’indice zéro est celui de la diagonale principale. - Lignes 18–20 : c’est le cas le plus facile. Il est immédiat que l’on se déplace de en dans L (pour le voir, lire les déplacements sur le tableau 2D). Le début du slice est clairement
k. La fin du slice se devine car les indices dansLde la première colonne deTsont les multiples dep. - Lignes 24–26 : c’est très analogue.
Slices personnalisés
L’objectif de ce paragraphe est de construire des classes autorisant des slices, en quelque sorte « vos » slices. Pour cela, il faut connaître la syntaxe générale des slices ainsi que les objets de type slice.
Syntaxe complète d’un slice
La syntaxe qu’on a rencontrée, et qui est la plus courante pour un slice, est de la forme s[i:j] ou s[i:j:k], les indices i, j et k pouvant être omis. Cependant, la syntaxe complète d’une opération de slicing offre davantage de possibilités. Ainsi, un code pourrait contenir la syntaxe suivante :
ma_seq[12, 10:(14, 22):-2, (5,33), 2:]
Cette syntaxe curieuse est bien celle d’un slice ! La principale différence de la syntaxe complète avec la syntaxe antérieure est que
- il peut y avoir plusieurs slices entre les crochets ; dans l’exemple ci-dessus, on en compte 4, séparés par des virgules ;
- les « indices » ne sont plus forcément entiers ; dans l’exemple ci-dessus, on dispose ainsi de l’«indice»
(5,33).
Chacun de ces «items» placés entre les crochets et séparés par des virgules, peut avoir deux formes :
- des expressions, ci-dessus 12 ou encore le tuple
(5, 33); - des slices «propres», ci-dessus
10:(14, 22):-2ou encore2:(qui contiennent une ou deux fois le symbole deux-points et appelés proper slice dans la documentation officielle).
Cependant, tout type de séquence ne supporte pas cette syntaxe ; par exemple, pour une liste :
L = [65, 31, 9, 32, 81]
print(L[1:3, 2:4])
print(L[1:3, 2:4])
TypeError: list indices must be integers, not tuple
En effet, et c’est la clé de personnalisation des slices, la sémantique d’un slice est déterminée par la méthode __getitem__ de la séquence appelée ; or, dans l’exemple ci-dessus, la méthode __getitem__ de la classe list n’accepte entre des crochets d’indexation :
- soit qu’une seule expression, par exemple
L[3]; - soit qu’un seul slice propre, par exemple
L[2:4].
Cependant, dans l’idée de créer des slices personnalisés, vous pouvez définir une classe puis créer (ou surcharger) la méthode __getitem__ de cette classe afin de pouvoir utiliser la syntaxe complète des slices sur des instances de votre classe. Voici un exemple sans intérêt sauf d’illustrer la syntaxe :
class Ma_seq:
def __getitem__(self, index):
print(index)
ma_seq = Ma_seq()
ma_seq[12, 10:(14, 22):-2, (5,33), 2:]
(12, slice(10, (14, 22), -2), (5, 33), slice(2, None, None))
Le type slice
Observons le code suivant :
alpha = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
s = alpha[5::4]
t = alpha[slice(5, None, 4)]
print(s)
print(t)
FJNRVZ
FJNRVZ
Commentaire de code
- Ligne 3 : noter l’appel à la mystérieuse fonction
slice. - Lignes 2 et 3 : noter les analogies.
Lorsqu’un slice tel que s[3::2] est créé, en réalité, Python appelle s[slice(3, None, 2)] où slice est une fonction built-in de Python.
La fonction slice est en fait le constructeur de la classe du même nom. Comme on s’y attend, un objet de la classe slice possède des attributs désignant le début(start), la fin (stop) et le pas (step) du slice :
s = slice(5, None, 4)
print(s.start, s.stop, s.step)
5 None 4
Habituellement, ces attributs ont des valeurs entières mais rien n’y oblige, par exemple, ci-dessous, un des « indices » est un tuple :
s = slice(10, (14, 22), -2)
print(s.stop)
(14, 22)
Signalons qu’on peut utiliser le retour de slice pour «habiller» une extraction valable pour toute séquence :
# Permet d'extraire les éléments
# d'indices impairs de n'importe quelle séquence
impairs = slice(1, None, 2)
alpha = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
print(alpha[impairs])
# -> BDFHJLNPRTVXZ
L = [10, 11, 12, 13, 14, 15]
print(L[impairs])
# -> [11, 13, 15]
Implémentation d’un slice et applications
Conseil : en parallèle des explications un peu générales qui viennent, lisez la 1re illustration ci-dessous, ce sera plus digeste  .
.
La connaissance du mécanisme de génération d’un slice permet de créer des slices personnalisés. Lorsqu’un slice dans sa syntaxe complète s[slice_list] est créé, alors
- si
slice_listne contient qu’un seul slice, comme dans le slices = alpha[5::4]alorsslice_listest converti avec la fonctionsliceet l’objet de type slice obtenu est passé en argument às.__getitem__; - si
slice_listcontient plusieurs items slice, comme dansma_seq[12, 10:14:-2, (5,33), 2:]qui contient 4 items slice, chaque slice propre (comme10:14:-2) est converti en objet de type slice et chaque expression (comme12) est laissée intacte et, après conversion, les items slice sont passés en argument sous forme de tuple às.__getitem__.
Dans tous les cas, le retour de s.__getitem__ détermine la valeur du slice.
Illustration 1 : concaténation de slices
Construisons une classe nommée StrMultipleSlices, qui hérite de la classe str et dont les slices agiront comme le montre l’extrait de code suivant :
# Code de StrMultipleSlices omis
alpha = StrMultipleSlices("ABCDEFGHIJKLMNOPQRSTUVWXYZ")
print(alpha[5:9, 5, 10:4:-1, 20:])
FGHI-F-KJIHGF-UVWXYZ
Commentaire de code
- Ligne 4 : la classe permet d’utiliser des slices dans leur syntaxe complète.
- Lignes 4 et 5 : l’action d’un slice sur une chaîne
alphade typeStrMultipleSlicesrenvoie la concaténation des différents slices placés entre crochets après les avoir sépares par un tiret.
Voici le code complet commenté :
class StrMultipleSlices(str):
def __getitem__(self, slide_list):
try:
return super().__getitem__(slide_list)
except TypeError:
S=[]
for slide_item in slide_list:
S.append(super().__getitem__(slide_item))
return '-'.join(S)
alpha = StrMultipleSlices("ABCDEFGHIJKLMNOPQRSTUVWXYZ")
print(alpha[5:9, 5, 10:4:-1, 20:])
FGHI-F-KJIHGF-UVWXYZ
Commentaire de code
- Ligne 1 : la classe hérite de la classe
stren sorte qu’on va effectuer des slices de chaînes. - Ligne 3 : pour obtenir des slices personnalisés, on surcharge la méthode
__getitem__. - Ligne 14 : lorsque le slice est appelé, c’est un tuple de 4 élements qui est envoyé à
__getitem__via le paramètreslide_list(ligne 5). Ainsi, les deux premiers éléments de ce tuple sont :slice(5, 9, 1)et5. - Ligne 5 : en cas de slice unique, on laisse agir les slices de la classe mère
str. - Lignes 6–9 : sinon, une exception est levée et on laisse agir séparément les slices de la classe
str(cf.super()ligne 9) tout en plaçant chaque slice obtenu dans une liste (cf.appendligne 9). - Lignes 11 et 15 : il ne reste plus qu’à concaténer les chaînes de la liste en les séparant par un tiret.
Illustration 2 : périodes dans une année
On va créer une classe Annee représentant une année donnée en argument à la classe, par exemple Annee(2016). Cette classe représentera une séquence de jours et permettra de déterminer, en utilisant la syntaxe des slices, tous les jours entre deux dates données. Voici un exemple d’utilisation de la classe Annee:
# code de Annee omis
a=Annee(2016)
print(a[(22, 2):(5, 3):2])
print(a[(25,12):])
print(a[14,7])
[(22, 2), (24, 2), (26, 2), (28, 2), (1, 3), (3, 3)]
[(25, 12), (26, 12), (27, 12), (28, 12), (29, 12), (30, 12), (31, 12)]
(14, 7)
Commentaire de code
- Ligne 3 : une instance représentant l’année 2016.
- Ligne 4 : la syntaxe d’un slice dont les indices sont des jours ; ici, on liste les jours de 2 en 2 entre le 22 février 2016 et le 4 mars 2016 inclus. Noter (ligne 7) que le 29 février existe en 2016.
- Ligne 5 : idem pour les jours de l’année après Noël 2016 avec un indice implicite.
- Ligne 6 : appliqué à un unique jour, le slice renvoie le jour en question (ligne 9).
Afin de limiter les calculs, le code de Annee utilise la classe date du module standard datetime de gestion des dates.
Le principe d’obtention des jours entre les deux dates données et avec un pas donné utilisé par la classe Annee est le suivant :
- grâce au module
datetime, les deux jours du slice sont convertis en deux «numéros» (le terme exact est «ordinaux») ; - on appelle ensuite la fonction
rangesur ces numéros et avec le pas pour obtenir les numéros des jours de l’intervalle ; - enfin, à nouveau avec l’aide du module
datetime, on reconvertit ces numéros en jours.
Voici maintenant le code complet et commenté de la classe Annee :
from datetime import date
class Annee:
def __init__(self, an):
self.an = an
self.debut_ordinal=date(an, 1,1).toordinal()
self.fin_ordinal=date(an+1, 1,1).toordinal()
def __getitem__(self, index):
if isinstance(index, slice):
start, stop, step = index.start, index.stop, index.step
an=self.an
start=date(an, start[1], start[0]).toordinal() if start is not None else self.debut_ordinal
stop=date(an, stop[1], stop[0]).toordinal() if stop is not None else self.fin_ordinal
if step is None:
step=1
return [(date.fromordinal(num).day, date.fromordinal(num).month) for num in range(start, stop, step)]
else:
return index
a=Annee(2016)
print(a[(22, 2):(5, 3):2])
print(a[(25,12):])
print(a[14,7])
[(22, 2), (24, 2), (26, 2), (28, 2), (1, 3), (3, 3)]
[(25, 12), (26, 12), (27, 12), (28, 12), (29, 12), (30, 12), (31, 12)]
(14, 7)
Commentaire de code
- Lignes 5 et 22 : une instance de
Anneenécessite de connaître l’année. En fait, deux instances ne diffèrent au plus que par un 28 février absent ou présent. - Ligne 8 : À cause de slices de la forme
a[(25,12):](cf. ligne 24), on a besoin de calculer le numéro correspondant au premier janvier de l’année suivante. - Lignes 23–25 : si on calcule un slice sur un objet de type
Annee, la méthode__getitem__(ligne 9) est appelée et le paramètreindexest de typeslice. - Ligne 18 :
__getitem__renvoie une liste de jours calculée avec les méthodesfromordinalettoordinal. - Lignes 14 et 15 : chaque «indice» du slice est un tuple
(jour, mois), cf. par exemple le tuplestartavecstart[1]etstart[0]ligne 14. - Lignes 14 et 15 : chaque date est convertie successivement en le type
datededatetimepuis en ordinal. - Lignes 14 et 15 : chacune des expressions conditionnelles (les deux
if ... else ...) permet de gérer un slice implicite qui commence en début d’année (cf. l’attributdebut_ordinal) ou se termine en fin d’année (cf. l’attributfin_ordinal). - Lignes 16 et 17 : si le troisième indice de slice est absent, le slice s’assimile à un slice de base et cela signifie que le pas est de 1.
- Lignes 27 et 28 : pour un calcul de slice entre deux jours, la liste des jours est renvoyée. Un jour est présenté sous la forme d’un tuple jour et mois.
Illustration 3 : sous-matrice
Par matrice, on entend ici un simple tableau 2x2 de nombres entiers. On veut créer une classe représentant des matrices et permettant d’extraire, avec la syntaxe des slices, une sous-matrice dont les éléments sont régulièrement espacés sur les lignes et les colonnes de la matrice initiale.
Par exemple, on dispose de la matrice suivante :
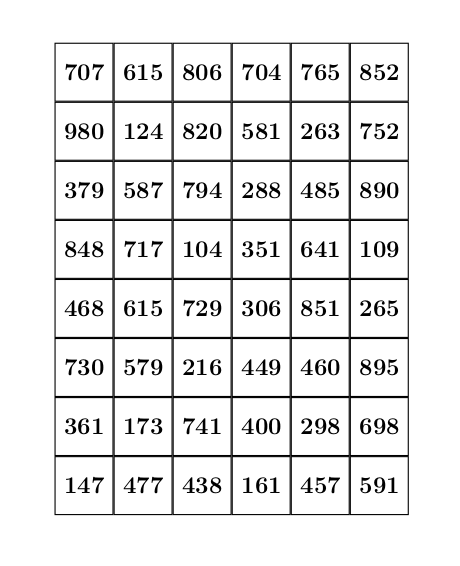
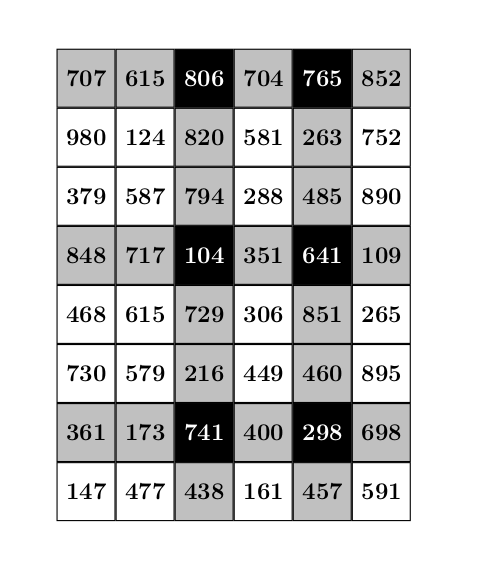
et on veut extraire la sous-matrice telle que
- ses lignes sont les lignes de , extraites 3 par 3 en commençant à l’avant-dernière ligne,
- ses colonnes sont les colonnes d’indices pairs à partir de la 2e colonne.
On cherche donc à extraire les éléments marqués en noir ci-dessous :
Voici un exemple de fonctionnement du programme et son affichage :
# Code de Matrix omis
array=[
[707, 615, 806, 704, 765, 852],
[980, 124, 820, 581, 263, 752],
[379, 587, 794, 288, 485, 890],
[848, 717, 104, 351, 641, 109],
[468, 615, 729, 306, 851, 265],
[730, 579, 216, 449, 460, 895],
[361, 173, 741, 400, 298, 698],
[147, 477, 438, 161, 457, 591]
]
M=Matrix(array)
print(M[-2::-3, 2::2])
741 298
104 641
806 765
Commentaire de code
- Ligne 15 : observer les deux slices entre les crochets.
Pour parvenir au résultat, on crée une classe Matrix et on va lui implémenter la méthode __getitem__.
L’implémentation va permettre d’extraire aussi bien un élément de la matrice qu’une sous-matrice. Plus précisément, pour extraire par exemple l’élément à la ligne d’indice 5 et à la colonne d’indice 3, on écrira M[5, 3]. Pour extraire une sous-matrice, on utilisera la syntaxe de slice, par exemple M[-2::-3, 2::2]. Il est également possible de panacher les deux notations, par exemple M[5, 1:4].
Voici le code complet et commenté :
class Matrix:
def __init__(self, array):
self.nlines = len(array)
self.ncols = len(array[0])
self.array=[list(array[j]) for j in range(self.nlines)]
def __getitem__(self, index):
I=[None, None]
for i, item in enumerate(index):
if isinstance(item, slice):
I[i]=item
else:
I[i]=slice(item, item+1, 1)
M = self.array
n = self.nlines
p = self.ncols
ind_lines = range(n)[I[0]]
ind_cols = range(p)[I[1]]
sub_array =[[M[i][j] for j in ind_cols] for i in ind_lines]
return Matrix(sub_array)
def __str__(self):
return '\n'.join([' '.join(map(str, self.array[i])) for i in range(self.nlines)])
array=[
[707, 615, 806, 704, 765, 852],
[980, 124, 820, 581, 263, 752],
[379, 587, 794, 288, 485, 890],
[848, 717, 104, 351, 641, 109],
[468, 615, 729, 306, 851, 265],
[730, 579, 216, 449, 460, 895],
[361, 173, 741, 400, 298, 698],
[147, 477, 438, 161, 457, 591]
]
M=Matrix(array)
print(M)
print()
print(M[-2::-3, 2::2])
print()
print(M[5, 1:4])
print()
print(M[5, 3])
707 615 806 704 765 852
980 124 820 581 263 752
379 587 794 288 485 890
848 717 104 351 641 109
468 615 729 306 851 265
730 579 216 449 460 895
361 173 741 400 298 698
147 477 438 161 457 591
173 741 400
717 104 351
615 806 704
579 216 449
449
Commentaire de code
- Lignes 4–6 : on passe un tableau 2x2 (une liste de listes) à la matrice (ligne 37) et on en extrait, dans des attributs, les dimensions de la matrice ainsi que ses coefficients.
- Ligne 9 : par défaut, et pour simplifier, on suppose qu’entre les crochets de slices, on passe toujours à
Mune suite d’exactement 2 items (la taille deI), séparés par une virgule (attention, cette suite est juste de la syntaxe et, bien qu’en ayant l’apparence, ce n’est pas un tuple et ce n’est même pas un objet). Pour un code plus robuste, il faudrait capturer dans untry/exceptun nombre éventuellement incorrect d’items de slice. - Lignes 10 et 14 : chacun des deux items est transformé en objet de type
sliceet placé dans une liste. - Lignes 18 et 19 : on peut ensuite facilement extraire les indices de lignes et de colonnes recherchés en appliquant ces slices aux
rangedes nombres de lignes et de colonnes. - Lignes 23–24 : on implémente une méthode simpliste d’affichage mais qui donne des alignements corrects si les coefficients de la matrice sont des entiers ayant tous le même nombre de chiffres.
Ce type de slices est implémenté dans le logiciel mathématique Sagemath et, avec une plus grande envergure, dans la bibliothèque de calcul numérique NumPy.
Annexes
Les slices dans la doc officicielle
La documentation officielle est peu prolixe sur les slices (mais le sujet n’est pas si vaste). Pour une connaissance en profondeur, les points importants à lire sont les suivants :
-
le type slice,
-
la méthode
__getitem__, -
la syntaxe des slicings, sans doute la partie la moins abordable,
-
la description de la classe built-in slice,
-
la description de la fonction
itertools.islice.
Copie ou pas ?
Lorsqu’on effectue un slice (disons t) d’une liste ou d’un tuple (disons s), le contenu de s n’est jamais recopié. Les contenus de s et de t réfèrent aux mêmes objets, simplement lors de la création de t, des références vers les éléments du slice ont été créées. Autrement dit, une séquence s et un slice de s partagent les mêmes contenus.
Voici une illustration commentée :
from random import randrange
N=100
L = [randrange(100,1000) for _ in range(N)]
g, d = 42, 87
S = L[g:d]
for _ in range(5):
i = randrange(g, d)
print(L[i] is S[i-g])
True
True
True
True
True
Commentaire de code
- Ligne 4 : on construit une liste
Ld’entiers aléatoires entre 100 et 1000 [on choisit des entiers valant au moins 100 pour éviter l’effet de cache utilisé par défaut par Python sur les petits nombres]. - Ligne 5 : on construit un slice
Ssur la listeLentre les indices g (pour gauche) et d (pour droit). - Lignes 8–9 : on génère aléatoirement 5 entiers dans le slice
S. - Ligne 10 : on compare, non pas la valeur, mais l'identité de chacun des objets choisis dans le slice avec l’identité des éléments correspondants dans
L. - Lignes 11–15 : on constate que les identités sont les mêmes : il n’y a pas eu de copie d’objet, juste copie de références.
Le cas des chaînes est différent1. En effet, il se trouve que si s est une chaîne, alors toute indexation s[k], où s[k] est un caractère unicode d’ordinal à partir de 256, crée un nouveau caractère de valeur identique, cf. le code source de CPython. Comme toute opération de slicing sur une séquence effectue implicitement une indexation, tout slicing de chaîne recrée les caractères de la chaîne. Le code suivant illustre les changements :
D=1000
s = ''.join(chr(x) for x in range(D,D+3))
a, b, c = s[:]
print(s[0] == a)
print(s[0] is a)
True
False
Commentaire de code
- Ligne 1 : l’ordinal des caractères unicodes doit dépasser 256 (ici, à partir de 1000).
- Ligne 3 :
aest le premier item d’un slice des. - Lignes 4 et 5 : les deux caractères ont même valeur mais ne sont pas les mêmes en mémoire (le caractère référencé par
aest nouveau).
Coût d’un slice
Si s est un slice construit à partir d’une liste t, alors la création de s nécessite la copie de références vers les éléments de t que s référence. Par exemple, si t est une liste d’un million d’entiers alors t[:] va créer un million de références vers les éléments de t, comme cela est confirmé le code source de CPython. Relativisons toutefois : les slices restent un outil très efficace et l’expérience montre que le coût de création d’un slice est peu élevé.
La méthode indices
La méthode indices étant assez délicate à décrire, on va d’abord l’illustrer par le code ci-dessous :
alpha = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
N= len(alpha)
# Exemple 1
s = slice(12, 30, 2)
print(alpha[s])
begin, end, step = s.indices(N)
print(''.join([alpha[i] for i in range(begin, end, step)]))
print(begin, end, step)
print('----------------------------------')
# Exemple 2
s = slice(12, -30, -1)
print(alpha[s])
begin, end, step = s.indices(N)
print(''.join([alpha[i] for i in range(begin, end, step)]))
print(begin, end, step)
MOQSUWY
MOQSUWY
12 26 2
----------------------------------
MLKJIHGFEDCBA
MLKJIHGFEDCBA
12 -1 -1
La méthode indices
- s’applique à un objet de type slice (cf. lignes 5 et 8 et aussi lignes 15 et 18), disons
s; - prend un paramètre, disons
N, qui représente une longueur de séquence (ci-dessus, nombre de lettres de l’alphabet) ; - renvoie trois indices
a,betctels querange(a, b, c)corresponde aux indices des éléments d’une séquence de longueurNà laquelle le slicesserait appliqué.
Par exemple, dans le code ci-dessus, si s = slice(12, -30, -1) alors s.indices(26) est le triplet : en effet, range(12, -1, -1) contient exactement les indices des éléments du slice s appliqué à une séquence de longueur 26 telle que la chaîne des lettres de l’alphabet.
Attention, contrairement à ce que l’on pourrait penser dans un premier temps (et qu’on lit parfois), slice.indices(N) ne renvoie pas des indices de slice qui appliqués à un objet (disons O), de longueur N, coïnciderait avec le slice initial appliqué à O. Par exemple :
alpha = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
N= len(alpha)
# Exemple 1
s = slice(12, 30, 2)
begin, end, step = s.indices(N)
print(alpha[begin:end:step])
print(alpha[s])
print('----------------------------------')
# Exemple 2
s = slice(12, -30, -1)
begin, end, step = s.indices(N)
print(alpha[begin:end:step])
print(alpha[s])
MOQSUWY
MOQSUWY
----------------------------------
MLKJIHGFEDCBA
Commentaire de code
- Lignes 7–9 et 18–19 : dans le premier exemple, il se trouve que
s.indicesrenvoie effectivement des indices valables pour un slice. - Lignes 15–17 et 21–22 : cependant, ce n’est pas le cas dans le 2e exemple puisque le slice renvoyé en appliquant à
alphales indices de retour de la méthodesequenceest vide (ligne 21) alors que le slice initial n’est pas vide (ligne 22).
Slices et la fonction range
Observons le code suivant :
s = [65, 31, 9, 32, 81, 82, 46, 12]
i = 2
j = 6
t = s[i:j]
u = [s[k] for k in range(i, j)]
print(t)
print(u)
[9, 32, 81, 82]
[9, 32, 81, 82]
Commentaire de code
- Lignes 6 et 7 : noter l’analogie entre
s[i:j]etrange(i, j).
Plus généralement, si s est une séquence de longueur et si i et j sont deux indices :
- soit tous les deux positifs ou nuls,
- soit tous les deux strictement négatifs,
- éventuellement invalides pour
s,
alors on a l’égalité :
list(s[i:j]) == [s[m] for m in range(i, j) if m in range(-len(s),len(s))]
et même
list(s[i:j:k]) == [s[m] for m in range(i, j, k) if m in range(-len(s),len(s))]
En fait, on dispose de bien mieux que cela : la méthode slices.indices nous fournit justement la liste de tous les indices d’une liste L extraits par le slice L[i:j:k], autrement dit, l’égalité suivante est vraie sans aucune restriction, y compris si les indices sont implicites :
L[i:j:k]==[L[m] for m in range(*slice(i, j, k).indices(len(L)))]
Slices itérateurs
Jusqu’à présent, les slices utilisés sont des séquences telles que des listes ou des chaînes. Ces slices sont des itérables mais ne sont pas des itérateurs. Le cas d’un slice sur un range est analogue à celui des listes puisque le retour de range n’est pas non plus un itérateur ; ainsi, des slices de range sont encore de type range :
r = range(10, 20)
s = r[3::2]
print(type(s))
print(list(s))
<class 'range'>
[13, 15, 17, 19]
Toutefois, le module standard itertools permet de créer des slices qui ne seront pas des séquences mais plutôt des itérateurs. Pour créer de tels itérateurs, utiliser la fonction islice (écrite avec un seul s et qui abrège Iterator slice) :
from itertools import islice
alpha = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
alpha_iter = islice(alpha, 5, 22, 4)
print(alpha_iter)
print(list(alpha_iter))
print(list(alpha[5:22:4]))
<itertools.islice object at 0xb716102c>
['F', 'J', 'N', 'R', 'V']
['F', 'J', 'N', 'R', 'V']
Commentaire de code
- Lignes 4 et 8 :
alpha_iterest un itérateur, pas une chaîne. - Lignes 6–7 et 9–10 :
alpha_iterse comporte comme le slicealpha[5:22:4]sauf qu’il se contente d’itérer sur les éléments sans les stocker.
Les indices de l’itérateur sont les arguments donnés à la fonction islice. Les raccourcis de slices consistant à omettre les indices se traduisent pour islice par des arguments valant None. Par exemple, l’équivalent itérateur du slice s[2::-3] est islice(s, 2, None, -3). S’il n’y a que deux indices donnés en arguments, le troisième est considéré comme valant 1 ; par exemple, l’équivalent itérateur du slice s[2:5:] est islice(s, 2, 5) qui est équivalent à islice(s, 2, 5, 1) :
from itertools import islice
alpha = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
alpha_iter = islice(alpha, 3, 10)
print(list(alpha_iter))
print(list(islice(alpha, 3, 10, 1)))
['D', 'E', 'F', 'G', 'H', 'I', 'J']
['D', 'E', 'F', 'G', 'H', 'I', 'J']
Limitations
Une limitation cependant de la fonction islice : aucun des 3 arguments représentant les indices ne peut être négatif, cf. lignes 3 et 7 dans le code ci-dessous :
>>> from itertools import islice
>>> alpha = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
>>> alpha_iter = islice(alpha, 3, 10, -1)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: Step for islice() must be a positive integer or None.
>>> alpha_iter = islice(alpha, -10, 20, 2)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: Indices for islice() must be None or an integer: 0 <= x <= sys.maxsize.
>>>
D’autre part, curieusement, un objet de type islice ne conserve pas de trace des indices de slice passés en arguments et qui sont nommés habituellement start, stop et step (cf. tout retour de la fonction range) :
from itertools import islice
alpha = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
alpha_iter = islice(alpha, 3, 10, 2)
print(alpha_iter.start)
print(alpha_iter.start)
AttributeError: 'itertools.islice' object has no attribute 'start'
De même, les arguments d’indices de islice ne peuvent pas être nommés (alors que c’est possible d’ailleurs pour la fonction range) :
from itertools import islice
alpha = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
alpha_iter = islice(alpha, start=3, stop=10, step=2)
alpha_iter = islice(alpha, start=3, stop=10, step=2)
TypeError: islice() does not take keyword arguments
-
C’est yoch qui a attiré mon attention sur ce point lors d’une première version de ce document.
↩
Les slices, avec leur syntaxe concise et bien pensée, et leur implémentation au sein même du langage permettent au programmeur d’écrire rapidement du code efficace pour effectuer des opérations d’extraction et de remplacement de toutes sortes. Associés aux fonctionnalités de manipulation de séquences (somme, répétition, listes en compréhension, etc.), les slices sont un outil puissant, commode et accessible, en particulier dans des situations de manipulation de chaînes de caractères ou de tableaux multidimensionnels.