Hey, vous battez pas, on veut tous la même chose 
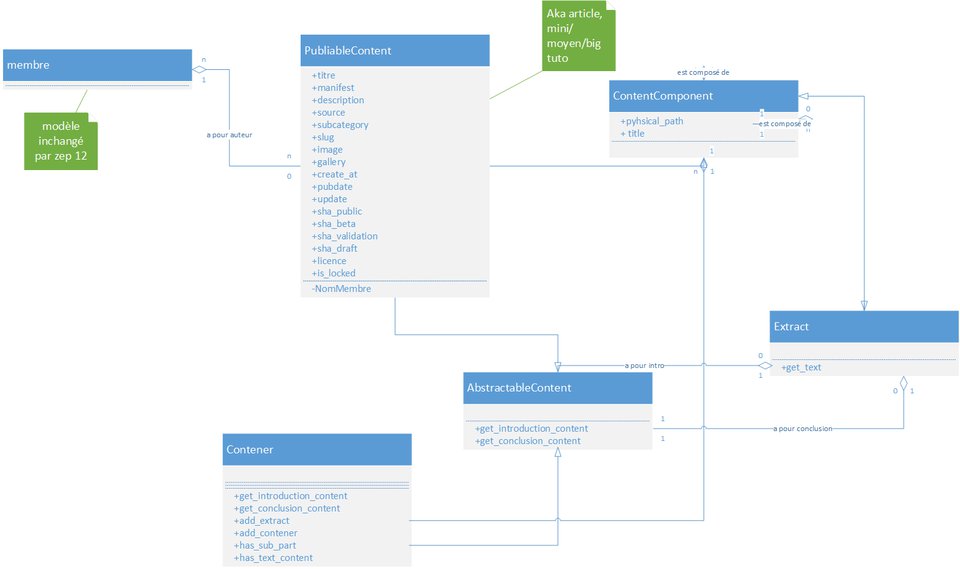
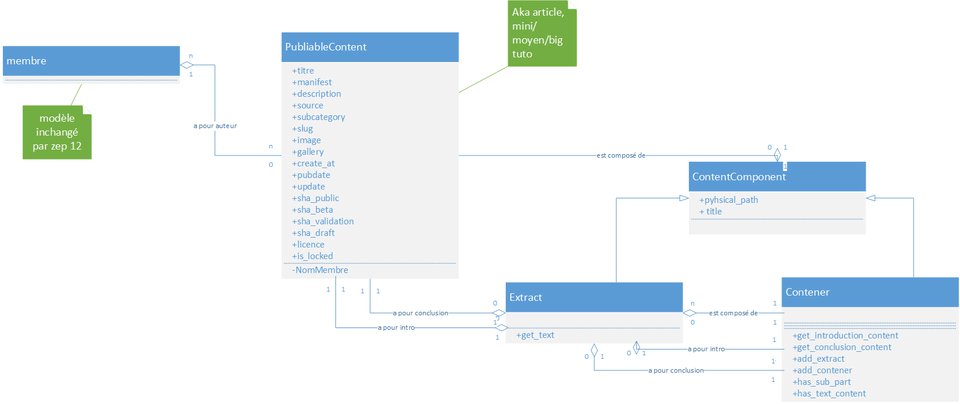
Déjà, je note qu'on a à peu près un consensus sur l'emploi des clés intro/conclu, donc on avance 
clé nominale/primaire/whatever, hash, pas hash ?
Pour moi, au contraire d'artragis, je pense que les problèmes de recouvrement vont plus loin qu'avec l'intro et la conclusion. Autant je vois effectivement mal l'utilisateur un extrait dont le slug tomberai justement sur p_introduction (d'ailleurs, c'est pas possible), ce qui veut pas dire non plus que c'est une bonne solution (pourquoi p_? est ce partie intégrante de la norme ou juste un truc de l'éditeur online pour se protéger ?), et j'était pas contre celle de Firm1 à l'époque, qui me semble tout à fait justifiée encore aujourd'hui.
Pour autant, comme le slug balance les caractères non-alphanumérique, on ne peut pas assurer qu'il n'y aura pas de recouvrement pour les noms d'extraits. J'ai du mal à trouver un exemple marquant, mais celui qui me vient à l'esprit (après 3 jours de recherches), ce serait un extrait dont le titre serait utilisation de { et } et un second qui serait utilisation de ? et :, qui donneraient à mon sens le même slug. Bien sur, mon exemple est complètement bancal, mais on ne peut pas exclure que ça puisse arriver, parce que l'auteur fait ce qu'il veut, donc pour moi, il faut une clé nominale.
Et il en faut d'autant plus une que je suis sensible à l'argument de Firm1 sur la recherche dans le JSON : au moment ou on se détachera de la base de donnée (j'en parle en dessous), il faudra d'une manière ou d'une autre qu'on valide l'url qui est donnée pour retourner le bon contenu. Si on commence à comparer les slugs de tout les sections de l'arborescence avec l'url, ça va être relativement long, il faut donc un truc un peu plus subtil, et c'est vrai qu'à ce niveau là, les pk étaient vachement pratiques, puisqu'il "suffisait" de faire un GET avec le bon pk et on était à peu près fixé, ce qui était vachement pratique. S'ouvre alors plusieurs options pour contourner ça :
- On s'en fout, et tant pis pour la surcharge, on vire la clé nominale ;
- On propose un mécanisme qui, comme le propose artragis, évite les recouvrements, et une fois encore, tant pis pour la clé nominale ;
- J'avais proposé que à l'exportation, un arbre soit créé afin de faciliter la tache le cas échéant, on aurait qu'à parcourir cet arbre pour valider une url ;
- On prend une clé nominale en forme de hash, mais j'avais pas réfléchi au fait que cette clé pouvais changer au cours du temps, il faut donc trouver un critère intelligent qui ne change pas ;
- On reste attaché à la base de donnée, au moins pour ça.
Pour autant, l'argument de la longueur de cette clé nominale ne tient pas, malgré le fait que le hash me parait à réflexion une idée pas si bonne que ça. Un hash à 6 caractère me semble déjà une bonne sécurité, et rien ne dit que dans l'avenir, on ne va pas passer les 10000 chapitres (on est déjà au alentours de 4000), ce qui ferait une clé nominale qui, à un caractère près, ferai la même taille.
Pourquoi selon moi, la base de donnée n'est pas une bonne idée
Parce que.
Déjà, je précise que je ne suis pas pour un abandon total de la base de donnée, comme j'ai déjà du le dire à l'une ou l'autre reprise : il faut au moins donner un pk au tutoriel et conserver ses auteurs, ainsi que ces métadonnées tels que les hash des commits/branches, et ainsi de suite.
J'ai cependant peur que si on reste attaché à la base de donnée, on retombe dans le système actuel ou tout est stocké en base de donnée et on se retrouve avec des trucs abérants dont j'ai déjà parlé et qui m'as poussé à ouvrir cette ZEP (entre autre, le titre en base de donnée qui correspond à la version draft tandis que le titre en béta ou online sont pas les mêmes), et qui oblige une fois encore à perdre en factorisation par des appels exagérés à différentes chose. Même si on simplifie le mécanisme en balançant Part et Chapter et en les regroupant en une seule représentation unique (Section, à priori), si on continue à en stocker les informations en base de donnée, on court une fois encore à la catastrophe à mon sens : une base de donnée n'est pas fait pour stocker des objets versionnés, c'est bien pour ça que le site à choisi d'employer git.
Il y a aussi l'autre problème, que j'ai déjà fait remarquer à Firm sur sa PR concernant le ré-import de tuto : si on reste collé à la base de donnée, une Section ou un Extrait doivent obligatoirement avoir un pk, donc avoir été créé sur le site avant d'être modifié. Autrement dit, on perd l'avantage du travail en ligne ou tu fais ton tuto sur ton pc et ou tu push régulièrement des MàJ quand tu l'entend avec le contenu que tu l'entend : ça perd vachement de son intérêt. Je vais prendre mon propre cas : je suis en train d'écrire un tuto, et j'ai plus ou moins délimité la structure. Sauf que quand je l'écris, je me rend compte que y'a des choses qui doivent changer de place, être plus ou moins développée et ainsi de suite, mais je m'en rend compte PENDANT l'écriture du tutoriel, donc si on suis la logique, trop tard puisque j'ai déjà fixé ma structure en base de donnée et que je vais être obligé d'en passer par le site pour en changer.
Sans parler du cas inverse. Imaginons qu'on dise "non, t'es pas obligé de créer ta structure avant, le site s'adaptera à tes push" … Oui, mais quand ? Autant dans le cas du ré-import d'un zip, le site parcoure la structure de celui-ci et valide ce qu'il veut. Dans le cas d'un push à la git, le site n'en sais rien et n'est pas consulté dans le processus. Il faudrait alors un bouton "mettre à jour le JSON" qui rajouterai les pk là ou il n'y en a pas. Sans compter qu'il faudrait gérer le cas des Sections/Extraits qui deviendraient orphelins du jour au lendemain (supprimé dans le JSON par l'auteur mais pas en base de donnée car ça n'aurait pas été fait via le site) ou des multiposts (l'auteur ne prend pas la peine de faire un fecth du dépot après la mise à jour du JSON, ce qui aura pour effet de recréer des lignes en base de donnée au prochain appui sur le bouton).
Bref, énormément d'ennuis à gérer si on veux effectivement pouvoir laisser l'auteur travailler dans son coin avec git.
Clem' sous ACID
- un auteur peut avoir des co-auteurs, et là les choses se corsent un peu plus. En partant du principe que l'auteur A travaille sur l'éditeur en ligne et que l'auteur B travaille en local, si l'un décide de mettre à jour sa version en même temps que l'autre, bonjour les dégats transactionnels.
- lorsqu'on voudra implémenter le déplacement d'un extrait d'un tutoriel à un autre, on sera bien embêté lorsqu'on se rendra compte qu'il y'a conflit entre les clés d'identification.
Firm1
Pour moi, Firm1, tu oublies deux choses dans ce que tu dis, et la première est liée à la ZEP-8 : et git dans tout ça ? J'veux dire, déjà, git est ACID, enfin je l'espère (et si c'est pas le cas, on a plutôt intérêt à arrêter de discuter, ça n'as plus aucun intérêt), donc si recouvrement il y a, il y a toujours l'historique pour s'en sortir. Et puis quand bien même : si un auteur fait sa popote sur le site et un second de l'extérieur, à un moment, il va y avoir une opération de push. Et là, normalement, en cas de recouvrement, git va hurler au conflit (pull request, toussa), ce qui mettra la puce à l'oreille de l'auteur, normalement. Donc pour moi, ça, c'est pas un problème, clé nominale ou pas
Concernant le déplacement, j'ai du mal à voir en quoi c'est un problème : on peut toujours imaginer redonner un hash à cet extrait, puis la chance pour qu'il y aie deux hash identique est quand même vachement minime s'ils sont bien foutu 
Le reste
puisqu'une fois le tuto publié la page d'arbo reste statique, pourquoi ne pas exporter le html comme on le fait habituellement pour les extraits?
artragis
+1 pour l'idée, je pense que c'est même déjà dans la ZEP (et si c'est pas le cas, ça le sera)
L'auteur a le droit de structurer son dépot comme il le veut, et le site ne doit pas venir casser sa structure, ni la refuser, mais il doit s'adapter à sa structure, donc il faut que la technique s'adapte au modèle de l'auteur. ça peut aller du "je range tous les fichiers dans le même répertoire" à "je classe les extraits dans un seul dossier, les introductions dans un autre, et les conclusion à part".
Firm1
Tant que les chemins dans le JSON sont relatif à l'origine, peu importe comment il les range. Là ou ça me pose plus de problème, c'est les gens qui ont un comportement différent que celui de l'éditeur du site (genre "tout dans un dossier") et ensuite qui repasse par l'éditeur du site pour rajouter un chapitre. Ça sera le bordel