
Sans doute que, comme moi, il vous arrive de conserver les adresses de pages web auxquelles vous souhaitez pouvoir facilement revenir plus tard, au besoin. Ce peut être dans les favoris de votre navigateur Internet, dans une liste dans un simple fichier texte, ou encore tout autre système qui puisse conserver du texte.
Il vous est donc sans doute arrivé, que quelques années après avoir noté l’adresse de cette page web, vous souhaitez à nouveau la consulter. Et là, quelle surprise, la page à laquelle vous vous attendiez n’est plus disponible ! Les raisons de cette indisponibilité peuvent être multiples: le nom de domaine n’existe plus, le lien donne maintenant une belle erreur 404 Not Found, le format des URLs utilisé par ce site n’est plus le même, l’article publié sur ce blog a été supprimé, etc.
À part vous apitoyer sur votre sort, qu’avez comme possibilités pour retrouver la page web perdue ? Vous pouvez tenter votre chance auprès de la Wayback Machine, encore faut-il que la page que vous cherchez ait été archivée. Vous pouvez aussi espérer que la page web est en cache auprès d’un moteur de recherche très connu.
Comment éviter cette prise de tête lorsque des URLs deviennent invalides ? Une solution consiste à sauvegarder la page web au moment où vous stockez son adresse (à ce moment, l’adresse est encore valide, normalement !). Vous pouvez sauvegarder la page au format PDF (de nos jours, les navigateurs web ont tous cette fonctionnalité), mais vous avez alors les inconvénients du format PDF: complètement statique, le formatage peut parfois être un peu abîmé, les copié-collés difficiles, etc. Sinon vous pouvez utiliser la fonctionnalité Enregistrer sous de votre navigateur web. Dans tous les cas, ces solutions requièrent une action manuelle de votre part, en plus de noter le lien. Et même si vous prenez le réflexe de sauvegarder chaque page dont vous notez l’adresse, comment organiser toutes ces sauvegardes de façon efficace, pour être capable de rapidement retrouver la sauvegarde correspondant à une adresse web donnée ?
Pour répondre à toutes ces questions, je vais vous présenter dans ce billet ArchiveBox. Il s’agit d’un système permettant d’automatiser la sauvegarde de pages web et de gérer facilement ces sauvegardes. Il suffit de donner à ArchiveBox les URLs des pages à conserver, et ArchiveBox s’occupera de les sauvegarder dans plusieurs formats. Il dispose également d’une interface web qui permet de parcourir les sauvegardes et de facilement consulter une page web qui n’existe plus à l’adresse depuis laquelle elle a été sauvegardée.
Si jusqu’ici je n’ai pas réussi à vous intéresser à ArchiveBox, vous pouvez aussi lire la partie Background & Motivation du site d’ArchiveBox, qui évoque d’autres raisons supplémentaires qui peuvent vous pousser à vouloir sauvegarder des pages web.
Je vous propose dans une première partie de mettre en place ArchiveBox et découvrir comment il fonctionne. Ensuite, je vous montrerai comment j’ai automatisé la sauvegarde des liens que je stocke dans un DokuWiki et dans l’application Bookmarks de Nextcloud. Je ne dis pas qu’il s’agit de la méthode à employer pour automatiser ce genre de tâches, il s’agit surtout d’un retour d’expérience.
Le logo utilisé pour ce billet est celui d’ArchiveBox.
Découverte d'ArchiveBox
Cette première partie a pour but de vous donner un aperçu du fonctionnement de ArchiveBox. C’est principalement un résumé des points de la documentation qui m’intéressaient.
Installation
Créons un dossier dédié à nos essais avec ArchiveBox:
mkdir archivebox && cd archivebox
Plaçons-nous dans un environnement virtuel Python pour ne pas polluer notre système:
python3 -m venv venv
source venv/bin/activate
Nous pouvons maintenant installer ArchiveBox avec pip:
pip install archivebox
La documentation d’ArchiveBox indique qu’il faut avoir au moins la version 14 de NodeJS, mais avec la version 12 sur mon système, je n’ai pas constaté de problème.
Ce billet a été rédigé lorsque la version la plus récente de ArchiveBox était la version 0.6.2. Il est possible de forcer l’installation de cette version :
pip install archivebox==0.6.2
Initialisons ArchiveBox:
archivebox init --setup
ArchiveBox va alors télécharger via npm tous les outils dont il a besoin pour
récupérer des pages web. Le seul qui me manquait était ripgrep, disponible
dans les dépôts de Debian. N’utilisant pas Chrome, ArchiveBox ne l’a pas trouvé
et l’a seulement marqué comme désactivé. Pour moi, ce n’est pas gênant, Chrome
n’est utile que pour avoir les captures d’écrans des pages web.
Utilisation d’ArchiveBox
Lançons ArchiveBox:
archivebox server
L’interface est disponible via votre navigateur à l’adresse 127.0.0.1:8000.
On n’a encore archivé aucune page web, donc c’est plutôt vide… Il y a surtout deux possibilités pour ajouter des pages web à archiver: directement par l’interface web, ou bien en ligne de commande.
Commençons par ajouter une page à sauvegarder depuis l’interface web. Il faut aller sur le lien en
haut à droite intitulé ADD +. Il faut alors se connecter avec les
identifiants que vous avez renseignés lors de l’initialisation de ArchiveBox.
Vous arrivez alors sur une interface d’administration Django, recliquez sur le
même ADD +.
Tentons d’ajouter le tutoriel Écrire des programmes prouvés corrects avec Coq. On ne sélectionne pas de méthode d’archivage, comme ça elles seront toutes utilisées, on va pouvoir voir ce que produit chacune d’entre elles.
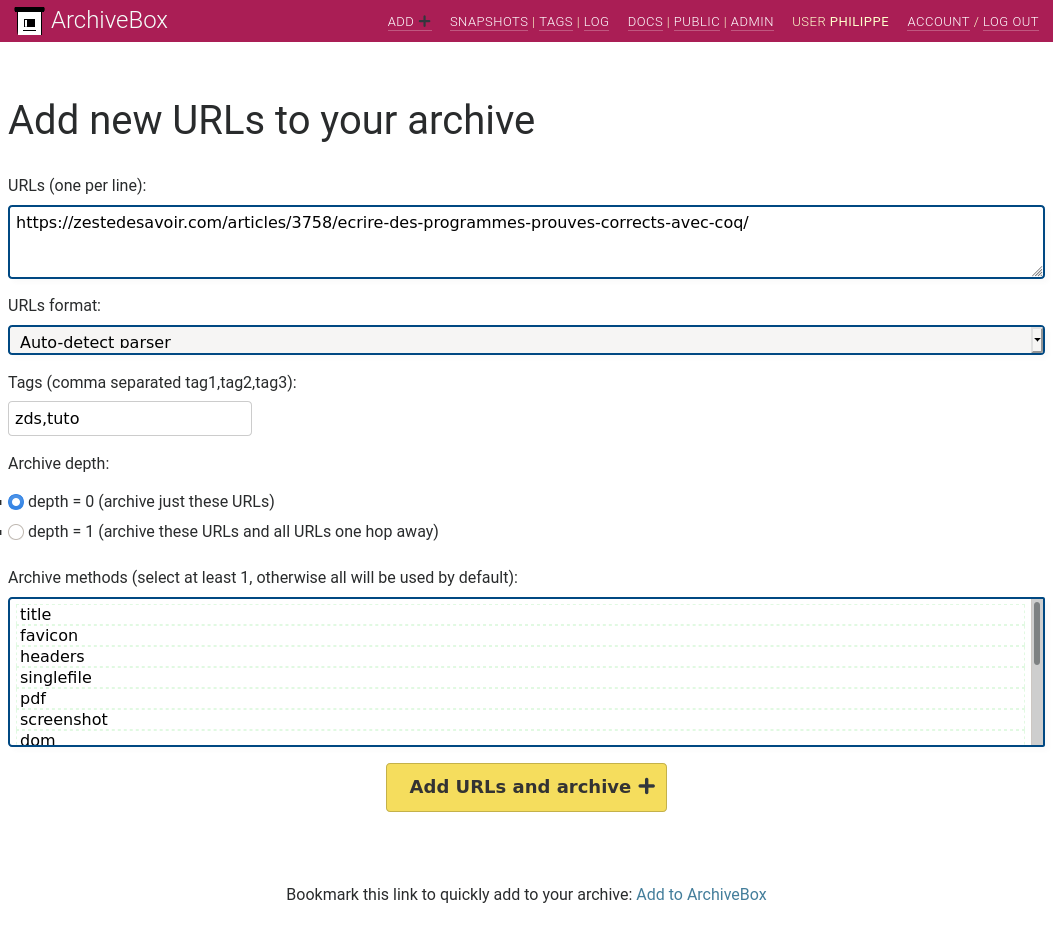
L’équivalent en ligne de commande est la commande suivante:
archivebox add https://zestedesavoir.com/articles/3758/ecrire-des-programmes-prouves-corrects-avec-coq/
De plus, ArchiveBox gère beaucoup de formats d’entrée possible: on peut lui passer un simple fichier texte avec une URL par ligne, un fichier XML, l’historique ou les marque-pages de votre navigateur web, les liens de votre Pocket, etc.
Après une petite attente (55 secondes, d’après les logs), on obtient un message nous indiquant le succès de l’archivage:
https://zestedesavoir.com/articles/3758/ecrire-des-programmes-prouves-corrects-avec-coq/
> ./archive/1621784098.999583 > title
> favicon
> headers
> wget
> readability
> mercury
> media
> archive_org
176 files (11.0 MB) in 0:00:55s
La liste nous indique les méthodes d’import qui ont été utilisées. Si on consulte la page ArchiveBox de la page que l’on vient d’importer, on a accès aux différents formats dans lesquels la page a été sauvegardée.
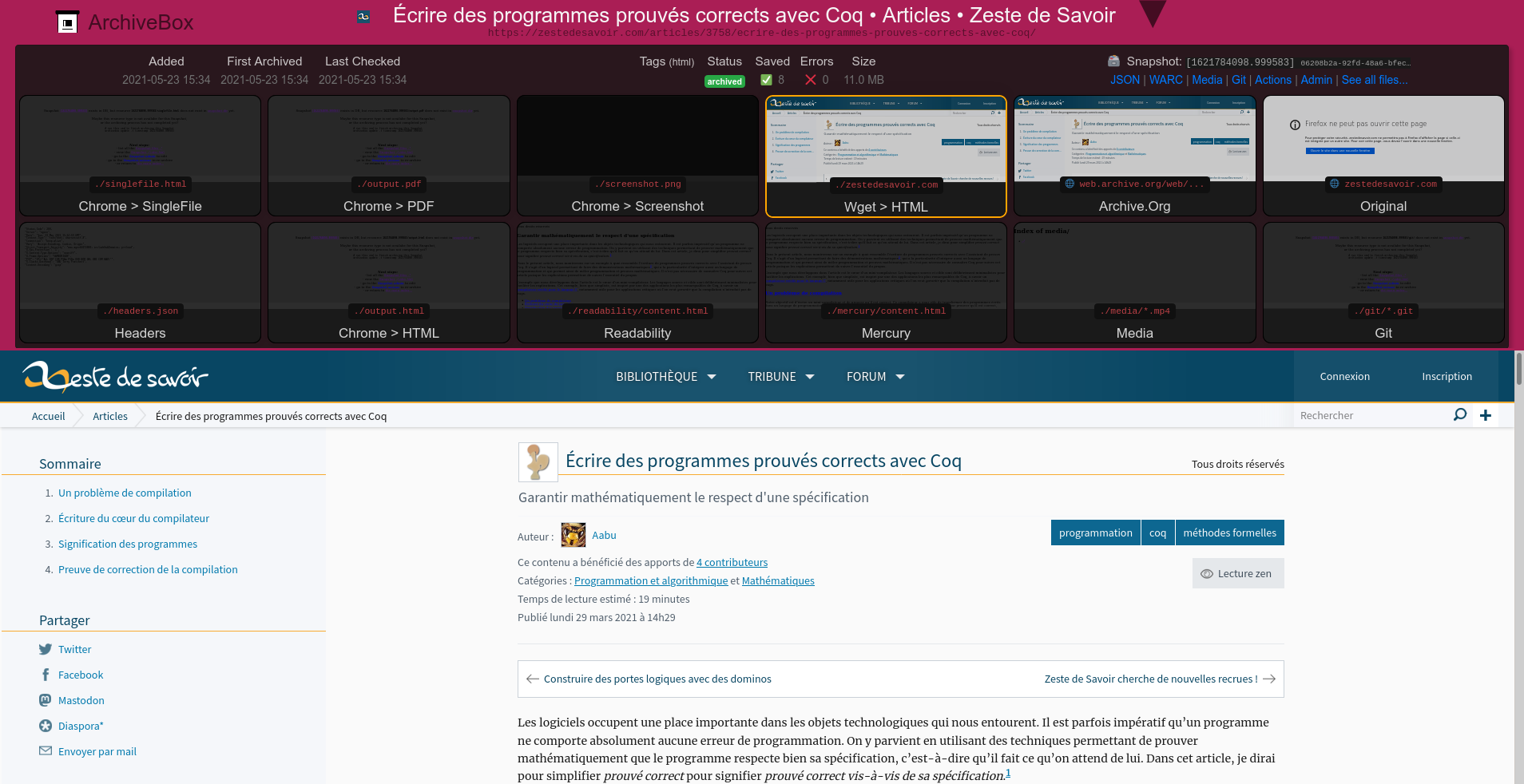
On peut y voir:
- le titre de la page et la favicon associée
- tous les imports via Chrome (SingleFile, PDF, Screenshot, HTML) ne sont pas disponibles (n’ayant pas Chrome, c’est normal !)
- la page a été téléchargée avec
wgetet permet de visualiser la page comme si on était vraiment sur ZdS ! - ce n’est pas visible dans les aperçus, mais
wgeta aussi téléchargé la page dans le formatwarc, un format d’archive fait exprès pour sauvegarder des pages web, et apparemment plutôt bien reconnu dans le milieu (selon Wikipedia, je ne connaissais pas ce format avant). On peut visualiser ce type d’archive avec ReplayWeb.page (ou utiliser l'instance en ligne) - ArchiveBox a aussi envoyé une demande d’archivage au service en ligne Internet Archive (Wayback Machine)
- ArchiveBox propose également deux formats ressemblant à ce que fait Pocket, le mode lecture de nombreux navigateurs, ou même l’option Lecture zen de ZdS: n’afficher que le contenu pertinent de la page (ici le contenu de l’article) et masquer tout le reste (les menus, etc). ArchiveBox utilise pour cela Readability (un service similaire à Pocket, qui a fermé en 2016, toujours selon Wikipedia et Mercury utilisé par l'extension Chrome du même nom. Ces deux rendus sont donc composés d’une page HTML sans aucun CSS et ne contiennent que le contenu de l’article, sans rien d’autre.
- une section Media, vide ici, stockerait les vidéos de la page.
- une section Git, vide ici, aurait cloné le dépôt si le lien à archiver était un dépôt Git.
Tout ce contenu est stocké dans le dossier archive/<le timestamp de la sauvegarde>/ du
dossier où on a lancé ArchiveBox et contient l’arborescence suivante:
~/archivebox/archive/1621784098.999583 [venv] % tree -L 1
.
├── archive.org.txt
├── avatar.spacefox.fr
├── cdnjs.cloudflare.com
├── favicon.ico
├── fonts.googleapis.com
├── fonts.gstatic.com
├── headers.json
├── index.html
├── index.json
├── media
├── mercury
├── readability
├── secure.gravatar.com
├── warc
└── zestedesavoir.com
On constate que toutes les dépendances de la page web ont été téléchargées et rangées dans le dossier correspondant à leur nom de domaine.
On peut s’interroger sur l’espace que prend cette sauvegarde:
~/archivebox/archive/1621784098.999583 % du -h -d 1 | sort -h
0 ./media
8,0K ./secure.gravatar.com
24K ./avatar.spacefox.fr
32K ./fonts.googleapis.com
32K ./readability
76K ./mercury
428K ./fonts.gstatic.com
3,3M ./cdnjs.cloudflare.com # contient les polices FontAwesome
3,4M ./zestedesavoir.com # les polices représentent une part importante des 3,4 Mo
4,0M ./warc
12M .
Les fichiers à la taille la plus importante sont principalement les polices de
caractères. L’archive warc contenant toute la page web, il n’est pas étonnant
qu’elle pèse presque autant que tout le reste du dossier. Je vous laisser juger
s’il s’agit d’une taille importante ou non au regard de la page qu’on vient de
sauvegarder, mais ce que je peux vous dire, c’est que ArchiveBox annonce:
ArchiveBox can use anywhere from ~ 1gb per 1000 articles, to ~ 50gb per 1000 articles
Même Git et les vidéos !
Juste pour voir, essayons une page contenant une vidéo, comme cet
article.
Dans ce cas, ArchiveBox se plaint que des imports n’ont pas réussi, sans donner
plus de détails. Il indique tout de même la commande invoquée qui a échouée, en
l’exécutant manuellement, il s’avère que c’est un lien
https://www.youtube.com/img/meh7.png qui mène vers une erreur 404 et qui fausse
le code de sortie de wget. C’est dommage, parce qu’en dehors de ça, la page
est parfaitement sauvegardée, les vidéos de la page sont sauvegardées au format
MP4 dans le dossier media !
Maintenant, Git. Essayons de sauvegarder le dépôt GitHub de Zeste de
Savoir. Cette fois, le rendu wget
est peu satisfaisant, on ne retrouve pas du tout le style de GitHub (il y a
probablement un peu trop de JavaScript…); Readability parvient à sauvegarder
le contenu du README, Mercury est vide; et on retrouve bien les sources de ZdS
dans le dossier Git. En sortant du navigateur web et en allant vraiment dans le
dossier où est sauvegardé le dépôt Git, on se rend compte que cela correspond
bien à un clone du dépôt Git, on a donc tout l’historique Git du projet.
Si vous sauvegardez l’URL qui pointe sur un fichier ou dossier particulier d’un dépôt hébergé sur un dépôt Git (par exemple: https://github.com/zestedesavoir/zds-site/tree/dev/zds/tutorialv2), Archivebox sauvegardera la page web comme une page web classique, et ne détectera pas qu’il s’agit d’un dépôt Git. Ainsi, si vous sauvegardez l’URL d’un fichier, ce sera la page affichant ce fichier qui sera sauvegardée, et non pas une version brute du fichier (ce qui nous intéresse le plus souvent quand on parcourt des dépôts Git).
Si on sauvegarde une URL qui sert un fichier PDF, deux cas sont à distinguer:
- l’URL se termine par l’extension
.pdf(par exemple: https://zestedesavoir.com/tutoriels/pdf/249/rediger-sur-zds.pdf): c’est le cas le plus favorable, le fichier PDF sera sauvegardé et restitué comme un fichier PDF lorsqu’on consultera la sauvegarde; - l’URL ne se termine pas par l’extension
.pdf(par exemple: https://www.debian.org/doc/manuals/packaging-tutorial/packaging-tutorial): là c’est plus fâcheux, ArchiveBox ne reconnaît pas qu’il s’agit d’un PDF et ne gère pas l’aperçu. Il faut alors parcourir l’arborescence de la sauvegarde pour obtenir le fichier sauvegardé. Le fichier étant sans extension, votre navigateur vous proposera de le télécharger comme un fichier de typeapplication/octet-stream(il ne l’ouvre pas directement comme un fichier PDF). J’ai ouvert un ticket pour discuter de ce comportement.
Publier l’archive
ArchiveBox étant une application Django, il est tout à fait possible de l’exposer sur un serveur public. Mais, ayant peu envie de mettre en place Gunicorn pour gérer du contenu qui finalement est plutôt statique, on va essayer une fonctionnalité que propose ArchiveBox: exporter l’archive des pages web sauvegardées comme de l’HTML statique:
archivebox list --html --with-headers > index.html
index.html et le dossier archive sont alors les deux éléments qu’il faut
servir statiquement. Pour essayer, on peut utiliser Python pour lancer un
serveur web:
python3 -m http.server --bind 0.0.0.0 --directory . 8000
On retrouve à l’adresse 127.0.0.1:8000 une interface similaire à celle qu’on
a vu précédemment, mais servie de façon complètement statique ! Ce sera
amplement suffisant pour consulter de temps en temps des pages web disparues.
Tous les liens internes contenus dans le fichier index.html commencent par un
slash, ouvrir directement le fichier avec votre navigateur empêchera donc toute
navigation dans l’archive.
Le fichier index.html s’attend à trouver deux dossiers à côté de lui:
archive, qui contient les données de toutes les pages sauvegardées;static, qui contient les fichiers statiques CSS et JavaScript nécessaires pour l’interface de ArchiveBox. Ce dossier est dansvenv/lib/python3.7/site-packages/archivebox/templates/.
Pensez à utiliser des liens symboliques, pour rendre ces dossiers disponibles dans le dossier exposé par votre serveur web ! Au final, votre serveur web doit servir l’arborescence suivante:
~/www % tree -L 1
.
├── archive -> ~/archivebox/archive
├── index.html
└── static -> ~/archivebox/venv/lib/python3.7/site-packages/archivebox/templates/static
Quelques remarques…
… qui pourront être utiles pour la suite de ce billet.
Tags
Il est possible d’associer des tags aux pages sauvegardées, pour mieux les catégoriser, et donc mieux les retrouver !
On peut ajouter des tags avec l’option --tag de la commande archivebox add. Si on souhaite ajouter des tags différents aux URLs importées en une fois, on peut passer par un fichier au format JSON:
[
{"url": "https://archivebox.io/", "tags": "test,archivebox"},
{"url": "https://fr.wikipedia.org/wiki/Gallium", "tags": "test,wikipedia"}
]
archivebox add --parser json < urls.json
Lorsqu’on parcourt l’interface servie par archivebox server,
il est possible de filtrer les pages sauvegardées par tag.
Ce n’est en revanche pas possible avec un export statique de l’archive.
Archiver plusieurs fois la même URL
Si on demande à sauvegarder une URL déjà sauvegardée par ArchiveBox, cette demande est ignorée. L’avantage est que ça permet de gagner du temps et de la place et on est sûr que le contenu sauvegardé est celui qu’on a consulté lorsqu’on a sauvegardé initialement le lien . L’inconvénient est que ça ne permet pas de suivre l’évolution de la page sauvegardée (si des corrections ou mises à jour y sont apportées, par exemple).
Pour forcer une nouvelle sauvegarde, ArchiveBox
suggère
de modifier légèrement l’URL en ajoutant par exemple la date comme une ancre:
https://zestedesavoir.com/articles/3758/ecrire-des-programmes-prouves-corrects-avec-coq/#2021-05-23T18:08:51+00:00.
Cela ne change pas le contenu de la page web, mais pour ArchiveBox, c’est une
nouvelle URL inconnue, il ne fera aucun lien avec la précédente sauvegarde de
cette page web.
Configuration
ArchiveBox est plutôt facile à configurer. Après l’initialisation d’ArchiveBox, on peut changer les clés de configuration en ligne de commande, par exemple:
archivebox config --set CHROME_BINARY=google-chrome-stable
Tous les changements de configuration sont stockés dans le fichier ArchiveBox.conf.
Maintenant que nous avons exploré les possibilités d’ArchiveBox, je souhaite désactiver certaines méthodes d’archivage. Il est possible de définir des variables d’environnement qu’ArchiveBox consultera lors de son initialisation:
SAVE_SINGLEFILE=False USE_CHROME=False USE_NODE=False USE_YOUTUBEDL=False USE_READABILITY=False USE_MERCURY=False archivebox init --setup
Cette combinaison de paramètres a l’avantage de ne plus avoir besoin de NodeJS comme dépendance. Malheureusement, ArchiveBox ne conserve pas les paramètres qu’on lui a passé lors de son initialisation, il faut donc ensuite saisir:
archivebox config --set SAVE_SINGLEFILE=False USE_CHROME=False USE_NODE=False USE_YOUTUBEDL=False USE_READABILITY=False USE_MERCURY=False
La liste des options de configuration possibles est dans la documentation d’ArchiveBox.
Que se passe-t-il si… ?
Puisque je vais démarrer mon utilisation d’ArchiveBox en sauvegardant toutes les URLs que j’ai déjà répertoriées depuis un certain temps, peut-être que certaines URLs ne sont déjà plus valides, et renvoient des codes HTTP différents du code 200 (OK tout s’est bien passé).
Voici un résumé du comportement d’ArchiveBox suivant le code HTTP qu’il rencontre (non-exhaustif, basé sur les codes que j’ai pu obtenir sur mes URLs):
| Code HTTP | Signification | Comportement d’ArchiveBox |
|---|---|---|
| 000 | Pas de résolution DNS (le nom de domaine n’est plus enregistré)1 | URL avec erreur |
| 301 | Redirection permanente | ArchiveBox suit la redirection. |
| 302 / 307 | Redirection temporaire | ArchiveBox suit la redirection. |
| 404 | Page non trouvée | URL avec erreur, mais le titre (souvent un "404 Not Found"…) et la favicon sont sauvegardés. |
| 410 | Ressource plus disponible (aucune redirection connue) | URL avec erreur |
Avec cURL, vous pouvez obtenir le code HTTP renvoyé par un serveur répondant à une adresse web en utilisant la commande suivante:
curl -o /dev/null --silent --user-agent "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7)" \
--write-out "%{http_code}\n" $url
Les URLs avec une erreur sont tout de même stockées par ArchiveBox, mais notées comme "pas encore archivées". Une fonctionnalité plutôt sympa est que même si ArchiveBox n’est pas parvenu à sauvegarder une URL, il indique quand même combien de sauvegardes de cette URL sont disponibles sur la Wayback Machine, ce qui donne tout de même une chance de retrouver le contenu de la page, même si on a voulu sauvegarder la page trop tard…!
Lors de mes expérimentations, j’ai voulu sauvegarder une URL servie par un serveur qui semble bloquer les requêtes provenant d’outils comme cURL ou wget: j’obtenais un code HTTP 403 (Interdit !), mais dans mon navigateur, la page s’affichait bien. En demandant à cURL de présenter le User-Agent de Firefox, la page s’affichait bien. Par défaut, ArchiveBox utilise ce User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.61 Safari/537.36 ArchiveBox/0.6.2 (+https://github.com/ArchiveBox/ArchiveBox/) wget/GNU Wget 1.21: il tente de présenter les User-Agents des navigateurs les plus courants, mais ajoute aussi wget… Ainsi, il m’était impossible de télécharger la page avec ArchiveBox. Heureusement, il est possible de changer le User-Agent utilisé par cURL et wget lorsque ArchiveBox fait appel à ces outils:
archivebox config --set WGET_USER_AGENT="Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7)"
archivebox config --set CURL_USER_AGENT="Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7)"
Rester gentil
Il m’est arrivé de me faire bloquer mon adresse IP par certains serveurs qui pensaient que mes intentions étaient mauvaises. Il faut dire que sauvegarder d’une traite (i.e. sans interruption entre les requêtes !) une cinquantaine de pages du même site peut être perçu comme peu amical… et déclencher les procédures de protection contre les attaques DDoS.
Heureusement, wget dispose d’options pour attendre un certain moment entre deux requêtes: --wait=1 --random-wait permet d’attendre plus ou moins une seconde entre chaque requête, ce temps étant légèrement modifié de façon aléatoire, pour éviter que le serveur ne détecte qu’on attend précisément une seconde entre chaque requête.
Le choix de une seconde comme valeur est complètement empirique, je n’ai plus constaté de blocage avec cette valeur. Par contre, cela ralentit considérablement le téléchargement des pages web.
Il est possible de préciser à ArchiveBox quelles options il doit passer à wget:
# On récupère les paramètres par défaut:
archivebox config --get WGET_ARGS
# On garde les paramètres par défaut et on ajoute les nôtres:
archivebox config --set WGET_ARGS='["--no-verbose", "--adjust-extension", "--convert-links", "--force-directories", "--backup-converted", "--span-hosts", "--no-parent", "-e", "robots=off", "--wait=1", "--random-wait"]'
Il est aussi nécessaire d’augmenter le timeout qu’ArchiveBox utilise pour sauvegarder une page web (par défaut à une minute):
archivebox config --set TIMEOUT=240
Éviter que des dépendances inaccessibles faussent le résultat
J’utilise chez moi PiHole comme serveur DNS pour bloquer les publicités et autres trackers. Or, il s’avère que certaines pages web que je souhaitais sauvegarder nécessitent des ressources (image, feuille de style CSS, script JavaScript …) stockées sur des serveurs bloqués par PiHole.
Autre cas problématique que j’ai pu remarquer: une page web a dans son code HTML une image, seulement l’adresse de cette image renvoie une erreur HTTP 500.
Dans ces deux cas, wget essaie de télécharger la ressource indiquée comme nécessaire par le code HTML de la page web à sauvegarder, mais rencontrant une erreur (pas de résolution DNS dans le premier cas, une erreur 500 dans le deuxième), son code d’erreur final reflétera ces erreurs, alors qu’elles ne concernent pas (directement) la page initiale. C’est gênant parce que ArchiveBox considère alors que la sauvegarde avec wget a échoué, alors que ce n’est pas complètement le cas. En revanche, savoir que la page que l’on souhaite sauvegarder renvoie elle-même directement une erreur est important.
Pour contourner ce fonctionnement de wget, voici un script shell qui commence par simplement tester si la page que l’on souhaite sauvegarder ne renvoie pas elle-même une erreur, puis télécharge la page avec ses dépendances, tout en ignorant le code de retour de ce dernier appel à wget:
#!/bin/bash
# On récupère quelques options passées à wget, pour imiter au mieux la requête wget
# qui téléchargera la page et ses dépendances:
user_agent=""
compression=""
no_verbose=""
for arg in "$@";
do
if [[ "$arg" == "--user-agent="* ]]
then
user_agent=$arg
elif [[ "$arg" == "--compression="* ]]
then
compression=$arg
elif [[ "$arg" == "--no-verbose" ]]
then
no_verbose=$arg
fi
done
# L'URL de la page à télécharger est le dernier argument passé au script:
# ($arg est la variable utilisée dans la boucle précédente qui itère sur
# les paramètres du script, après la boucle $arg garde le dernier paramètre)
url=$arg
# On regarde si on peut accéder à la page, sans récupérer son contenu (option --spider)
# $user_agent est entre guillemets car cette variable contient du texte avec des espaces
wget $no_verbose --spider "$user_agent" $compression $url
return_code=$?
# Certains sites n'aiment pas l'option --spider (qui fait une requête HEAD)
# On leurs donne une seconde chance, sans l'option --spider, mais en ne gardant
# pas le contenu récupéré (on le redirige vers /dev/null avec l'option -O)
if [ $return_code -ne 0 ]
then
wget $no_verbose "$user_agent" $compression -O /dev/null $url
return_code=$?
fi
# Si la page est accessible, alors on la télécharge avec toutes ses dépendances,
# on fait ici l'appel à wget qu'aurait fait ArchiveBox sans ce script.
if [ $return_code -eq 0 ]
then
wget "$@"
fi
# On renvoie le code de retour du wget qui teste si la page est accessible:
exit $return_code
Après avoir rendu notre script exécutable, il ne reste plus qu’à indiquer à ArchiveBox qu’il faut utiliser ce script comme programme wget:
chmod u+x my_wget
archivebox config --set WGET_BINARY=/chemin/vers/my_wget
Maintenant qu’on a découvert ArchiveBox et qu’on l’a configuré pour qu’il se comporte comme on le désire, on va pouvoir automatiser la sauvegarde de liens.
- C’est tout du moins la cause du code 000 que j’ai observé, il y a peut-être d’autres causes qui mènent à ce code d’erreur.↩
Sauvegarde des liens d'un DokuWiki
J’utilise un DokuWiki où j’écris de nombreux trucs et astuces liés à l’informatique. Généralement, si j’ai à chercher comment faire telle chose, j’y écris ce que j’ai trouvé, en mettant le lien de là où je l’ai trouvé. On ne pas se mentir, il y a beaucoup de liens vers StackOverflow, mais il y a aussi quelques articles de blogs, des issues GitHub, etc. Pouvoir revenir à la page web où j’ai trouvée la solution permet d’avoir tout le contexte de la solution (remarques de l’auteur, réactions dans les commentaires, solutions alternatives…) et ainsi de ne pas être limité par mon wiki où j’ai écrit seulement la ligne qui résout exactement le problème précis que j’avais à ce moment-là.
Sauvegarder ces liens est donc important, il m’est déjà arrivé que des liens qui m’avaient donné une solution ne soient plus disponibles… et ce wiki a moins de 3 ans !
L’objectif de cette partie est d’automatiser la collecte de tous les liens externes contenus dans mon wiki, et passer cette liste de liens à ArchiveBox pour qu’il les sauvegarde.
Collecter tous les liens
Pour extraire tous les liens externes de mon wiki, j’ai d’abord cherché si une extension ne faisait pas ça. J’ai trouvé l’extension xtern qui permet de lister les liens morts d’un wiki. J’aurais pu l’adapter pour qu’elle me liste tous les liens externes, mais il y a plus simple.
Il faut savoir que DokuWiki stocke les pages du wiki comme de simples fichiers texte. Dans le langage de formatage de DokuWiki, les liens externes (qui mènent à un site externe au wiki) peuvent être écrits avec trois formats:
https://zestedesavoir.com
[[https://zestedesavoir.com]]
[[https://zestedesavoir.com|Zeste de Savoir]] # dans ce cas, "Zeste de Savoir" est le texte du lien
Soyons tout de suite clairs, il y a dans mon wiki des liens que je ne souhaite pas sauvegarder (des liens qui mènent vers des pages très générales, qui ne sont là que pour se rendre facilement sur le site dont il est question, etc). On va donc définir comme convention que les liens qui ne sont pas entre deux crochets ne seront pas sauvegardés. Cependant, il est encore possible que la forme avec crochets soit nécessaire pour pouvoir afficher un texte à la place du lien. Dans ce cas, on rajoutera, de façon à ne pas gêner le serveur servant l’URL, une ancre ou un paramètre GET permettant de distinguer les URLs qu’on ne souhaite pas sauvegarder:
[[https://zestedesavoir.com/tutoriels/249/rediger-sur-zds/?__do_not_save__#10-4783_notes-et-abreviations|notes]]
[[https://zestedesavoir.com/tutoriels/249/rediger-sur-zds/#__do_not_save__|notes]]
Puisque le contenu dans lequel on cherche des URLs est composé de simples
fichiers textes, il doit donc être possible de faire un simple grep avec
une expression régulière pour trouver les liens:
grep -r --exclude-dir=wiki -P -o "\[\[https?:\/\/.+?\]\]"
-r: cherche dans tous les fichiers de tous les dossiers récursivement;--exlcude-dir=wiki: on exclut tous les fichiers se trouvant dans le dossierwiki, ils représentent des pages du wiki propre à DokuWiki (guide de mise en forme, etc);-P: j’utilise la version Perl des expression régulière, qui permet l’utilisation des quantificateurs paresseux (non-greedy / lazy);-o: ne renvoie que les parties du texte qui correspondent à l’expression régulière (et pas toute la ligne);- concernant l’expression régulière, on cherche tout ce qui se trouve entre
deux crochets et qui commence par
http://ouhttps://. Le point d’interrogation après.+indique que ce quantificateur doit être paresseux, ainsi mon expression régulière s’arrêtera au premier]]qu’elle rencontre. Cela permet de gérer le cas où il y a plusieurs liens sur une même ligne: sans cette astuce, la regex considérerait tout ce qui est entre la première occurrence de[[et la dernière occurrence de]]sur la ligne.
Trouver l’expression régulière qui correspond à un maximum d’URLs n’est pas évident. Si on veut être le plus précis possible, la regex correspondante est rapidement assez compliquée. Après avoir regardé ce qu’utilise Symfony, je me suis finalement grandement inspiré de la simplicité dont fait preuve CodeIgniter. La tâche est grandement simplifiée ici, parce qu’on sait que les URLs sont délimitées par des crochets.
J’ai également regardé comment faisait DokuWiki lui-même pour détecter les URLs qui ne sont pas entre crochets, et… la regex à utiliser était en plusieurs morceaux, compliquée à reconstituer… La regex que j’utilise ici a le mérite d’être simple !
Au passage, je ne peux que recommander l’excellent outil en ligne Regex101 pour tester ses expressions régulières.
De cette manière, je récupère une sortie de la forme:
python/matplotlib.txt:[[https://matplotlib.org/gallery/ticks_and_spines/ticklabels_rotation.html]]
python/matplotlib.txt:[[https://matplotlib.org/3.1.0/api/markers_api.html|liste des symboles disponibles]]
Il y a encore du travail:
python/matplotlib: les liens trouvés sont dans la pagematplotlibde la catégoriepython. On va pouvoir se servir de cette information comme tags: sur cet exemple, on souhaite avoir les tagspythonetmatplotlib;- les crochets sont toujours présents;
- on récupère aussi le titre du lien s’il existe.
Puisqu’on a commencé avec grep, on va faire un script shell qui décortique ce
format pour en extraire les tags et l’URL et produire une sortie au format JSON
comme vue précédemment.
Obtenir un fichier JSON
Dans une boucle, on va convertir un par un les liens collectés. Admettons que
le lien sur lequel nous travaillons dans chaque itération dans la boucle est
stockée dans la variable nommée link:
$ echo $link
python/matplotlib.txt:[[https://matplotlib.org/3.1.0/api/markers_api.html|liste des symboles disponibles]]
Commençons par convertir le chemin du fichier contenant l’URL en tags:
tags=$(echo $link | sed -E -e "s/(.+)\.txt:\[\[.+\]\]/\1/" -e "s/\//,/")
On se sert de la commande sed pour faire la conversion:
-E: on utilise des expressions régulières;-e "s/(.+)\.txt:\[\[.+\]\]/\1/": "prend tout ce qui se trouve avant.txt:[[... n'importe quoi ...]]et ne garde que ça";-e "s/\//,/": "puis remplace tous les slashs par des virgules".
Pour l’URL, on va commencer par extraire tout ce qui se trouve entre les crochets:
url=$(echo $link | sed -E -e "s/.+\.txt:\[\[(.+)\]\]/\1/")
Deux cas se présentent alors: le lien a un titre ou n’en a pas. Pour tester
si un titre est présent, on vérifie si le symbole | est dans ce qu’on
vient d’extraire. Si c’est le cas, on ne garde que ce qui à gauche de |:
if [[ $url == *"|"* ]]
then
url=$(echo $url | sed -E -e "s/(.+)\|.+/\1/")
fi
On a ainsi notre URL. Si celle-ci contient __do_not_save__, on arrête là cette itération de la boucle, on ne souhaite pas considérer cette URL:
if [[ $url == *__do_not_save__* ]]
then
continue
fi
On peut maintenant afficher l’URL et ses tags, au format JSON:
echo '{"url": "'$url'", "tags": "'$tags'"}'
En mettant tous les morceaux de code ensemble dans une boucle, et en ajoutant la logique pour gérer complètement le format JSON, on obtient ce script:
#!/bin/bash
echo "["
first=1
while read link # chaque ligne lue sera stockée dans la variable $link
do
tags=$(echo $link | sed -E -e "s/(.+)\.txt:\[\[.+\]\]/\1/" -e "s/\//,/")
url=$(echo $link | sed -E -e "s/.+\.txt:\[\[(.+)\]\]/\1/")
if [[ $url == *"|"* ]]
then
url=$(echo $url | sed -E -e "s/(.+)\|.+/\1/")
fi
if [[ $url == *__do_not_save__* ]]
then
continue
fi
if [ $first -ne 1 ]
then
# On n'est pas la première URL: il faut mettre une virgule sur la ligne précédente
# et aller à la ligne.
# Ainsi toutes les lignes, sauf la dernière, auront bien une virgule à la fin de la ligne.
echo ","
fi
echo -e -n '\t' # Mettons une tabulation pour avoir une belle indentation, sans aller à la ligne
echo -n '{"url": "'$url'", "tags": "'$tags'"}' # on ne va pas à la ligne: la prochaine itération est chargée de mettre la virgule
first=0
done < <(grep -r --exclude-dir=wiki -P -o "\[\[https?:\/\/.+?\]\]")
echo # on va à la ligne (sinon on est toujours sur la ligne de la dernière URL)
echo "]"
Ce script, exécuté depuis le dossier data/pages/ de la racine des sources de DokuWiki, écrit sur la sortie standard la liste des liens à sauvegarder au format JSON. Si on redirige la sortie du script vers un fichier, on peut donner ce fichier à ArchiveBox:
./get_links.sh > links.json
archivebox add --parser json < links.json
Sauvegarde des liens de Nextcloud
Je stocke également des favoris sur mon instance Nextcloud, avec l’application Bookmarks. Cette application permet d’organiser des liens de façon hiérarchique (on peut placer les liens dans des dossiers), mais aussi ajouter des tags aux liens, par exemple. Lorsqu’on ajoute un lien, l’application se charge de récupérer le titre de la page pour l’utiliser comme nom du lien.
J’explique dans cette partie comment je récupère la liste des liens stockés sur mon instance Nextcloud, pour la donner à ArchiveBox. On va pour cela faire un script Python qui va exploiter l’API REST de l’application Bookmarks de Nextcloud.
Exclusion de liens
Comme pour le wiki, comment peut-on indiquer qu’on ne souhaite pas sauvegarder un certain lien ? J’ai déjà donné dans la réponse dans l’introduction de cette partie: on va utiliser un tag ! En effet, l’interface de l’application Bookmarks nous permet d’attribuer des tags aux liens. Ainsi, les liens qu’on ne souhaite pas sauvegarder devront posséder un tag caractérisant ce choix, pour moi ce sera un tag nommé do not save.
Récupération de la liste des liens
À l’aide d’un script Python, nous allons récupérer la liste des liens à sauvegarder et générer une liste au format JSON pour la passer à ArchiveBox. La documentation de l’utilisation de l’API REST de l’application Bookmarks est disponible ici.
Dans ArchiveBox, tous les liens sauvegardés depuis Nextcloud auront le tag bookmarks et des tags permettant de retrouver dans quels dossiers se situent les liens. Si un lien se trouve dans le dossier Foo, lui même placé dans le dossier Bar, alors le lien aura dans ArchiveBox les tags bookmarks, Foo et Bar. On pourrait aussi avoir dans ArchiveBox les tags utilisés dans Nextcloud, mais il s’avère que dans Nextcloud, je ne me sers des tags que pour marquer un lien comme à ne pas sauvegarder.
Notre script procédera en trois étapes:
- Récupérer tous les liens, en respectant la hiérarchie (dans quels dossiers sont les liens);
- Récupérer les liens tagués
do not save; - Formater la liste des liens, en triant les liens à garder et à exclure.
Authentification
Puisque je ne souhaite pas exposer publiquement tous mes liens (l’application permet de partager publiquement des dossiers de liens), il va être nécessaire de s’authentifier pour interagir avec l’API REST. Cela se fait en ajoutant un en-tête dans les requêtes HTTP que nous allons réaliser:
import base64
NEXTCLOUD_USER = "user"
NEXTCLOUD_PASSWORD = "p@$$w0rd"
credentials = {
"Authorization": b'Basic ' + base64.b64encode((NEXTCLOUD_USER + ":" + NEXTCLOUD_PASSWORD).encode())
}
Récupérer la liste des liens
On va maintenant récupérer la liste des tous les liens.
import urllib.request
import json
NEXTCLOUD_API_ENDPOINT = "https://votrenextcloud.fr/apps/bookmarks/public/rest/v2/"
# On récupère les liens du dossier racine (folder/-1), mais aussi toute l'arborescence (layers=-1)
req = urllib.request.Request(NEXTCLOUD_API_ENDPOINT + "folder/-1/children?layers=-1", headers=credentials)
with urllib.request.urlopen(req) as f:
response = f.read()
data = json.loads(response.decode('utf-8'))
data est un objet ayant la structure suivante (je n’ai laissé que les éléments qui nous intéressent pour la suite):
{
'status': 'success',
'data': [{
'title': 'Dossier A',
'type': 'folder',
'children': [{
'title': 'Dossier A1',
'type': 'folder',
'children': [{
'type': 'bookmark',
'url': 'https://linuxfr.org/news/de-l-art-d-installer-grapheneos-sur-son-smartphone'
}, {
'type': 'bookmark',
'url': 'https://linuxfr.org/news/quel-telephone-plus-ou-moins-libre-en-2021'
}]
}, {
'type': 'bookmark',
'url': 'https://matplotlib.org/3.1.0/api/markers_api.html'
}]
}, {
'type': 'bookmark',
'url': 'https://zestedesavoir.com/tutoriels/249/rediger-sur-zds/'
}]
}
Les dossiers sont de type folder, ils ont un titre (title) et leur contenu (liens et sous-dossiers) sont dans un tableau children. Les liens sont de type bookmark et ont une url.
Récupérer les liens exclus
De la même manière que pour tous les liens, on peut récupérer la liste des liens exclus en demandant les liens qui ont le tag correspondant:
NEXTCLOUD_EXCLUDE_TAG = "do not save"
# On souhaite obtenir la liste complète, sans pagination (page=-1).
# On souhaite seulement les liens contenant le tag (tags[]=...).
# Puisque le nom du tag a des espaces, il faut échapper cet espace (urllib.parse.quote())
req = urllib.request.Request(NEXTCLOUD_API_ENDPOINT + "bookmark?page=-1&tags[]=" + urllib.parse.quote(NEXTCLOUD_EXCLUDE_TAG), headers=credentials)
with urllib.request.urlopen(req) as f:
response = f.read()
excluded_urls = [e['url'] for e in json.loads(response.decode('utf-8'))['data']]
Ici, le contenu de la réponse HTTP a la forme suivante:
{
'status': 'success',
'data': [{
'url': 'https://zestedesavoir.com/'
}, {
'url': 'https://www.lemonde.fr/'
}]
}
On peut donc bien récupérer la liste des URLs avec une simple liste en compréhension.
Formater la liste des liens à sauvegarder
À partir de la liste de tous les liens, il faut récupérer les URLs à sauvegarder, les dossiers de ces URLs (pour avoir les tags pour ArchiveBox) et exclure les URLs qui sont taguées comme telles. Puisque la liste contenant tous les liens est hiérarchique, on va utiliser une fonction récursive pour récupérer tous les liens et les tags associés:
# le tag commun dans ArchiveBox pour tous les liens venant de Nextcloud:
ARCHIVEBOX_TAG = "bookmarks"
formatted_data = []
def parse_folder(data, tags):
for e in data:
if e['type'] == 'folder':
# Cet élément est un dossier: on s'enfonce dans la récursion pour l'explorer,
# tout en ajoutant le nom du dossier comme tag:
parse_folder(e['children'], tags + [e['title']])
else:
# Si ce n'est pas un dossier, c'est que c'est un lien:
assert(e['type'] == 'bookmark')
# On garde le lien uniquement s'il n'est pas exclu:
if e['url'] not in excluded_urls:
formatted_data.append({
"url": e['url'],
"tags": ','.join(tags) # tous les tags obtenus à ce niveau de la récursion sont séparés par une virgule
})
parse_folder(data['data'], [ARCHIVEBOX_TAG])
Afficher la liste des liens
On a fait le plus dur, il ne nous reste plus qu’à afficher la liste des liens dans le format JSON, pour qu’ArchiveBox puisse les importer:
# ensure_ascii=False permet d'avoir des caractères non-ASCII dans la sortie JSON.
# Sans ce paramètre, 'é' est affiché comme '\u00e9', par exemple.
print(json.dumps(formatted_data, ensure_ascii=False, indent=4))
Code complet
Finalement, on obtient le script suivant:
Afficher/Masquer le contenu masqué
import urllib.request
import json
import base64
NEXTCLOUD_USER = "user"
NEXTCLOUD_PASSWORD = "p@$$w0rd"
NEXTCLOUD_API_ENDPOINT = "https://votrenextcloud.fr/apps/bookmarks/public/rest/v2/"
NEXTCLOUD_EXCLUDE_TAG = "do not save"
ARCHIVEBOX_TAG = "bookmarks"
formatted_data = []
def parse_folder(data, tags):
for e in data:
if e['type'] == 'folder':
parse_folder(e['children'], tags + [e['title']])
else:
assert(e['type'] == 'bookmark')
if e['url'] not in excluded_urls:
formatted_data.append({
"url": e['url'],
"tags": ','.join(tags)
})
credentials = {
"Authorization": b'Basic ' + base64.b64encode((NEXTCLOUD_USER + ":" + NEXTCLOUD_PASSWORD).encode())
}
req = urllib.request.Request(NEXTCLOUD_API_ENDPOINT + "folder/-1/children?layers=-1", headers=credentials)
with urllib.request.urlopen(req) as f:
response = f.read()
data = json.loads(response.decode('utf-8'))
req = urllib.request.Request(NEXTCLOUD_API_ENDPOINT + "bookmark?page=-1&tags[]=" + urllib.parse.quote(NEXTCLOUD_EXCLUDE_TAG), headers=credentials)
with urllib.request.urlopen(req) as f:
response = f.read()
excluded_urls = [e['url'] for e in json.loads(response.decode('utf-8'))['data']]
parse_folder(data['data'], [ARCHIVEBOX_TAG])
print(json.dumps(formatted_data, ensure_ascii=False, indent=4))
Il n’y a plus qu’à donner le resultat de ce script à ArchiveBox:
python3 get_nextcloud_bookmarks.py > links.json
archivebox add --parser json < links.json
Il ne reste plus qu’à placer le lancement de ces commandes (génération de la listes de liens, appel à ArchiveBox) dans des tâches cron pour complètement automatiser la sauvegarde des liens.
En guise de conclusion, je vais vous donner quelques chiffres:
- La sauvegarde initiale réalisée par ArchiveBox (donc tous mes liens de DokuWiki et Nextcloud) a sauvegardé 946 pages web.
- Cette sauvegarde initiale a duré plus de 26 heures (avec
--wait=1 --random-waitpassé à wget, ce qui ralentit beaucoup les sauvegardes). - Le dossier contenant les pages web sauvegardées a une taille de 11 Go, dont deux dépôts Git qui représentent 5,4 Go.
- Parmi tous les liens que souhaitais sauvegarder, environ une cinquantaine n’était plus valide. En arrondissant à 1000 liens à sauvegarder, cela fait 5% de liens invalides après au plus 3 ans.
Les raisons de l’invalidité des liens que j’ai rencontré le plus sont:
- changement de nom de domaine;
- changement du format de l’adresse, par exemple:
https://monsuper.blog/post/fooest devenuhttps://monsuper.blog/foo-12; - le lien renvoie vers une erreur 404 (la partie blog de ce site n’existe plus, l’article sur ce blog a été supprimé, etc);
- le blog de ce site a été déplacé vers un sous-domaine:
https://monsuper.site/blog/fooest devenuhttps://blog.monsuper.site/foo; - le site n’existe tout simple plus: le nom de domaine n’existe plus.
Finalement, pour la majorité des liens cassés, le contenu associé existe toujours quelque part sur Internet, mais sous une adresse différente. Le gros problème est que les responsables des sites opérant ces changements d’adresse ne mettent pas en place de mécanisme pour assurer une redirection (presque) transparente de l’ancienne adresse vers la nouvelle.
À travers ce billet, j’espère vous avoir montré qu’un lien simplement noté quelque part ne veut pas dire qu’il sera forcément possible dans le futur d’accéder au contenu associé, mais des solutions existent pour s’assurer de pouvoir consulter le contenu dont on vient de noter l’adresse web.
Qui se lance dans la sauvegarde des contenus de Zeste de Savoir ? 

{kind=link}