Pendant le semestre qui arrive, je vais avoir des cours de statistiques descriptives (je suis en L1 de sociologie). Histoire de prendre un peu d’avance, j’ai commencé à lire un livre1 sur le sujet, mais je me retrouve un peu bloqué en voulant comprendre la formule pour calculer un intervalle de confiance.
L’auteur donne la formule qui suit pour calculer la borne inférieure d’un intervalle de confiance à 95% d’un pourcentage $p$ sur un échantillon de taille $n$.
La question que je ne peux m’empêcher de me poser est alors : d’où vient ce $1,96$ ?
J’ai cherché un peu sur internet, et j’ai cru comprendre que les anglophones appelaient ça la Z-value, mais je me retrouve vite bloqué par mon niveau en maths2.
J’en viens donc à ma question : quelle est l’origine mathématique de cette valeur ?
Ou, si ça demande trop de pré-requis, est-ce que vous auriez des ouvrages à me conseiller pour mieux comprendre ce qui se cache derrière ces formules ?
Merci d’avance pour votre aide !
Martin, Olivier, et François de Singly. L’analyse de données quantitatives. A. Colin, 2005. ↩
Je viens d’un bac pro, où les cours de maths sont très simplifiés (c’est à peine si on connait les noms des symboles $\Sigma$ ou $\int$). ↩
Erf, grillé par Holosmos… Pas grave, je poste quand même
C’est simple (si simple que je peux te répondre ).
Je ne sais pas où tu en es dans ton apprentissage de ta statistique, mais, généralement, pour voir si un évènement est significatif, on utilise un seuil. Par exemple, lorsqu’il y a moins de 5% de chance que cet évènement arrive, on dit qu’il est significatif (du coup, comme la chance d’avoir 200 fois à un dé de six faces est inférieure à 5%, je peux dire que l’évènement est significatif et que le dé est pipé − à 5% d’erreur).
1,96 correspond justement à 5% sur la loi normale, qui est une loi majeure dans la statistique. Voici pourquoi.
Je peux détailler si t’as besoin de plus d’infos :3
Disons que tu as une boîte noire qui te renvoie 1 avec une certaine probabilité inconnue $p$ et 0 avec une probabilité $1-p$. Ton but c’est de trouver $p$ : pour ça, un truc naturel, c’est de prendre la moyenne de plein de sorties de la boîte (si tu en prends suffisamment, la valeur que tu obtiendras sera effectivement proche de $p$).
Maintenant on fixe une certaine taille $n$, qui est un paramètre de l’expérience. On répète plein de fois la petite expérience : « prendre $n$ sorties de la boîte noire et ajouter leur moyenne à un histogramme ». En abscisse on a donc les éléments de $\{0/n,1/n, 2/n, \ldots, n/n\}$, et en ordonnée le nombre de fois qu’on a obtenu ce résultat. Si tu traces une courbe pour relier les différents batons, pour $n$ assez grand, elle va typiquement ressembler à une cloche, avec un maximum en $p$. Autrement dit, on remarque expérimentalement que la distribution "empirique" de la moyenne des sorties de la boîte noire se rapproche d’une distribution normale.
C’est un résultat central de probabilité qui s’appelle le théorème central limite : pour $n$ suffisamment grand, la quantité ($\overline{X_n}$ est la moyenne que tu calcules):
vaut approximativement1 la probabilité qu’une variable suivant une loi normale (centrée réduite) soit entre $-\theta$ et $\theta$. Or, si on choisit $\theta=1.96$, cette probabilité vaut quasiment… $0.95$ !
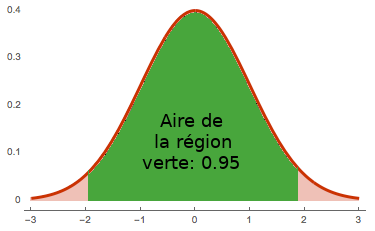
Graphiquement : si je dessine la courbe représentant une densité de probabilité d’une loi réelle, la probabilité qu’une variable aléatoire suivant la loi associée soit dans $[-\theta,\theta]$ est exactement l’aire de la région formée par la courbe entre $-\theta$ et $\theta$. Dans le cas de la loi normale, ça veut dire que l’aire de la courbe de sa densité entre $-1.96$ et $1.96$ vaut à peu près $0.95$ :
Densité normale
(Désolé pour le dessin moche, et j’ai volé la courbe quelque part sur Google Images.)
Pour la dernière question, je ne connais pas de bouquin là-dessus sans trop de maths. Je pense qu’à la différence de pas mal de domaines des maths, les outils utiles dans les stats du quotidien sont des résultats non triviaux de probabilité. Ça me paraît un peu compliqué de bien comprendre toutes ces choses avant d’avoir des bonnes intuitions des concepts centraux en proba.
Il y a plusieurs manières de rendre ça rigoureux, mais la plus simple consiste à écrire $\lim_{n\to \infty}$ à la ligne du dessus. ↩
@Dwayn :
L’exemple que tu donnes avec le dé pipé est trompeur.
Si je lance un dé 4 fois de suite, et qu’il me donne 4 fois le même résultat, alors je peux déjà déduire que le dé est pipé, avec 5% de risque de me tromper.
Avec 200 lancers, et 200 fois le même résultat, alors tu peux aussi dire que le dé est pipé, il y a toujours un rique de te tromper, mais le risque est extrêmement faible.
Juste pour être sur : la variable $\overline{X_n}$ est la moyenne (arithmétique) de tous les résultats obtenus ?
Ça me paraît un peu compliqué de bien comprendre toutes ces choses avant d’avoir des bonnes intuitions des concepts centraux en proba.
À vrai dire, je m’intéresse aux stats, aux probas et aux combinatoires, donc si tu as des ressources ou des moyens de formation (autres que le bac ) à me proposer, je suis preneur.
D’ailleurs, j’ai l’impression qu’on peut obtenir la formule de l’écart-type à partir de cette formule. C’est vraiment le cas ?
À vrai dire, je m’intéresse aux stats, aux probas et aux combinatoires
On entend par "probas" la version théorie de la mesure. C’est assez difficile à aborder si tôt … mais ça explique ce que tes cours n’expliquent pas.
Et pour cause. Si tes cours n’expliquent pas, c’est pas qu’ils sont nuls, c’est que c’est assez difficile à appréhender et que ça n’est pas nécessaire : on a fait des proba bien avant leur formalisation au XXe.
Pour l’écart type, dans le cas de données classiques, il y a une formule, qui n’est pas celle que tu proposes.
Ce que j’appelle des données classiques, c’est par exemple : j’ai une population de 100 individus, j’ai l’âge de chacun, et je veux calculer l’âge moyen, et l’écart-type de l’âge.
Les valeurs traitées sont donc des entiers , ou plus généralement des réels, et pas uniquement les valeurs 0 et 1.
Dans ton cas, les valeurs sont toutes 0 et 1. Du coup, il peut y avoir des formules spécifiques pour le calcul de l’écart type. Et peut-être que la formule générale devient cette formule, dans ce cas précis.
Pour t’en assurer, tu peux reprendre la formule générale, et faire les vérifications.
Edit : En fait, non, ta formule ne peut pas être bonne. En fait, p = Xn, donc ton numérateur est nul, et ta formule donne systématiquement 0.
Je sais pas trop où tu en es dans les maths, mais voilà un très bon poly de probabilité sans théorie de la mesure : http://www.lpma-paris.fr/dw/lib/exe/fetch.php?media=users:amaury:probas-lambert.pdf
En fait, ce que je voulais dire c’est « j’ai l’impression que la formule de l’écart-type ressemble à ce morceau de formule ci, est-ce qu’elles ont un lien direct ou c’est accidentel ? ». Désolé pour le quiproquo.
Je sais pas trop où tu en es dans les maths, mais voilà un très bon poly de probabilité sans théorie de la mesure : http://www.lpma-paris.fr/dw/lib/exe/fetch.php?media=users:amaury:probas-lambert.pdf
Juste pour être sur : la variable $\overline{X_n}$ est la moyenne (arithmétique) de tous les résultats obtenus ?
Oui, c’est ça. En fait « l’objet » $\overline{X_n}$ est une variable aléatoire (dans la formule que tu cites un peu plus bas, c’est le terme probabiliste). C’est un raccourci pour :
où $X_i$ est la variable aléatoire correspondant à la sortie de la $i$-ème boîte noire ($X_i$ suit donc une loi de Bernoulli de paramètre $p$). En particulier la remarque plus haut :
Edit : En fait, non, ta formule ne peut pas être bonne. En fait, p = Xn, donc ton numérateur est nul, et ta formule donne systématiquement 0.
n’a pas de sens car $\overline{X_n}$ est une variable aléatoire et $p$ un nombre réel fixé.1
À vrai dire, je m’intéresse aux stats, aux probas et aux combinatoires, donc si tu as des ressources ou des moyens de formation (autres que le bac ) à me proposer, je suis preneur.
Ça existe probablement, mais je n’en connais pas, donc je ne peux pas t’en recommander un plus qu’un autre. Les documents que cite @Würtz ont l’air de qualité, mais ça m’étonnerait qu’on puisse aborder ça sérieusement au niveau Bac… Après en voyant les trucs que tu ne connais pas, ça peut te donner une idée des concepts avec lesquels il faudrait devenir familier.
M’enfin j’ai pas d’autres conseils que faire des maths, disons de niveau L1/L2, sur des chapitres qui te plaisent (au fond peu importe lesquels, l’important c’est de pratiquer).
D’ailleurs, j’ai l’impression qu’on peut obtenir la formule de l’écart-type à partir de cette formule. C’est vraiment le cas ?
Oui, tu as sans doute reconnu le $\sqrt{p(1-p)}$. Ce n’est effectivement pas un hasard : ici, on a appliqué le théorème central limite au cas particulier des $X_i$ qui suivent des Bernoulli de paramètre $p$. L’énoncé complet le plus classique du théorème est :
Si $X_1, \ldots, X_n, \ldots$ sont des variables aléatoires indépendantes suivant une même loi d’espérance $\mu$ et d’écart-type $\sigma$ (non nul), alors :
Et on lit la partie de droite « converge en loi vers une loi normale centrée réduite ».
Ce qu’on appelle convergence en loi, c’est ce qui nous permet d’écrire l’égalité des deux probabilités dans mon message précédent.
Du coup, on ne déduit pas la formule de l’écart-type du théorème central limite (c’est plutôt l’inverse). Le TCL c’est un outil plutôt avancé, tandis que la formule de l’écart-type d’une Bernoulli est facile à calculer avec la définition.
En fait ça en a un pour les probabilistes, qui écrivent parfois $X=x$ (avec $X$ variable aléatoire et $x$ réel) au lieu de « $X=$x presque sûrement », ce qui un raccourci pour « $\Pr(X=x)=1$ ». M’enfin cette égalité n’est pas vraie en général dans notre cas. ↩
Je vais relire une ou deux fois le topic pour bien assimiler tout ça et je le passe en résolu. C’est vraiment motivant d’arriver à comprendre enfin ce concept.
Merci !
C’est pas français, mais « merci beaucoup » c’était pas assez fort. :) ↩
Connectez-vous pour pouvoir poster un message.
Connexion
Pas encore membre ?
Créez un compte en une minute pour profiter pleinement de toutes les fonctionnalités de Zeste de Savoir. Ici, tout est gratuit et sans publicité.
Créer un compte




 ).
).
 ) à me proposer, je suis preneur.
) à me proposer, je suis preneur.