Je ne suis pas convaincu, je pense qu’il faut qu’on garde une séparation modèle (base de données/stockage) et controlleur (action/traitement des données) un peu comme le modèle MVC de programmation. Ou Microsoft Access qui fait une séparation entre les tables, les vues, les requêtes et les formulaires.
Ok on peut en parler… Pourquoi considères-tu qu’il faille garder cette séparation ?
Je suis persuadé qu’il faut donner une ossature/structure principale. Puis à cette ossature greffer des propriétés.
Par contre ces propriétés annexes devrait suivre une norme, une structure, un typage précis, ou un système de suggestions de nouvelles propriétés :
Pour être certain qu’on va affecter un nom identique à un même champs 2 semaines après ou s’il y a plusieurs utilisateurs.
Pour qu’on puisse s’y retrouver en cas d’action/traitement automatique pour travailler sur les données.
Quand je parle de typage précis c’est d’overRide le format VarChar pour ajouter un type : Téléphone, Adresse, CP, etc…
Que penses-tu de ceci :
Quand on travaille sur un objet (appelons ça comme ça pour le moment), on a deux situations possibles :
Il y a deux problèmes à traiter, comme tu le mentionnes.
-
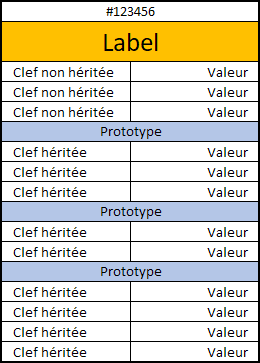
Il pourrait y avoir une typo : simplement parce qu’on a mal orthographié une clef, on se retrouve avec une nouvelle propriété alors qu’on voulait modifier la valeur d’une propriété héritée.
-
Il pourrait y avoir un problème de type : on override une valeur, mais en donnant un type qui provoquera, ailleurs dans le système, des erreurs parce que ce type ne convient pas à cet endroit.
Donc je propose deux solutions.
Si on souhaite créer une nouvelle propriété, non héritée donc, on doit le faire explicitement. Si c’était du code, on aurait une instruction "new" par exemple, mais là on envisage plutôt un logiciel intégré, donc cela se traduirait par
1) une action explicite de l’utilisateur pour exprimer sa volonté de créer une propriété non héritée, et
2) une représentation visuelle du statut "non hérité" de la propriété.
Si au contraire on souhaite overrider une valeur, on ne peut le faire qu’un choisissant un type qui soit
Puisque les valeurs sont des objets, leurs types sont définis par les prototypes qu’elles ont. Donc par exemple, si j’ai une propriété prévue pour recevoir des valeurs ayant "quadrilatère" en proto, je peux aussi y mettre des valeurs ayant "quadrilatère" et "parallélogramme" en proto. Du moment que le proto "quadrilatère" est présent, on en bon. Ensuite, plus tu vas vers les objets héritiers, plus tu obtiens des propriétés spécifiques.




 Pourquoi ne pas accentuer l’utilisation d’ACCESS et des vues ?
Pourquoi ne pas accentuer l’utilisation d’ACCESS et des vues ?