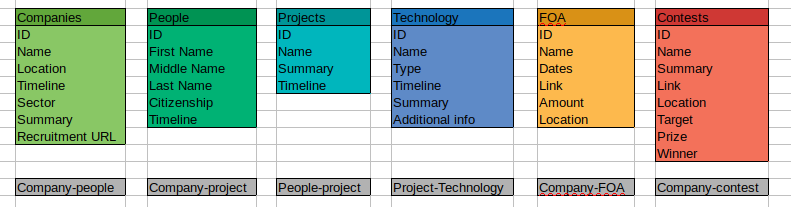
Bonjour,
Pour des besoins semi-professionnel, j’ai besoin de créer une petite base de données (quelques milliers d’entrées tout au plus). Je n’ai jamais fait ça, et je n’ai pas trop envie de devoir y revenir dans quelques mois, donc je me demandais comment le faire au mieux, et en écrivant sur un papier mes tables, je me suis retrouvé avec un certains nombre de cas de redondances. Je veux dire :
Projets
- nom
- personnes
- date
- …
Personnes
- nom
- compagnie
- projets
- …
compagnie
- nom
- personnes
- projets
- …
Vous voyez où je veux en venir. Si je procède de cette manière, ça me semble plus naturel. Mes requêtes seront sûrement aussi plus facile. Mais les informations sont dupliquées et pourraient être retrouvées.
Comment fait-on quand on fait les choses bien ?
Merci !
+0
-0