- Moté,
Salut tout le monde,
Je souhaite recueillir votre avis sur ma structure de BDD. Avant de vous expliquer mon besoin, je vous précise qu’actuellement je souhaite travailler un peu cette structure de BDD et éventuellement la remplir, mais que je n’ai pas prévu pour l’instant de l’exploiter dans le sens d’en créer une interface. J’utilise pour l’instant LibreOffice Base et je verrai ce que je réussirai à faire un jour, ou je la donnerai à d’autres.
Certains m’ont déjà vu parler de ce que j’ai fait pendant mon stage dernier. J’ai travaillé sur les filières locales de matériaux durables pour le BTP, comprendre les matériaux biosourcés, recyclés, ou de réemploi. J’ai notamment consulté des listes et des listes d’entreprise pour en faire un tableau lui-même exploité dans un Power BI. L’idée global d’avoir un chantier dans telle région et de chercher dans la BDD quelles sont les entreprises qui peuvent proposer tels matériaux, de telles origines, pour tel usage.
Est-ce que vous pourriez me dire ce que vous en pensez ?
Quelques petites précisions :
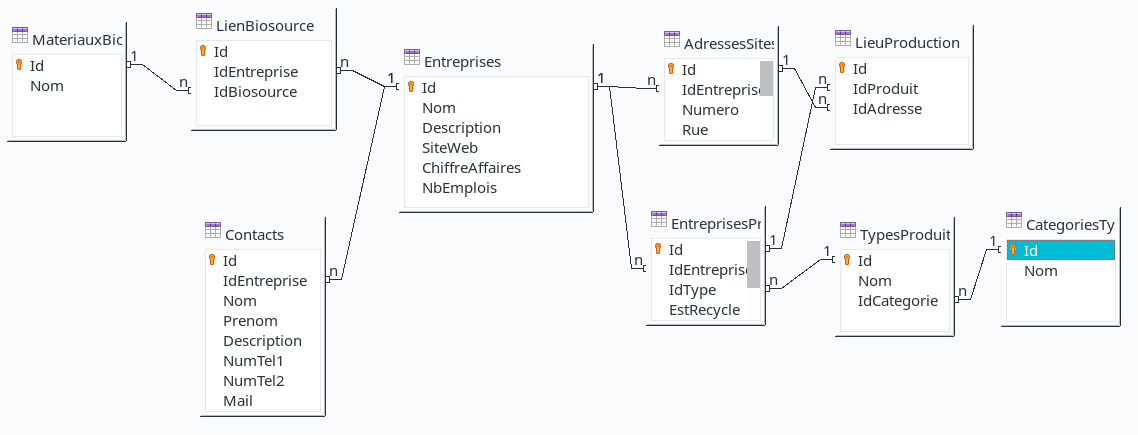
- Les liens sont bien affichés de 1 vers n, il faut éventuellement agrandir pour le voir.
- Les clefs primaires sont indiquées avec un petit symbole de clef orange. De toute façon, chaque table a actuellement un champ Id qui sert de clef primaire.
- Au niveau des types, j’ai des Int (pour les Id, notamment), de mémoire quelques SmallInt, beaucoup de texte (VARCHAR), rarement des textes sans casse (VARCHAR_IGNORECASE, ou un truc du genre), et un "mémo" (LONGVARCHAR je crois) pour la description d’entreprise.
Pour le fonctionnement, donc, il s’agit de remplir en priorité la table Entreprises. Pas mal de champs sont prévus, mais souvent optionnels. On m’a déjà conseillé de reporter les champs concernant l’adresse sociale vers la table Adresses, avec une relation depuis la table Entreprises via l’Id de l’adresse.
Il est prévu de pouvoir avoir plusieurs adresses. Certaines entreprises ont des bureaux dans plusieurs coins. Plus important, il y a souvent plusieurs sites de production. Le champ EstProduction permet de distinguer les sites de production des simples bureaux administratifs.
La table Produits est la table la plus importante. Chaque contient l’entreprise, un type de produit (pendant mon stage, on s’est en parti basé sur la base Inies pour les types, par exemple Isolation, ou Poteau), et une indication de si ce produit est disponible en biosourcé, recyclé ou réemploi. J’aurais pu faire plus simple, mais j’ai trouvé intéressant de dinstiguer selon chaque produit s’il est recyclé ou biosourcé, et non pas de manière globale pour tous les produits de l’entreprise.
Les types de produits sont une table qui va être globalement fixe. C’est en gros une liste, qui peut éventuellement être amenée à changer, mais en gros ça va être fixe. Elle permet à la table Produits de venir piocher dedans. Le champ Ordre est destiné à trier l’affichage des types pour la sélection. La table CatégoriesTypes sert à catégoriser les types de produits, pour faciliter l’insertion et la recherche dans les données.
Dans le même genre, j’ai un tableau Biosource qui sera également une liste de matériaux biosourcés (chanvre, lin, paille, bois, etc.). Il y a une table LienBiosource qui permet de faire le lien entre les entreprises et les matériaux biosourcés qu’elle utilise. On n’aura pas une précision par produit, mais je ne pense pas que ce soit nécessaire parce que sinon ça va être chiant à remplir pour un apport pas forcément intéressant.
Enfin, une table Contacts qui viendra contenir tous les contacts publics pour les entreprises. Lié à l’entreprise, puis des champs classiques, je ne pense pas qu’il y en ait besoin de plus.
Merci à tous !

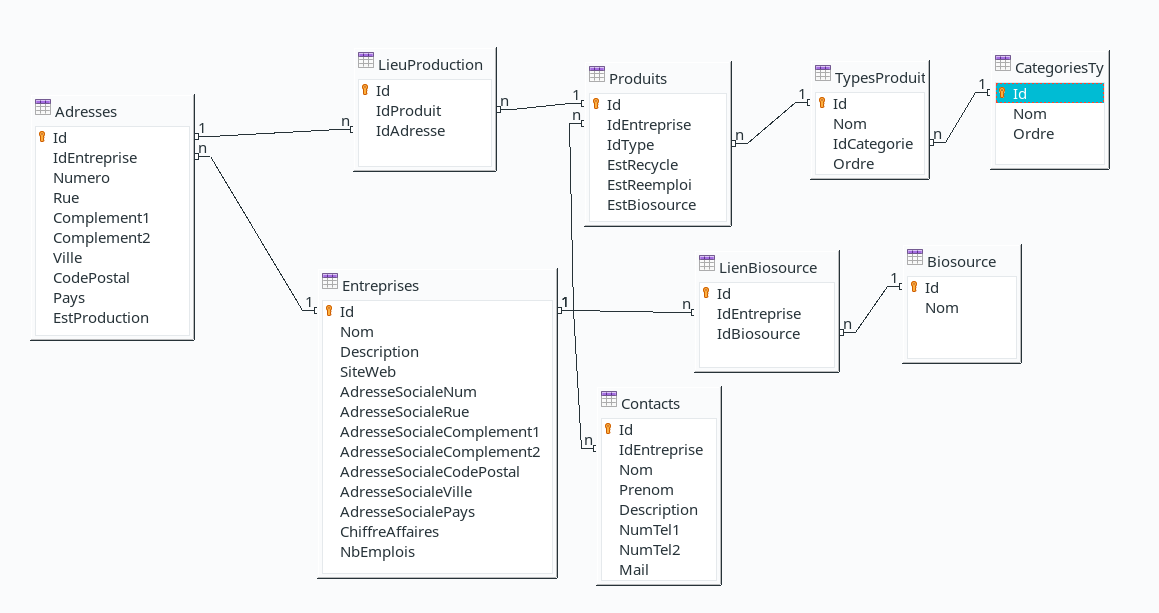
 On pourrait imaginer par exemple vouloir les attributs ChiffreAffaires et NbEmplois par site plutôt que seulement pour toute l’entreprise, comme illustré ci-dessous.
On pourrait imaginer par exemple vouloir les attributs ChiffreAffaires et NbEmplois par site plutôt que seulement pour toute l’entreprise, comme illustré ci-dessous. Je passe en résolu !
Je passe en résolu !