- Moté,
Hello tout le monde,
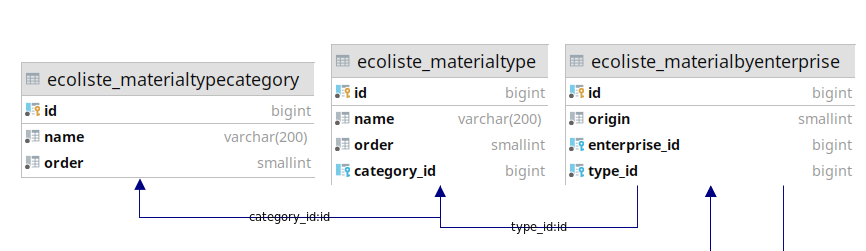
Je suis en train de développer mon app Django (comme certains peuvent déjà l’avoir compris ^^). J’en suis encore au tout début, mais j’ai mis en place mes modèles de BDD et je commence sur mes vues. J’ai actuellement la vue suivante :
def enterprise(request, enterprise_id):
enterprise = get_object_or_404(Enterprise, pk=enterprise_id)
addresses = Address.objects.filter(enterprise=enterprise)
context = {
"page_title": enterprise.name,
"enterprise": enterprise,
"addresses": addresses,
}
return render(request, "ecoliste/enterprise.html", context)
Et en fait, je me rends compte que j’aimerais bien avoir des fonctions nommées plutôt que d’écrire des filtres, et qu’en plus cela augmenterait la réutilisabilité de mon code. Par exemple :
def enterprise(request, enterprise_id):
enterprise = get_enterprise(request, enterprise_id)
addresses = get_enterprise_addresses(enterprise)
context = {
"page_title": enterprise.name,
"enterprise": enterprise,
"addresses": addresses,
}
return render(request, "ecoliste/enterprise.html", context)
Bon, la 1e je suis pas convaincu, parce que la requête get_object_or_404 est vraiment pas complexe, et définir une autre fonction nécessite de passer la requête en paramètre pour gérer la 404. Edit : pas du tout en fait, comme c’est une erreur y a pas besoin  Par contre, c’est normalement le seul cas où j’ai besoin de gérer une 404, donc pour les autres je pourrais définir des fonctions nommées qui fonctionnent bien. D’un autre côté, ce serait vraiment pour quelques lignes de codes.
Par contre, c’est normalement le seul cas où j’ai besoin de gérer une 404, donc pour les autres je pourrais définir des fonctions nommées qui fonctionnent bien. D’un autre côté, ce serait vraiment pour quelques lignes de codes.
Du coup, qu’en pensez-vous ? Est-ce que cela rendrait vraiment mon code plus lisible, et peut-être plus testable ? Et si oui, où est-ce que je devrais rédiger ces fonctions, dans les models, ou dans les views ? (Ou ailleurs ?)
Merci 
 Merci du conseil, je testerai demain !
Merci du conseil, je testerai demain !