
Suite à la proposition de coma de faire un sujet à part pour le cours concernant le ML, j'ouvre ce topic.
Rappel
Il a été question, suite à la proposition de Vayel, de rédiger un cours sur le Machine Learning. Mais ce sujet étant fort vaste, la proposition de scinder les tutoriels a été avancée.
Il est donc question (proposition d'Arius) d'un premier tutoriel d'introduction au ML sur les différents concepts amenés par ce domaine ainsi que sur ses utilités, etc. Et d'un autre sur les différentes méthodes et possibilités d'implémentation.
La grande idée suivante est de ne pas rédiger un long cours sur le ML qui prendrait un temps fou tant à le lire qu'à l'écrire et qui serait bien trop indigeste mais plutôt de faire un cours par sujet abordé.
Les personnes actuellement intéressées pour la rédaction sont :
- Arius ;
- Kjé ;
Vayel (l'es-tu ?);- et moi-même.
Si qui que ce soit est motivé pour rédiger, diriger, coder, whatever, n'hésitez pas à nous en faire part.
Edit
Votre attention s'il vous plait, voici l'article de ML dans sa version du 08/07/2015 - 13:00 ! Jusqu'à présent, il y a le chapitre sur l'apprentissage supervisé et une intro pour l'apprentissage non-supervisé et l'apprentissage par renforcement, chapitres qui doivent encore être étayés.
Bonne lecture ! 
Plan
- Introduction au machine learning
- Définition
- Les trois grands types d’apprentissage
- L’apprentissage supervisé
- Problèmes de régression
- Problèmes de classification
- Régression logique
- Arbres de décisions
- Réseaux de neurones artificiels
- Résumé
- Justesse et convenance de l’hypothèse
- L’apprentissage non-supervisé
- Justesse de la séparation
- L’apprentissage par renforcement
- L’apprentissage supervisé
- Le machine learning dans notre monde d’aujourd’hui
Article
Quand on s'intéresse un peu à la discipline qu'est l'intelligence artificielle (IA en français ou AI en anglais pour Artificial Intelligence), on remarque vite qu'elle est devenue tellement vaste qu'elle est maintenant subdivisée en plusieurs sous-domaines. Un de ces domaines qui existe depuis déjà longtemps, mais qui ne cesse de se compléter, et qui est celui qui nous intéresse ici est le domaine de l'apprentissage.
Cet article a pour objectif de donner un avant-goût de ce qu'est le machine learning, une des manières de traiter l'apprentissage et l'exploration de données. Nous verrons à quoi ça sert, dans quels domaines on le retrouve, quels en sont les grands principes, comment le catégoriser, le hiérarchiser, etc.
Bien que le machine learning repose sur des bases mathématiques d'analyse, de probabilités et d'algèbre linéaire entre autres, le but ici n'est pas d'expliciter tous ces calculs longs et relativement compliqués pour certains. Les détails des algorithmes et leur démonstration n'ont leur place que dans un cours dédié audit algorithme. À mon plus grand désarroi, je ne vous assommerai pas, chers lecteurs, d'équations vicieuses.
Introduction au machine learning
Commençons par un tout petit rappel historique. Le début du XXe siècle a connu une grande avancée de la logique mathématique1. En 1939, la machine Bombe créée par l'équipe d'Alan Turing a été mise au point. Sept ans plus tard, en 1946, ce fut l'ENIAC, la première machine totalement électronique qui vit le jour. Près d'une dizaine d'années plus tard, lors d'une conférence au Dartmouth College, une université plus que réputée aux États-Unis (et membre de l'Ivy League), est apparu pour la première fois le terme Artificial Intelligence (et donc Intelligence Artificielle en français). Tout cela pour dire qu'il n'a pas fallu beaucoup de temps pour que les esprits se rendent compte des capacités de ces nouvelles machines et se mettent fantasmer sur des machines intelligentes.2 À partir de là, il n'est pas facile de dire précisément quand le terme machine learning est apparu, mais il faut savoir qu'il n'a pas tardé : l'algorithme Perceptron, inventé vers 1957, est une implémentation de réseau de neurones artificiels, domaine du machine learning qui sera présenté plus loin.
Où faut-il en arriver ? À la conclusion que le machine learning n'est pas de toute jeunesse et constitue donc une branche de l'IA qui a eu largement (à son échelle) le temps de s'étendre et de se remplir. À nouveau, cet article n'est qu'une introduction au domaine et pas un cours à part entière !
Définition
Avant d'aller plus loin, je propose que nous tentions de définir ce terme, machine learning, présent dans le titre et dans l'introduction qui n'est pas particulièrement explicite (ou dirais-je « pas suffisamment explicite »).
|
Le machine learning (souvent abrégé ML) est une branche de l'IA qui a pour objectif de concevoir des systèmes capables d'apprendre à réaliser une tâche, tâche qu'il peut être assez difficile d'exprimer par des algorithmes dits plus classiques. |
De plus, la traduction française de ce terme est apprentissage automatique. Il est donc effectivement question d'apprendre, et ce, de manière automatique (autonome).
Cependant, ne nous laissons pas avoir si facilement : le ML n'est pas une manière magique de créer une IA forte en lui apprenant à tout faire, mais un regroupement de concepts et d'algorithmes qui peuvent être appliqués, ou non, selon le contexte du problème posé.
Maintenant, voyons un peu comment il est possible de hiérarchiser, de classer les différents sous-domaines du ML.
Les trois grands types d'apprentissage
Comme dit juste avant, le grand principe du machine learning est d'apprendre. Cependant, il n'y a pas qu'une seule méthode qui a été trouvée. Il y en a même énormément, et pour des questions de simplicité, elles ont été regroupées en familles, que l'on appelle les types d'apprentissage (automatique). Les voici :
- l'apprentissage supervisé ;
- l'apprentissage non-supervisé ;
- l'apprentissage par renforcement ;
- et certains ajoutent également l'apprentissage par transfert.
Là, c'est le moment où vous remarquez que le chapitre est nommé « Les trois types » alors que je viens de vous en donner quatre. Il ne sera pas, dans cet article, question de l'apprentissage par transfert car il n'est pas réellement question d'apprentissage. D'ailleurs, le terme anglais est inductive transfer. Il n'y a pas le mot learning dedans. L'apprentissage par transfert est la branche du machine learning qui tente de transférer une connaissance ou une capacité acquise à réaliser une tâche vers une autre tâche non maîtrisée. Par exemple, si l'on dispose d'un système capable de reconnaitre un visage humain sur une photo (ce qui est aujourd'hui largement popularisé), on peut imaginer qu'il y a moyen, sans trop le modifier, de lui faire reconnaitre un visage de chat ou de chien. Cependant, lors de ce nouvel apprentissage, le système est censé se baser sur ce qu'il connait déjà, à savoir la localisation de visages humains sur une photo. Ce domaine peut également s'avérer très intéressant, mais il ne rentre que difficilement dans ce qui nous intéresse ici.
L'apprentissage supervisé
Commençons par une petite mise en situation. Je veux savoir si je peux aller jouer au tennis aujourd'hui selon la météo.3 Ce que nous allons faire, c'est regarder pour les $n$ derniers jours (10, 15, 100, ou peu importe) quel a été le temps et s'il m'a été possible d'aller jouer au tennis. Sur base de ces $n$ données de départ, un algorithme va pouvoir prédire (ce terme est vraiment important ici) si oui ou non il m'est possible d'aller jouer au tennis aujourd'hui en sachant quelle est la météo.
Ce qui a été fait ici est un bel exemple d'apprentissage supervisé car nous n'avons pas dit simplement à l'algorithme Alors, je peux ?! mais nous lui avons fourni du matériel pour pouvoir travailler et donc prédire. Le terme supervisé vient du fait que le programme censé faire la prédiction est nourri par un ensemble de données avant qu'il ne se voit demander quoi que ce soit.
De manière plus formelle, on va parler d'exemple pour désigner un jour avec ses propriétés météorologiques. Toutes les données que l'on fournit au programme sont appelées exemple étiquetés car on leur a donné à chacun une étiquette disant si oui ou non une partie de tennis était envisageable. Aujourd'hui a également ses propriétés météorologiques mais n'a pas encore d'étiquette. C'est justement ce que l'on attend de l'algorithme, de nous donner (par prédiction) cette étiquette. On parle alors d'exemple non-étiqueté. De manière encore plus formelle (j'ai promis de ne pas vous assommer avec des formules et des développements, je n'ai pas promis de ne pas être un minimum formel  ), on note les conditions météorologiques $x$ (avec $x_1$, la température, $x_2$, le temps d'ensoleillement, $x_3$, le taux d'humidité, etc. où $x$ est donc un vecteur) et on note l'étiquette $y$. Nos exemples étiquetés sont donc des couples $(x, y)$.
), on note les conditions météorologiques $x$ (avec $x_1$, la température, $x_2$, le temps d'ensoleillement, $x_3$, le taux d'humidité, etc. où $x$ est donc un vecteur) et on note l'étiquette $y$. Nos exemples étiquetés sont donc des couples $(x, y)$.
L'apprentissage supervisé peut tout de même être une fois de plus subdivisé. Les cas les plus courants d'apprentissage supervisé sont les problèmes dits de régression et ceux dits de classification.
Problèmes de régression
Certains ont probablement déjà entendu le terme régression à un cours de maths. Je ne vais pas rentrer dans une définition de ce qu'est la régression mais sachez qu'ici, le terme régression signifie que nous nous trouvons dans les mathématiques continues, à savoir les ensembles tels que $[0, 1]$, $[-\pi, 21.5]$, $\mathbb R$, etc.
Prenons un exemple : nous avons récupéré le nombre d'heures d'ensoleillement sur 39 jours (pas forcément consécutifs) et nous avons également récupéré la température moyenne de ces jours. Pour une représentation explicite, il est courant d'en faire un graphique. Ici, on représente sur l'axe $x$ (axe des abscisses ou axe horizontal) le nombre d'heures d'ensoleillement, et sur l'axe $y$ (axe des ordonnées ou axe vertical), la température moyenne.
Voici à quoi ressemble ce graphique (il est très dépendant des données mesurées, lesquelles sont ici fictives).
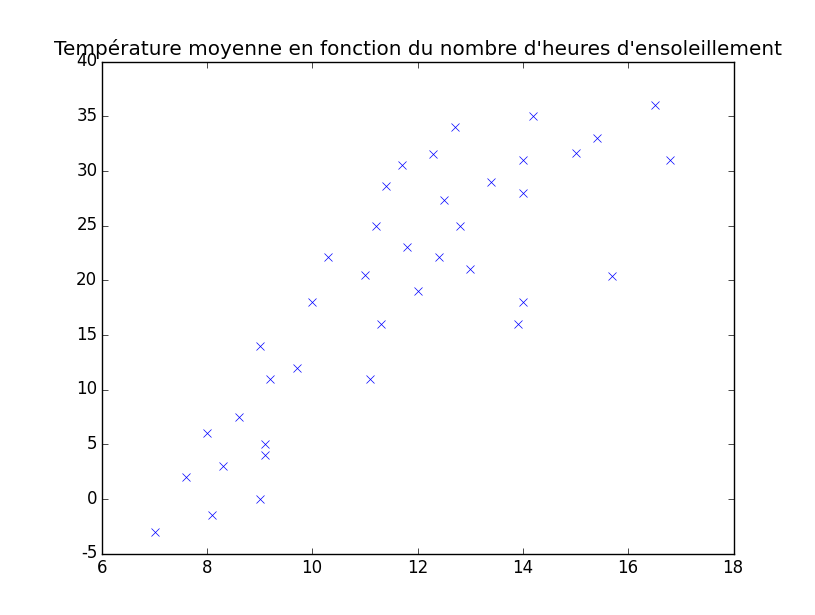
On y voit donc un ensemble de points (représentés par des croix bleues) où chaque point correspond à un couple $(x, y)$ comme expliqué ci-dessus. L'objectif de notre régression est de trouver un lien entre ces deux valeurs, donc a priori de déterminer une fonction (que nous allons appeler $h(x)$ pour « hypothèse ») qui pourrait nous servir à prédire par exemple la température moyenne d'un jour qui aurait 1 heure, 2 heures et demi, 6 heures, 8.9457 heures d'ensoleillement, etc. Mon objectif ici n'est pas de vous apprendre à le faire, mais juste de vous montrer à quoi cela peut ressembler. En réalité, ça peut ressembler à plein de choses ! La plus simple est ce que l'on appelle régression linéaire car il s'agit d'une droite. Voici un exemple de régression linéaire sur notre ensemble de données.
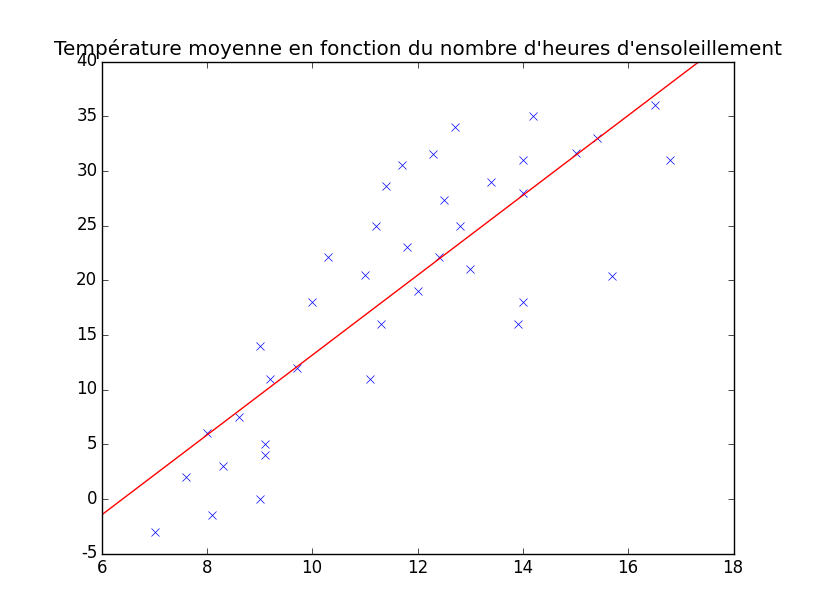
Vous pouvez voir, en rouge sur le graphique, une magnifique droite qui correspond plus ou moins à nos données. Laissons les maths de côté, visualisez juste qu'une fois une hypothèse trouvée, on peut prédire la température moyenne pour un certain nombre d'heures d'ensoleillement. Il suffit pour cela de se placer au bon endroit sur l'axe $x$ (par exemple au point $x=16$) et puis de regarder où se situe, au niveau de l'axe $y$ l'intersection avec notre droite. Voici donc comment trouver la prédiction de la température moyenne d'une journée ayant une heure d'ensoleillement, sur base des 39 jours relevés précédemment :
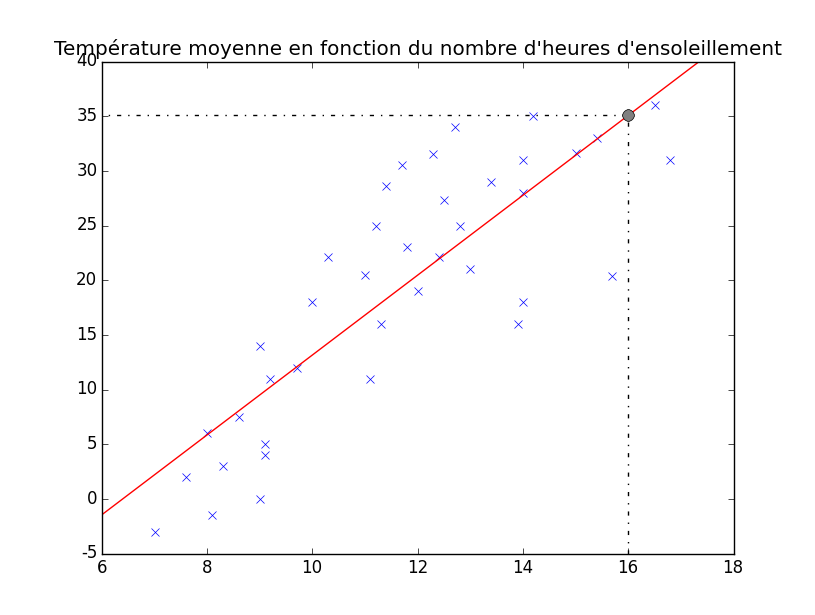
On y voit que lorsque $x$ vaut 16 ici, $y$ vaut approximativement 35. Notre hypothèse nous dit donc que la température moyenne sera de plus ou moins 35 degrés.
Cependant, bien que notre droite convienne assez bien pour certains points du graphique, pour d'autres, c'est moins exact. Il y a donc moyen de trouver d'autres types de courbes qu'une droite. Par exemple une fonction comme celle-ci peut sembler un peu plus précise.
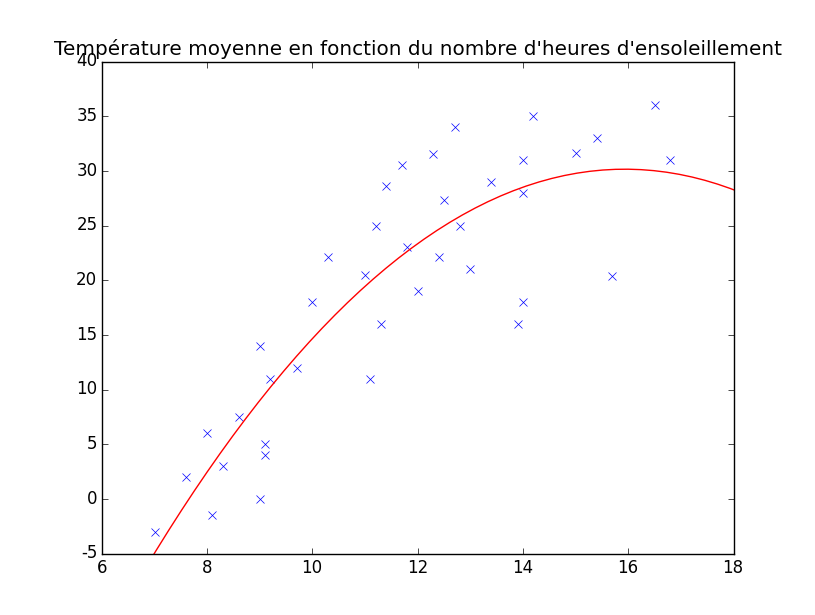
On peut y voir que pour le même point $x = 16$, on a $y = 30$ et plus 35. Il existe plein d'hypothèses possibles avec plein de formes possibles.
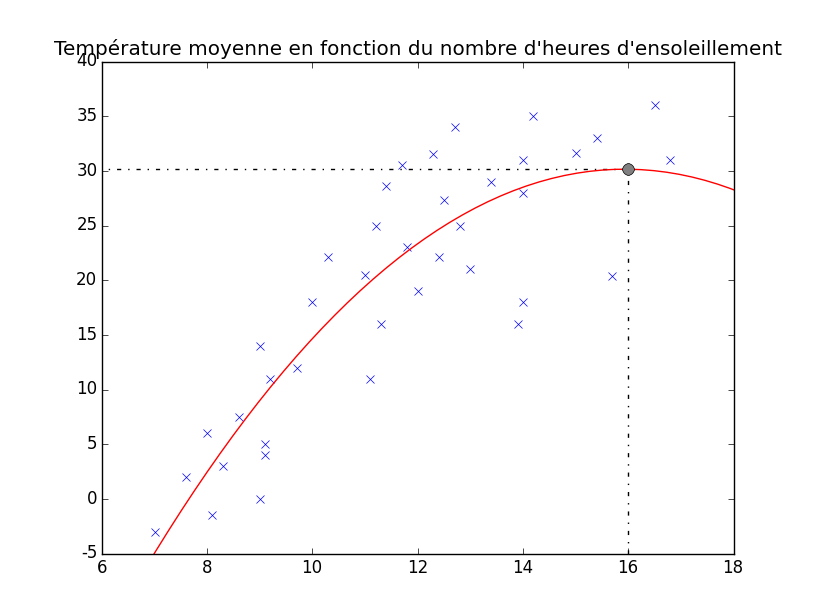
Le travail de la personne chargée d'implémenter un système de machine learning est à ce niveau de trouver quelle(s) hypothèse(s) convient/conviennent le mieux. Certains algorithmes existent afin que cette tâche ne soit plus donnée à un humain : c'est l'algorithme qui va déterminer quelle est la « meilleure forme » pour l'hypothèse selon les données fournies.
L'idée générale d'un problème de régression est donc d'explorer les données que l'on peut lui fournir afin qu'il en déduise une règle, une fonction qui va servir à prédire une valeur de sortie pour de nouvelles entrées.
Ce que nous avons fait est de la régression avec un seul attribut (le nombre d'heures d'ensoleillement dans notre cas). Cependant, il est possible d'appliquer une méthode de régression sur autant de variables (attributs) que l'on veut. Imaginons les attributs suivants pour le même problème : le nombre d'heures d'ensoleillement, la latitude, la longitude, le volume des précipitations, etc. On a alors au moins quatre attributs, ce que l'on ne peut donc plus simplement représenter sur un graphique. Vous comprenez pourquoi j'ai pris un exemple n'ayant qu'un seul attribut donc : pour pouvoir faire une représentation graphique 2D simple.
Nous avons effectivement travaillé ici dans des mathématiques continues car notre température moyenne (notre valeur $y$) est un nombre réel et peut donc prendre une infinité de valeurs différentes.
Exemple
Today's technology has lots of I.Q., but no E.Q.; lots of cognitive intelligence, but no emotional intelligence. So that got me thinking, what if our technology could sense our emotions? What if our devices could sense how we felt and reacted accordingly, just the way an emotionally intelligent friend would?
Voilà ce qu'a dit Rana el Kaliouby, une informaticienne égyptienne partie travailler aux USA. Son problème était qu'elle pouvait communiquer avec sa famille par des appareils communs comme un téléphone ou un ordinateur mais qu'elle ne pouvait communiquer ses émotions.
Those questions led me and my team to create technologies that can read and respond to our emotions, and our starting point was the human face.
Elle a donc choisi d'orienter ses recherches sur une évaluation des émotions depuis le visage humain.
Vous devez probablement vous demander pourquoi je vous raconte tout cela, mais la réponse est simple : nous sommes en plein machine learning. Laissez moi m'expliquer.
Rana el Kaliouby est co-fondatrice de la société Affectiva. Cette société a développé (et développe toujours) une application (entre autres) appelée Affdex. Le but de cette application est de déterminer dans quel état émotionnel se trouve la personne devant l'appareil (tablette, portable, ordinateur, ou autre). Pour une description un peu plus détaillée, je vous invite à regarder la vidéo TED qui suit, voire également le site officiel d'Affectiva.
Rana el Kaliouby: This app knows how you feel — from the look on your face, TED talk
Dans les alentours de 05:00, une volontaire monte sur l'estrade pour faire une démonstration live. On peut voir que son visage est reconnu (marqué par le carré vert) par l'application et que les points principaux du visage sont reconnus également (sourcils, contour des yeux, contour de la bouche, etc.). Sur base de cela, certaines valeurs sont extraites pour être utilisées comme attributs par le cœur du programme : une implémentation de machine learning, et même plus précisément de régression. Effectivement, si vous regardez le dessus de l'image suivante (extraite de la vidéo précédente), vous pouvez voir plusieurs caractéristiques (smile, joy, disgust, brow rise, …) qui sont évalués à l'aide d'un certain pourcentage. C'est ici que se situe notre régression : en fonction de la position, de l'orientation, de la distance entre les points clefs du visage, toutes ces caractéristiques sont évaluées.

Source : Rana el Kaliouby: This app knows how you feel — from the look on your face, TED talk, 05:28
Attention donc : l'ensemble du problème n'est pas du machine learning. Le ML se situe au cœur du programme qui doit être pré-traité.
Problèmes de classification
Par opposition à ce terme de régression, vient le terme classification. Ici, ce terme signifie que nous sommes en présence des mathématiques discrètes, à savoir les ensembles où seules certaines valeurs prédéfinies sont accessibles (par exemple $\{0, 1, 2, 3, 4\}$, $\{-6, -4, -2, 0, 2, 4\}$, $\{$Gauche, Droite$\}$, etc.).
Régression logique
À nouveau, prenons un exemple : nous allons tenter de classifier des élèves selon qu'ils ont réussi ou pas. Pour cela, nous allons utiliser deux informations : leur moyenne à la session d'examens (sur l'axe des abscisse) et leur moyenne tout au long de l'année (sur l'axe des ordonnées). Sur le graphique ci-dessous, chaque point $(x, y)$ représente un élève tel que sa coordonné $x$ est donc la moyenne aux examens et sa coordonnée $y$ la moyenne sur l'année. Si le point est représenté par un losange vert, c'est que l'élève a réussi et passe en première session. À l'opposé, si le point est représenté par une croix rouge, c'est que l'élève ne passe pas en première session (ajourné ou recalé).
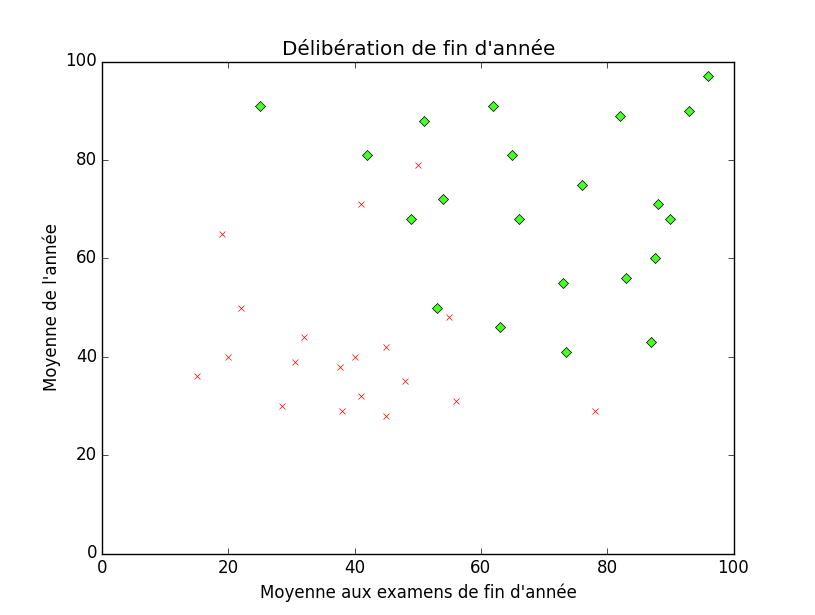
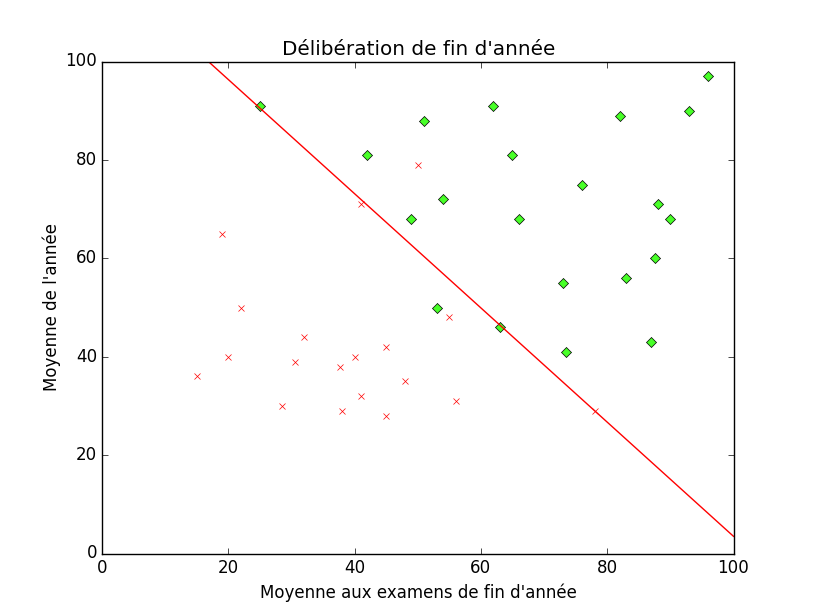
Le but est à nouveau de déterminer un moyen de prédire si l'élève va passer ou non selon ses résultats, que l'on fournit au programme. Ici, il devient difficile de trouver une fonction enverra le couple $(x, y)$ sur soit 1 soit 0 (par exemple) car cette fonction serait totalement discontinue et impossible à étudier et surtout à réutiliser. Il faut donc ruser. Il apparait tout de même une séparation relativement claire entre les élèves ayant réussi et ceux ayant raté. Nous pouvons tenter cette fois de trouver une courbe (une fonction) qui séparera nos deux classes4. Cette courbe peut être linéaire, quadratique ou autre, tout comme pour la régression.
Voici une possibilité de séparation :
À partir de là, pour réellement classifier (car c'est ce qui est attendu tout de même), il faut placer le nouveau point sur notre graphique et déterminer de quel côté de la courbe d'hypothèse il se situe. Par exemple, si nous avons un élève qui a fait approximativement 55% à sa session d'examens et qui a eu une moyenne de 60% au long de l'année. En le plaçant sur le graphique, on le voit au dessus de la courbe d'hypothèse, du côté des points verts, donc admis.
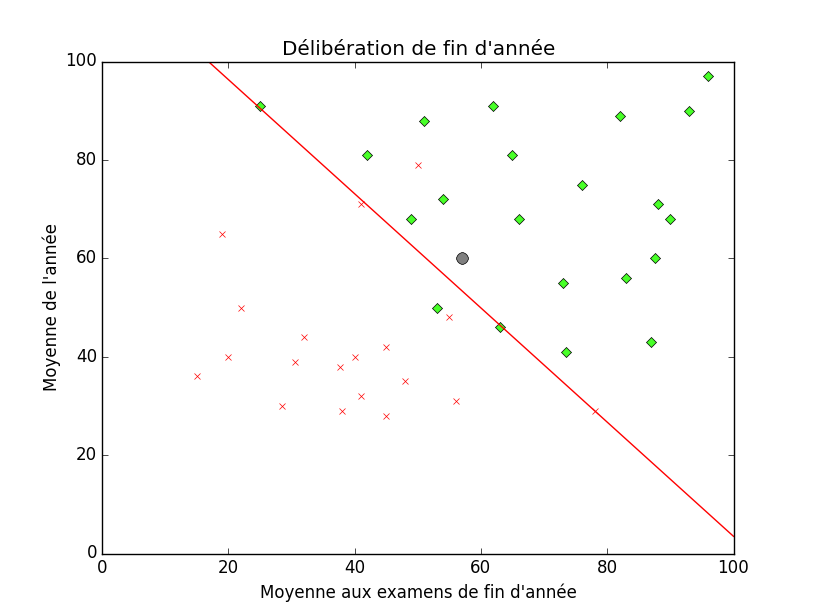
Ce que nous venons de voir ici ressemble, mine de rien, très fort aux problèmes de régression. De plus, cette méthode de classification (par une fonction à valeur réelle $\mathbb R^n \to \mathbb R$) s'appelle régression logique. Le terme régression vient du fait que nous utilisons une fonction à valeur réelle et le terme logique vient de l'utilisation de la fonction logique (également appelée fonction sigmoïde pour ceux qui voudraient aller creuser un peu plus loin).
Arbres de décisions
Afin de résoudre des problèmes de classification, il est également assez courant de trouver des arbres de décisions. Comme son nom l'indique, un arbre de décision est un arbre. Un arbre (en algorithmique) est composé de nœuds qui sont reliés entre eux par des arrêtes selon une certaine hiérarchie. Chaque nœud a un certain nombre de fils. On appelle le tout premier nœud (celui tout au dessus de l'arbre) la racine. On appelle les derniers nœuds (ceux n'ayant pas de fils) des feuilles.
Assez parlé théorie, qu'est-ce que les arbres ont avoir avec le machine learning ?!
Vous vous souvenez de l'exemple sportivo-météorologique d'au dessus ? C'est en réalité l'exemple qu'a utilisé Ross Quinlan pour expliquer son algorithme de machine learning appelé ID3 qui n'est autre qu'un algorithme de génération d'arbres de décisions. Je ne vais pas vous faire l'explication de cet algorithme ici, ce n'est pas le but de cet article, je vais juste tenter de vous donner une intuition de comment fonctionne un arbre de décision.
Voici un exemple d'arbre de décision (qui est en réalité le résultat optimal pour l'exemple d'explication de l'algorithme ID3) :

Dans notre exemple, nous avons les attributs suivants : Prévisions (qui peut prendre les valeurs suivantes : Ensoleillé, Nuageux, et Pluvieux), Humidité (qui peut prendre les valeurs suivantes : Faible, et Élevée), et Vent (qui peut prendre les valeurs suivantes : Faible, et Fort). Il y a en réalité un quatrième attribut, qui est la température mais qui n'apporte pas d'informations strictement nécessaire pour arriver à cet arbre optimal pour les exemples étiquetés donnés comme ensemble d'entrainement.
Si maintenant nous voulons déterminer s'il est possible de jouer au tennis un jour où les prévisions météorologiques sont pluvieuses avec un vent fort, une humidité faible, et une température moyenne. Comment faire pour avoir notre réponse ?
Imaginons maintenant que nous partions forcément de la racine, et qu'à chaque fois que nous arrivons sur un nœud, nous avons une question sur un des attributs. Le premier nœud nous pose comme question Comment sont les prévisions ?, ce à quoi nous pouvons répondre pluvieuses. Si nous regardons bien, ce nœud a trois fils, et celui qui correspond à des prévisions pluvieuses est celui tout à droite. Nous retombons sur un nœud, nous avons donc à nouveau une question, qui, cette fois-ci, est Comment est le vent ?, ce à quoi nous pouvons répondre fort. Une fois de plus, ce noeud a plusieurs fils, et celui correspondant à un vent fort est celui de droite. Si nous continuons sur ce chemin, nous arrivons sur une feuille disant non. Nous avons donc réussi à classifier notre exemple : la valeur que doit prendre notre valeur $y$ (à savoir la classe) est non.
Tout comme pour les exemples précédents, notre arbre de décisions est tout petit et très simple. Les réels problèmes de machine learning ont des milliers d'exemples et bien souvent des dizaines voire des centaines d'attributs différents.
Réseaux de neurones artificiels
Les réseaux de Neurones Artificiels (ou RNA), aussi appelés ANN (pour Artificial Neural Networks font également partie de tous ces concepts du machine learning. Premièrement, pourquoi réseau, pourquoi neurone, et pourquoi artificiel ?
On parle de neurones car les algorithmes sur des RNA sont inspirés du fonctionnement du cerveau animal qui est un amas de neurones connectés entre eux et qui s'envoient des signaux les uns aux autres.
Voici un schéma de neurone :
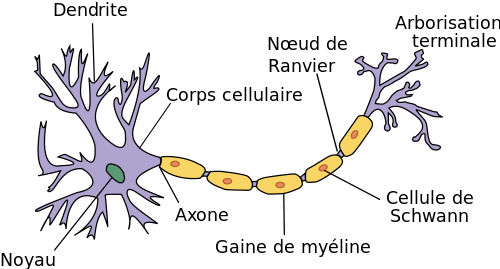
Source : wikimedia, licence CC-SA
Sans rentrer dans les détails, ce qui nous intéresse ici sont les parties suivantes : le corps cellulaire, les dendrites, et l'axone. Chaque neurone (artificiel) a donc un certain nombre d'entrées (inputs) qui sont les dendrites, une unité de travail qui est le corps cellulaire, et une sortie (output) qui est l'axone. Il est commun d'appeler un neurone artificiel une unité logique (UL ou LU pour Logical Unit en anglais).
Voici comment nous pouvons schématiser une telle unité logique :
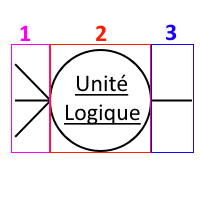
Cette UL a été explicitement décomposée en trois parties :
- la partie 1 (en mauve) qui est l'ensemble des inputs (les dendrites) ;
- la partie 2 (en rouge) qui est l'unité logique en elle-même, celle qui fait les calculs (le corps cellulaire) ;
- la partie 3 (en bleu) qui est l'output (le seul et unique output, l'axone).
Une fois que l'on a une seule unité logique, on ne sait pas faire grand chose, mais lorsqu'on en met plusieurs reliées les unes aux autres, selon des couches, on obtient un réseau !
Voici donc un exemple de réseau (générique) dont j'expliquerai le fonctionnement juste après :
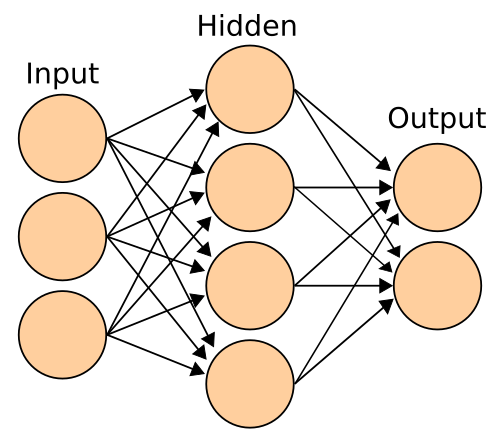
Source : wikimedia, licence : CC-SA
La première couche (ou colonne) est celle des inputs. Les trois neurones tout à gauche représentent chacun un attribut (les prévisions météorologiques, le vent et l'humidité par exemple). Ceux-là n'ont pas d'input car ils sont eux-mêmes les neurones-zéros en quelque sorte. Ils sont ensuite envoyés dans la couche Hidden (qui veut dire caché en anglais) afin que les unités logiques de ce niveau évaluent un résultat à renvoyer à la troisième couche, la couche d'output qui est la sortie, le résultat, la classification. Il peut y avoir plus d'une couche Hidden, il peut même y en avoir autant que l'on désire, mais ici, une seule est représentée pour simplifier le schéma.
Chacune des connections qui vont d'un neurone à un autre va avoir un poids différent, donc va influer sur le neurone suivant d'une certaine manière (plus ou moins forte que ses frères de niveau). Le fait de pouvoir calculer quelque chose de différent à chaque neurone permet d'obtenir des systèmes d'une haute complexité qu'il est difficile voire très difficile d'exprimer à l'aide d'un algorithme classique.
Il est compliqué pour moi de continuer de détailler les RNA sans entrer dans des explications mathématiques du fonctionnement, ce qui n'a pas sa place ici donc ce que je ne ferai pas (de plus, j'ai promis au loup, alors vous comprenez…)
Résumé
Pour récapituler ceci, si l'ensemble des prédictions possibles est fini, nous avons affaire à un problème de classification et si à l'inverse il est infini, nous avons affaire à un problème de régression. Ces classes de problèmes sont assez proches mais se traitent tout de même différemment.
Voici donc comment se déroule un problème classique d'apprentissage automatique lorsque nous sommes en présence d'apprentissage supervisé.
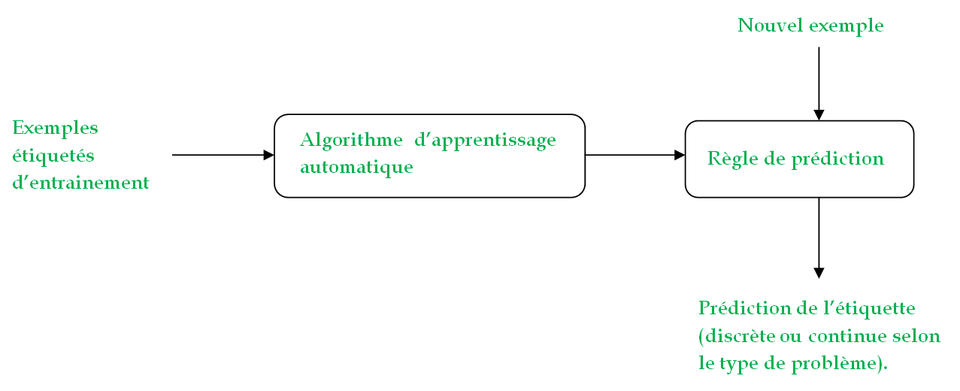
Tout d'abord, on fournit à l'algorithme un set d'exemples étiquetés, sur base desquels ce dernier va déterminer une règle (ou hypothèse). Une fois cette règle trouvée, elle va être réutilisée pour pouvoir prédire les étiquettes de nouveaux exemples.
Justesse et convenance de l'hypothèse
Nous avons vu que dans l'apprentissage supervisé, le programme apprend à réaliser une tâche sur base d'exemples qui lui sont fournis. Avec ces exemples, une hypothèse est trouvée et puis il y a des prédictions avec des valeurs différentes de celles des exemples. Cependant, toute la précision et l'exactitude du programme dépendent de cette hypothèse. Si cette hypothèse est mal choisie, le programme peut devenir faux donc inefficace.
Deux cas de figure peuvent se présenter lors de la détermination de l'hypothèse (en supposant que l'ensemble d'exemples représente assez bien les cas moyens) :
- l'overfitting ;
- et l'underfitting.
Overfitting est le terme anglais (qui peut se traduire en sur-adaptation ou sur-ajustement) qui désigne le cas où l'hypothèse trouvée convient très bien, voire même trop bien, à l'ensemble d'apprentissage. Cela pourrait paraître, au premier abord, d'être une bonne chose. Cependant, l'overfitting peut être plus que nocif pour l'exactitude du programme car la courbe pourrait devenir très irrégulière, très courbée pour parvenir à coller au mieux à l'ensemble d'entrainement.
Si on reprend la mise en situation de la classification ci-dessus, on peut imaginer un cas d'overfitting comme suit par exemple :
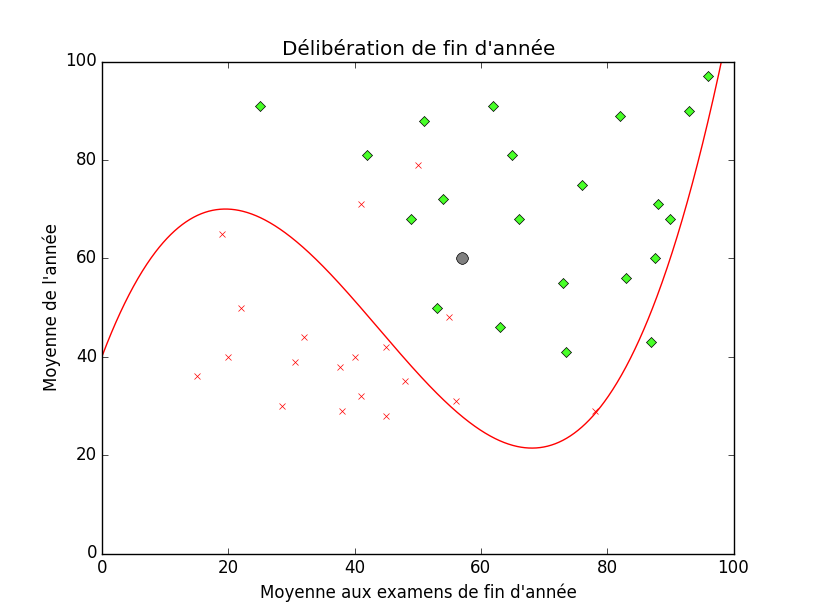
Underfitting est, comme vous vous en doutez, le terme opposé. Il peut se traduire en sous-adaptation ou sous-ajustement et désigne le cas où l'hypothèse est trop simple et ne convient pas suffisamment ne dut-ce qu'à l'ensemble d'entrainement.
Toujours sur ce même exemple, un peut imaginer un cas d'underfitting par exemple si on se contente de dire « si l'élève 50% à ses examens, il passe ». Sur graphique, cela ressemblerait à ceci :
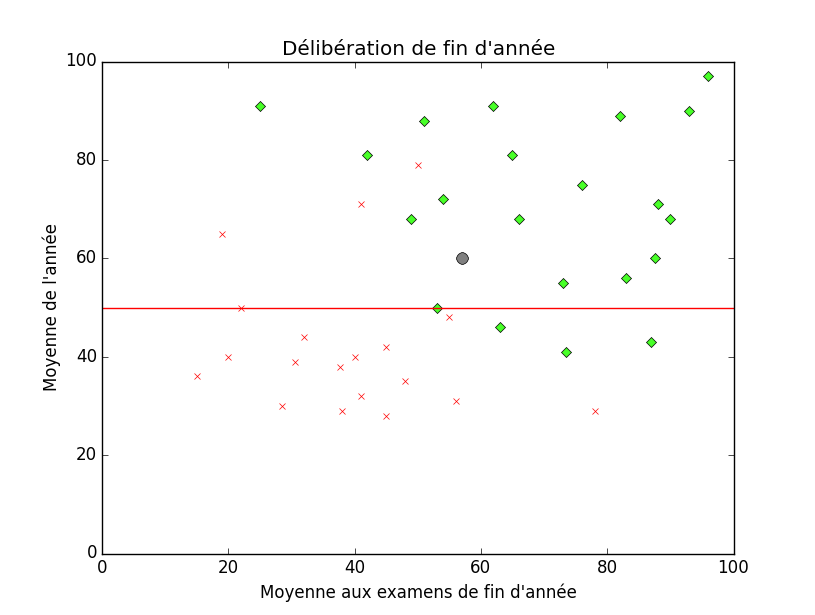
Il faut savoir que ce sont deux extrêmes que l'on essaye à tout prix d'éviter. Cependant, bien souvent, il y a plusieurs hypothèses possibles et c'est au(x) développeur(s) ou au(x) chef(s) du projet de choisir celle(s) qui sera/seront utilisée(s).
L'apprentissage non-supervisé
Tout comme pour l'apprentissage supervisé, dans l'apprentissage non-supervisé, l'algorithme reçoit des exemples . Cependant, contrairement au cas précédent, ces exemples ne sont pas pré-étiquetés. Le but d'un tel algorithme est alors de réussir à classer l'ensemble de données hétérogènes reçues. L'approche de ce genre de problèmes est plus probabiliste que précédemment.
Ce genre de problème s'appelle clustering en anglais et peut se traduire par partitionnement en français.
Remettons-nous en contexte : le service de Google News analyse constamment des articles venant de tout internet. Cependant, ces articles n'ont pas une étiquette bien précise faite pour Google News afin qu'il puisse regrouper les articles sur le match de foot du dimanche, ceux sur les élections présidentielles au Cameroun, ceux sur la taille moyenne des carottes naines vertes en Papouasie-nouvelle Guinée, ceux sur… Enfin je crois que vous avez compris le principe.
Google News analyse donc le contenu de ces articles et les classe tout seul sans qu'aucune information sur le nombre de classes attendues ou sur les propriétés de classification ne soit données. Il fait donc du partitionnement, ou ici de manière plus générale de l'apprentissage non-supervisé.
Pour prendre un exemple un peu plus simple à expliquer que Google News qui classe tout seul selon un nombre indéfini de classes, nous allons tenter d'imaginer un système censé déterminer différents types d'utilisateur de ZdS.
Pour pouvoir simplifier le graphique (2D et pas 3D), considérons uniquement sur l'axe $x$ le nombre de tutoriels et sur l'axe $y$ le nombre d'articles.
Sur l'image animée suivante, on peut voir au début un ensemble de points noirs (qui représentent les membres représentés). Ensuite, il y a deux couleurs : le rouge et le bleu, qui tentent de déterminer deux types d'utilisateurs différents. Il y a les bleus qui sont des auteurs d'articles et les rouges qui sont les auteurs de tutoriels (globalement). J'ai expressément placé un gif animé dans le but de montrer le déroulement d'un algorithme en particulier (les $k$-moyennes). Cet algorithme ici place deux foyers (les croix) aléatoirement sur les données, puis trouve où placer ces foyers au mieux pour partitionner les données selon la ligne bleue continue. De là, il est facile de déterminer à quelle partition fait partie n'importe quel membre : on fait exactement comme pour la classification, à savoir placer le membre au bon endroit sur le graphique puis regarder dans quelle partition il se trouve (de quel côté de la droite).
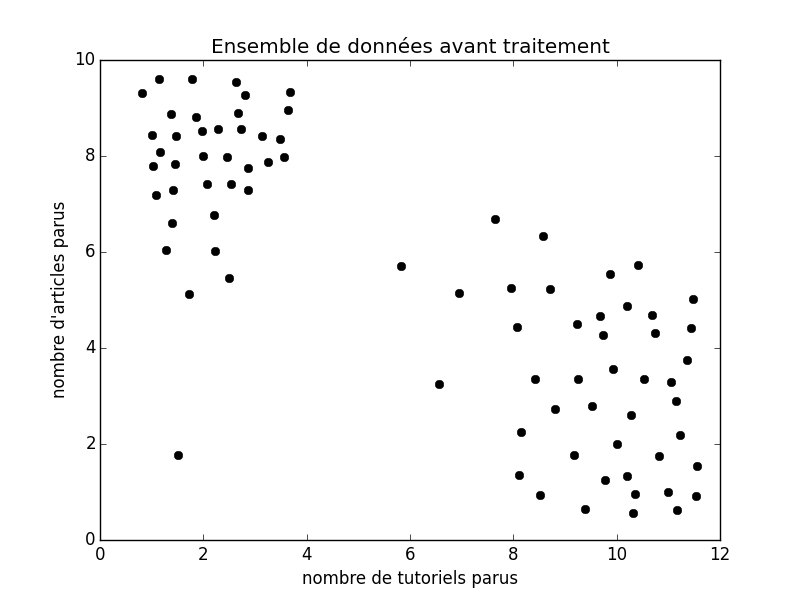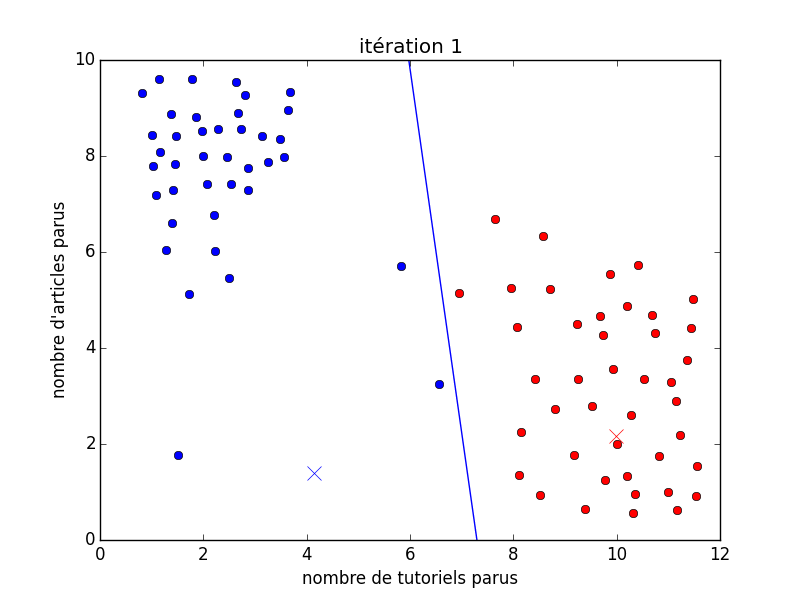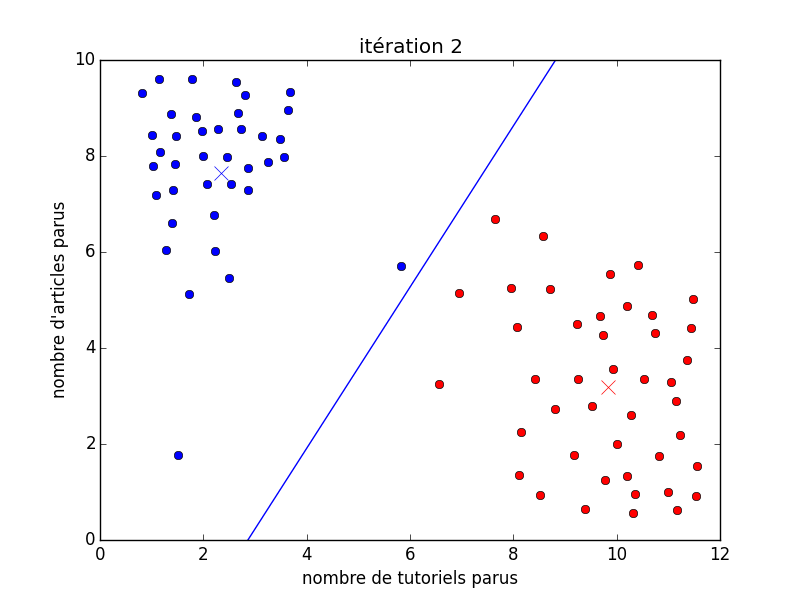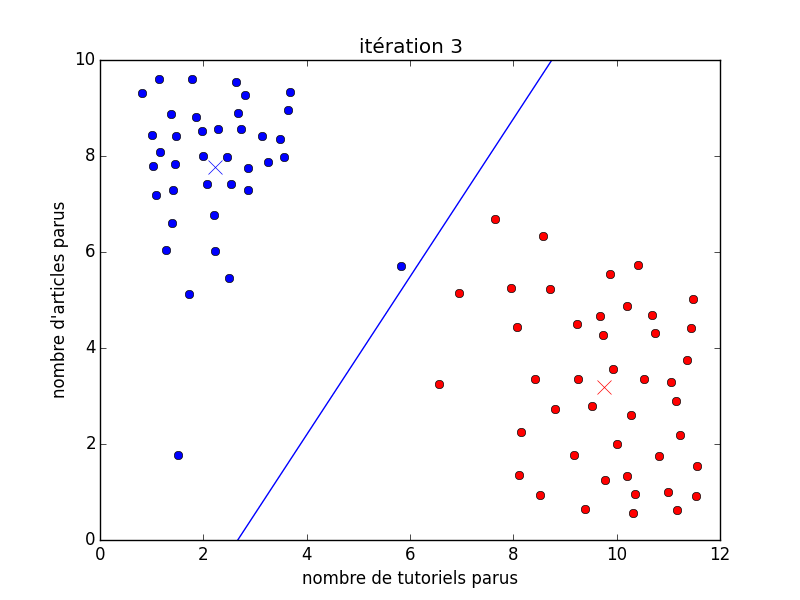
Vous pouvez donc le voir, la grande différence par rapport à l'apprentissage supervisé est le fait que dans ce cas-ci, au tout début (avant la première itération), nous n'avons encore aucune classe. Pour en revenir avec la définition pseudo-formelle donné ci-dessus, avant nous avions des coupes d'exemples $(x, y)$ avec $x$, le vecteur des attributs et $y$, la classe, alors que maintenant, nos exemples ne sont plus qu'un vecteur d'attribut ($x$) et la machine doit se débrouiller seule avec les classes.
Justesse de la séparation
Je rappelle que pour l'apprentissage supervisé, nous avions parlé de l'overfitting et de l'underfitting, deux cas où ce que l'ordinateur a calculé ne convient pas à la réalité. Ces termes sont basés sur le mot fitting, qui est donc relatif aux exemples étiquetés que l'on donne à l'algorithme. On ne peut donc pas les utiliser pour l'apprentissage non supervisé car il n'y a pas d'exemples étiquetés.
Cependant, il peut tout de même arriver qu'une hypothèse ne soit pas bonne, même en apprentissage non-supervisé ! C'est, habituellement, lié soit à l'utilisation d'un algorithme non-compatible avec certaines contraintes du problème, soit à un ensemble de données non-représentatives de la réalité. Sur la figure suivante, nous pouvons clairement voir que la suppression de bon nombre d'auteurs d'articles aient été retirés change totalement la manière de partitionner les données. Cependant, le résultat obtenu reste tout à fait cohérent par rapport à l'algorithme et à ce que l'on lui demande !
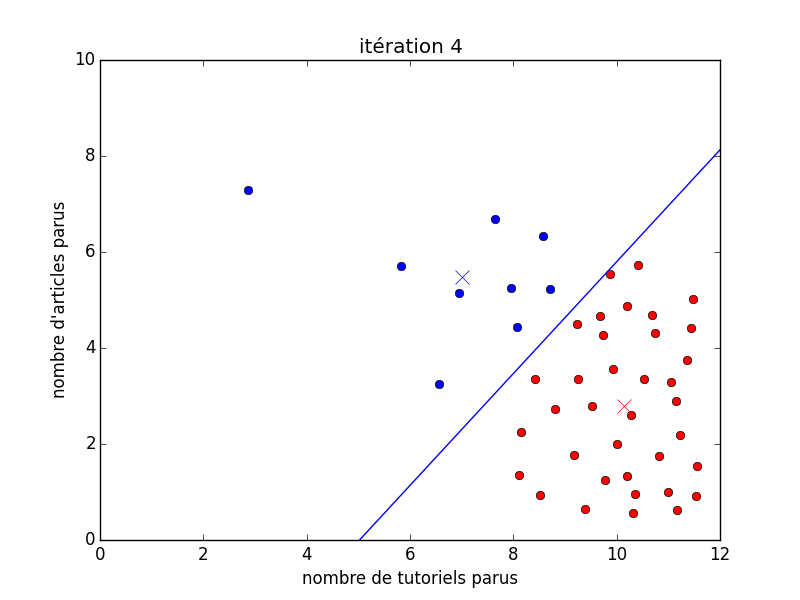
L'apprentissage par renforcement
C'est dans le début des années 1980 que ces algorithmes d'apprentissage par renforcement se sont répandus. Ces méthodes sont fortement inspirées, du moins au début, de l'analyse de la psychologie comportementale. Effectivement, un humain, mais également un chat, un hippocampe ou encore un goéland apprend tout au long de son existence. Je ne vais pas revenir ici sur les théories de Pavlov et du conditionnement mais il est maintenant mondialement reconnu que le comportement d'un être vivant peut être conditionné, donc modifié à l'aide d'un stimulus associé à une action. De manière plus intuitive, commencez une partie d'échec contre quelqu'un qui n'a jamais joué. Vous allez fort probablement gagner (à moins que vous n'ayez jamais joué non plus en quel cas je vous prierais de ne pas faire foirer mes exemples !). Cependant, si vous ne jouez que très rarement mais que votre adversaire s'entraine pendant plusieurs mois voire plusieurs années, il deviendra très certainement meilleur que vous. Il aura donc appris à jouer avec l'expérience.
J'espère que cette métaphore n'était pas trop confuse et que vous comprenez quelle est l'essence de l'apprentissage par renforcement. Effectivement, le but est d'avoir un système dit dynamique, donc qui évolue, qui n'est pas statique. L'apprentissage par renforcement permet donc d'améliorer un comportement en le répétant, en s'entrainant à le faire et surtout en apprenant de ses erreurs.
Le machine learning dans notre monde d'aujourd'hui
Vous ne serez pas surpris, je l'espère, de savoir qu'à l'heure qu'il est, le ML s'est répandu un peu partout. On le retrouve par exemple dans les situations suivantes :
- classification de nos e-mails comme spam/pas-spam (apprentissage supervisé : on a appris aux boites mails à reconnaitre un e-mail de spam d'un e-mail normal) ;
- les systèmes de recommandation des sites comme Amazon (apprentissage non-supervisé : Amazon classe tout seul les différents articles disponibles sur ses serveurs) ;
- les voitures automatiques de Google (apprentissage par renforcement : les voitures avaient des bases mais apprennent ensuite en roulant) ;
- l'identification de maladies (apprentissage supervisé : des médecins peuvent avoir un diagnostic probabiliste selon les symptômes du patient) ;
- partitionnement de l'ADN (apprentissage non-supervisé : des algorithmes tournent pour tenter de trouver certains gênes responsables de caractéristiques physiques, psychologiques, etc.) ;
- et plein d'autres…
Pour conclure, j'espère que cette petite introduction vous a aidé à comprendre un peu mieux ce qu'est le machine learning, dans quels cas c'est utilisé, son importance aujourd'hui, etc. J'espère également que cela vous a donné envie d'en savoir plus sur ce qu'il y a moyen de faire, et comment.
Je tiens à remercier fortement Vayel pour les relectures et les commentaires pertinents tant sur le fond que sur la forme !
PS : il semblerait que les balises maths aient du mal dans les balises secrets, mais vous comprendrez tout de même. 
-
Il est ici question de la discipline mathématique appelée logique qui a pour représentants De Morgan, Boole, Gödel, Hilbert, et compagnie, et non de la notion populaire de logique mathématique que l'on confère allègrement à toute personne ayant une forte intuition mathématique ! ↩
-
Il faut savoir que l'idée d'une machine pensante avait déjà été émise par certains scientifiques (surtout logiciens) tels Alan Turing. Une idée pas si lointaine que cela de l'intelligence artificielle existait déjà avant le premier ordinateur électronique. ↩
-
Toute ressemblance avec l'exemple de Ross Quinlan pour son algorithme ID3 sur des arbres de décision est totalement fortuite. ;) ↩
-
Effectivement, en présence d'un problème de classification, le résultat attendu pour la valeur de $y$ est appelée classe car le but est de classifier les éléments, donc de les associer à la classe correspondante. ↩









{kind=link}
{kind=link}