
- KFC,
Salut,
Alors, pour ma part j'avais deux heures à perdre du coup voici le début d'une ébauche:
- Génération d'un polygone aléatoire qui consiste à générer des points autour d'un centre. Le point suivant est généré par un angle par rapport au précédent et une longueur. Les deux grandeurs sont tirées suivant une loi normale, et les paramètres de variance et de moyenne permettent de gérer la régularité et la rotondité du polygone.
- Comme le polygone n'est pas forcément très joli, on le lisser via l'algorithme itératif de Chaïkin, qui s'apparente à une régularisation via des Splines. Une ou deux passes sont suffisantes, surtout que chaque passe multiplie par deux le nombre de faces du polygone.
Ces deux premières étapes permettent d'obtenir une zone pour une forêt qui semble réaliste.
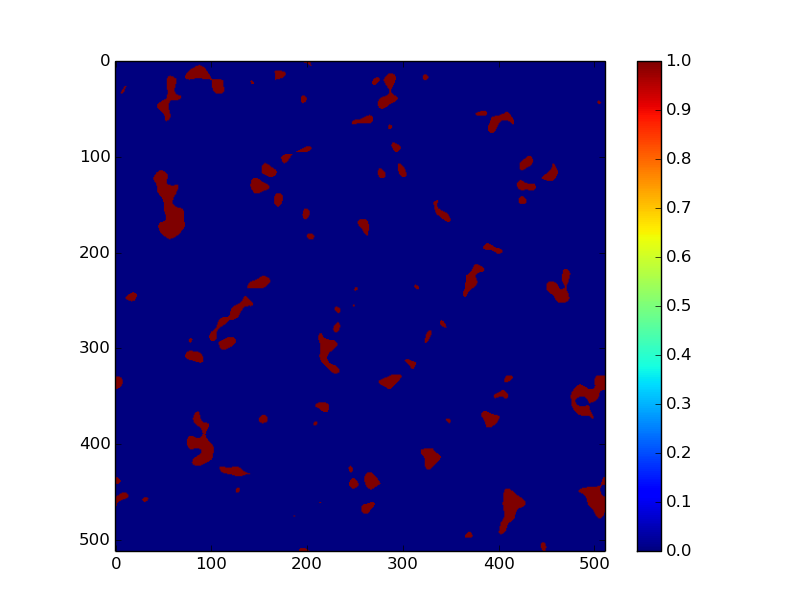
Ensuite, on générer des arbres aléatoirement dans cette zone et selon une distribution de probabilité particulière. Pour cela, on utilise la méthode de rejet pour générer des points à l'intérieur de notre polygone uniquement, et la méthode d'inverse généralisée pour simuler une distribution particulière (sur l'image suivante, selon l'axe x on a une loi normale et selon l'axe y une distribution exponentielle).
Pour le feu, ce qui nous intéresse c'est la "zone d'influence" de l'arbre, c'est à dire la zone dans laquelle tout autre arbre est susceptible de brûler. Sans vent, on peut admettre que globalement cette zone correspond au feuillage, qu'on peut approximer par un disque. Comme le rayon du feuillage est plus ou moins proportionnel à l'age de l'arbre, on modélisera le rayon d'influence par une loi exponentiel. Du coup, pour chaque arbre, on tire aléatoirement un rayon selon cette loi.
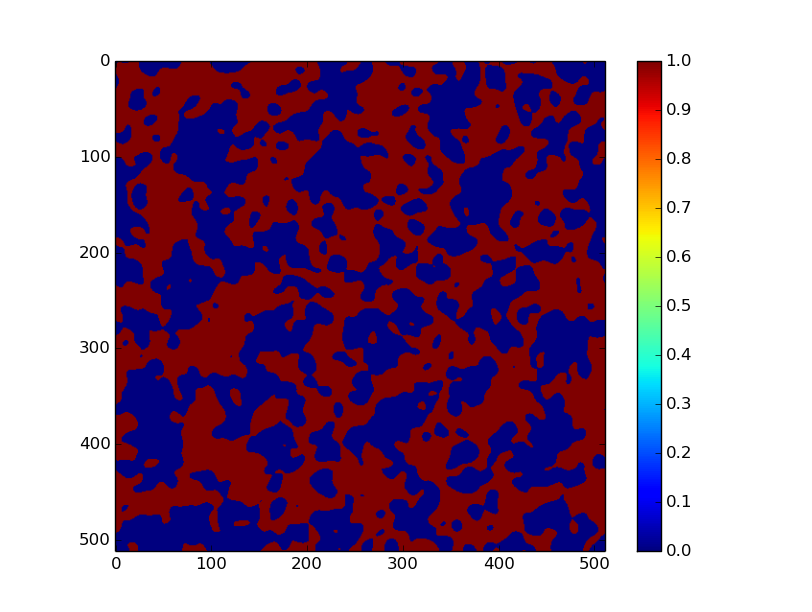
Pour chaque arbre on calcul le graphe de recouvrement, c'est à dire que si deux arbres ont une zone d'influence qui s'entrecoupe, on les relie.
Bon, comme tout à été tiré aléatoirement jusqu'à présent, on considère arbitrairement que le premier arbre de notre liste à décidé de faire une auto-combustion. De cet arbre, grâce à un algorithme de parcours tout simple, on marque comme brûlé les arbres de voisins en voisin.
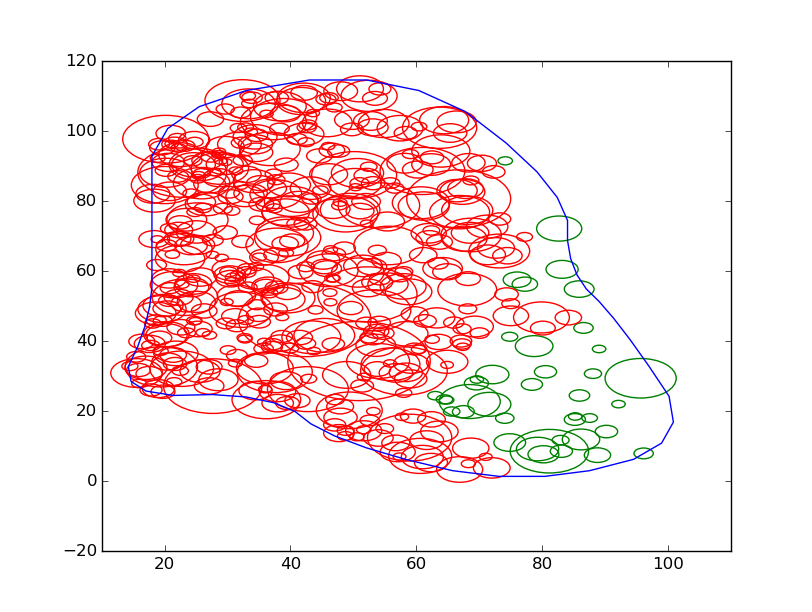
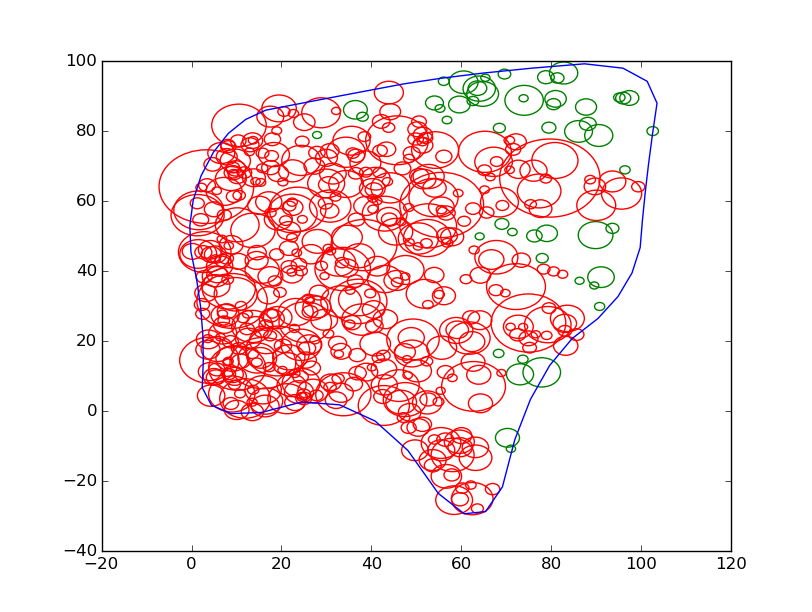
Comme on peut s'y attendre, les arbres non brûlés sont situés à droite puisqu'il y a une densité plus faible à droite qu'à gauche à cause de la densité exponentielle.
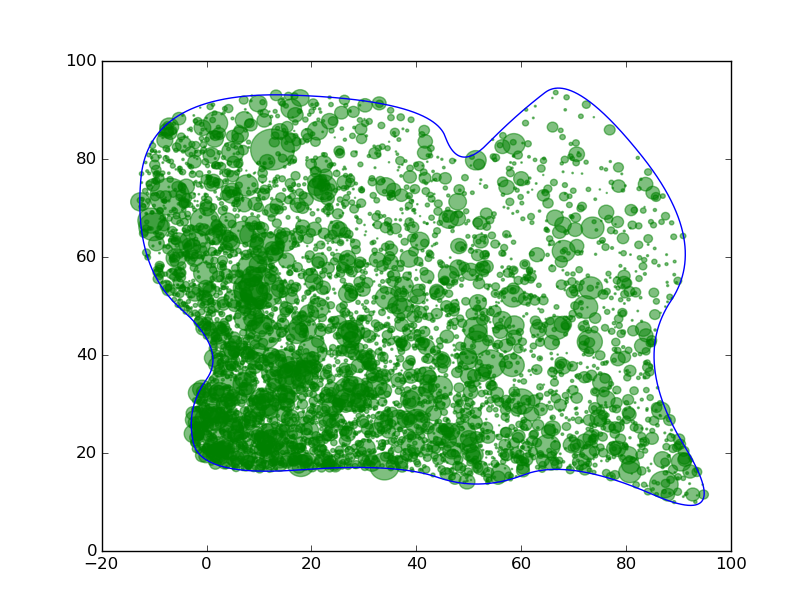
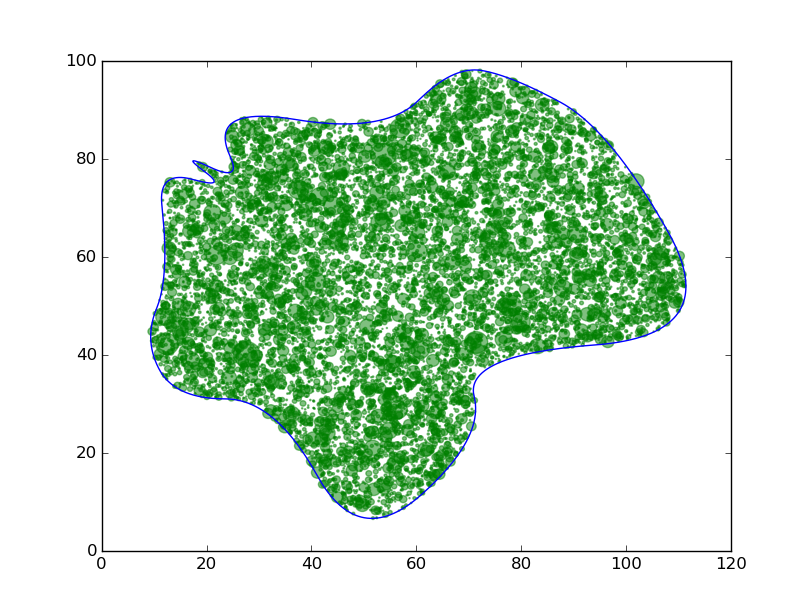
Amélioration à venir :
- Intégrer les statistiques sur les arbres brûlés et non brûlés.
- intégration du vent : le vent déforme les cercles d'influence en ellipses d'influence selon le sens du vent et le rayon initial.
- la zone d'influence est un gradient orienté vers l'extérieur.
- la zone d'influence est probabiliste : en fonction de la distance centre à centre, et des ratios de surfaces on a pas la même probabilité de brûler, à voir.
- une version 'temporelle', où l'on peut voir le résultat au fur et à mesure.
- une version 'physique' où l'on a une diffusion de la chaleur dynamique (c'est facile à faire sur une zone d'influence, par contre aux interfaces et en cas de superposition, ça pue…)



 . Je peux donner des références si vous voulez explorer un peu le sujet.
. Je peux donner des références si vous voulez explorer un peu le sujet.

