
Bonjour à tous.
Le défi de ce mois va s’intéresser à la génération automatique de texte.
La génération de texte un domaine qui peut vite devenir compliqué, c'est la raison pour laquelle se défi va exposer plusieurs sujets et expérimentions à réaliser avec des améliorations possibles. La génération de texte n'est qu'un prétexte pour s'occuper. Si vous utilisez ce défi pour réaliser une super interface graphique avec un nouveau langage ou une nouvelle bibliothèque, c'est un défi réussi même si au final vous n'avez pas spécialement traité de génération de texte. Ce qui compte, c'est comment vous vous appropriez le défi et comment vous exposez vos résultats. Il n'y pas de bonnes réponses ni de mauvaises participations.
Texte, langages et génération automatique
La section ci dessous est petit cours accéléré de linguistique. Il ne se veut être ni exhaustif ni totalement exact, que les éventuels linguistes qui passent par là me pardonnent.
La définition tant attendue :
Un texte est dans une langue donnée une suite de phrases disposant d'un sens global.
Le premier élément important à définir est la langue dans laquelle on va travailler.
Certaines langues sont dites vivantes (Par exemple, le Français, l'Italien, l'Anglais), d'autres sont dites anciennes (on ne les parle plus au jours le jours mais on les comprends, latin et grec ancien sont de bons exemples). Certaines sont qualifiées de mortes si on les comprends même pas (linéaire A, par exemple). Il existe selon les estimations entre 3000 et 6000 langues dans le monde.
Une langue va fixer :
- L'alphabet qu'on va utiliser. L'alphabet est l'ensemble des symboles qu'on va utiliser pour parler et écrire la langue : ce sont les lettres. La plupart des pays occidentaux utilisent l'alphabet Latin mais il en existe beaucoup d'autres, l'alphabet grec (chez nos amis grecs), cyrillique (utilisé en Russie et pays slaves) ou encore arabe.
- Le lexique c'est à dire l'ensemble des mots admissibles pour une langue donnée. Une bonne référence sur le lexique d'une langue est un dictionnaire de la langue incriminée.
A chaque mot est associé :
- Une catégorie : nom, verbe, adverbe, adjectif… Ces catégories servent lorsque la grammaire de la langue rentre en jeu
- Un ou plusieurs sens. Par exemple chat peut être un animal, mais aussi une conversation en ligne.
Enfin, la grammaire est un ensemble de règles qui servent à modifier les mots en fonction du sens qu'on veut donner à la phrase. Une règle de grammaire française est par exemple : Les verbes du 1er groupe se conjuguent en -ent à la 3eme personne du pluriel.
Maintenant que nous avons révisé nos cours de langue, nous pouvons nous pencher sur le sujet en lui même !
Génération automatique de charabia dans une langue donnée
Thématiques abordées : probabilité et génération aléatoire, unicode, GUI
Un point intéressant que la linguistique nous apprend est que la fréquence d’apparition des lettres va varier d'une langue à une autre, et ce même à alphabet constant.
Prenons l'exemple de l'anglais et du français. Les histogrammes d’apparition sont les suivant :
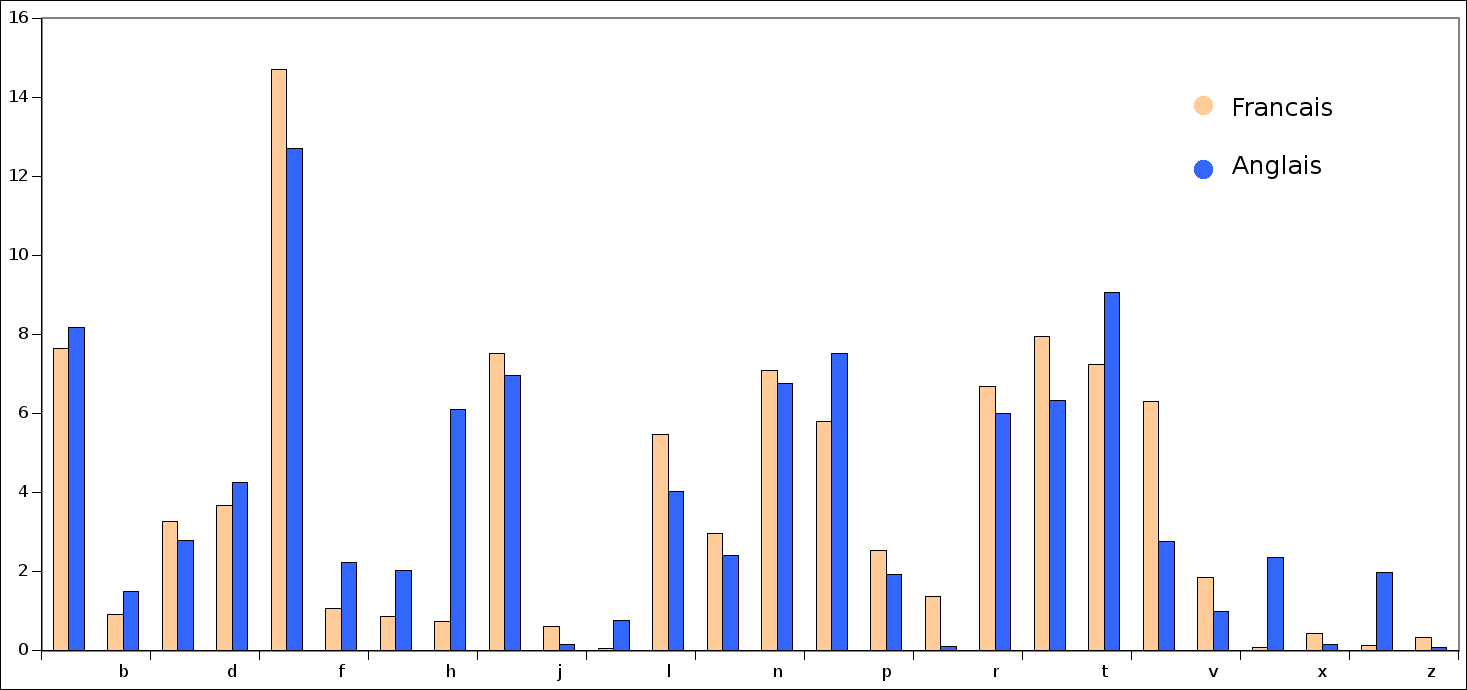
Le but de cette section du défi va être de générer une suite de caractères (autrement dit, du charabia) dans une langue donnée (ie suivant une distribution donnée). Vous trouverez les distributions pour différentes langues dans ce fichier CSV.
La génération demande de supporter des caractères plus variés que ce qu'on peut manipuler au jour le jour. La solution retenue pour gérer ce genre de chose s'appelle Unicode (ou UTF).
Pour réaliser ce petit générateur de charabia, les différentes étapes élémentaires sont :
- Afficher des caractères unicodes dans votre programme
- Lire des caractères unicodes depuis un fichier
- Lire un fichier CSV
- Tirer des nombres aléatoire en fonction d'une distribution donnée
Si vous avez réussi toutes ces étapes, il n'y a plus qu'à assembler ! D'ailleurs, une fois que votre générateur de charabia marche, pourquoi ne pas ajouter un mode quiz afin de deviner de quelle langue il s'agit et système de score persistant pour en faire un mini jeu ?
La distribution des fréquences se trouve ici
Génération de phrases par dictionnaire
Thématique abordée : fichier, génération aléatoire
Génération simple
On vous l'a sûrement dit à l'école, une phrase affirmative c'est sujet + verbe + compléments
Et bien on peut utiliser cette méthode pour générer des phrases. Si vous disposez d'une liste de sujets potentiels, de verbes et de compléments, alors en tirant au sort un de chaque vous pouvez générer une phrase.
Exemple :
| Sujet | Verbe | Complément |
|---|---|---|
| La souris | jouer | Dans la cuisine |
| le chat | courir | sur la table |
| le chien | nager | à minuit |
Vous pouvez générer des phrases comme :
- La souris joue dans la cuisine
- Le chat et le chien nagent à minuit sous la table.
On souhaite que les phrases soient grammaticalement correctes : autrement dit, il faut conjuguer le verbe. Vous pouvez bien sûr augmenter la taille de votre liste de sujet en faisant varier la cardinalité (Le chat, des chats, un chat, trois chats). Il faut bien sur accorder le verbe en conséquence. En rajoutant des conjonctions de coordination (le fameux mais, ou, et, donc, or, ni, car) il est possible de complexifier les phrases assez simplement.
Vous disposez d'une liste de mots courants en Français ici et un rappel des règles de grammaire ici .
Pour la culture, c'est une approche qu'on va qualifier de système expert, car le système qu'on conçoit dispose d'une énorme connaissance lexicale, grammaticale et sémantique.
Génération avancée : prise en compte du sens et ontologie
Cependant, le soucis avec cette méthode, c'est qu'on peut facilement générer des phrases qui n'ont pas de sens. Par exemple : La souris mange le chat.
Pour pallier à ceci, vous pouvez mettre en place système ontologie. Par exemple, on peut définir une relation $<$ pour manger et dire que pour manger : $souris<chat$ , $viande<chien$ , $croquette<chat$ afin de signifier que le chat mange la souris, le chien mange de la viande… Grâce à ce système, il est possible de définir des contraintes sur les éléments tirés au sort et ainsi de donner du sens aux phrases.
L'ontologie peut être décrite avec des langages comme le Web Ontology Language. Protégé est un logiciel Open source d'édition d'ontologie. Afin de ne pas décrire tout ce qui est possible et imaginable, il est possible de générer de l'information et des faits avec ce qu'on appelle des moteurs d'inférence
Génération de phrases par chaîne de Markov
Thématique abordée : chaînes de Markov
Les chaînes de Markov sont un outil mathématique assez avancé, je ne ferai qu'une description superficielle de ces dernières.
L'idée principale derrière est de générer aléatoirement quelque chose de sorte que la probabilité de génération d'un élément ne dépende que du dernier élément généré. Par exemple, avec la chaîne de Markov suivante,
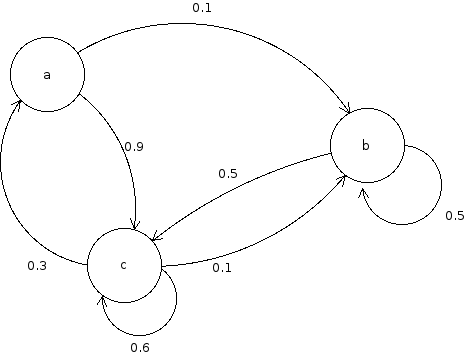
Si la lettre courante est 'a', la prochaine lettre peut être 'b' avec une probabilité de 0.1 (ce qu'on note $P(b|a)=0.1$, on parle de probabiliaaté conditionnelle) ou 'c' avec une probabilité de 0.9 ($P(c|a)=0.9$). Du point de vu mathématique, il est important que la somme des probabilités sortant d'un état (ici une lettre), soit égale à 1.
Pour appliquer ce concept à la génération de texte, on va remplacer nos simples lettres par des mots entiers.
le système doit d'abord passer par une phase d’apprentissage où on lui fournit des textes existants. De ces textes, le système va générer les chaînes de Markov correspondantes en reliant un mot au mot qui le suit. Par exemple si on lui donne les phrases
- Le chat mange la souris
- La souris mange le fromage
On va avoir :
De là, en se donnant juste un premier mot, il est possible de générer une phrase de façon aléatoire. Ce générateur n'a aucune connaissance de grammaire ni de syntaxe, dès lors la qualité de génération sera grandement influencée par la quantité et la diversité des textes que le système aura eu en phase d'apprentissage. Si vous intégrez la ponctuation comme élément de base dans les chaînes, il est possible de générer des textes entiers.
Conclusion
Voilà c'est à vous pour ce défi, on vous attends nombreux. Si vous des questions ou besoin d'aide, n'hésitez pas à demander !




 . Il y a un subreddit assez marrant qui n'est peuplé que de bots générant des posts à partir de chaines de Markov :
. Il y a un subreddit assez marrant qui n'est peuplé que de bots générant des posts à partir de chaines de Markov : 



 ), mais j'ai trouvé un soucis de texte, dans la ligne juste après le titre "Génération avancée : prise en compte du sens et ontologie" : "c'est qu'on facilement avoir facilement générer" -> "c'est qu'on peut facilement générer", ou "c'est qu'on peut facilement avoir généré"?
), mais j'ai trouvé un soucis de texte, dans la ligne juste après le titre "Génération avancée : prise en compte du sens et ontologie" : "c'est qu'on facilement avoir facilement générer" -> "c'est qu'on peut facilement générer", ou "c'est qu'on peut facilement avoir généré"?



