
Bonjour,
Si vous lisez ce message c'est que Zeste de Savoir fonctionne, ouf ! Comme vous avez pu le constater ces dernières heures et plus généralement ces dernières semaines, le site subit régulièrement des coupures et vous avez le droit à des erreurs 500. Aujourd'hui fut la pire journée avec une coupure d'environ une demi-heure vers 12h40 et une coupure d'une heure trente vers 15h30 (contre 5 à 10 minutes habituellement).
Toute l'équipe de Zeste de Savoir tient à s'excuser pour ces coupures et fait le nécessaire pour que cela n'arrive plus.
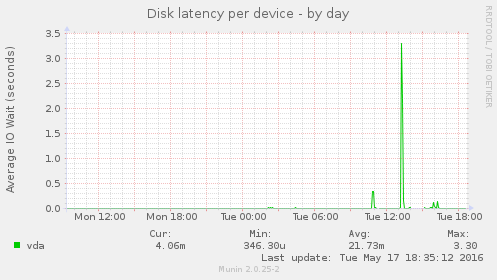
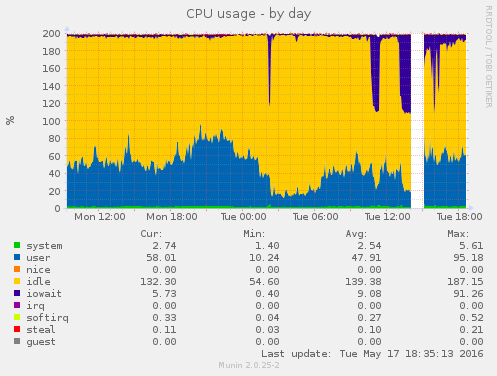
Quelques explications s'imposent : pour une raison inconnue, il arrive que le disque du serveur devienne inaccessible pendant plus de 120s ce qui fait planter MySQL et par la même occasion l'instance du site puis tout le serveur. Après diverses investigations qui sont encore en cours il semblerait que cela vienne de notre fournisseur de VPS, OVH, car nous ne sommes pas les seuls à avoir ces erreurs. Nous sommes en train de voir avec eux ce qui ne va pas.
De plus, nous faisons des tests sur chez Gandi qui accepte de nous aider en nous offrant des services pour voir si la solution qu'ils proposent convient à Zeste de Savoir.
Nous vous tiendrons au courant lorsque nous auront plus d'informations,
L'équipe technique de Zeste de Savoir
–
EDIT (17 mai) : un ticket est ouvert chez OVH, nous attendons une réponse.
EDIT (18 mai) : une réponse est arrivée, cf ce message. On attend de voir si ça résous vraiment le problème.













 Merci à toi l'oiseau !
Merci à toi l'oiseau !

