Asvin, j'ai évidemment regardé les paris des autres après les miens, pour comparer.
Il suffit de voir, si le sujet prend l'ampleur ou non, suivant le nombre de participants.
D'ailleurs il y a bientôt le tirage au sort pour la ligue des champions… Le PSG va t'il réussir sa saison .. alors qu'il leur manque Thiago silva et ibra ?
monaco est il dans les choux?
moi je reste surpris de voir Bordeaux être en tête de ce championnat, mais tant mieux ça met un peu de suspens
D'ailleurs il y a bientôt le tirage au sort pour la ligue des champions… Le PSG va t'il réussir sa saison .. alors qu'il leur manque Thiago silva et ibra ?
monaco est il dans les choux?
moi je reste surpris de voir Bordeaux être en tête de ce championnat, mais tant mieux ça met un peu de suspens
Tirage au sort de la LDC : Le PSG s'en sort plutôt bien, je pense que le barça est prenable, encore plus sachant que Suarez sera pas là pour leur aller. Monaco ne pouvait pas vraiment espérer mieux, mais vu leurs prestations en L1, va falloir qu'ils relèvent un peu -beaucoup- le niveau quand même.
Bordeaux en tête, pour mon plus grand plaisir, ça ne durera pas. Mais Bordeaux affiche de belles promesses dans le jeu par rapport à l'année dernière grâce à Sagnol (coucou Gillot@Jefaisaveccequej'aivosgueules). Donc on verra bien.
Concernant le groupe C j'ai peur pour Monaco… Clairement ils n'ont pas actuellement le niveau
pour le groupe du PSG je ne suis pas spécialement inquiet ils peuvent passer mais attention, j'ai l'impression que cette année ils n'ont pas la même patate et il manque du monde pour l'instant… à voir après les retours de thiago et ibra
Désolé pour mon retard ! J'ai eu une fin de semaine chargée.
Mes pronos
C'est la première fois que je participe (oui/non) : non
match
pseudo
prono
30082014-ligue1-monaco-lille
adndebanane
N
30082014-ligue1-caen-rennes
adndebanane
1
30082014-ligue1-lens-reims
adndebanane
N
30082014-ligue1-lorient-guingamp
adndebanane
1
30082014-ligue1-nantes-montpellier
adndebanane
N
30082014-ligue1-toulouse-evian
adndebanane
1
31082014-ligue1-bordeaux-bastia
adndebanane
1
24082014-ligue1-metz-lyon
adndebanane
N
24082014-ligue1-paris-stetienne
adndebanane
N
Notre joueur virtuel
match
pseudo
prono
29082014-ligue1-marseille-nice
hasard
1
30082014-ligue1-monaco-lille
hasard
1
30082014-ligue1-caen-rennes
hasard
2
30082014-ligue1-lens-reims
hasard
2
30082014-ligue1-lorient-guingamp
hasard
1
30082014-ligue1-nantes-montpellier
hasard
N
30082014-ligue1-toulouse-evian
hasard
N
31082014-ligue1-bordeaux-bastia
hasard
2
24082014-ligue1-metz-lyon
hasard
1
24082014-ligue1-paris-stetienne
hasard
2
Les super-pronos de Clem
matchs
super-pronos
29082014-ligue1-marseille-nice
1
30082014-ligue1-monaco-lille
1
30082014-ligue1-caen-rennes
2
30082014-ligue1-lens-reims
2
30082014-ligue1-lorient-guingamp
1
30082014-ligue1-nantes-montpellier
N
30082014-ligue1-toulouse-evian
N
31082014-ligue1-bordeaux-bastia
2
24082014-ligue1-metz-lyon
1
24082014-ligue1-paris-stetienne
2
Rappel : les pronostics des membres participant pour la première fois à l'atelier ne sont pas pris en compte dans la prise de décision de Clem - cf. Notes
Vous retrouverez toutes les statistiques des matchs de cette quatrième journée sur le site de la ligue et tous les buts sur cette vidéo.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Vendredi 29 août 2014
20:30 Olympique de Marseille 4 - 0 OGC Nice
Samedi 30 août 2014
17:00 AS Monaco 1 - 1 LOSC Lille
20:00 SM Caen 0 - 1 Stade Rennais FC
20:00 RC Lens 4 - 2 Stade de Reims
20:00 FC Lorient 4 - 0 EA Guingamp
20:00 FC Nantes 1 - 0 Montpellier Hérault SC
20:00 Toulouse FC 1 - 0 Evian TG FC
Dimanche 31 août 2014
14:00 Girondins de Bordeaux 1 - 1 SC Bastia
17:00 FC Metz 2 - 1 Olympique Lyonnais
21:00 Paris Saint-Germain 5 - 0 AS Saint-Etienne
Qu'avez-vous pensé de cette journée ? Un but, une action en particulier ? On aura en tout cas remarqué la moyenne de 2.9 buts par match, ce qui est plutôt pas mal !
Classement des participants à l'atelier
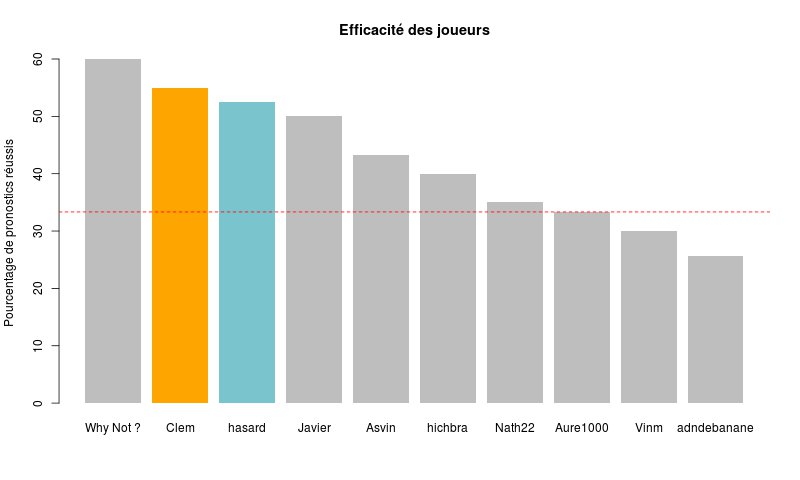
Classement par pourcentage de bons pronostics réalisés depuis la première participation.
Classement par pourcentage de bons pronostics après 4 journées de championnat
Le trio de tête (Why Not ?, Clem et le hasard) se maintient. Bien joué Why Not ?, tu maintiens ton ratio de bons pronos à 60 % !
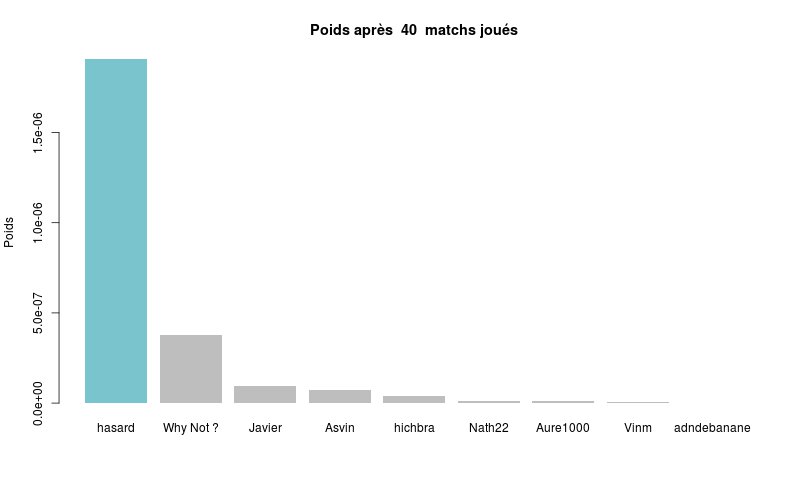
La figure suivante présente les poids de chaque joueur, qui entreront en compte dans l'algorithme qui calculera les pronostics de Clem pour la prochaine journée de championnat.
Classement par poids après 4 journées de championnat
Le tableau suivant résume les poids (weights), le nombre de matchs pronostiqués (nb_match_played) et le nombre de pronostics réussis (en %) (efficiency) par joueur (expert).
Pour participer, il vous suffit de copier/coller le code markdown suivant, d'indiquer si c'est la première fois que vous participez à l'atelier puis de remplacer pseudo par votre pseudo et N par votre pronostic.
Vous pouvez poster vos pronostics jusqu'à vendredi 12 septembre, 12h (il y a une trêve internationale d'ici là).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
C'est la première fois que je participe (oui/non) :
match | pseudo | prono
------|--------|------
12092014-ligue1-lyon-monaco | pseudo | N
13092014-ligue1-rennes-paris | pseudo | N
13092014-ligue1-bastia-lens | pseudo | N
13092014-ligue1-montpellier-lorient | pseudo | N
13092014-ligue1-nice-metz | pseudo | N
13092014-ligue1-reims-toulouse | pseudo | N
13092014-ligue1-stetienne-caen | pseudo | N
14092014-ligue1-lille-nantes | pseudo | N
14092014-ligue1-guingamp-bordeaux | pseudo | N
24082014-ligue1-evian-marseille | pseudo | N
Si je ne m'abuse, hasard a aujourd'hui un poids largement supérieur à la somme de tous les autres participants, et donc les paris de clem seront exactement les mêmes que les paris de hasard.
Pour moi, le coefficient de 1/2 pour une erreur sur un match est excessif.
Au bout de 100 pronostics, un joueur qui a 45 bons résultat doit-il peser 2 fois plus qu'un joueur qui a 44 bons résultats ?
D'ailleurs, tout système basé sur des poids 'exponentiels' aboutit au bug que je dénonce.
Pour s'en rendre compte, il suffit de faire quelques simulations après 10 ou 12 journées de championnat.
Pour moi, le bon poids à accorder à chaque joueur, c'est tout simplement son pourcentage de réussite.
WhyNot a fait le bon pronostic sur 60% des matches qu'il a pronostiqué, il a un poids de 0.60, Javier a un poids de 0.5 , et hasard un poids de 0.525.
Et un joueur qui n'a jamais joué a un poids de 33%.
Après, on peut peaufiner, surtout sur les matches de ligue 1.
WhyNot suit visiblement l'équipe de Bordeaux, on peut imaginer qu'il connaît bien cette équipe et qu'il sait quels joueurs sont en forme, quels joueurs sont blessés.
Si WhyNot a eu jusqu'à aujourd'hui 100% de réussite sur les matches de Bordeaux, et 50% de réussite sur les matches de Guingamp, alors son pronostic pour le match Bordeaux-Guingamp aura un coefficient de (1+0.5)/2 = 0.75.
Même avec seulement 9 pronostiqueurs, et 5 journées de championnat comme aujourd'hui, cela devrait améliorer sensiblement le résultat.
Mais ça demande une adaptation importante de la base de données !
Je pense que ton idée – utiliser le pourcentage de réussite pour faire les super-prédictions – peut fonctionner. Mais je ne suis pas convaincu qu'elle fonctionnerait mieux que le système actuel (mais peut-être as-tu de meilleurs arguments dans ta besace ?).
Il me semble qu'il est normal que, pour le moment, Clem prenne ses décisions selon l'avis du joueur virtuel hasard. Celui-ci a réalisé de très bon pronostics tout au long des 4 premières journées. Par ailleurs, Why Not ? qui est devant au classement par pourcentage de réussite a certes réalisé de bon pronos mais seulement sur 2 journées - ce qui rend sa performance moins impressionnante que celle de hasard. Je ne vois donc pas de problème ici.
La diminution du poids par deux à chaque mauvais pronostic ne m'apparait pas problématique, au contraire. Celle-ci permet de rendre le système dynamique : tu peux par exemple voir que l'influence de Why Not ? entre les journées 3 et 4 augmente significativement. Si hasard continue de faire de mauvaises performances, son poids va très rapidement baisser, alors que son classement en pourcentage de bon pronos va tendre vers 33%.
Un dernier point qui découle du précédent est la différence d'ordre de grandeur entre les joueurs. Dans ton exemple (joueur avec 44% de bons pronos VS joueur avec 45%), tu ne prends que deux joueurs, ce qui perturbe le raisonnement. Si j'ajoute quatre très mauvais parieurs (e.g. efficacité de 10%) au pool de parieurs, tu vois que les pronostics de ces mauvais parieurs, s'ils sont identiques entre eux, ont la même importance que les pronostics de tes bons parieurs - ce qui est gênant. Alors qu'en considérant leurs poids, leur importance sera négligeable (regarde par exemple mon influence, par rapport à celle de hasard et Why Not ? : il faut environ 300 pronos identiques de mauvais pronostiqueurs comme moi pour avoir une influence du même ordre de grandeur que celle de Why Not ?), tout en restant très dynamique (je suis sûr de pouvoir dépasser Javier !).
Toutefois, il y a des pistes pour améliorer l'algorithme, en le compliquant très sensiblement. Clem pourrait par exemple faire ses pronos au hasard selon une distribution qui suivrait les poids, plutôt que de simplement faire la somme de ces poids. Cet algorithme est d'ailleurs implémenté et ses résultats sont visibles sur le premier message du sujet (il faut dérouler la liste des super-pronos de Clem et regarder les super-pronos sous le label "random") - j'avais choisi de rester sur la version simple, qui n'implique pas de notions mathématiques/statistiques compliquées.
N'hésite pas à me donner tort et – surtout – à participer à l'atelier
Fais quelques simulations avec une douzaine de participants (fidèles ou occasionnels). Tu verras que sauf très rares exceptions, l'algo actuel consiste à prendre purement et simplement les choix du joueur le mieux classé. Même si sur un match donné, il y a consensus contre lui.
Prends un exemple tout simple, par exemple au bout de 10 journées. Tous les joueurs ont fait 100 pronostics.
Ils ont respectivement 50 49 48 47 46 45 bons pronostics.
On ne peut pas vraiment dire qu'il y a un joueur qui se détache du lot.
Et pourtant, l'algo actuel sélectionnera sur tous les matches les pronostics du joueur '50'. Même s'il y a consensus contre lui sur certains matches.
Ceci étant, je suis ok pour convenir que ma proposition lisse trop, et donne des poids trop similaires à tous les joueurs.
On peut considérer que les joueurs qui ont moins de 33% de bons pronostics sont effectivement des 'boulets', et donc, il faut diminuer sensiblement leur poids.
Un aménagement possible, c'est de prendre pour chaque joueur un coefficient égal à "Pourcentage de bonne réponse" - 30% par exemple.
Du coup, tous les joueurs qui ont une note en dessous de 30% ne sont pas pris en compte.
Et pour les autres joueurs :
WhyNot : Score 60% –> coeff = 0.30
Javier : Score 50% –> coeff = 0.20
hasard : Score 52% –> coeff = 0.22
Joueur Nouveau : Estimation 33% –> coeff = 0.03
Ainsi, si sur un match donné, Whynot pronostique Victoire à domicile, alors que Javier et hasard pronostiquent Nul, et les autres joueurs se répartissent sur les 3 résultats possibles, Clem choisira Nul, plutôt que le choix du joueur le mieux classé.
Javier est moins performant que Whynot, Hasard est moins performant que Whynot. Mais si Javier et Hasard dont d'accords contre Whynot, alors on suit le choix de Javier + Hasard.
Bonjour à tous ! Je profite de cet atelier pour aborder un sujet qui, il y a de cela quelques années, m'intriguait beaucoup : comment peut-on générer des nombres aléatoires – et donc du hasard – avec un ordinateur ? Certains d'entre vous, à la lecture de ce sujet, se sont peut-être par exemple demandés comment je faisais pour simuler les pronostics de mon joueur virtuel hasard. Une façon rapide et peu éclairante serait de répondre que j'exécute la commande R sample(c("1","N","2"),size=10,replace=TRUE,prob=c(1/3,1/3,1/3)). Mais vous ne seriez pas beaucoup plus avancés n'est-ce pas ?
Note à ceux qui savent : pour faire les choses bien en parlant de ces notions, il faudrait introduire des notions de statistiques pas évidentes à comprendre rapidement, comme les notions de distributions, de variables aléatoires, de variables indépendantes et identiquement distribuées, etc. Cela nécessiterait d'écrire un article dédié - ça dépasse un peu mes intentions ici.
Une façon de simuler les pronostics serait de tirer un nombre aléatoire $u$ compris entre 0 et 1 et de définir 3 zones : si $u < 1/3$, le joueur virtuel parie 1. Si $1/3 \leq u < 2/3$, le joueur virtuel parie N. Enfin, si $u \geq 2/3$, le joueur virtuel parie 2. En répétant l'expérience 10 fois, on obtiendrait une suite de 10 pronostics !
Le problème est qu'il est difficile de générer des nombres $u$ réellement aléatoires. Cela demande de mesurer des phénomènes physiques qui semblent imprédictibles puis de les convertir en une suite de nombre (wikipédia (en)).
Ces méthodes sont surtout utilisées en cryptographie pour générer des clefs aléatoires, car elles ne remplissent pas nos besoins quotidiens de programmeurs :
elles demandent des moyens plutôt important (appareils de mesures, interfaces,…) et du temps ;
elles ne permettent pas à l'exécution d'un programme d'être reproductible - ce qui est souvent très important.
Par exemple, en sciences, on va vouloir reproduire les simulations réalisées par une autre équipe pour vérifier ses propos et ses conclusions. Mais cela est impossible si ces simulations sont basées sur des nombres générés aléatoirement : on ne pourra pas répéter exactement les mêmes simulations.
Ce dernier point vous semble peut-être étonnant : nous avons besoin de nombres aléatoires mais en même temps ceux-là deviennent problématiques dans notre méthodologie scientifique. Comment faire ? Nous allons utiliser des nombres pseudo-aléatoires, c'est à dire des nombres obtenus grâce à des opérations mathématiques déterministes (une fois que l'on a la formule, c'est toujours la même liste de nombre qui sort) mais qui semblent générés aléatoirement. Plusieurs algorithmes existent pour réaliser ce petit tour de passe-passe.
Intéressons-nous à un algorithme simple à comprendre : le générateur congruentiel linéaire.
Un générateur congruentiel linéaire est définit par la relation de récurrence suivante, :
$$X_{n+1} = (a X_n + b) \mod m$$
avec $a$ le multiplicateur, $b$ l'incrément et $m$ le module. L'opération $\mod$ permet d'obtenir le reste de la division euclidienne $a X_n + c$ par $m$. La transformation $\hat{X_n} = \frac{X_n}{m} \mod 1$ permet d'obtenir un générateur de nombres pseudo-aléatoires compris entre 0 et 1.
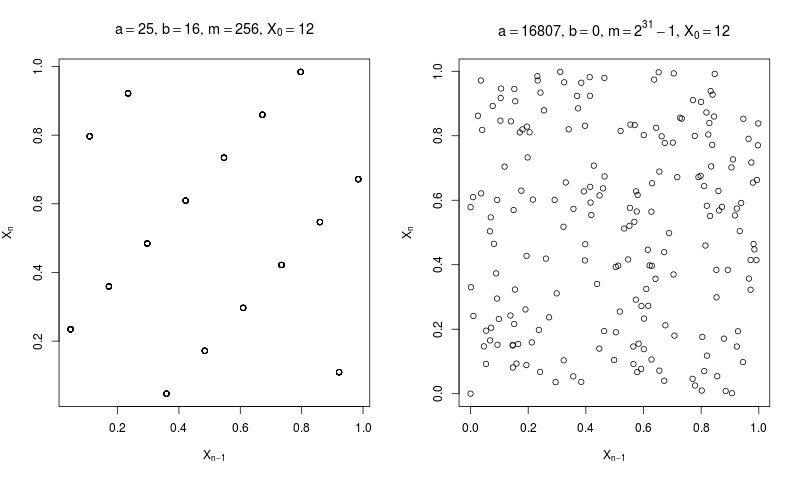
Pour un ensemble donné de paramètres $(a,b,m)$ et un terme initial $X_0$ (la graine, seed en anglais) donnera ainsi toujours la même suite de nombre – ce qui permettra, si besoin, de rendre un code reproductible : il suffira d'indiquer la graine utilisée. Le choix des valeurs des paramètres $(a,b,m)$ est central. Essayons d'illustrer le problème.
J'ai utilisé ici deux jeux de paramètres $(a,b,m)$ différents pour générer 200 nombres. Sur la figure de droite, tout semble bien se passer, on obtient 200 nombres différents et il n'y, du moins pas à l'oeil nu, pas de motif évident – les nombres semblent occuper la figure aléatoirement. Sur la figure de gauche, en revanche, on ne voit que 16 points ! Et pour cause : avec le jeu de paramètres donné, le générateur ne produit une suite que de 16 nombres différents (et encore, essayez avec la graine $X_0 = 10$ :p) ! Il est évident que ce jeu ne permet pas de générer des nombres pseudo-aléatoires alors que celui de la figure de droite semble le pouvoir. Vous pouvez trouver d'autres exemples qui fonctionnent bien sur wikipédia.
On a maintenant de quoi générer des nombres entre 0 et 1 et j'ai expliqué précédemment comment passer de ces nombres à des pronostics 1/N/2 : un mystère de résolu ! De la même manière, vous pourrez maintenant simuler les résultats d'un dé, même pipé
On peut considérer que les joueurs qui ont moins de 33% de bons pronostics sont effectivement des 'boulets'
Je ne suis encore pas convaincu par ton exemple, parce qu'il ne met en jeu que 6 joueurs aux pourcentages de réussite très proches – ce qui biaise la démonstration. Si tu prends 100 joueurs, répartis en plusieurs classes d'efficacité, observes-tu la même chose ? Sachant qu'il y aura sans doute plus de joueurs moyens que de joueurs excellents, es-tu certain qu'un consensus de moyens ne peut dépasser la valeur du poids de meilleur joueur ? J'en doute.
A tout le monde : plus que 48h pour poster vos pronostics de la prochaine journée ! Bonne chance
Simplifions le raisonnement en prenant des joueurs qui ont tous participé autant de fois.
On a donc par exemple un joueur excellent qui a 60% de bons pronostics et des joueurs moyens qui ont 50% de bons pronostics.
Au bout de 10 journées, il y a donc 10 bonnes réponses d'écart entre le joueur excellent et les joueurs moyens.
2^10 = 1024. Il faut donc 1024 joueurs moyens pour peser autant que le joueur excellent.
Au bout de 20 journées, c'est pire.
Le joueur excellent a toujours 60% de bonnes réponses, soit 120 bonnes réponses.
Les joueurs moyens ont toujours 50% de bonnes réponses, soit 100 bonnes réponses.
20 bonnes réponses d'écart ; 2^20 = 1 million …
Il faut donc un million de joueurs moyens ( tous d'accord entre eux) pour peser autant que le joueur excellent.
Les pourcentages de bons pronostics de chaque joueur ne changent pas, mais le poids relatif de chaque joueur change.
Tes calculs sont justes et c'est vrai qu'ils plaident en faveur d'un autre algorithme. Je vais implémenter ta proposition dans les semaines qui viennent, on peut aussi en imaginer une version stochastique, ce qui nous donnerait 4 algorithmes donnant les pronos de Clem. On peut ensuite imaginer donner à chaque journée les super-pronos de l'algorithme ayant la meilleure performance depuis le début du championnat. Intuitivement, je dirai que l'algorithme actuellement implémenté est très efficace en présence d'un "leader", d'un pronostiqueur avec de très bons résultats, l'autre plus efficace en présence de joueurs moyens uniquement. Clem peut ainsi adapter la façon de prendre une décision en fonction des forces en présence.
Je trouve intéressant de laisser l'algorithme actuel en route parce qu'il est très simple à comprendre et qu'il permet d'entrer doucement dans l'apprentissage automatique séquentiel.
J'arrête les pronostics de la 5ème journée, qui commence ce soir, d'ici deux heures – retardataires, manifestez-vous !
C'est la première fois que je participe (oui/non) : non
match
pseudo
prono
12092014-ligue1-lyon-monaco
adndebanane
2
13092014-ligue1-rennes-paris
adndebanane
2
13092014-ligue1-bastia-lens
adndebanane
1
13092014-ligue1-montpellier-lorient
adndebanane
N
13092014-ligue1-nice-metz
adndebanane
2
13092014-ligue1-reims-toulouse
adndebanane
2
13092014-ligue1-stetienne-caen
adndebanane
1
14092014-ligue1-lille-nantes
adndebanane
N
14092014-ligue1-guingamp-bordeaux
adndebanane
2
24082014-ligue1-evian-marseille
adndebanane
2
match
pseudo
prono
12092014-ligue1-lyon-monaco
hasard
N
13092014-ligue1-rennes-paris
hasard
1
13092014-ligue1-bastia-lens
hasard
N
13092014-ligue1-montpellier-lorient
hasard
1
13092014-ligue1-nice-metz
hasard
2
13092014-ligue1-reims-toulouse
hasard
1
13092014-ligue1-stetienne-caen
hasard
2
14092014-ligue1-lille-nantes
hasard
1
14092014-ligue1-guingamp-bordeaux
hasard
N
24082014-ligue1-evian-marseille
hasard
2
Les super-pronos de Clem
matchs
super-pronos
12092014-ligue1-lyon-monaco
N
13092014-ligue1-rennes-paris
1
13092014-ligue1-bastia-lens
N
13092014-ligue1-montpellier-lorient
1
13092014-ligue1-nice-metz
2
13092014-ligue1-reims-toulouse
1
13092014-ligue1-stetienne-caen
2
14092014-ligue1-lille-nantes
1
14092014-ligue1-guingamp-bordeaux
N
24082014-ligue1-evian-marseille
2
Rappel : les pronostics des membres participant pour la première fois à l'atelier ne sont pas pris en compte dans la prise de décision de Clem - cf. Notes
Rhaaaa!! Je suis en retard je sais, je me suis dis que j'avais le temps avec la trève internationale, mais en fait, avec la reprise des cours, j'ai pas pu trop me pencher sur les réponses. D'ailleurs, l'aspect mathématique m'intéresse, mais définitivement pas le temps de m'y pencher.
C'est la première fois que je participe (oui/non) : non
Connectez-vous pour pouvoir poster un message.
Connexion
Pas encore membre ?
Créez un compte en une minute pour profiter pleinement de toutes les fonctionnalités de Zeste de Savoir. Ici, tout est gratuit et sans publicité.
Créer un compte