Cette partie va présenter un aspect crucial de la programmation d’une application web : l’accès aux données. Comme vous avez fait un peu de C#, vous avez peut être l’habitude d’utiliser une base de données et d’effectuer des requêtes SQL via des méthodes fournies par le framework .NET. Un ORM va nous permettre d’accéder à une source de données sans que nous ayons la sensation de travailler avec une base de données.
Cela paraît étrange, mais signifie simplement que grâce à cet ORM, nous n’allons plus écrire de requêtes, ni créer de tables, etc., via un système de gestion de base de données mais directement manipuler les données dans notre code C#. Un ORM très populaire avec C# est Entity Framework.
- ORM ? Qu'est-ce que c'est ?
- Les différentes approches pour créer une base de données
- Présentation d'Entity Framework
ORM ? Qu'est-ce que c'est ?
Principe d’un ORM
Comme dit en introduction, ORM signifie que l’on va traduire de l’Objet en Relationnel et du Relationnel en Objet.
Mais dans cette histoire, c’est quoi "objet" et "relationnel" ?
Le plus simple à comprendre, c’est "l’objet". Il s’agit ici simplement des classes que manipule votre programme. Ni plus, ni moins.
Par exemple, dans notre blog nous avons des articles, pour lesquels nous avons créé une classe Article, qui décrit ce qu’est un article du point de vue de notre programme. Chouette, non ?
Maintenant, le gros morceau : le "Relationnel".
Nous ne parlons pas ici des relations humaines, ni même des relations mathématiques mais de la représentation relationnelle des données.
Ce terme vient de l’histoire même des bases de données1. Ces dernières ont été créées pour répondre à des principes complexes3 et une logique ensembliste.
De ce fait, les créateurs des bases de données, notamment M.Bachman vont créer une architecture qui va représenter les données en créant des relations entre elles.
Plus précisément, les données vont être normalisées sous forme d’entités qui auront entre elles trois types d’interactions : One-To-One, One-To-Many, Many-To-Many.
Nous verrons la traduction de ces termes au cours de nos cas d’étude.
Plus tard, avec l’arrivée de la programmation orientée objet, les chercheurs dans le domaine des bases de données, vont tenter de modéliser d’une manière compatible avec UML le fonctionnement des bases.
Grâce à ces travaux les programmes ont pu traduire de manière plus immédiate les "tables de données" que l’on trouve dans les bases de données relationnelles en instances d’objets.
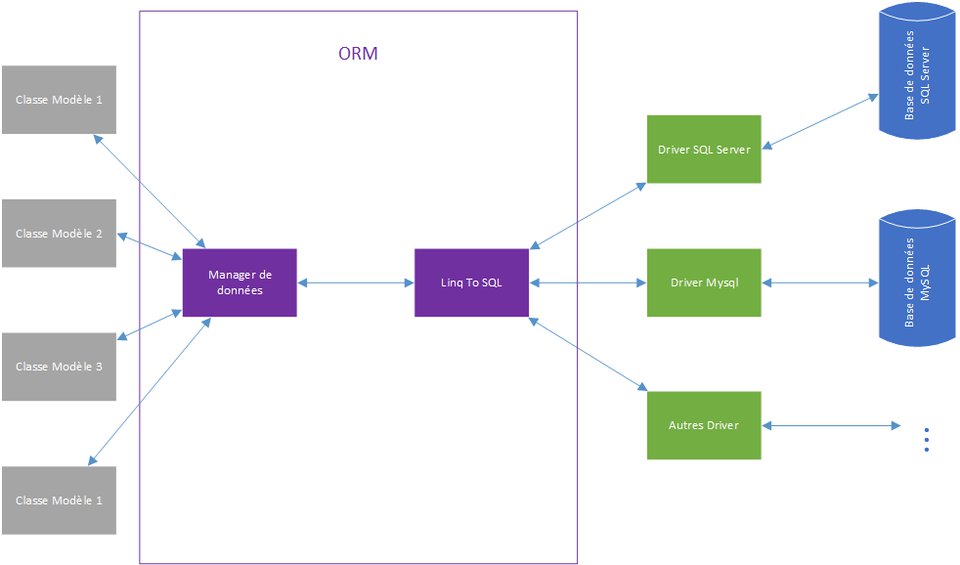
Dans le cadre de .NET l’ORM est souvent constitué d’une API qui se découpe en deux parties : un gestionnaire d’objet/données et un "traducteur" qui se sert de Linq To SQL.
Grâce à cette organisation, l’ORM n’a plus qu’à se brancher aux connecteurs qui savent converser avec le système choisi (MSSQL, MySQL, Oracle, PostgreSQL…).
Des alternatives à Entity Framework ?
Comme vous l’aurez compris, nous allons choisir Entity Framework en tant qu’ORM pour plusieurs raisons :
- c’est le produit mis en avant par Microsoft, il est régulièrement mis à jour (actuellement : version 6) ;
- il est bien documenté ;
- il est parfaitement intégré au reste du framework .NET (validation, exceptions, Linq…) ;
- il se base sur l’API standard ADO.NET ;
- il est complet tout en restant suffisamment simple d’utilisation pour le présenter à des débutants.
Comme nous avons pu nous en rendre compte dans les parties précédentes, ASP.NET ne nécessite pas un ORM. C’est juste un outil qui vous facilitera le travail et surtout qui vous assurera une véritable indépendance d’avec le système de gestion de bases de données que vous utilisez.
Le monde du .NET est néanmoins connu pour fournir un nombre important d’alternatives au cours du développement.
Une petite exploration des dépôts NuGet2 vous permettra de vous en rendre compte.
Il existe en gros deux types d’ORM :
- les ORM complets, qui accèdent vraiment au meilleur des deux mondes objet et relationnel. Entity Framework en fait partie ;
- les ORM légers, qui sont là pour vous faciliter uniquement les opérations basiques, dites CRUD.
Un ORM complet : NHibernate
NHibernate est un ORM qui se veut être le concurrent direct de Entity Framework.
Son nom est un mot valise rassemblant ".NET" et "Hibernate". Il signifie que NHibernate est le portage en .NET de l’ORM Hibernate, bien connu des développeurs Java et Java EE.
De la même manière que Entity Framework, NHibernate se base sur ADO.NET. Par contre, il reprend un certain nombre de conventions issues du monde Java comme l’obligation de posséder un constructeur par défaut.
Un ORM léger : PetaPOCO
PetaPOCO est un ORM qui s’est construit par la volonté grandissante des développeurs à utiliser des POCO.
POCO, c’est un acronyme anglais pour Plain Old CLR/C# Object, autrement dit, un objet qui ne dépend d’aucun module externe. En Java, vous retrouvez également le concept de POJO, pour Plain Old Java Object.
Le problème posé par les ORM tels que NHibernate et EntityFramework, c’est que rapidement vos classes de modèles vont s’enrichir d’annotations, d’attributs ou de méthodes qui sont directement liés à ces ORM.
Or, en informatique, on n’aime pas que les classes soient fortement couplées, car cela complique beaucoup la maintenance et l’évolutivité du code. On essaie donc au maximum de respecter le principe de responsabilité unique (SRP).
Nous verrons plus tard que dès que l’accès à la base de données est nécessaire, nous préférons utiliser le patron de conception Repository.
L’utilisation d’un ORM complet peut rapidement mener à des repository assez lourds à coder et à organiser.
PetaPOCO vous permet donc d’utiliser vos classes de modèle tout simplement. Par contre certaines fonctionnalités ne sont pas implémentées.
Les différentes approches pour créer une base de données
Nous désirons créer un site web. Ce site web va devoir stocker des données. Ces données ont des relations entre elles…
Bref, nous allons passer par une base de données. Pour simplifier les différentes questions techniques, nous avons fait un choix pour vous : nous utiliserons une base de données relationnelle, qui se base donc sur le SQL.
Maintenant que ce choix est fait, il va falloir s’atteler à la création de notre base de données et à la mise en place de notre ORM. Comme ce tutoriel utilise Entity Framework, nous utiliserons les outils que Microsoft met à notre disposition pour gérer notre base de données avec cet ORM précis.
Avant toute chose, je voulais vous avertir : une base de données, quelle que soit l’approche utilisée, ça se réfléchit au calme. C’est souvent elle qui déterminera les performances de votre application, la créer à la va-vite peut même tuer un petit site.
Maintenant, entrons dans le vif du sujet et détaillons les trois approches pour la création d’une base de données.
L’approche Model First
L’approche Model First est une approche qui est issue des méthodes de conception classique. Vous l’utiliserez le plus souvent lorsque quelqu’un qui a des connaissances en base de données, notamment la méthode MERISE1.
Cette approche se base sur l’existence de diagramme de base de données parfois appelés Modèle Logique de Données. Ces diagrammes présentent les entités comme des classes possédant des attributs et notamment une clef primaire et les relient avec de simples traits.
Pour en savoir plus sur cette approche, je vous propose de suivre cette petite vidéo :
L’approche Database First
Comme son nom l’indique, cette méthode implique que vous créiez votre base de données de A à Z en SQL puis que vous l’importiez dans votre code. C’est une nouvelle fois le Modèle Logique de Données qui fera le lien entre la base de données et l’ORM. La seule différence c’est que cette fois-ci c’est Visual Studio qui va générer le schéma par une procédure de rétro ingénierie.
L’approche Code First
Cette dernière approche, qui est celle que nous avons choisi pour illustrer ce tutoriel, part d’un constat : ce qu’un développeur sait faire de mieux, c’est coder.
Cette approche, qui est la plus commune dans le monde des ORM consiste à vous fournir trois outils pour que vous, développeur, n’ayez qu’à coder des classes comme vous le feriez habituellement et en déduire le modèle qui doit être généré.
Nous avons donc de la chance, nous pourrons garder les classes que nous avions codées dans la partie précédente, elles sont très bien telles qu’elles sont.
Trois outils, ça fait beaucoup non ? Et puis c’est quoi ces outils ?
Quand vous allez définir un modèle avec votre code, vous allez devoir passer par ces étapes :
- coder vos classes pour définir le modèle ;
- décrire certaines liaisons complexes pour que le système puisse les comprendre ;
- mettre à jour votre base de données ;
- ajouter des données de test ou bien de démarrage (un compte admin par exemple) à votre base de données.
Tout cela demande bien trois outils. Heureusement pour vous, ces outils sont fournis de base dans Entity Framework, et nous en parlons dans le point suivant, soyez patients. 
Comment choisir son approche
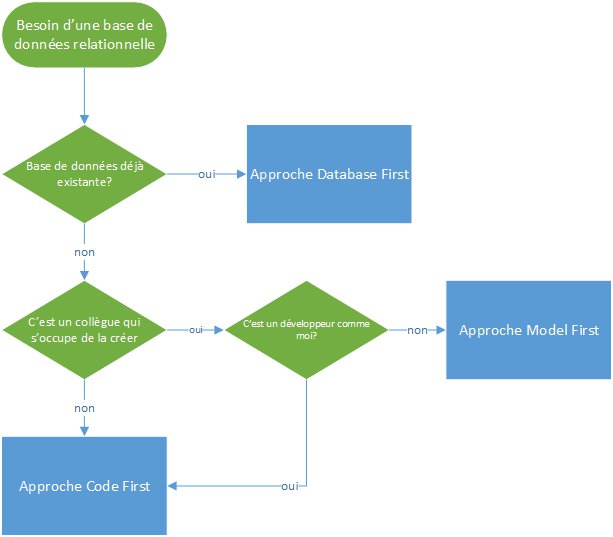
Quand vous démarrez un projet, vous allez souvent vous poser beaucoup de questions. Dans le cas qui nous intéresse, je vous conseille de vous poser trois questions :
- Est-ce qu’il y a déjà une base de données ? Si oui, il serait sûrement dommage de tout réinventer, vous ne croyez pas ?
- Est-ce que vous êtes seuls ? Si oui, vous faites comme vous préférez, c’est comme ça que vous serez le plus efficace, mais si vous êtes à plusieurs il vous faudra vous poser une troisième question primordiale…
- Qui s’occupe de la BDD : un codeur, ou un expert qui a réfléchi son modèle via un diagramme ? Il y a fort à parier que s’adapter à l’expertise de la personne qui gère la BDD est une bonne pratique, non ?
Pour être plus visuel, on peut exprimer les choses ainsi :
-
La Méthode MERISE est une méthode franco-française encore très répandue aujourd’hui pour gérer les projets et notamment les étapes de conception.
↩
Présentation d'Entity Framework
À partir de ce chapitre nous utiliserons Entity Framework comme ORM et nous suivrons l’approche Code First.
Entity Framework, c’est le nom de l’ORM officiel de .NET. Développé par Microsoft, il est à l’heure actuelle en version 6. Vous pourrez observer l’arrivé d’une version mineure par semestre environ, parfois plus, parfois moins lorsque l’outil est très stable. Vous pouvez bien sûr le télécharger sur NuGet.
Je vous ai dit tout à l’heure qu’il fallait trois outils pour suivre l’approche Code First. Bien évidemment, Entity Framework les possède.
Un mapper
Le mot francisé serait "mappeur", et son principal but est de faire correspondre les objets POCO à des enregistrements en base de données.
C’est à ce mapper que sont accrochés les connecteurs qui vous permettront d’utiliser les différents systèmes de gestion de base de données. De base vous aurez droit à SQLServer LocalDB. Pour tester notre blog, c’est ce connecteur que nous utiliserons car il permet de créer rapidement des bases de données, et de les supprimer tout aussi rapidement une fois qu’on a tout cassé. 
Une API de description
Quand vous utilisez un ORM, il faudra parfois décrire les relations entre les classes. En effet, certaines sont complexes et peuvent être interprétées de plusieurs manières, il vous faudra donc dire explicitement ce qu’il faut faire.
Vous pouvez aussi vouloir nommer vos champs et tables autrement que ce qu’indique la convention.
Pour cela, vous avez deux grandes méthodes avec EntityFramework.
Les annotations
Comme nous l’avions vu lorsque nous avons voulu vérifier la cohérence des données saisies par l’utilisateur, vous allez pouvoir décrire votre modèle avec des annotations.
Les annotations les plus importantes seront :
[Index]: elle permet de s’assurer qu’une entrée est unique dans la table, et ainsi accélérer fortement les recherches.[Key]: si votre clef primaire ne doit pas s’appeler ID ou bien qu’elle est plus complexe, il faudra utiliser l’attribut Key.[Required]: il s’agit du même[Required]que pour les vues1, il a juste un autre effet : il interdit les valeursNULL, ce qui est une contrainte très forte.
La Fluent API
La seconde méthode a été nommée "Fluent API". Elle a été créée pour que ça soit encore une fois la production de code qui permette de décrire le modèle.
La Fluent API est beaucoup plus avancée en termes de fonctionnalités et vous permet d’utiliser les outils les plus optimisés de votre base de données.
Je ne vais pas plus loin dans l’explication de la Fluent API, nous ne l’observerons à l’action que bien plus tard dans le cours, lorsque nous aurons affaire aux cas complexes dont je vous parlais plus tôt.
Les migrations Code First
Troisième et dernier outil, qui bénéficiera de son propre chapitre tant il est important et puissant.
Les migrations sont de simples fichiers de code (on ne vous a pas menti en disant que c’était du Code First) qui expliquent à la base de données comment se mettre à jour au fur et à mesure que vous faîtes évoluer votre modèle.
Une migration se termine toujours par l’exécution d’une méthode appelée Seed qui ajoute ou met à jour des données dans la base de données, soit pour tester soit pour créer un environnement minimum (exemple, un compte administrateur).
-
Nous pourrons d’ailleurs observer que tous les filtres par défaut sont utilisés à la fois par les vues et Entity Framework. C’est une sécurité supplémentaire et une fonctionnalité qui vous évitera de produire encore plus de code.
↩