Bon, vous en avez assez de devoir supprimer votre base de données à chaque modification ? J’ai la solution pour vous : les migrations.
Ce chapitre vous expliquera comment les créer, les modifier et les appliquer.
- Définition
- Créer un jeu de données pour tester l'application
- Améliorer notre modèle avec la FluentAPI
Définition
Cas d’utilisation
Comme nous avons pris de bonnes habitudes, pour définir ce qu’est une migration, partons d’un cas concret.
Vous avez pu voir jusqu’à présent qu’à chaque fois que vous amélioriez votre modèle de données, il fallait remettre la base de données à zéro. Je ne sais pas pour vous, mais, moi, je n’ai pas envie de devoir remettre mon blog à zéro à chaque fois que je l’améliore.
Alors on peut tenter de jouer avec des sauvegardes. Avant d’améliorer le site, je sauvegarde ma base de données sur une copie. Ensuite, je vais faire le changement et enfin je vais migrer mes données sur la base de données qui vient d’être recréée.
Vous comprenez que c’est long et frustrant.
Mais en plus de ça, j’ai un ami qui m’aide à créer mon blog, alors lui aussi, de temps en temps il fait des améliorations sur le modèle de données. Malheureusement, à chaque fois, je ne m’en rend pas tout de suite compte alors je perds beaucoup de temps à tout recréer.
Et puis parfois, comme mon ami est très en retard par rapport aux modifications que j’ai faites, il y a tellement de choses qui changent qu’il oublie de faire certaines configurations et donc ça plante.
Enfin, mon ami, il s’y connaît en base de données, son livre de chevet, c’est ce tuto, alors pour lui les vues, les déclencheurs, les index… ça n’a plus aucun secret. Mais a priori, votre code ne dit pas comment utiliser ces fonctionnalités des systèmes de gestion de base de données.
La solution : les migrations
Désireux de trouver un remède à tous ces problèmes, les auteurs des différents frameworks web ont travaillé sur un concept qu’on appelle les migrations. L’avantage, c’est que ASP.NET ne fait pas exception à la règle.
Une migration, c’est un outil qui résout ces problèmes en fonctionnant ainsi :
- à chaque changement du modèle, on crée le code SQL qui permet de modifier à chaud la base de données ;
- l’exécution de ce code est totalement automatisée ;
- chaque code possède un marqueur temporel qui permet d’ordonner les migrations.
Schématiquement, on pourrait dire que les migrations fonctionnent ainsi :
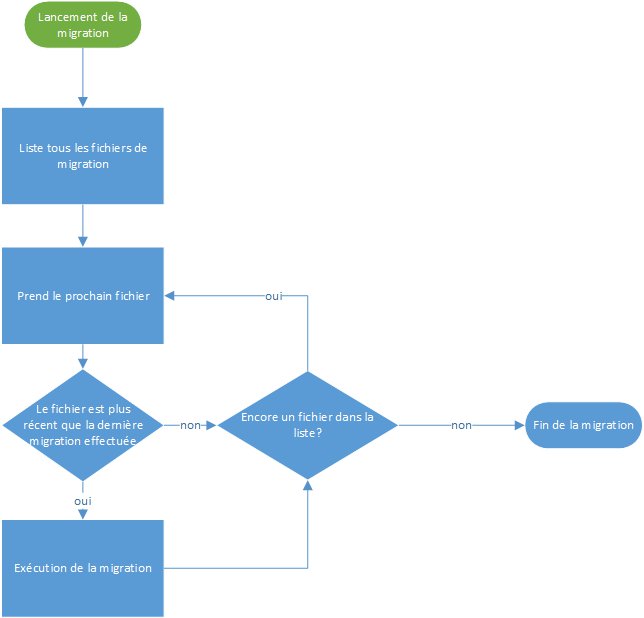
L’avantage de ce système c’est que non seulement il facilite tout, mais surtout il se base sur des simples fichiers de code, dans notre cas du C#. Du coup, vous pouvez modifier le comportement de vos migrations pour améliorer votre BDD. Nous allons voir ça par la suite.
Enfin, autre fait intéressant : si à force de faire beaucoup de modifications, vous trouvez que votre modèle n’est pas aussi bon que vous le souhaitez, toutes les migrations sont réversibles. Une fois le reverse opéré, il ne vous reste plus qu’à supprimer le fichier de migrations et plus personne ne se souviendra que vous avez tenté de faire ces modifications là et avez échoué.
Mettre en place les migrations
Comme on parle de tâches automatiques, il ne faudra pas avoir peur du terminal, enfin je veux dire de PowerShell.
Dans le menu "Outils" puis "Gestionnaire de package NuGet", sélectionnez "Console du gestionnaire de paquet".
Là, il vous faudra entrer la commande Enable-Migrations puis lancer la commande Add-Migration initial.
Plus tard, quand vous désirerez ajouter une migration, il faudra utiliser la commande Add-Migration nom_lisible_par_un_humain_pour_la_migration. Ensuite, la commande magique s’appellera Update-Database.
Dans cette vidéo, nous ferons un tour du propriétaire des migrations :
Créer un jeu de données pour tester l'application
Doucement, la fin de la troisième partie de ce tutoriel approche, et avec elle vous avez appris les bases nécessaires pour créer un site web dynamique avec ASP.NET.
Avant de publier ce site web, vous allez néanmoins vouloir vous assurer que votre site fonctionne et que tout s’affiche là où il faut. Pour vous faciliter la tâche, vous allez sûrement ajouter quelques données à votre base de données.
Heureusement, comme nous avons choisi l’approche CodeFirst, il y a une méthode simple pour insérer des données automatiquement et ça, ça n’a pas de prix.
Un jeu de données simple
Si vous vous souvenez de la vidéo sur les migrations, vous vous souviendrez que j’ai évoqué le fichier Configuration.cs du dossier Migrations. Dans ce fichier, se trouve une méthode Seed.
Sans tenter de traduction hasardeuse, le but de cette méthode est simple : ajouter des données à votre base de données pour que vous puissiez démarrer votre application.
Vous trouverez en argument de cette fonction le contexte de données qui établit la connexion avec votre BDD, profitons-en.
Ajoutons un article
Commençons par faire simple. Ajoutons un article.
Cela se passe exactement comme dans nos contrôleurs. Il suffit de créer un objet Article, de l’ajouter au contexte et de sauvegarder le tout.
context.Articles.Add(new Article
{
Contenu = "plop !",
Pseudo = "un pseudo",
Titre = "mon titre",
});
context.SaveChanges();
Maintenant, dans l’hôte Powershell du gestionnaire de package, lancez Update-Database.
Et quand on regardera dans l’explorateur de serveur, notre nouvel article sera créé !

Tant que nous sommes dans le fichier de migrations, nous avons accès à des méthodes d’extension spécialement réalisées pour être utilisées dans la méthode Seed. L’un des cas est la méthode AddOrUpdate qui vient se greffer aux DbSet et qui vous permet d’ajouter une entité uniquement si elle n’est pas existante (i.e si aucun champ dont la valeur doit être unique possède déjà un doublon en base de données) et de la mettre à jour dans le cas contraire.
Dans le cadre d’une base de données de test, je préfère ne pas l’utiliser, mais quand on parlera des données pour le site final, ça peut beaucoup aider.
Créons un compte administrateur
Créer un compte utilisateur, c’est si différent que ça de créer un article ?
En fait, si vous jetez un coup d’œil au fichier AccountController.cs, vous vous rendrez compte que pour gérer la sécurité, ASP.NET MVC sépare pas mal les classes et au final créer un compte utilisateur demande quelques prérequis. Or, comme nous n’avons pas vu en détail l’authentification dans notre blog, je préfère vous fournir quelques explications basiques ainsi que le code.
Un utilisateur, de base dans ASP.NET, est composé de deux entités distinctes :
- la première gère son Identité et son Authenticité ;
- la seconde gère ses informations complémentaires.
L’identité et l’authenticité sont deux concepts importants qui seront détaillés plus tard, mais pour faire simple, vous êtes identifiés lorsque vous avez donné votre pseudo, et authentifié quand vous avez donné le mot de passe adéquat.
Il faut ajouter que les utilisateurs ont des rôles. Par exemple, sur Zeste de Savoir, je suis un simple membre, mais certains sont membres du staff et peuvent valider un tuto ou modérer les forums, et au dessus de tous, il y a des administrateurs qui ont sûrement quelques super pouvoirs.
Pour gérer tout ça, vous ne pourrez pas vous contenter de faire un Context.Users.Add(), vous le comprenez sûrement. Il faut appeler un manager qui lui-même sait gérer les différentes tables qui lui sont présentées dans un Store.
Nous n’irons pas plus loin pour l’instant, passons au code :
if (!context.Roles.Any(r => r.Name == "Administrator"))
{
RoleStore<IdentityRole> roleStore = new RoleStore<IdentityRole>(context);
RoleManager<IdentityRole> manager = new RoleManager<IdentityRole>(roleStore);
IdentityRole role = new IdentityRole { Name = "Administrator" };
manager.Create(role);
}
if (!context.Users.Any(u => u.UserName == "Proprio"))
{
UserStore<ApplicationUser> userStore = new UserStore<ApplicationUser>(context);
UserManager<ApplicationUser> manager = new UserManager<ApplicationUser>(userStore);
ApplicationUser user = new ApplicationUser { UserName = "Proprio" };
manager.Create(user, "ProprioPwd!");
manager.AddToRole(user.Id, "Administrator");
}
Un jeu de données complexes sans tout taper à la main
Nous l’avons vu, pour créer un jeu de données, il suffit de créer des objets et de les ajouter à la base de données. Seulement la méthode utilisée jusque là est un peu embêtante :
- pour créer un jeu de données qui doit être représentatif de tous les cas d’utilisation, il faut tout écrire à la main. Imaginez-vous devoir écrire 50 articles complets juste pour tester !
- vous perdez le "sens" de vos données. Si pour être représentatif, vous devez avoir un article qui a un tag, un qui en a deux, un qui n’en a pas, répéter cela pour les articles qui sont courts, longs, très longs… Si vous chargez vos articles dans un fichier JSON comme je vous l’avez proposé dans la partie précédente, comment savez vous quel article représente quel cas quand vous lisez votre code ? Comment savez-vous que vous n’avez pas oublié de cas ?
Pour résoudre ces problèmes, nous allons donc procéder par étapes :
Premièrement, nous allons générer des données cohérentes en grand nombre de manière automatique.
Pour cela, téléchargez le package NuGet Faker.NET. Ce module vous permet de générer automatiquement plein de données. Vous aurez droit à :
| Nom | Commentaires | Méthodes utiles (non exhaustif) |
|---|---|---|
| Address | Vous permet d’accéder à tout ce qui concerne une adresse, de la rue au code postal. | City(), StreetAddress(). Beaucoup de méthodes propres aux US et UK. |
| Company | Vous permet d’accéder aux différentes dénominations pour les entreprises | Name() (pour le nom) et CatchPhrase() (pour simuler un slogan) |
| Internet | Très utile pour simuler ce qui est propre aux sites web | DomainName() et DomainSuffix() pour générer des adresses de site web, UserName() pour générer un pseudo ! |
| Lorem | Génère des textes plus ou moins longs sur le modèle du Lorem. | Sentence() pour générer une phrase, Words(1).First() pour un seul mot, Paragraph() pour un seul paragraphe, Paragraphs(42) pour avoir la réponse à la question sur l’univers et le sens de la vie en latin, of course. |
| Name | Tout ce qui concerne l’état civil d’une personne | First() (prénom) Last() (nom de famille) |
| Phone | Génère des numéros de téléphone | Number(), il n’y a que ça |
| RandomNumber | Equivalent à la méthode Next() de l’objet Random | … |
Ainsi pour créer un article avec deux tags, nous pourrons faire :
Tag tag1 = new Tag { Name = Faker.Lorem.Words(1).First() };
Tag tag2 = new Tag { Name = Faker.Lorem.Words(1).First() };
context.Tags.AddOrUpdate(tag1, tag2);
Article article = new Article
{
Contenu = Faker.Lorem.Paragraphs(4),
Pseudo = Faker.Internet.UserName(),
Titre = Faker.Lorem.Sentence(),
Tags = new List<Tag>()
};
article.Tags.Add(tag1);
article.Tags.Add(tag2);
context.Articles.Add(article);
Un jeu de données pour le debug et un jeu pour le site final
Je vous propose de terminer cette partie sur les jeux de données par la création de deux jeux de données : un pour les tests et un pour la production.
En effet, les caractéristiques de ces jeux de données et la manière de les créer est différente en fonction du contexte. Regardons un peu ce que nous attendons de ces deux jeux de données :
Le jeu de tests doit :
- permettre de tester tous les cas, du plus courant au plus étrange ;
- représenter une utilisation fidèle du site, lorsque je teste mon blog, je ne vais pas tenter d’y mettre 15 000 articles si je sais que je ne vais en poster qu’un par mois (soit 24 en deux ans), à l’opposé, si je m’appelle Zeste de Savoir, je dois pouvoir obtenir une dizaine de tutoriels longs avec beaucoup de contenu pour voir comment ça se comporte.
Le jeu de production doit :
- permettre l’installation du site ;
- être prévisible et donc documenté, si vous créez un compte administrateur (obligatoire), il doit avoir un mot de passe par défaut qu’on peut trouver facilement ;
- ne pas casser les données déjà présentes en production.
Je vais donc vous donner quelques conseils pour que vous mettiez en place des données cohérentes rapidement.
Nous allons nous servir d’une propriété très intéressante des fichiers de configuration de ASP.NET. Comme nous avons plusieurs "versions de données", nous allons aller dans le fichier Web.config.
Une fois dans ce fichier, il faudra localiser la section appSettings. Là, nous y ajouterons une ligne <add key="data_version" value="debug"/>.
Cela dit que la "version des données" par défaut sera "debug". Vous pourrez changer ça, mais cela n’aura pas d’importance puisque de toute façon nous allons dire explicitement quelles données utiliser quand on fait des tests et quand on met en production.
Pour les données de tests :
- Allez dans le fichier Web.Debug.Config, et ajoutez-y le code suivant :
<appSettings>
<add xdt:Transform="Replace" xdt:Locator="Match(key)" key="data_version" value="debug"/>
</appSettings>
Cela aura pour effet de dire « quand tu buildes en debug, trouve-moi la propriété "data_version" et remplace sa valeur par "debug" ».
2. Dans le fichier Migrations/Configuration.cs, créez une méthode privée nommée seedDebug qui a les mêmes arguments que Seed et coupez-collez le code de la méthode Seed dans seedDebug.
3. Dans la méthode Seed, vous allez maintenant préciser "si je veux des données de debug, alors, appeler seedDebug :
protected override void Seed(Blog.Models.ApplicationDbContext context)
{
if (ConfigurationManager.AppSettings["data_version"] == "debug")
{
seedDebug(context);
}
}
Vous pouvez étoffer votre code de test en y mettant de nouvelles données, vous pouvez aussi vous inspirer du patron de conception Factory pour créer des articles qui correspondent à des paramètres différents.
Pour le jeu de données de production
Tout comme précédemment, nous allons utiliser la transformation des fichiers de configuration.
Nous allons donc aller dans le fichier Web.Release.config et y entrer le code :
<appSettings>
<add xdt:Transform="Replace" xdt:Locator="Match(key)" key="data_version" value="production"/>
</appSettings>
Du coup on peut encore créer une méthode privée dans le fichier Migrations/Configuration.cs et l’appeler de manière adéquate :
protected override void Seed(Blog.Models.ApplicationDbContext context)
{
if (ConfigurationManager.AppSettings["data_version"] == "debug")
{
seedDebug(context);
}
else if (ConfigurationManager.AppSettings["data_version"] == "production")
{
seedProduction(context);
}
}
private void seedProduction(ApplicationDbContext context)
{
}
Il ne nous reste plus qu’à savoir quoi mettre dans la fonction seedProduction.
Et là, plus question de faire de la génération automatique, il va falloir créer les objets un à un.
Dans cette configuration, j’ai un petit faible pour les fichiers JSON ou YAML qui regroupent une description des objets à créer. On appelle ces fichiers des fixtures.
Ils ont de nombreux avantages :
- ils sont plus lisibles que du code ;
- ils sont facilement modulables (ajouter ou retirer un objet est très facile) ;
- ils sont versionnables, c’est-à-dire que si vous travaillez à plusieurs avec des outils comme GIT ou SVN, ces fichiers seront correctement gérés par ces outils.
Surtout, cette fonction ne doit pas détruire les objets déjà présents. Vous allez donc devoir absolument utiliser la méthode AddOrUpdate et faire les vérifications d’existence quand le cas se présente.
Améliorer notre modèle avec la FluentAPI
Les explications qui vont suivre s’adressent surtout aux personnes qui ont une bonne connaissance des bases de données. Nous l’avons mis dans ce tutoriel car vous trouverez rapidement des cas où il faut en passer par là, mais ils ne seront pas votre quotidien, rassurez-vous.
Si vous vous souvenez de l’introduction à l’approche Code First, je vous avais parlé de trois outils dont un qui s’appelle la Fluent API.
Cette API est très complète et permet en fait de personnaliser d’une manière encore plus complète vos entités quand bien même aucune Annotation n’existe.
Elle est complétée par la possibilité de personnaliser un maximum les migrations qui, je vous le rappelle, sont de simples fichiers de code.
Ce chapitre pourrait mériter un livre complet qui s’appellerait alors "améliorer les performances, la sécurité et l’utilisation de votre base de données". J’ai pour ma part choisi deux "cas d’étude" que j’ai rencontrés dans plusieurs de mes projets, et pour le premier, il a même été tout le temps rencontré.
Nous allons donc conjuguer la Fluent API avec une possible connaissance du SQL pour des cas très précis tels que l’ajout de contraintes plus complexes ou l’utilisation de fonctionnalités avancées des bases de données.
Quand les relations ne peuvent être pleinement décrites par les annotations
Lors que vous définissez une relation, parfois, elle est plus complexe qu’il n’y parait et les annotations ne suffisent pas à la décrire proprement, ou alors il faut se torturer un peu l’esprit pour y arriver.
C’est à ce moment-là qu’intervient la Fluent API. Je vais vous présenter deux cas "typiques" qui vous demanderont d’utiliser la FluentAPI.
Le premier cas, on peut le représenter très simplement sous la forme d’un schéma :
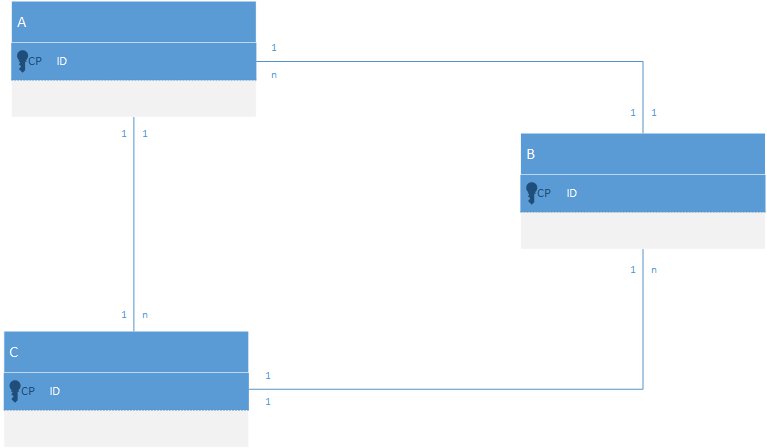
Nous avons donc à un moment dans notre modèle, une entité C qui est liée fortement à une instance d’une entité B qui est liée à une instance d’une entité A qui est liée à une instance d’une entité C.
Sauf qu’il est tout à fait possible que l’instance C de départ et celle d’arrivée soient… une seule et unique instance. Si vous pensez que ça n’arrive pas dans votre cas précis, souvenez vous de la loi de Murphy : "s’il existe une manière pour que l’action en cours se termine par une catastrophe, alors, ça finira par arriver".
Maintenant, imaginez que vous avez besoin de supprimer l’entité A.
Par défaut, ce genre de relation entraine une suppression en cascade. Donc quand Entity Framework enverra la commande SQL associée à la suppression de A, C va être détruite. Mais du coup, B aussi. Et du coup A aussi, et du coup… attendez, on a déjà supprimé A ? Donc, quand on a demandé la suppression de C, la base de donnée n’était plus cohérente. Donc, on ne peut pas appliquer "supprimer C", comme "supprimer C" a été demandé par "supprimer B", on ne peut pas non plus demander "supprimer B" ni "supprimer A".
Plus globalement, cette situation peut arriver selon deux schémas : le cycle (cercle) et le diamant (losange). Il faudra donc décrire ce qu’il faut faire pour briser cette figure.
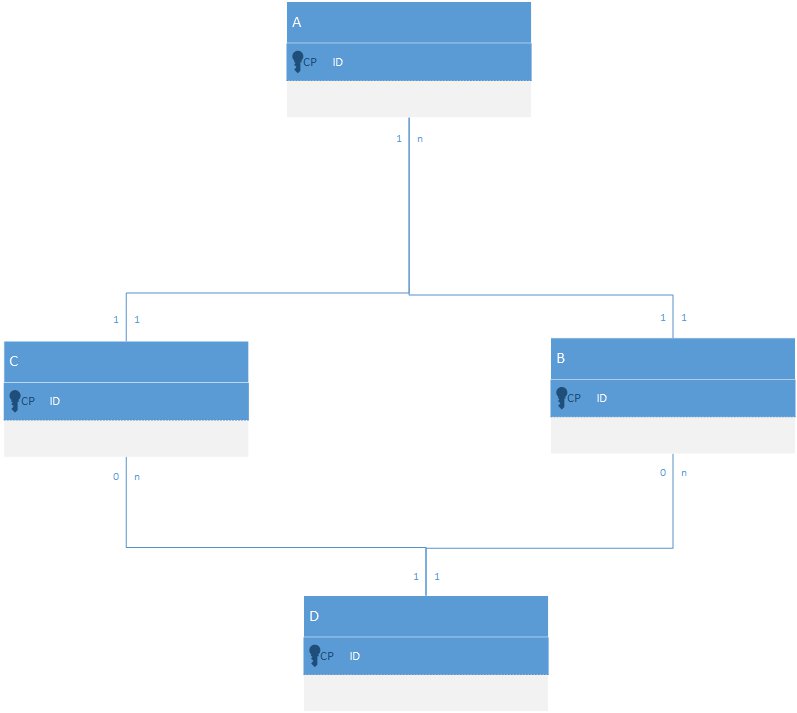
La solution la plus simple est de décider une entité dont la suppression n’engendrera pas de suppression en cascade. Le problème c’est que cela génèrera la possibilité que l’entité liée ne soit liée à rien. Il faudra donc dire que la relation est "optionnelle".
Pour cela, il faudra aller dans le fichier qui contient notre contexte de données. Nous allons y surcharger la méthode OnModelCreating, comme ceci :
public class ApplicationDbContext : IdentityDbContext<ApplicationUser>
{
public ApplicationDbContext()
: base("DefaultConnection", throwIfV1Schema: false)
{
}
protected override void OnModelCreating(DbModelBuilder modelBuilder)
{
base.OnModelCreating(modelBuilder);
}
}
À l’intérieur de cette méthode, nous allons utiliser les possibilités du DbModelBuilder.
Puis nous allons décrire pas à pas comment doivent se comporter nos entités. Dans le cas des A/B/C, par exemple, nous aurions pu écrire :
modelBuidler.Entity<A>()
.HasMany(obj => obj.BProperty)
.WithOptional(objB -> objB.AProperty)
.WillCascadeOnDelete(false);// on dit explicitement qu'il n'y a pas de suppression en cascade
Lorsque vous recréerez une migration, le code de génération de la base de données sera amendé avec cette gestion des conflits.