Quoi de plus fatiguant que de renommer des nœuds en masse dans Maya ? 
Maya dispose de quelques outils, mais ils ne font jamais exactement ce qu’on souhaite, pas vrai ?
On est tous passés par là, mais c’est dans ces moments qu’on se dit qu’il serait peut-être temps d’apprendre à scripter deux-trois trucs. Peut-être même est-ce la raison pour laquelle vous avez décidé de commencer ce tutoriel ? 
Eh bien réjouissez-vous, car on va attaquer l’automatisation de ce travail ingrat qu’est le renommage des nœuds. 
- Retrouver des nœuds avec un nom pas défaut
- Détecter les caractères non-ASCII
- Avoir des noms de nœud simples et propres
- rename() pour renommer vos nœuds
- Une ch’tite boucle pour renommer des ch'tits nœuds...
Retrouver des nœuds avec un nom pas défaut
Notre premier bout de code va se concentrer sur la récupération des nœuds ayant un nom par défaut.
On va les débusquer ces fripons ! 
Vous êtes d’attaque, j’aime ça ! 
La commande de base
Sans trop de surprises, la commande qui va nous permettre de trouver les noms par défaut est ls() :
mc.ls('*pSphere*', type='transform')
Ici, on cherche tous les nœuds de type transform ayant pSphere dans leur nom.
Notez que j’ai mis l’argument type='transform' car ce que nous souhaitons renommer, ce sont les nœuds de transformation (c’est-à-dire que l’on peut sélectionner).
Sur ma petite scène, cela donne :
[u'root|pSphere1', u'|pSphere1', u'pSphere2', u'pSphere3']
Elle n’est pas superbement bien nommée cette scène, du travail de sagouin ! 
Mais alors, il suffirait d’avoir une liste de noms par défaut, de leur ajouter * avant et après pour avoir notre liste de nœuds mal nommés ? 
Bien vu ! On peut essayer !
Premier script
default_names = ['pSphere', 'pCube', 'pPlane', 'pPyramid', 'locator']
for default_name in default_names:
name_expr = '*'+default_name+'*'
print mc.ls(name_expr, type='transform')
Ligne à ligne, cela donne :
default_names = ['pSphere', 'pCube', 'pPlane', 'pPyramid', 'locator']
La première chose ici, consiste à lister les noms par défaut des nœuds qu’on retrouve le plus. Pour ce tuto, je vais m’en tenir à ceux-là, mais vous pouvez augmenter cette liste suivant vos besoins.
Notez qu’on utilise default_names (avec un s) qui est le nom de la liste. 
for default_name in default_names:
Nous allons ensuite la parcourir en prenant les noms un à un.
name_expr = '*'+default_name+'*'
Puis nous fabriquons une expression en ajoutant les étoiles devant et derrière le nom. Ainsi, "pSphere" devient "*pSphere*", "pCube" devient "*pCube*", etc.
print mc.ls(name_expr, type='transform')
Enfin, nous affichons le résultat de la commande ls() pour chacun des noms.
Chez moi, cela donne :
[u'root|pSphere1', u'|pSphere1', u'pSphere2', u'pSphere3']
[u'root|pCube1', u'|pCube1', u'pCube2', u'pCube3']
[]
[]
[]
Instructif, mais ne serait-il pas plus intéressant de récupérer l’ensemble sous la forme d’une seule et même liste ? Ça tombe bien, la commande ls() permet une légèreté syntaxique pour le faire en un seul appel. Vous pouvez en effet passer une liste d’expressions, un peu comme ça :
mc.ls(['*pSphere*', '*pCube*', '*pPlane*', '*pPyramid*', '*locator*'], type='transform')
Mmmhhh… Si nous avions un moyen de générer une liste depuis default_names en ajoutant des étoiles devant et derrière chacun des noms, on pourrait passer cette nouvelle liste en argument de ls().
Vous avez tout compris !
Second script
La méthode simple consiste à transformer nos noms en expressions avec des étoiles. En gros, transformer ça :
['pSphere', 'pCube', 'pPlane', 'pPyramid', 'locator']
En ça :
['*pSphere*', '*pCube*', '*pPlane*', '*pPyramid*', '*locator*']
Puis à passer cette liste à la commande ls().
Pour cela, une simple boucle suffit :
name_exprs = []
for default_name in default_names:
name_expr = '*'+default_name+'*'
name_exprs.append(name_expr)
print mc.ls(name_exprs, type='transform')
Et bien entendu, je vous propose une explication ligne à ligne :
name_exprs = []
Ici, on prépare la liste que notre boucle va remplir de nos noms sous forme d’expressions.
for default_name in default_names:
Le début de la boucle, on parcourt un à un tous les noms de notre liste de noms par défaut.
name_expr = '*'+default_name+'*'
Comme précédemment, nous ajoutons les étoiles devant et derrière le nom pour en faire une expression.
name_exprs.append(name_expr)
Nous ajoutons notre expression fraîchement construite à notre liste finale…
print mc.ls(name_exprs, type='transform')
…que nous utilisons enfin dans notre commande ls() qui va nous sortir tous les nœuds de notre scène correspondant à *pSphere*, ou *pCube*, ou *pPlane*, etc. 
Sur ma petite scène faite de cubes et de sphères, cela donne :
[u'root|pSphere1', u'|pSphere1', u'pSphere2', u'pSphere3', u'root|pCube1', u'|pCube1', u'pCube2', u'pCube3']
Pas mal hein ? 
Script du paresseux
La version pour les flemmards endurcis (les codeurs Python en fait ) c’est :
mc.ls(['*'+n+'*' for n in default_names], type='transform')
Cette méthode utilise une comprehension list :
['*'+n+'*' for n in default_names]
C’est de l’ordre du langage, nous ne l’expliquerons donc pas ici. Je vous invite, en revanche, à creuser un peu le sujet (list comprehension, dict comprehension, etc.), il est possible que vous appreniez des choses intéressantes.
Vous pouvez lui ajouter un select() devant :
default_names = ['pSphere', 'pCube', 'pPlane', 'pPyramid', 'locator']
mc.select(mc.ls(['*'+n+'*' for n in default_names], type='transform'))
Et bim ! En deux lignes vous sélectionnez tous les nœuds avec un problème de nom par défaut. Avouez que ça envoie du pâté auprès des collègues ! 
On va mettre ça sous forme de fonction qu’on peut mettre dans un coin et garder pour plus tard.
default_names = ['pSphere', 'pCube', 'pPlane', 'pPyramid', 'locator']
def get_nodes_with_default_names():
"""Return a list of nodes in current scene having default name"""
return mc.ls(['*'+n+'*' for n in default_names], type='transform')
Détecter les caractères non-ASCII
Nous allons scripter un moyen de détecter les nœuds ayant un caractère non-ASCII.
Debout, couché, ascii?
On prononce aski bande de petits malins !
Je suppose que ça n’a rien à voir avec ce sport qu’on pratique d’ordinaire à la montagne en hiver ?
Vous avez de l’humour et c’est bien, ça prouve que vous êtes réveillé.
Donc non-askii c’est en snowb… 
Le prochain pavé de code risque de vous êtres très désagréable… 
Bon, prenons les choses dans l’ordre. 
Unicode ni reproche
Maya, ainsi qu’énormément d’applications modernes, gèrent très bien la norme de codage de caractère Unicode, qui permet d’écrire des lettres dans toutes les langues (mais pas que), mais si cette dernière est très pratique pour les applications utilisant des caractères riches et, par conséquent, tournées vers l’expression littérale (e.g. le web), elle devient handicapante dans le cas où on cherche, justement, une uniformité et une concision.
En quoi un moyen de gérer tous les caractères est-il gênant ?
Saviez-vous qu’il existe plusieurs types d’espace en Unicode ? Idem pour les traits-d’unions. Il suffit qu’un graphiste copie-colle un mot trouvé sur le net et deux mots visuellement identiques ne le seront en fait pas.
Autre exemple : Une fois au lighting, vous faites des expressions pour assigner des matériaux et des attributs. Si vos nœuds portent des noms « techniquement » différents, bien que « visuellement » identiques, vous allez passer plus de temps à faire correctement votre travail.
Limiter le nombre de caractères utilisables pour les noms des nœuds (et autres données de votre pipeline) simplifie ce qui passe dans les tuyaux.
En tant que francophone, nous pourrions arguer qu’utiliser une telle limitation de caractère revient à réciter du Corneille la langue greffée de clous rougis au fer. Nous n’aurions qu’à moitié tord. Mais force est de constater que se contraindre à l’utilisation d’un sous-ensemble des caractères de notre langue peut nous rendre de grands services technologiques et il peut être utile de détecter, et modifier, les caractères qui n’y appartiennent pas.
Et c’est ce que nous allons faire ! 
La norme ASCII
La norme ASCII est la plus simpliste des façons de stocker des caractères en informatique. C’est aussi une des plus vieilles (1960). Elle est composée de 128 caractères (7 bits) dont 95 imprimables (c-à-d, lisibles):
!"#$%&'()*+,-./
0123456789:;<=>?
@ABCDEFGHIJKLMNO
PQRSTUVWXYZ[\]^_
`abcdefghijklmno
pqrstuvwxyz{|}~
Ils sont tous là!
Comme vous pouvez le constater, pas d’accents, un seul type d’espace, pas de œ, etc.
Curiosité littérale
On va mettre ça en pratique.
Créez un nœud portant le nom nœuds et regardons ce qui se passe :
mc.createNode('transform', name='nœuds')
# Result: u'n\u0153uds' #
Déjà, u'n\u0153uds', ça calme direct  .
.
Un indice : Le \u indique que c’est de l’Unicode, puis 0153 parce que « œ » est le caractère Unicode numéro… 153. (Cherchez « caractère Unicode 153 » sur internet pour vous en convaincre ).
Toutefois, le nœud est correctement nommé dans Maya :
// TODO image
Et si vous tapez la commande en MEL :
createNode "transform" -name "nœuds";
// Result: nœuds //
Cette fois ci le nom du nœud apparaît correctement. Mais comment cela se fait-il ?
C’est la magie de l’Unicode qui est totalement supporté par le MEL !
Précédemment, je vous ai dis que l’Unicode était géré de manière native par la plupart des applications modernes. C’est le cas pour Maya et son MEL, mais dans le cas de Python 2.x, les chaînes de caractère natives sont en ASCII (comme en langage C). C’est d’ailleurs une des raisons qui fait que Python 2 et 3 ne sont pas (ou très partiellement) compatibles. Dans ce dernier, les chaînes de caractères sont nativement en Unicode.
Il va falloir virer tout ça!
La méthode
Il y a plusieurs méthodes pour détecter qu’une chaîne de caractères est valable en ASCII, mais je vais vous proposer la mienne et vous allez voir que c’est assez logique.
On va essayer d’encoder notre chaîne de caractère en ASCII et voir ce qui se passe :
>>> 'a'.encode('ascii')
'a'
Sans trop de surprise, avec un simple a, cela fonctionne, car cette lettre fait partie de la norme ASCII.
Qu’en est-il avec un caractère un peu plus élaboré :
>>> 'é'.encode('ascii')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeDecodeError: 'ascii' codec can't decode byte 0xc3 in position 0: ordinal not in range(128)
Bam ! Pour faire simple, le message d’erreur indique que le caractère 0xc3 (notre é) ne peut pas s’encoder en ASCII, car son numéro de caractère, est au-dessus de 128.
Inspection du plantage
En Python, quand vous voyez un message tel que :
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
BlahblahError: une erreur c'est pas bien blah blah
C’est que le code a planté quelque part. 
Sauf qu’à défaut de faire planter l’application entière (ici, Maya), Python arrête immédiatement l’exécution du script et « crie » à qui veut l’entendre qu’on a eu un problème avec une erreur bien identifiée. Cette « erreur bien identifiée » s’appelle une « exception » (dans notre petit exemple, c’est BlahblahError).
Le fait de « crier » une exception porte un nom : « Lever une exception ».
Comme le précise la documentation ( ), la méthode str.encode() lève une exception UnicodeDecodeError si l’encodage échoue.
Voir Python nous cracher lever son exception au visage ne nous aide pas (Venant d’un python c’est même plutôt dangereux ), mais que diriez-vous si je vous disais que le principe d’une levée d’exception c’est de pouvoir « l’attraper » et la prendre en compte pour continuer l’exécution de son script ?
Je dirais que je ne vois pas trop ou tu veux en venir… 
Qu’a cela ne tienne, nous allons voir ça rapidement.
Appropriation du mécanisme
Voici un code qui attrape l’exception et improvise :
try:
'é'.encode('ascii') # on essait de faire ca
except UnicodeDecodeError: # si la ligne precedente plante en levant l'exception UnicodeDecodeError
print 'non ascii string!' # on affiche le message 'non ascii string!'
Si vous exécutez ce bout de code, vous aurez bien évidement le message « non ascii string! ».
D’un point de vue logique, nous avons donc un morceau de code qui tente quelque chose, et un autre qui réagit en cas d’échec. Ce mécanisme porte un nom : la « gestion d’exception », et comme vous pouvez le constater en lisant la page Wikipédia, ce n’est pas un petit concept…
Je ne vais pas m’étendre sur le sujet, vous avez compris le principe. On ne va pas vous demander de fabriquer vos propres exceptions.
On va se contenter de s’appuyer là-dessus et essayer d’encoder tous les noms des nœuds de notre scène et regarder s’ils génèrent une erreur.
On prend les mêmes et on recommence.
Voici enfin la fonction renvoyant tous les nœuds disposant d’au moins un caractère non-ASCII :
def non_ascii_named_nodes():
result = []
for node in mc.ls('*'):
try:
node.encode('ascii')
except UnicodeDecodeError:
result.append(node)
return result
Avec ce que nous venons de voir plus haut, vous devriez être en mesure de comprendre tout seul, mais expliquons ça ligne à ligne.
result = []
On crée une liste qu’on va remplir dans la boucle for qui suit et qui va stocker les nœuds problématiques.
for node in mc.ls('*'):
On démarre la boucle qui va itérer sur chacun des nœuds de notre scène courante.
try:
node.encode('ascii')
On entre dans le bloc de gestion d’exception qui essaie de convertir le nom du nœud en ASCII…
except UnicodeDecodeError:
result.append(node)
Et la suite de la gestion d’exception qui « attrape » l’exception UnicodeDecodeError si elle se produit (indiquant un souci durant l’encodage en ASCII) et ajoute le nœud à la liste
return result
Et enfin, on renvoie la liste remplie des nœuds problématiques.
La version puriste
Oui, oui, je sais, je chipote mais pour pleins de bonnes raisons, le fait de créer une liste, de la remplir n’est pas une méthode particulièrement recommandée. Il vaut mieux passer par un générateur :
def non_ascii_named_nodes():
for node in mc.ls('*'):
try:
node.encode('ascii')
except UnicodeDecodeError:
yield node
Notez le yield à la dernière ligne.
Je ne vais pas vous expliquer ce que c’est car d’autres le font mieux que moi.
Avoir des noms de nœud simples et propres
Il peut être intéressant de limiter les caractères utilisables dans le nom de ses nœuds.
Pourquoi se limiter ? 
Cela permet d’éviter de se poser trop de questions.
Si, au lighting, on se rend compte qu’un nœud ne passe pas simplement parce que le graphiste a fait une faute d’orthographe (e.g. un accent aigu au lieu d’un accent grave), on peut légitimement se demander ce qu’apporte une multitude de caractères.
On pourrait se limiter :
- aux caractères alphabétiques minuscules (
abcdefghijklmnopqrstuvwxyz), - aux caractères alphabétiques majuscules (
ABCDEFGHIJKLMNOPQRSTUVWXYZ), - aux nombres (
0123456789), - aux tirets bas (
_).
On pourrait stocker tous ces caractères dans une variable :
valid_chars = 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789_'
Mais tant qu’à faire les choses biens, sachez que Python dispose déjà de quelques variables du genre dans le module string.
Faites :
import string
help(string)
Puis allez en bas. Vous aurez quelque chose comme :
DATA
ascii_letters = 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ'
ascii_lowercase = 'abcdefghijklmnopqrstuvwxyz'
ascii_uppercase = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
digits = '0123456789'
hexdigits = '0123456789abcdefABCDEF'
letters = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuv...\xcd\xce...
lowercase = 'abcdefghijklmnopqrstuvwxyz\x83\x9a\x9c\x9e\xaa\xb5\xba\xd...
octdigits = '01234567'
printable = '0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTU...
punctuation = '!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~'
uppercase = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ\x8a\x8c\x8e\x9f\xc0\xc1\xc2\xc...
whitespace = '\t\n\x0b\x0c\r '
En fait, le module string contient déjà des variables contenant les caractères de base. Et comme vous pouvez le constater, ascii_letters est en fait l’addition de ascii_lowercase et ascii_uppercase.
Ainsi, nous pouvons faire :
>>> string.ascii_letters + string.digits + '_'
'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789_'
En quoi est-ce mieux de faire ça plutôt que d’avoir une variable contenant déjà toute la chaîne ?
Parce qu’un code est aussi une intention.
À la lecture du code…
>>> string.ascii_letters + string.digits + '_'
…peut se traduire par les lettres ASCII + les numéros + tiret bas. À l’inverse…
'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789_'
…nécessite que vous lisiez le contenu de la variable pour savoir s’il y a en effet uniquement les lettres, les numéros, et un tiret bas.
Nous avons donc notre belle variable valid_chars contenant tous les caractères valides que nos nœuds peuvent avoir.
import string
valid_chars = string.ascii_letters + string.digits + '_'
Il ne manque plus qu’à vérifier que les caractères qui composent le nom des nœuds sont tous présent dans cette variable.
La vérification sur un nœud
Nous allons créer une fonction qui va nous indiquer si le nom qu’on lui passe est valide ou non.
Voici le bout de code dont nous allons discuter :
import string
valid_chars = string.ascii_letters + string.digits + '_'
def is_valid(node_name):
for char in node_name:
if char not in valid_chars:
return False
return True
La première partie :
import string
valid_chars = string.ascii_letters + string.digits + '_'
…vous la connaissez déjà.
Passons à la suite.
def is_valid(node_name):
On définit une fonction is_valid() qui prend un nom de nœud en argument et qui renverra True ou False suivant que le nom du nœud passe en argument est valide ou non.
for char in node_name:
C’est parti ! Ici, on rentre dans une boucle qui va itérer sur chacun des caractères de notre nœud ('p', 'S', 'p', 'h', etc.).
if char not in valid_chars:
Si le caractère n’est pas dans le paquet des caractères valides…
return False
…on renvoie False.
return True
Si on arrive à la fin de la boucle, c’est que le nom est valide, on renvoie donc True.
Vous pouvez essayer :
>>> print is_valid('pSphere')
True
>>> print is_valid('pSphère')
False
Comme vous pouvez le constater, un nom invalide renvoie False.
La même chose, mais sur plusieurs nœuds
C’est bien joli mais l’objectif de tout ça c’est quand même de vérifier les noms des nœuds de toute une scène pas vrai ?
Vous allez voir que c’est beaucoup plus facile maintenant que nous avons notre petite fonction is_valid().
for node_path in mc.ls('*', recursive=True, long=True):
node_name = node_path.split('|')[-1]
node_name = node_name.split(':')[-1]
if not is_valid(node_name):
print "Invalid name detected", node_name
Vous avez sûrement remarqué quelques bricolages.
Mais trêve de spéculations, sautons les deux pieds joints dans tout ça :
for node_path in mc.ls('*', recursive=True, long=True):
Ici, nous allons itérer à travers tous les nœuds de notre scène.
Pour rappel, l’argument recursive s’assure que l’expression (ici, '*') s’applique à l’intérieur de tous les namespaces de notre scène.
L’argument long donne le chemin complet vers un nœud. Or, nous ne souhaitons vérifier que son nom. Pourquoi, dans ce cas, utiliser le chemin complet ?
Bien vu !
La réponse est toute simple :
Une fois nos nœuds détectés, il faut bien que nous disposions d’un chemin complet pour pouvoir l’afficher. Si notre boucle affiche :
Invalid name detected pSphère
Vous serez bien embêté pour le retrouver dans votre scène pas vrai ?
node_name = node_path.split('|')[-1]
Ici, on utilise une petite technique pour s’assurer que justement, nous récupérons le nom du nœud.
Prenons un exemple :
>>> node_path = '|root|toto|head'
La première chose est de couper la chaîne de caractères au niveau du |, comme ceci:
>>> node_path.split('|')
['root', 'toto', 'head']
Puis nous récupérons le dernier élément de la liste via l’index [-1] qui, comme vous l’aurez deviné, prend le premier élément en partant de la fin de la liste.
>>> node_path.split('|')[-1]
'head'
On a bien récupéré le nom du nœud !
Continuons…
node_name = node_name.split(':')[-1]
Encore ?
Et non !
Regardez bien, cette fois ci c’est sur : que nous coupons.
Pourquoi ?
À cause des namespaces Maya pardi !
Si votre nœud est mis dans un namespace et se nomme 'toto_001:head', il faut bien couper au niveau du namespace et ne conserver que le nom (ici, 'head').
C’est donc le même mécanisme que pour le chemin, mais on coupe sur : au lieu de |.
if not is_valid(node_name):
Enfin ! Notre petite fonction !
Je ne vais pas vous détailler son fonctionnement, nous l’avons déjà fait précédemment.
La condition stipule que si le nom du nœud n’est pas valide, on entre dans le bloc de condition…
print "Invalid name detected", node_name
…qui ne fait qu’afficher le nom du nœud invalide.
Vous pouvez mettre toute ça dans une fonction et vous obtenez :
import string
valid_chars = string.ascii_letters + string.digits + '_'
def is_valid(node_name):
for char in node_name:
if char not in valid_chars:
return False
return True
def report_invalid_nodes():
for node_path in mc.ls('*', recursive=True, long=True):
node_name = node_path.split('|')[-1]
node_name = node_name.split(':')[-1]
if not is_valid(node_name):
print "Invalid name detected", node_name
Et voila, vous avez une jolie fonction qui vous liste tous les nœuds qui pourront vous sauter au visage plus tard.
Optimisation et concision
Je me suis retenu pour ne pas vous malmener, mais j’aimerais pousser un peu certains concepts.
Utiliser un set plutôt qu’une chaîne de caractère
Ce type de condition peut être très coûteux :
if truc in plein_de_trucs:
En effet, on va s’assurer que la variable truc est présente dans le paquet plein_de_trucs. On va donc comparer avec truc, chacun des éléments de plein_de_trucs, un à un.
Le morceau de code qui nous concerne est dans la fonction is_valid() :
if char not in valid_chars:
Je ne vais pas commencer un cours sur l’algorithmique mais, pour faire simple, plus plein_de_trucs (ou, dans notre cas, valid_chars) contient d’éléments, plus c’est lent.
Python est assez efficace de base, mais c’est une bonne pratique d’utiliser un set() pour stocker des éléments qu’on souhaite comparer régulièrement.
Ainsi, la variable valid_chars, originellement définie sous la forme :
valid_chars = string.ascii_letters + string.digits + '_'
Devient:
valid_chars = set(string.ascii_letters + string.digits + '_')
Sur mes tests, j’obtiens un joli 25 % de vitesse en plus.
Les générateurs
Autre concision possible, en utilisant des générateurs.
Ces deux fonctions font exactement la même chose :
def is_valid(node_name):
for char in node_name:
if char not in valid_chars:
return False
return True
def is_valid(node_name):
return all((c in valid_chars for c in node_name))
La première est écrite de manière traditionnelle, la seconde utilise un générateur, plus rapide et concis, combine à all() qui renvoie True si l’intégralité des éléments du générateur (ici, c in valid_chars) sont à True.
rename() pour renommer vos nœuds
C’est pas que ce tuto est un peu moisi du slip, mais là comme ça je dirais qu’on a toujours rien renommé…
Je sais, je sais, mais avouez qu’avant de renommer quelque chose, il était plus intéressant de savoir quoi.
Ici, on attaque la commande rename() (la documentation est ici). Vous allez voir qu’elle n’est pas compliquée.
Renommer un nœud
Comme vous vous en doutez, cette commande renomme le nœud que vous lui donnez :
mc.rename('noeud_a_renommer', 'nouveau nom')
Avouez que c’est simple.
Vous ne pouvez pas donner un nom vide, sinon Maya vous enverra bouler.
Notez que si le nouveau nom entre en conflit avec un nom existant, le nœud se verra attribué un nom unique en rapport avec le nom que vous souhaitiez lui donner (souvent, Maya ajoutera un chiffre derrière).
Partons de l’exemple :
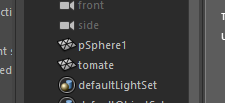
Si vous renommez pSphere1 en tomate comme ici :
mc.rename('pSphere1', 'tomate')
Vous obtenez :
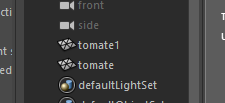
tomate1.D’une certaine façon, il est impossible d’être sûr que le nom que vous souhaitez donner est réellement celui que Maya va assigner au nœud.
Mais comment je peux être sûr que le nom créé par Maya est bien celui que je lui ai donne ? 
Les développeurs de Maya ont pensé à vous !
La fonction rename() renvoi le nom réel, tel que Maya l’a assigné :
vrai_nom = mc.rename('noeud_a_renommer', 'nouveau nom')
Dans notre exemple précédant, cela aurait donné :
real_name = mc.rename('pSphere1', 'tomate')
print real_name # 'tomate1'
Vous pouvez également ajouter un dièse # au nom pour indiquer à Maya que vous souhaitez ajouter un numéro :
print mc.rename('pSphere1', 'cerise#')
# 'cerise1'
Renommer la sélection
Sachez aussi que vous pouvez renommer le nœud sélectionné en ne passant qu’un seul argument à la fonction rename() :
mc.select('pSphere1')
mc.rename('tomate')
Je ne suis pas un fervent adepte de cette méthode. Beaucoup de commandes permettent d’agir selon la sélection mais cette approche peut rendre le code difficile à suivre, car il n’est jamais explicitement écrit ce qu’on cherche à faire. 
Mais vous êtes grand, faites ce qui vous semble le plus clair.
ignoreShape pour ne pas renommer la shape
Si vous utilisez Maya depuis un moment, vous aurez sûrement remarqué qu’il a tendance à essayer de renommer les nœuds de shape quand vous renommez le transform.
Prenons le nœud pSphere1:
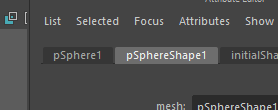
Renommez le nœud en toto :
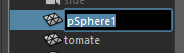
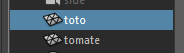
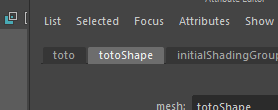
Par défaut, la commande rename() fonctionne également de cette façon.
Si vous annulez et que vous exécutez :
mc.rename('pSphere1', 'toto')
Vous remarquerez le même résultat :
Pourtant, la valeur renvoyée par la commande n’est que toto.
Donc Maya renomme encore des choses sans me le dire ?
Hé oui , mais comme vous l’aurez deviné, vous pouvez désactiver ce mécanisme via l’argument ignoreShape.
Annulez une dernière fois puis exécutez :
mc.rename('pSphere1', 'toto', ignoreShape=True)

shape n’est pas renomméHaha, il fait moins le malin !
Créer et modifier des namespaces
La commande rename() permet également de créer des namespaces et de déplacer des nœuds d’un namespace à l’autre, simplement en le renommant.
Si vous avez l’habitude de manipuler Maya, vous devriez savoir à quel point les namespaces peuvent être casse-pied. Je vous montre cette méthode pour que vous sachiez qu’elle existe. Mais il est peu probable que vous l’utilisiez souvent.
Reprenons notre exemple de départ:
Exécutez :
mc.rename('pSphere1', ':toto:tomate')
Notez qu’on ajoute les deux-points : en début de nom pour écrire le namespace absolu. Si on ne le fait pas, Maya lève une exception et refuse de crever le namespace:
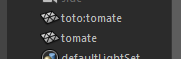
Maya a mis le nœud dans un namespace !
Exactement !
Ouvrez votre Namespace Editor et admirez :
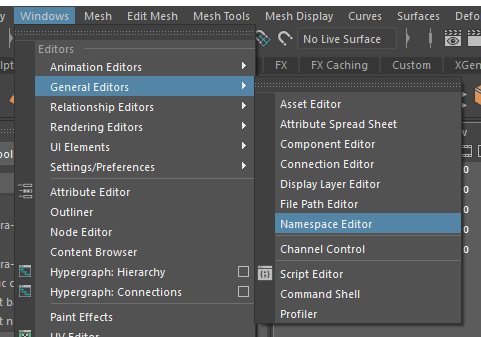
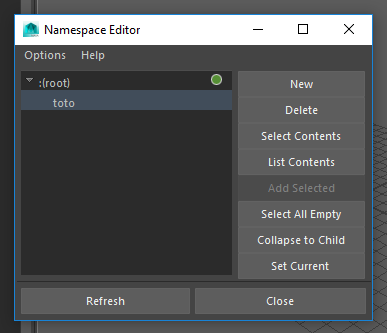
Et c’est pas fini, exécutez :
mc.rename('tomate', 'toto:cerise')
Tu as oublié de mettre les deux-points : !
Ah bon ?
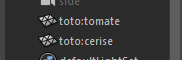
Mais, Maya n’a pas planté ?
Eh non ! C’est une des bizarreries de Maya. Accrochez-vous :
- quand vous mettez un deux-points
:devant le namespace, vous le passez en mode absolu et Maya va le créer ; - quand vous ne mettez pas les deux-points
:devant le namespace, vous le passez en mode relatif et Maya va : - l’ignorer s’il n’existe pas,
- l’utiliser s’il existe.
Ne vous inquiétez pas, comme je vous le disais, je voulais principalement vous faire savoir que vous pouviez créer et changer les nœuds de namespace via la commande rename(). Il est peu probable que vous n’ayez jamais à le faire donc pas de panique !
Une ch’tite boucle pour renommer des ch'tits nœuds...
Comme le nom de cette section le laisse présager, je vais vous présenter une petite boucle pour renommer votre sélection.
Nous allons renommer par rembourrage.
On va peut-être rester poli.
Vous n’en êtes peut-être pas familier, mais c’est le bon terme. Le terme qu’on utilise le plus souvent dans les logiciels 3D est son homologue anglais, padding, mais pour des raisons évidentes de COCORICO !!!, eh bien nous allons utiliser le terme rembourrage dans les explications.
Le principe est simple. Nous voulons renommer une sélection avec un modèle (pattern en anglais) qui ressemble à <nom du noeud><trois chiffres>. Un peu comme jointure_porte001, jointure_porte002.
Naïvement, on ferait ça :
i = 1
name = 'jointure_porte'
# parcours les noeuds de la selection
for node in mc.ls(selection=True, long=True):
# genere un nouveau nom
# 'jointure_porte' + '003'
new_name = name + str(i).zfill(3)
# et renomme le noeud avec son nouveau nom
mc.rename(node, new_name)
# et on incremente la valeur pour passer au suivant
i += 1
Pas vrai ?
La seule information qui peut vous manquer pour comprendre cette boucle c’est la méthode str.zfill() qui, comme son nom l’indique, remplit la string de zéros, je vous renvoie vers la documentation pour plus d’informations.
Ça sent le piège.
Eh bien testons.
Faites une chaîne de groupe (martelez Ctrl+g sur votre clavier), ouvrez la hiérarchie puis sélectionnez aléatoirement (c’est important ) des nœuds de la hiérarchie :
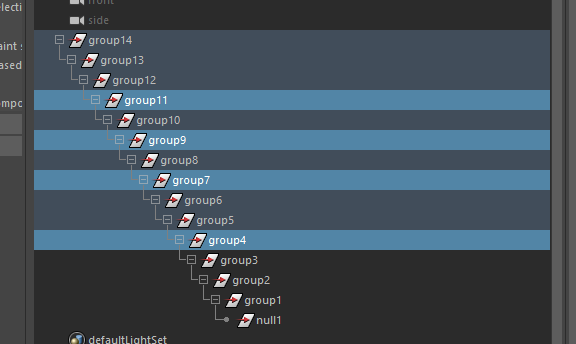
Puis exécutez le code !
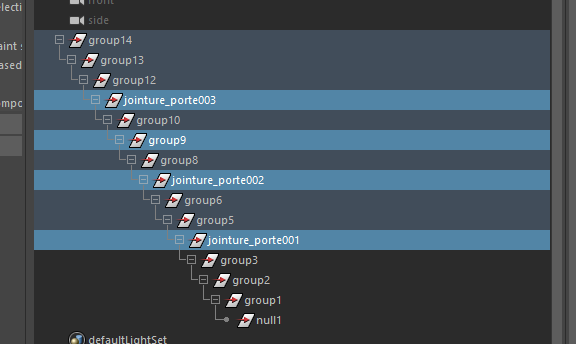
Si vous avez sélectionné de manière aléatoire, vous remarquerez que certains nœuds n’ont pas été renommés.
Mais si vous êtes bien vigilant, vous remarquerez que Maya a planté :

Ouvrons le Script Editor et regardons ça de plus près :
# Error: No object matches name
# Traceback (most recent call last):
# File "<maya console>", line 12, in <module>
# RuntimeError: No object matches name #
Ligne 12, c’est la ligne qui appelle la commande rename(), et le message semble indiquer qu’il ne trouve pas le nœud Maya à renommer.
Comment ça ce fait ?
C’est à vous de réfléchir un peu !
Rappelez-vous, j’ai insisté pour sélectionner de manière aléatoire les nœuds du groupe. L’idée était de s’assurer que l’ordre des nœuds n’était pas connu à l’avance.
Si votre sélection impose que la commande ls(selection=True, long=True) renvoie quelque chose comme ça :
['|group1|enfant1',
'|group1',
'|group1|enfant2']
À la première itération, c’est |group1|enfant1 qui va être renommé, donc pas de problème. À la seconde, on renomme |group1, une fois encore pas de problèmes.
Mais qu’arrive-t-il quand la commande va chercher à renommer |group1|enfant2 ? Hé bien il ne va pas réussir à y accéder, car on a renommé |group1| à l’itération précédente.
Le nœud |group1 n’existe plus !
Et c’est ce qui c’est la raison pour laquelle on ne peut pas prendre bêtement l’ordre de la sélection.
Mais comment peut-on faire ?
Comme souvent en programmation, il y a moultes façons d’arriver à un résultat. Je vais vous proposer ma solution qui, cela va de soi, est la meilleure de toute !
Remarquez comment il suffirait de trier les nœuds renvoyés par ls() pour commencer par le bas et remonter. Dans notre micro-exemple, la liste deviendrait :
['|group1|enfant2',
'|group1|enfant1',
'|group1']
Ha ! Je me rappelle mes super tutos Python et la fonction sorted() (plus d’informations ici).
C’est ça ! On va utiliser cette méthode avec son argument reverse pour… inverser le tri.
i = 1
name = 'jointure_porte'
for node in sorted(mc.ls(selection=True, long=True), reverse=True):
new_name = name + str(i).zfill(3)
mc.rename(node, new_name)
i += 1
Et le résultat :
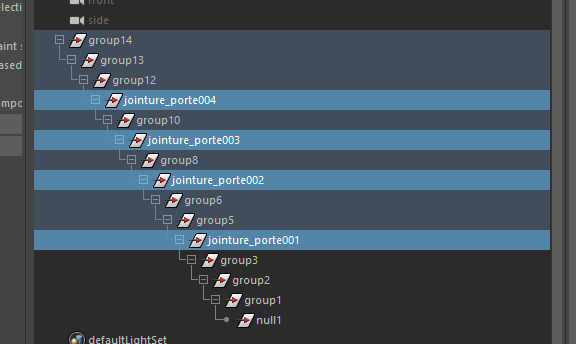
On pourrait s’arrêter là…
Mouais… Regarde, comme il a commencé par le bas, les noms sont numérotés du bas vers le haut, c’est tout nul.
Notez que j’ai dit on pourrait…
Ce qui me permet d’introduire le dernier exercice !
Ha ! Mais je disais rien moi.
Que nenni ! Vous allez le faire cet exercice !
Donc, on aimerait que la numérotation se fasse de bas en haut, mais la hiérarchie des nœuds nous impose de renommer de bas en haut… Comment se dépêtrer de tout ça ?
Je vais vous donner un indice : Il faut procéder en deux temps.
Allez ! Maintenant à vous de jouer ! Cherchez un peu et n’ouvrez la solution que quand vous avez fait quelques essais. Ce n’est que comme ça que vous assimilerez les concepts.
Ayez ? Vous avez trouvé cherché ? Voici le code :
i = 1
name = 'jointure_porte'
nodes = sorted(mc.ls(selection=True, long=True), reverse=True)
node_names = []
for node in nodes:
new_name = name + str(i).zfill(3)
node_names.append(new_name)
i += 1
node_names.reverse()
for node, node_name in zip(nodes, node_names):
mc.rename(node, node_name)
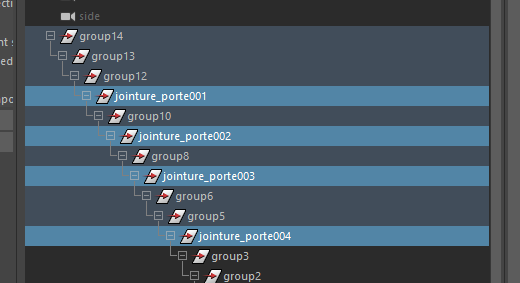
Je vous explique le code.
nodes = sorted(mc.ls(selection=True, long=True), reverse=True)
Dans la mesure où la boucle de renommage va s’exécuter deux fois, cette ligne stocke les nœuds à renommer, du bas vers le haut, tel qu’on l’a vu précédemment.
node_names = []
Ceci est la liste que nous allons remplir avec les noms générés, en vue de les inverser plus tard.
for node in nodes:
new_name = name + str(i).zfill(3)
node_names.append(new_name)
i += 1
Je mets la boucle en entier, j’suis un ouf !
Bon, le for in itère à travers les nœuds de la sélection inversée, générés précédemment.
Remarquez l’autre différence avec la boucle du premier exemple : on n’utilise plus directement rename() mais on stocke le new_name dans la liste node_names.
Arrivé à ce stade, on a deux listes :
nodescontenant les nœuds à renommer, dans le bon ordre.node_namescontenant les noms des nœuds, mais dans le mauvais ordre.
Il nous reste plus qu’à inverser la dernière liste pour s’assurer que les noms sont assignés du plus gros chiffre (en bas de la hiérarchie) au plus petit chiffre (vers le haut). C’est ce que nous faisons en utilisant la méthode list.reverse() (documentation ici).
node_names.reverse()
C’est peut-être à partir de là que votre code commence à se différencier du mien :
for node, node_name in zip(nodes, node_names):
Si vous ne comprenez pas cette ligne, vous avez sûrement raté une partie de votre tutoriel Python concernant les boucles.
La commande zip() (documentation ici permet d’itérer sur deux listes en même temps, en vous donnant chacun des éléments à la queue leu-leu : ['A', 'B', 'C', 'D'] et [1, 2, 3, 4] deviennent [('A', 1), ('B', 2), etc.
Les listes nodes et nodes_names faisant logiquement la même taille, la première contient les nœuds sources, à renommer, la seconde comprenant les noms à assigner.
On va vraiment s’arrêter là cette fois.
Mettez tout ça dans une fonction que vous pourrez utiliser quand bon vous semblera ou dans une petite interface.
Et voilà !
Vous avez vu que ce n’est pas si compliqué que ça.
Il y a pleins de nuances, de cas particuliers à gérer. Renommer des nœuds n’est pas une tâche dénuée de complexité, mais c’est un exercice motivant, car vous pouvez le pratiquer dans votre travail quotidien, et intéressant, car il permet d’apprendre à manipuler pas mal de concepts liés aux boucles.
Je vais vous laisser quelques pistes pour faire évoluer vos boucles de renommage :
- Creusez un peu le fonctionnement de la commande
ls()histoire de ne pas vous en tenir qu’à la sélection. - Utilisez
str.startswith()etstr.endswith()pour améliorer votre méthode de recherche de nœuds mal nommés. - Faites une boucle chercher et remplacer qui cherche un morceau du nom d’un nœud pour le modifier. Aidez-vous de la condition
'word' in namequi permet de trouver un mot dans une chaîne de caractères, puis utilisezstr.replace()pour remplacer ce mot. - N’oubliez pas
str.format()pour les noms un peu tarabiscotés. - Ras-le-bol de renommer ? Faites une petite interface pour présenter tout ça !
- etc.
Faites ce que vous voulez, mais prenez le contrôle sur votre travail et surtout, amusez-vous !