Si vous avez acheté un NAS, vous avez peut-être lu qu’il valait mieux acheter des disques durs « spécial NAS » pour mettre dedans. Mais pourquoi au fait ?
Parce que les mathématiques !
C’est moche, mais c’est la vérité.
En première approche…
Un NAS est plutôt utilisé pour du stockage de masse à long terme, donc sans besoin d’I/O par seconde élevées, et avec un débit max limité par le réseau – il existe des cas particuliers.
Donc on pourrait se dire que quitte à acheter, disons des disques de 4 To, autant prendre des disques à 5900 tours/minute à 120-130 € que des disques à 7200 tours/minute à 250-280 € pièce. Surtout pour en mettre plusieurs dans le même boitier : avec la tolérance de panne, il suffit de les remplacer s’ils lâchent, donc pas la peine de les prendre ultra-fiables.
Sauf que « les maths »
Une caractéristique presque inconnue des disques durs, c’est leur taux d’erreur incorrigible. Tous les n bits lus, il va y en avoir un que tous les systèmes internes au disque ne pourront pas corriger, et donc une lecture va planter (ça marche aussi avec les écritures)1.
Pour un disque dur de particulier, le constructeur donne en général n ≥ 1014 donc un taux d’erreur inférieur incorrigible inférieur à 10-14 par bit lu. C’est très fiable : un rapide calcul montre qu’un disque de 4 To (3,2 * 1013 bits) peut être statistiquement lu 3 fois en entier sans erreur – laquelle, pour un particulier, ne prête généralement pas à conséquence.
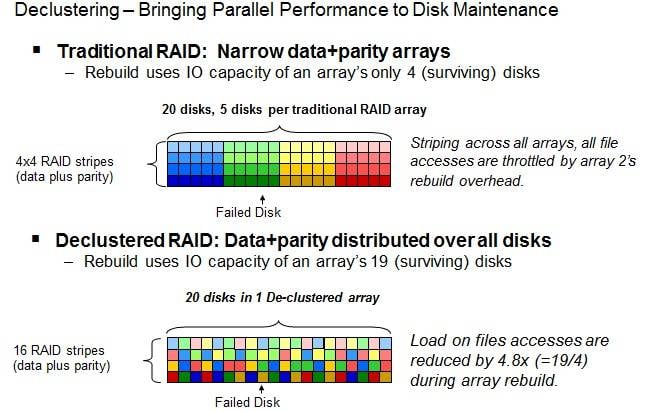
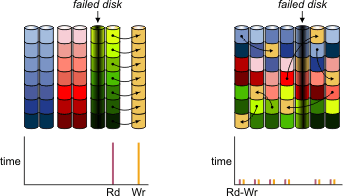
Mais on parle d’un NAS, avec des disques durs en RAID. Quand ce RAID tolérant aux pannes plante, on doit reconstruire les données du nouveau disque.
Le pire des cas, c’est le RAID 5 : la grappe peut contenir pas mal de disques, et comme il n’y a une tolérance d’un seul disque, une reconstruction implique de lire l’intégralité de tous les disques pour reconstruire le nouveau disque. Donc de lire ou écrire l’intégralité de tous les disques de la grappe.
La probabilité reconstruction d’une grappe RAID 5 est donc de :
Applications :
- Un « petit » RAID5 de 3 disques de 2 To (4 To utilisables) : 61,9 % de chances de reconstruction
- Un beau RAID5 de 5 disques de 4 To (16 To utilisables) : 20,2 % de chances de reconstruction
- Les 5 disques de 6 To (24 To utilisables) du club vidéo ou de l’entreprise ? Un disque dur mort et votre grappe est foutue (9 % de chances de renconstruction)
Oups.
Et une erreur au milieu d’une reconstruction RAID, c’est souvent l’opération complète à refaire — une opération qui dure des heures et qui sollicite beaucoup les disques, donc augmente leur risque de panne.
Les disques « spécial NAS »
Ces disques ont plein de petites différences mais surtout une meilleure résistance aux erreurs incorrigible : typiquement n = 1015, soit 10 fois mieux que les disques grand public.
Ce qui permet donc de reconstruire les grappes de disques (avec une probabilité de 95,3 %, 85,2 % et 78,7 % sur les 3 exemples précédents).
Si vous avez un NAS avec de la tolérance de pannes, vous devez probablement aussi investir dans des disques à haute résistance aux erreurs pour que cette tolérance de pannes soit réelle et pérenne.
-
En réalité c’est le secteur qui ne sera pas correctement lu/écrit, parce que le disque ne peut lire ou écrire qu’un secteur entier. D’où cette mention dans les specs. Mais ça ne change pas les calculs. ↩
C’est la dure loi des mathématiques et des grands nombres, où de grandes fiabilités sur des quantités de données gigantesques donnent une fiabilité globale parfois en-deçà de ce qui était imaginé.
À noter que :
- Ce sont des garanties constructeur, donc avec un peu de chance ça se passera bien. Tout comme on peut cramer un disque dur de bonne qualité, comme celui du boulot qui m’a fait penser à écrire ce billet. À vous de voir si vos données peuvent se permettre d’un coup de chance ou s’il vaut mieux investir.
- Les liens LDLC et Seagate ne sont là qu’à titre d’exemple (disques de la même marque disponibles sur le même site et dont les spécifications sont faciles à trouver, ce qui n’est pas si évident que ça). Je n’ai aucun contrat avec ces marques.