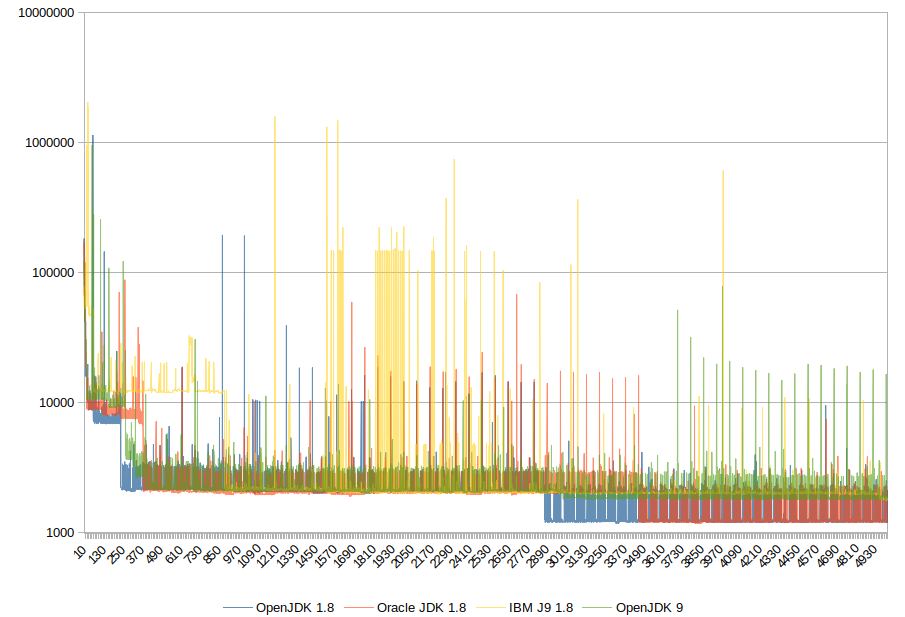
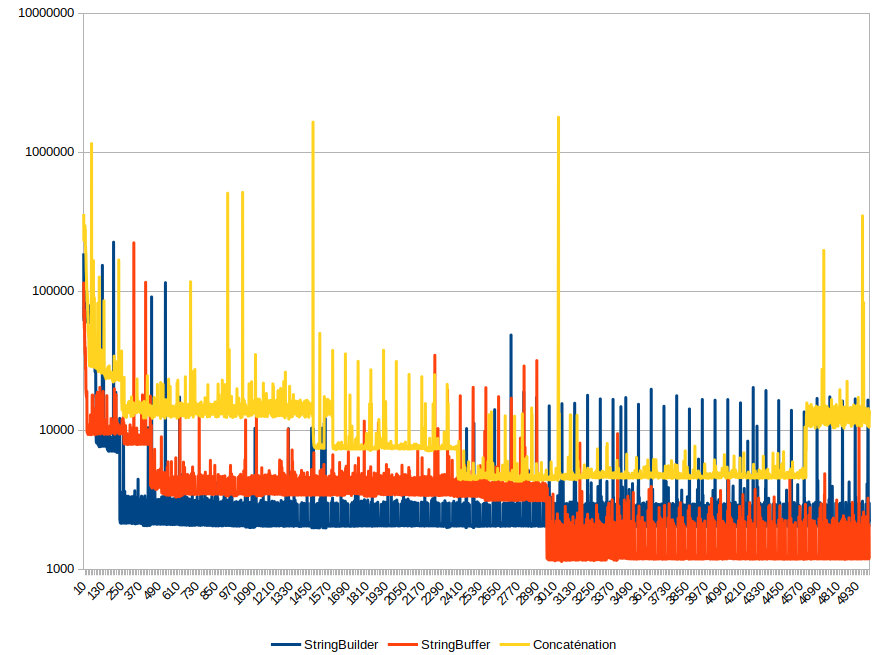
Imaginons que j’aie une méthode à optimiser. Par exemple – sans intérêt réel – cette fonction qui génère une chaîne de 100 caractères aléatoires :
1 2 3 4 5 6 7 8 9 10 11 | private static final Random RANDOM = new Random(); private static final char[] CHARS = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123465798".toCharArray(); private static final int ALPHABET_SIZE = CHARS.length; private static String functionToMeasure() { final StringBuilder sb = new StringBuilder(100); for (int i = 0; i < 100; i++) { sb.append(CHARS[RANDOM.nextInt(ALPHABET_SIZE)]); } return sb.toString(); } |
En admettant que je sais (par algorithmique, par mesures, etc.) que c’est cette fonctionnalité que je dois améliorer. Ou que cette fonction a plusieurs implémentations possibles (ici avec StringBuffer, StringBuilder ou des concaténation de chaines de caractères) que je dois comparer.
La question que je me pose est :
Comment assurer une mesure et une comparaison fiables ?
Eh bien mine de rien, il y a moyen de bien se planter juste avec une question d’apparence aussi simple !
Un micro-benchmark
Je fais un micro-benchmark pour vérifier comment cette fonction se comporte. Le code ne mesure que le temps d’exécution de la méthode, et on fait quelque chose du résultat pour être sûr qu’une optimisation ne va pas se contenter de ne pas exécuter la méthode, ce qui fausserait tout.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 | import java.util.Random; public class Test { private static final Random RANDOM = new Random(); private static final char[] CHARS = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123465798".toCharArray(); private static final int ALPHABET_SIZE = CHARS.length; private static final int LOOPS = 1; private static final long[] TIMES = new long[LOOPS]; public static void main(String... args) { String string; for (int i = 0; i < LOOPS; i++) { final long start = System.nanoTime(); string = functionToMeasure(); TIMES[i] = System.nanoTime() - start; System.out.println(string); } long totalTime = 0; for (long time : TIMES) { totalTime += time; } System.out.println(LOOPS + " loops in " + totalTime + " ns " + "--> " + (totalTime / LOOPS) + " ns/string, " + "throughput " + (LOOPS * 1_000_000_000L) / totalTime + " strings/s"); } private static String functionToMeasure() { final StringBuilder sb = new StringBuilder(100); for (int i = 0; i < 100; i++) { sb.append(CHARS[RANDOM.nextInt(ALPHABET_SIZE)]); } return sb.toString(); } } |
On commence par se demander combien de temps il faut pour exécuter une fois cette méthode :
1 | 1 loops in 97898 ns --> 97898 ns/string, throughput 10214 strings/s
|
Ça me paraît bien lent : seulement 10 000 générations par seconde en moyenne. Je m’attendais mieux de la part de Java.
Je suis sûr qu’on peut améliorer ça en ne modifiant qu’une seule ligne de code. Comment ?
Quand 1 + 1 ≠ 2 !
La réponse est très simple : il suffit de modifier le nombre de fois où on lance le test et donc de modifier la valeur à la ligne 9 !
Attends, tu ne te fouterais pas un peu de notre gueule là ? Si on lance le test 10 fois, on devrait avoir 10 fois le même résultat !
Et c’est vrai… si on lance 10 fois le même test dans 10 JVM différentes avec le même code, on a des petites variations mais le résultat est toujours le même, à peu de choses près.
Mais si on demande à une même JVM d’exécuter plusieurs fois la même méthode, ce qui se produira en réalité, les résultats ne sont plus les mêmes. Jugez plutôt :
1 2 3 4 5 6 7 | 1 loops in 95804 ns --> 95804 ns/string, throughput 10437 strings/s 10 loops in 806218 ns --> 80621 ns/string, throughput 12403 strings/s 100 loops in 1639395 ns --> 16393 ns/string, throughput 60998 strings/s 1000 loops in 5508983 ns --> 5508 ns/string, throughput 181521 strings/s 10000 loops in 17692767 ns --> 1769 ns/string, throughput 565202 strings/s 100000 loops in 131703629 ns --> 1317 ns/string, throughput 759280 strings/s 1000000 loops in 1155445070 ns --> 1155 ns/string, throughput 865467 strings/s |
Édifiant non ? On a pas loin d’un facteur 100 ! Mais pourquoi ?
Zyeutons ce qui se passe en détails…
Je modifie le système de tests pour enregistrer les temps d’exécution de chaque exécution :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 | import java.util.Random; public class Test { private static final Random RANDOM = new Random(); private static final char[] CHARS = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123465798".toCharArray(); private static final int ALPHABET_SIZE = CHARS.length; private static final int LOOPS = 5000; private static final long[] TIMES = new long[LOOPS]; public static void main(String... args) { String string; for (int i = 0; i < LOOPS; i++) { final long start = System.nanoTime(); string = functionToMeasure(); TIMES[i] = System.nanoTime() - start; System.out.println(string); } long totalTime = 0; System.out.println("Time list:"); for (int i = 0; i < LOOPS; i++) { long time = TIMES[i]; System.out.println(time); totalTime += time; } System.out.println(LOOPS + " loops in " + totalTime + " ns " + "--> " + (totalTime / LOOPS) + " ns/string, " + "throughput " + (LOOPS * 1_000_000_000L) / totalTime + " strings/s"); } private static String functionToMeasure() { final StringBuilder sb = new StringBuilder(100); for (int i = 0; i < 100; i++) { sb.append(CHARS[RANDOM.nextInt(ALPHABET_SIZE)]); } return sb.toString(); } } |
Si on trace les temps de réponse (échelle logarithmique !) en fonction du numéro de l’échantillon, on obtient ce genre de graphe :
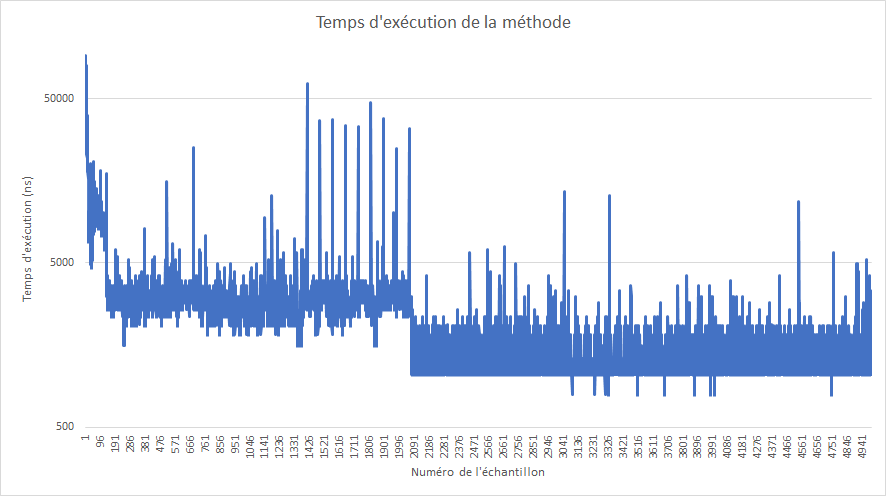
On y voit 4 plages de fonctionnement qui correspondent à 4 niveaux d’optimisation différents :
- Les toutes premières exécutions, très lentes (environ 90 000 ns).
- La première centaine d’exécutions tombe rapidement aux alentours de 10 000 - 20 000 ns, soit déjà un bon facteur 5, mais c’est assez instable.
- Ensuite, jusqu’à la 2000ème exécution, on oscille entre 2000 et 3000 ns, soit un facteur de près de 10.
- Cette méthode est vraiment très utilisée, elle est encore optimisée et tombe vers 1000 ns (en réalité, 80 % des échantillons sont à 1047 ns exactement, d’où ce « plat » sur le graphique et un débit théorique de 973 709 générations/seconde).
Tout ça correspond aux différentes passes d’optimisation de la JVM : on passe graduellement d’une méthode utilisée une fois donc entièrement interprétée, à une méthode identifiée comme critique pour le fonctionnement de l’application donc compilée et optimisée à fond par la JVM.
Ce petit exemple nous a montré que déterminer à priori les performances d’un bout de code d’un langage interprété par une JVM n’est pas du tout quelque chose de trivial. En effet :
- Il y a une compilation à la volée qui optimise le code le plus utilisé.
- Cette optimisation se fait en plusieurs étapes au fur et à mesure de l’utilisation de la méthode.
- Un micro-benchmark peut donc être parfaitement non représentatif de l’application finale.
- Rien de tout ceci n’est facilement visible avec des outils de traçage type YourKit.
- Attention à la représentativité des tests mais aussi aux métriques récoltées !
De même, si le but du test est de comparer plusieurs solutions, attention à ce que l’environnement soit comparable : si on lance des tests séquentiellement dans une même JVM, les derniers test seront avantagés par une optimisation préalable possible de certaines parties du code, et désavantagés par une pression mémoire plus importante, les deux ne se compensant probablement pas. Il vaut probablement mieux lancer une JVM séparée par élément à tester.
Une question intéressante serait de savoir comment se comportent d’autres machines virtuelles de langages face à ce genre de problématiques : une autre JVM (ici celle d’Oracle sous Windows, on pourrait se demander si la version Linux, OpenJDK, IBM J9 ou Android se comportent pareil), les langages .NET, Python… Si vous avez le courage de lancer ces tests, indiquez-le en commentaire !