
SpaceFox à t-il réellement écrit tous ces textes ?
Si je vous pose la question, vous vous doutez bien que la réponse n’est pas si simple.
Je me suis intéressé à la question d’un point d’un point de vue statistique, sans à priori sur les réponses, et les résultats que j’ai pu obtenir sont plutôt intéressants.
Vous n’aurez la réponse que lorsque vous aurez terminé de lire le billet.
- Notre cadre de travail
- Cherchons le style @SpaceFox
- Comparons les styles d’écriture
- La réponse à la grande question
- Que s’est-il passé ?
Notre cadre de travail
Comme vous le savez-tous, durant le mois d’octobre, SpaceFox s’est lancé un défi personnel, celui d'écrire trente et une nouvelles, à raison d’une par jour pendant tout le mois d’octobre.
En début novembre il à fait un retour d’expérience/bilan de celui-ci. Il racontait dans son bilan que l’expérience avait été plutôt positive.
Néanmoins, on peut se demander comment c’est possible pour un renard être humain normalement constitué, qui doit certainement avoir un boulot à plein temps de rédiger un texte différent tous les jours.
Deux réponses sont possibles :
- Il est fort … très fort
- Il triche !
C’est donc à la deuxième question, que nous allons tenter de répondre.
Pour répondre à cette question, nous allons essayer d’identifier le style d’écriture de @SpaceFox, puis comparer son style avec celui de ses textes produits et à partir de là, voir si le style est plutôt uniforme (il a gardé la même façon d’écrire) ou toujours différents (il a essayé de se renouveler chaque jour), ou les deux.
Cherchons le style @SpaceFox
Pour information, nous nous basons sur ses textes qui sont disponibles sur son site internet.

Pour trouver son style, nous allons, pour chacun de ses textes identifier les propriétés de chacun de ces textes. Pour cela, nous allons calculer plusieurs éléments :
- Le nombre de mots dans le texte
- Le nombre de verbes, noms, adverbes, … utilisés dans le texte
- La taille moyenne des mots d’une phrase
On va s’aider d’une bibliothèque de traitement automatique du langage naturel entrainée sur des modèles de la langue française pour faire le travail de parsing du texte. On va donc séparer les phrases, faire de l’analyse lexicale, détecter la nature des mots, et calculer les indicateurs ci-dessus.
On obtient donc le tableau suivant :
Afficher/Masquer le contenu masqué| Numéro du texte | AVG_WORD_SIZE | COUNT_WORD | A | ADJ | ADJWH | ADV | ADVWH | C | CC | CL | CLO | CLR | CLS | CS | DET | DETWH | ET | I | N | NC | NPP | P | PREF | PRO | PROREL | PROWH | PUNC | V | VIMP | VINF | VPP | VPR | VS |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 3.992 | 658 | 0 | 55 | 0 | 28 | 0 | 3 | 15 | 0 | 4 | 10 | 18 | 7 | 114 | 0 | 3 | 2 | 17 | 122 | 5 | 89 | 0 | 6 | 7 | 0 | 75 | 53 | 0 | 14 | 9 | 2 | 0 |
| 2 | 3.970 | 955 | 0 | 62 | 1 | 74 | 1 | 4 | 29 | 3 | 12 | 17 | 47 | 19 | 135 | 0 | 0 | 0 | 15 | 136 | 6 | 104 | 0 | 17 | 12 | 4 | 120 | 90 | 0 | 30 | 12 | 5 | 0 |
| 3 | 3.938 | 1060 | 0 | 56 | 1 | 67 | 0 | 4 | 26 | 0 | 16 | 11 | 37 | 14 | 163 | 2 | 0 | 3 | 9 | 185 | 15 | 122 | 0 | 12 | 17 | 2 | 133 | 97 | 0 | 19 | 44 | 4 | 1 |
| 4 | 4.070 | 962 | 0 | 68 | 0 | 47 | 0 | 3 | 24 | 4 | 13 | 12 | 31 | 9 | 149 | 1 | 3 | 2 | 8 | 175 | 7 | 112 | 0 | 18 | 9 | 1 | 130 | 92 | 0 | 14 | 28 | 2 | 0 |
| 5 | 3.666 | 712 | 0 | 64 | 0 | 25 | 0 | 0 | 15 | 1 | 2 | 5 | 10 | 2 | 142 | 0 | 0 | 0 | 34 | 116 | 25 | 101 | 0 | 1 | 5 | 0 | 93 | 30 | 0 | 9 | 28 | 4 | 0 |
| 6 | 4.078 | 663 | 0 | 41 | 1 | 33 | 1 | 1 | 13 | 2 | 6 | 10 | 37 | 17 | 99 | 0 | 0 | 3 | 21 | 108 | 10 | 68 | 0 | 10 | 6 | 1 | 86 | 62 | 0 | 12 | 12 | 1 | 2 |
| 7 | 3.855 | 1070 | 0 | 63 | 2 | 85 | 2 | 2 | 29 | 8 | 14 | 22 | 55 | 11 | 156 | 0 | 1 | 3 | 16 | 145 | 13 | 112 | 0 | 13 | 10 | 1 | 143 | 106 | 0 | 25 | 27 | 5 | 1 |
| 8 | 3.952 | 1518 | 0 | 108 | 0 | 74 | 3 | 1 | 44 | 0 | 18 | 18 | 63 | 21 | 236 | 0 | 0 | 2 | 23 | 258 | 14 | 184 | 0 | 15 | 15 | 1 | 206 | 132 | 1 | 35 | 40 | 4 | 2 |
| 9 | 3.581 | 1268 | 0 | 69 | 0 | 71 | 2 | 3 | 27 | 4 | 23 | 14 | 77 | 10 | 174 | 0 | 2 | 4 | 20 | 168 | 42 | 129 | 0 | 23 | 14 | 1 | 188 | 138 | 1 | 30 | 30 | 2 | 2 |
| 10 | 4.089 | 949 | 0 | 71 | 0 | 57 | 1 | 2 | 25 | 2 | 9 | 9 | 37 | 9 | 154 | 1 | 0 | 1 | 7 | 162 | 9 | 110 | 0 | 17 | 9 | 1 | 124 | 84 | 1 | 22 | 24 | 1 | 0 |
| 11 | 3.924 | 1202 | 0 | 75 | 0 | 79 | 4 | 9 | 46 | 2 | 16 | 30 | 57 | 17 | 165 | 0 | 1 | 2 | 23 | 161 | 4 | 127 | 0 | 16 | 13 | 0 | 145 | 119 | 0 | 48 | 39 | 3 | 1 |
| 12 | 3.493 | 942 | 0 | 67 | 2 | 63 | 0 | 4 | 28 | 2 | 12 | 10 | 53 | 5 | 123 | 0 | 0 | 2 | 17 | 122 | 17 | 93 | 0 | 21 | 14 | 1 | 148 | 92 | 1 | 21 | 18 | 3 | 3 |
| 13 | 3.905 | 423 | 0 | 37 | 0 | 19 | 0 | 0 | 15 | 2 | 8 | 3 | 18 | 6 | 61 | 0 | 1 | 0 | 6 | 62 | 0 | 42 | 0 | 8 | 6 | 0 | 58 | 41 | 0 | 19 | 10 | 0 | 1 |
| 14 | 3.980 | 1187 | 0 | 89 | 0 | 60 | 4 | 4 | 31 | 5 | 21 | 9 | 58 | 20 | 173 | 0 | 1 | 3 | 22 | 174 | 8 | 124 | 0 | 25 | 28 | 1 | 153 | 107 | 3 | 28 | 33 | 3 | 0 |
| 15 | 3.699 | 1147 | 0 | 81 | 0 | 70 | 0 | 1 | 40 | 6 | 22 | 6 | 58 | 13 | 171 | 1 | 1 | 1 | 15 | 167 | 7 | 130 | 0 | 29 | 18 | 1 | 151 | 105 | 5 | 20 | 19 | 1 | 8 |
| 16 | 4.385 | 712 | 0 | 61 | 1 | 40 | 0 | 5 | 26 | 2 | 5 | 6 | 15 | 4 | 107 | 0 | 0 | 0 | 12 | 129 | 15 | 87 | 0 | 9 | 6 | 2 | 83 | 57 | 0 | 14 | 22 | 4 | 0 |
| 17 | 3.916 | 795 | 0 | 46 | 0 | 40 | 1 | 1 | 38 | 0 | 18 | 6 | 29 | 8 | 130 | 0 | 1 | 0 | 4 | 132 | 28 | 99 | 0 | 8 | 10 | 0 | 94 | 68 | 1 | 10 | 19 | 4 | 0 |
| 18 | 3.864 | 701 | 0 | 54 | 0 | 29 | 1 | 3 | 21 | 1 | 3 | 8 | 30 | 12 | 119 | 0 | 0 | 0 | 8 | 129 | 1 | 92 | 0 | 3 | 5 | 0 | 87 | 59 | 2 | 17 | 14 | 3 | 0 |
| 19 | 3.928 | 447 | 0 | 54 | 0 | 26 | 0 | 0 | 13 | 0 | 1 | 2 | 3 | 4 | 78 | 0 | 0 | 0 | 17 | 80 | 3 | 62 | 0 | 5 | 3 | 0 | 61 | 18 | 0 | 6 | 11 | 0 | 0 |
| 20 | 4.534 | 704 | 0 | 69 | 1 | 30 | 0 | 0 | 21 | 0 | 2 | 4 | 3 | 5 | 140 | 1 | 0 | 0 | 16 | 130 | 26 | 105 | 0 | 6 | 13 | 0 | 68 | 36 | 3 | 4 | 19 | 1 | 1 |
| 21 | 3.742 | 457 | 0 | 34 | 0 | 36 | 0 | 5 | 16 | 1 | 6 | 4 | 25 | 4 | 58 | 0 | 0 | 0 | 5 | 61 | 3 | 45 | 0 | 10 | 7 | 0 | 63 | 56 | 0 | 7 | 8 | 3 | 0 |
| 22 | 4.337 | 449 | 0 | 47 | 0 | 21 | 0 | 0 | 24 | 0 | 5 | 8 | 12 | 4 | 59 | 0 | 0 | 1 | 9 | 69 | 11 | 55 | 0 | 1 | 4 | 0 | 63 | 38 | 0 | 11 | 7 | 0 | 0 |
| 23 | 4.035 | 603 | 0 | 51 | 0 | 22 | 0 | 0 | 21 | 1 | 4 | 13 | 13 | 5 | 103 | 0 | 0 | 1 | 6 | 107 | 13 | 78 | 0 | 4 | 5 | 0 | 81 | 48 | 0 | 8 | 18 | 1 | 0 |
| 24 | 3.560 | 812 | 0 | 43 | 0 | 33 | 0 | 4 | 26 | 2 | 26 | 13 | 44 | 9 | 110 | 0 | 1 | 0 | 10 | 113 | 9 | 92 | 0 | 11 | 9 | 0 | 123 | 87 | 1 | 17 | 22 | 4 | 3 |
| 25 | 4.011 | 651 | 0 | 43 | 0 | 46 | 0 | 2 | 10 | 3 | 8 | 3 | 33 | 8 | 91 | 1 | 0 | 4 | 9 | 101 | 9 | 75 | 0 | 9 | 3 | 0 | 96 | 56 | 2 | 23 | 13 | 1 | 2 |
| 26 | 3.052 | 159 | 0 | 4 | 0 | 12 | 0 | 1 | 1 | 1 | 3 | 1 | 11 | 3 | 26 | 0 | 0 | 0 | 0 | 24 | 1 | 15 | 0 | 2 | 1 | 1 | 26 | 21 | 0 | 0 | 4 | 1 | 0 |
| 27 | 3.581 | 1337 | 0 | 76 | 0 | 115 | 2 | 8 | 44 | 3 | 36 | 8 | 121 | 27 | 148 | 0 | 1 | 2 | 13 | 153 | 18 | 112 | 0 | 31 | 15 | 6 | 182 | 155 | 0 | 27 | 28 | 3 | 3 |
| 28 | 3.953 | 1825 | 0 | 134 | 2 | 159 | 1 | 25 | 74 | 0 | 35 | 20 | 111 | 45 | 227 | 1 | 0 | 1 | 26 | 242 | 2 | 198 | 0 | 23 | 36 | 0 | 161 | 167 | 0 | 60 | 63 | 2 | 10 |
| 29 | 3.524 | 712 | 0 | 41 | 0 | 41 | 3 | 2 | 22 | 2 | 7 | 7 | 32 | 10 | 104 | 0 | 0 | 7 | 9 | 93 | 11 | 67 | 0 | 27 | 3 | 1 | 105 | 67 | 2 | 29 | 16 | 2 | 2 |
| 30 | 3.590 | 409 | 0 | 18 | 0 | 24 | 0 | 2 | 13 | 1 | 3 | 4 | 17 | 3 | 74 | 0 | 0 | 0 | 14 | 65 | 10 | 46 | 0 | 6 | 5 | 0 | 53 | 35 | 1 | 6 | 8 | 0 | 1 |
| 31 | 4.211 | 469 | 0 | 35 | 0 | 41 | 1 | 4 | 19 | 0 | 11 | 8 | 13 | 7 | 60 | 0 | 0 | 1 | 9 | 69 | 5 | 46 | 0 | 12 | 8 | 0 | 55 | 46 | 0 | 9 | 9 | 0 | 1 |
Pour chaque texte (les lignes de notre tableau), on a les différentes caractéristiques.
Il ne nous reste plus qu’à analyser ces résultats pour comprendre si elle se ressemble ou au contraire elles n’ont rien à voir.
Comparons les styles d’écriture
Statistiquement, nous sommes ici en possession de données avec des variables continues, qui ont été normalisées. On peut procéder à une analyse en composantes principales pour visualiser ces résultats sur deux dimensions, afin de juger par nos propres yeux (l’œil humain voit mieux en 2D qu’en 33D) si les textes de @SpaceFox suivent un style particulier.
Attention, l’ACP se contente de recréer 2 dimensions à partir de nos 33 dimensions, en s’assurant que les deux dimensions nouvelles gardent le plus d’information possible.
Pour cela, on va utiliser la bibliothèque scikit-learn couplée à pandas de python pour procéder à cette ACP. Mon code ressemble donc à ceci :
import pandas as pd
from sklearn.decomposition import PCA
from sklearn.preprocessing import normalize
df = pd.read_csv('results.csv')
pca = PCA(n_components=2) # une ACP sur deux dimensions
pca.fit(df)
# notre ACP suit une loi normale
PCA(copy=True, n_components=2, whiten=False)
existing_2d = pca.transform(df)
existing_df_2d = pd.DataFrame(existing_2d)
existing_df_2d.index = df.index
existing_df_2d.columns = ['PC1','PC2']
existing_df_2d.head()
print(pca.explained_variance_ratio_)
Le résultat de ce morceau de code donne :
[0.98615272 0.00731169]
Ce qui nous dit que notre ACP a réussi à créer deux dimensions, dont la première (PC1) porte 98,6 % de l’information de notre tableau.
Autrement dit, la projection sur deux dimensions sera plutôt fidèle. On a perdu très peu d’information.
La réponse à la grande question
Trêve de plaisanterie, est-ce que tu peux nous dire quelle est la réponse ?
Observons les résultats ensemble :
Résultat de l’ACP (Afficher/Masquer)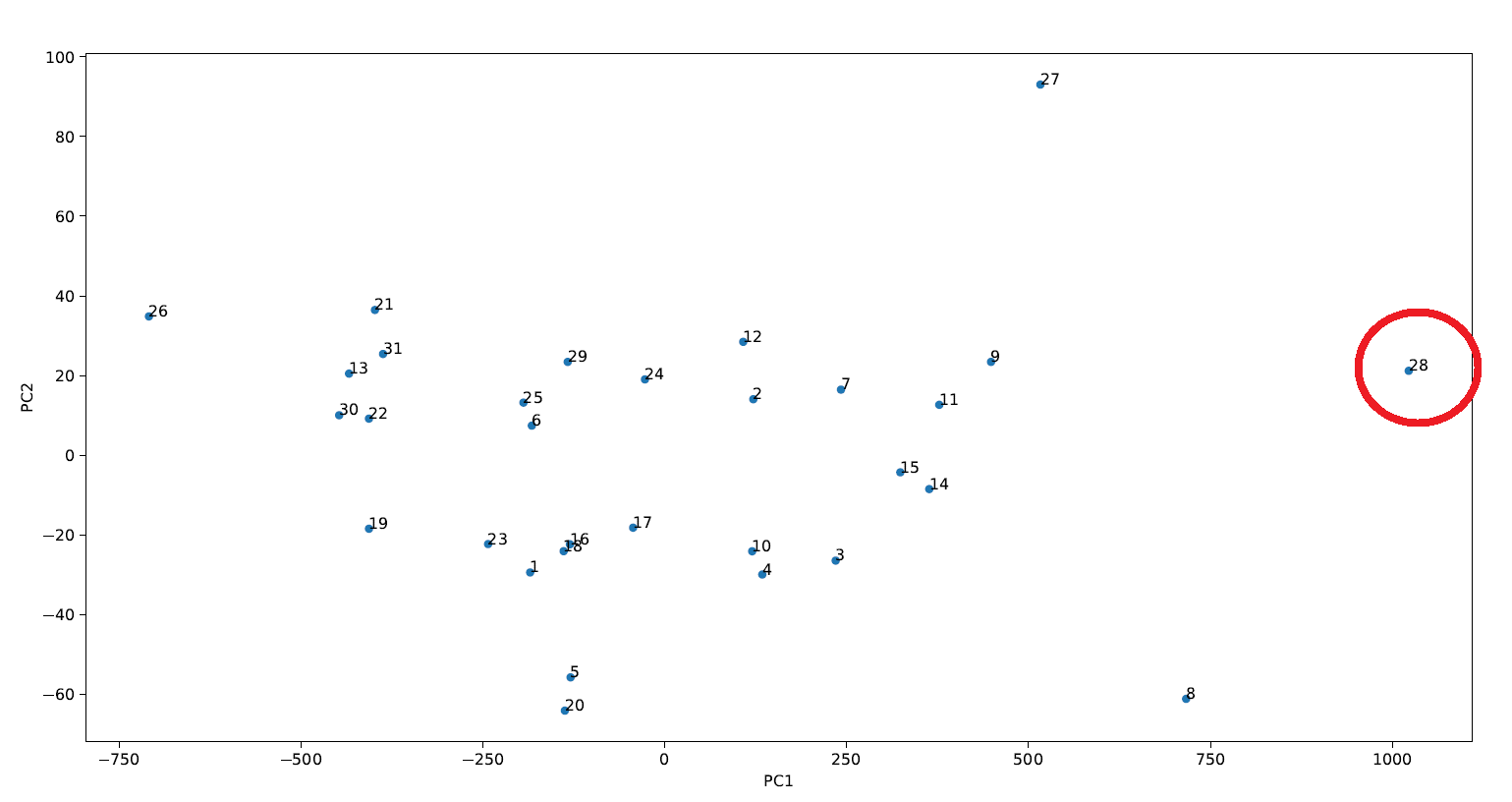
Ce que l’on observe ici c’est que (souvenez-vous que l’axe qui porte le plus d’information est l’axe PC1, celui des abscisses): Le texte N°28 est très différent des autres du point de vue de son style d’écriture.
C’est étonnant, très étonnant.
Ce détachement ne semble pas lié à la longueur du texte, car même après l’application d’une opération de centrage et réduction des données, on retrouve toujours ce texte en électron libre.
Que s’est-il passé ?
Si on remonte quelques semaines plus tôt, le jour de la publication de ce texte, l’auteur @SpaceFox déclarait :
Je ne vous ai pas oubliés, et je compte bien terminer les 31 textes ! Celui du 28 est à la fois le plus long et celui qui a été le plus difficile à écrire, en plus d’être la suite directe du précédent. Place à Le secret le plus intime !
Pourquoi l’auteur déclare-t-il que ce texte a été le plus difficile à écrire ? Tout porte à croire que ce texte n’a pas été écrit comme les autres, ni par la même personne.
J’ai ma petite idée, mais je laisse l’auteur ou quelqu’un d’autre qui a compris le stratagème nous expliquer tout ça de lui-même.















 .
.