- Un Chromebook, Chrome OS, pourquoi ?
- La première Ariane 5 n'a pas explosé à cause d'un bug informatique
Il y a peu, @spacefox a écrit un billet Git: La GUI est votre amie qui est loin d’être passée inaperçu à en juger le nombre de commentaires mais aussi les statistiques publiées dans le récap communautaire d’avril.
Je voulais ajouter un commentaire à ce billet mais au fur et à mesure que je l’écrivais j’ai constaté deux choses : il était très long et à la fin il manquait de structure.
Du coup je vais transformer le commentaire en billet, un peu plus structuré.
La question qui me turlupine et qui a été posée tant dans le billet de @spacefox que dans les commentaire c’est :
Est-ce qu’on comprend mieux ce qu’on fait quand on utilise la GUI (resp la CLI)?
- Quel outil pour Git?
- Anecdote 1 : let's stash clem'
- Anecdote 2: All your rebase are belong to us
- Les GUI que j'ai utilisé
Quel outil pour Git?
D’où l’on vient
J’ai appris à utiliser Git car j’ai voulu participer au projet Atoum créé par @mageekguy. A cette époque j’étais en 2ème année d’ingénieure et je ne connaissais qu’un seul système de gestion de version : SVN.
Lorsque je fus accueillie sur github avec des demande style "fais un rebase" ou "tire la branche de dev plutôt que master" j’étais totalement perdu ! On peut le dire : je ne comprenais pas ce que je faisais.
A cette époque j’utilisais deux outils :
- le plugin Git de Netbeans pour faire du put, du pull et des branches
- la CLI pour copier/coller des commandes qu’on me disait de faire.
Où l’on est
Puis le temps a un peu passé, et zeste de savoir a même commencé son développement et là j’ai commencé à apprendre à utiliser git. Mieux, au détour d’un autre projet étudiant, un enseignant m’a invité à regarder le fonctionnement théorique de git pour le comprendre. Voir que c’était un système de fichier à part entière, ce qu’était un commit, pourquoi on avait la commande reset et la commande revert.
Comme cela a une importance pour la suite du billet, on peut aussi noter que c’est là que j’ai appris la notion d’état "unstash", "stashed" et "committed". Même si je ne saisissais pas bien l’intérêt dans la vie de tous les jours : mes recherches se concentraient sur l’aspect théorique de git.
Notons que c’est là que j’ai vraiment compris ce que signifiait "git est décentralisé" et ce qu’était un "repo git". Les tuto qui t’expédient ça en mode "tu as le dépôt distant et le dépôt local" ne sont pas incorrects, mais ils ne te présentent pas vraiment la puissance et l’élégance de la chose du coup tu ne pige pas qu’il faut retenir le concept.
A partir de là j’ai une utilisation de git qui est vraiment très hybride :
- pour merger => GUI (que ça soit meld quand j’ai rien ou l’interface jetbrains, faut comprendre qu’à la base j’avais installé intellij sur mon poste pro à côté d’éclipse juste pour la partie Git)
- gérer les fichiers à inclure ou pas dans un commit => GUI, ça parraît con comme ça, mais le résultat en terminal de
git statusn’est pas réellement lisible dans la vie de tous les jours où tu dois faire des refacto - faire un rebase intéractif ou non => CLI
- toutes les autres opérations courantes => le premier outil que j’ai sous la main
Où l’on va
J’ai eu du mal à bien écrire la partie "où l’on est" car je suis nettement en train d’abandonner la CLI à cause de l’ergonomie de pycharm et IntelliJ qui me permettent de faire mieux, plus rapidement et en réduisant le nombre d’erreurs.
Cet aspect est précisément ce qui a déclenché l’écriture de ce billet et il se cristalise dans les deux anecdotes qui vont suivre.
Anecdote 1 : let's stash clem'
La première des anecdotes est un cas où j’ai découvert une fonctionnalité de git par la ligne de commande, mais que je ne l’ai vraiment comprise que plus tard grâce à l’utilisation d’une GUI.
L’histoire se déroule alors que @cepus gère le déploiement de zeste de savoir sur la béta. Il se rend compte qu’il y a un gros problème depuis notre dernier update d’un outil : notre connexion à la bdd ne se fait plus.
Problème : en local, même avec une stack identique à la béta, ça passe. D’ailleurs ça passe aussi sur notre CI.
Commence alors une investigation qui se termine par la modification directe sur le serveur de béta d’un fichier de code python pour rendre fonctionnelle notre connexion. S’en suit une PR, qui est mergée et cepus le lendemain cepus tente de faire le déploiement de la nouvelle version.
Et là, git nous dit qu’il y a des conflits qu’on ne peut pas tirer la branche sur le github et qu’il faut commiter les changements.
Sachant qu’une PR avait été faite pour pousser les changements utiles, je dis à cepus "aller, git reset --hard et on pourra tirer la branche.
Cepus me répond alors qu’il est préférable de simplement faire git stash pour ne pas perdre mes modifications et passer à la suite.
Là je suis perdu, je ne vois pas comment on peut avoir les deux à la fois sans faire un commit. Mais la commande, de manière assez magique, fonctionne : le dépôt revient dans le même état que si j’avais fait un commit et avec une commande que je ne connais pas, vhf arrive à me fournir à la volée le patch à appliquer si ça marche toujours pas.
Et pendant deux ans, cette expérience me laissera perplexe.
Jusqu’à ce qu’IntelliJ mette à jour son interface de "stash/unstash" (je ne sais plus quelle version était impactée) et fasse un article sur la manière d’utiliser cette fonctionnalité.
Pour info c’est Clic droit > git > repository > stash changes (ou unstash changes).
On a déjà une première info : un stash agit au niveau du dépôt et il a une opération inverse (unstash), d’un coup tout paraît moins magique.
Mais le gros truc qui a rendu tout clair dans mon esprit c’est le petit prompt qui s’ouvre alors :
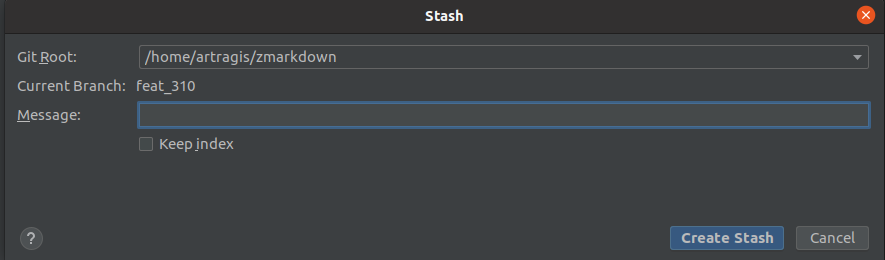
Ce prompt a un avantage clair et net : il me donne un contexte (le dépôt et la branche) ainsi que la possibilité d’entrer un message. Et là tout est clair on est dans une sorte de pseudo commit qui va faire tout le boulot du commit MAIS ne va pas s’intégrer à l’historique.
Et un coup d’oeil à Unstash Changes t’aidera à comprendre l’impact de tes actions. Et comme tu as été plus ou moins obligé d’entrer un message, au moment de faire ton "unstash" tu sais ce que tu vas appliquer. Au pire la GUI te permet d’avoir un petit diff en preview.
En fait ce que je retiens de cette anecdote c’est qu’une GUI a une logique de navigation là où une CLI a une logique à plat. La logique de navigation ajoute un contexte qui facilite la compréhension MAIS elle peut parfois rendre lourd le fonctionnement de la fonctionnalité.
Cette logique de navigation peut paraître magique à une personne qui a l’habitude de configurer l’exécution de sa ligne de commande avec les options qui vont bien mais utiliser une GUI n’empêche pas de comprendre les concept, au contraire, en donnant du contexte elle facilite l’autonomisation.
Anecdote 2: All your rebase are belong to us
Ah le rebase, c’est la seule opération qui m’a très longtemps bloqué sur la CLI car j’avais cette impression de comprendre ce que ça faisait quand on était en CLI alors qu’en fait c’était juste que j’avais déjà compris le concept de base et que du coup je n’utilisais que les formes les plus simples de la commande.
C’est encore sur zds que le noeud du problème se posera, et encore une fois il faudra un laps de temps conséquent pour que la GUI apporte un intérêt.
Or donc, nous sommes en plein développement des tribunes. Gustavi a galéré comme un dingue et m’a refilé le bébé. D’autres membres viennent alors m’aider. Mais voilà, un gros fix sur le module de tuto vient d’avoir lieu qui touche profondément au code de la publication. Et les tribunes, ça touche aussi énormément à ce code. Il faut rebaser.
Je commence à faire ma petite commande git rebase upstream/dev et là… c’est horrible.
Conflits de partout, impossible de savoir comment je dois appliquer les différences les unes par rapport aux autres, je passe 3 heures et à la fin ça bug.
Un développeur de zds (je ne sais plus qui, désolé, si tu te reconnais, bah voilà c’est de toi que je parle) me vient alors en aide et après une dizaines de minutes d’analyse de l’historique git me balance une commande imbitable qui ressemble un peu à git rebase --onto sha-commit1 sha-commit2. Je lance la commande et… là les conflits deviennent tellement faciles à résoudre que je n’y passe que 10 minutes et ça plante pas.
Cette commande était magique, et je vais passer pas mal de temps à essayer de comprendre :
- comment elle a fonctionné;
- comment je pourrais moi-même faire une telle commande plus tard.
Je pense qu’aujourd’hui j’en serais capable, mais je ne suis pas très confiant notamment sur l’ordre des commits en argument, et au pire j’ai pas souvent besoin de ça.
Sauf qu’après l’article de @spacefox, j’ai été pris de curiosité et j’ai été voir comment on pouvait faire un rebase sur pycharm/IntelliJ (c’est jouissif).
Et là on a un prompt, qui nous présente trois paramètres :
- commit to rebase onto
- commit to rebase from
- interractive (essayez le rebase interactif avec pycharm, c’est juste énorme, vous allez abandonner vim après ça)
Et chacun de ces éléments a un tooltip d’aide qui t’explique très bien à quoi ça sert. Le manuel de la commande man est pourtant très complet, mais justement il est tellement complet qu’on s’y perd.
Alors oui, aujourd’hui je sais à quoi sert "commit to rebase from", je sais prévoir le résultat qu’il aura, et je sais pourquoi je n’en ai pas besoin au jour le jour. Et l’usage base que de git rebase upstream/dev que j’avais me masquait tout ça.
Cette anecdote là montre qu’on peut tout à fait ne pas comprendre ce qu’on fait avec une CLI, que la GUI peut (et c’est loin d’être systématique) présenter les informations d’une manière qui la rend bien plus compréhensible.
Les GUI que j'ai utilisé
- Le plugin netbeans => très lourd, et fait beaucoup de choses bloquantes, mais bon netbeans c’est un peu vieux comme IDE
- Turtoise Git => fuyez, sincèrement, entre anti patern (on est sur du svn like), une interface de fusion qui est pas du tout prédictible et une visualisation qui n’apporte pas d’info, ça vois fera perdre du temps
- Source tree => c’est sympa, quand vous avez un seul remote, sinon ça devient trop chargé. En soit ce qui m’a fait oublier sourcetree c’est que son interface de merge est pas pratique, mes collègues sont obligés de gérer les conflits en copiant/collant du code tellement l’interface fait mal son taf.
- IntelliJ/pycharm => ma favorite, elle est en plus parfaitement intégrée. Le plus gros reproche que je lui fais c’est l’option "commit and push" qui te rouvre un prompt après, j’oublie trop souvent de le valider, ce qui signifie qu’il y a un problème d’ergonomie. Ah et aussi, comment tu peux deviner que "git blame" se transforme en "annotate"?




 Si ça t’intéresse je peux détailler mes cas d’usages.
Si ça t’intéresse je peux détailler mes cas d’usages.

