
Bonjour,
J’essaye d’extraire les 3 premiers nombres (encodés en Int32) d’un fichier binaire.
Ces nombres correspondent à des données utiles (N° de version, type de base de donnée, etc).
Sur l’image ci-dessous, on peut par exemple lire que les 3 premiers nombres sont 4, 1 et 9 :
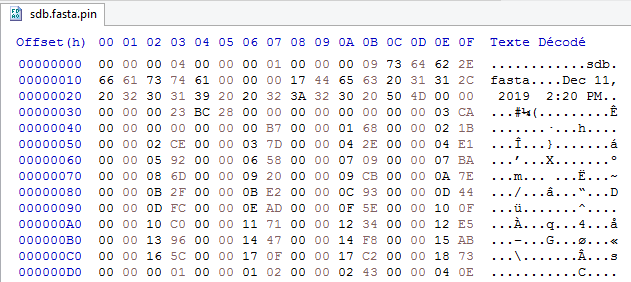
Le problème, c’est que je ne comprends pas du tout pourquoi mon code échoue.
Il renvoie les nombres 0, 0 et 0. Pourtant, je lis bien des entiers 32 bits il me semble.
Une idée d’où pourrait venir le problème ?
Afficher/Masquer le contenu masqué#include <iostream>
#include <fstream>
using std::ios;
using std::cout;
using std::endl;
using std::ifstream;
int main()
{
ifstream f_pin("sdb.fasta.pin", ios::in | ios::binary);
if (!f_pin.is_open())
{
cout << "Impossible d'ouvrir le fichier binaire !" << endl;
return 1;
}
int32_t version;
int32_t db_type;
int32_t title_length;
f_pin >> version;
f_pin >> db_type;
f_pin >> title_length;
cout << "Version de la base de donnée : " << version << endl
<< "Type de BDD (0 ou 1) : " << db_type << endl
<< "Longeur du titre : " << title_length << endl
;
/**
* Ouput attendu :
*
* Version de la base de donnée : 4
* Type de BDD (0 ou 1) : 1
* Longeur du titre : (à déterminer à l'exécution)
*
*/
f_pin.close();
return 0;
}
+0
-0



