
Salut à tous,
J'ai besoin de votre avis car Artragis, Pierre et moi sont confronté à un souci pour l'indexation des données pour la ZEP-12.
Le souci
Haystack ne semble pas être adaptés à nos nouveaux besoins. Grâce à la ZEP 12, on ne stocke plus les parties, chapitres et extraits dans la base de données. Avant on stockait, les parties, chapitres et extraits, plus quelques infos.
Le nouveau besoin est donc d'indexer du contenu, qui n'est pas dans la base de données.
Si on regarde la documentation, dans la partie FAQ, on trouve ceci,
When should I not be using Haystack?
Non-Model-based data. If you just want to index random data (flat files, alternate sources, etc.), Haystack isn’t a good solution. Haystack is very Model-based and doesn’t work well outside of that use case.
C'est effectivement impossible, d'indexer du contenu qui n'est pas dans la base de données, car lors de l'indexation, il faut lui donner un QuerySet (la méthode index_queryset). De plus, le modèle doit forcément étendre Model.model de Django. Lors du renvois des résultats de la recherche, Haystack va chercher dans les modèles enregistré. On peut lui préciser d'autre modèle mais ils doivent étendre Model.model de Django.
Pour plus d'information, sur le pourquoi, je vous renvois vers l'issue, ou j'explique le pourquoi avec le code correspondant.
Les solutions
-
Réindexer tous le contenu dans la base de données et faire comme avant.
- Avantage:
- "c'est comme avant".
- On peut rediriger l'utilisateur jusqu'au extrait.
- L'inconvénients:
- c'est qu'on ré-indexe tout, uniquement pour la recherche. Ça "casse" le travail fait par Artragis et Pierre.
- Avantage:
-
Stocker dans la base de donnée uniquement les extraits. L'idée, serait d'indexer le tuto avec toutes les informations dedans (l'extrait, chapitre, partie). On lance une recherche sur ce contenu en excluant les extraits. Quand on a trouvé quels tutos l'intéresserait. L'utilisateur clique sur un lien, ou on lui propose plusieurs extraits, chapitres, parties qui correspondent à ça recherche.
- Avantage:
- On indexe uniquement les extraits.
- On peut rediriger l'utilisateur jusqu'au extrait.
- Inconvénients:
- Lors de la publication, pandoc créé l'équivalent du chapitre en HTML et on n'a que le chapitre lors de l'indexation, il faut donc récupérer le chapitre en HTML et tenter de lé découper en petite partie, c'est pas du tout évident vu comment sont généré les chapitres en html (pas de délimitation précise entre les extraits).
- On indexe les extraits
- Quand l'utilisateur, clique sur le lien pour afficher les extraits qui correspondent, il faudrait aussi rechercher sur les introductions, conclusions des chapitres, ainsi que les introductions et chapitres et chapitres des parties, à la main. Cela génère donc 2xle nombre de chapitres + 2 x le nombres de parties + 2 (introduction et conclusion du tutoriel) d'IO pour aller lire les contenus sur le disque. De plus, on sera jamais aussi performant en recherchant à la main, qu'en recherchant avec Haystack.
- Avantage:
-
Stocker dans la base de donnée uniquement les chapitres (Poc dispo). L'idée serait la même que pour la solution du-dessus.On n'indexe le tuto avec toutes les informations dedans (l'extrait, chapitre, partie). On lance une recherche sur ce contenu en excluant les chapitres. Quand on a trouvé quels tutos l'intéresserait. L'utilisateur clique sur un lien, ou on lui propose plusieurs extraits, chapitres, parties qui correspondent à ça recherche.
- Avantage:
- On indexe uniquement les chapitres.
- Inconvénients:
- On redirige uniquement vers les chapitres et non plus vers les extraits. C'est suffisant.
- On indexe les chapitres
- Quand l'utilisateur, clique sur le lien pour afficher les chapitres qui correspondent, il faudrait aussi rechercher sur les introductions, conclusions des parties, ainsi que les introductions et conclusion du tutoriel, à la main. Cela génère donc 2 x le nombres de parties + 2 (introduction et conclusion du tutoriel) d'IO pour aller lire les contenus sur le disque. C'est pas non plus énorme, les plus gros tutoriels font 5 parties et donc génère 12 IO et c'est uniquement quand on recherche un big-tuto et que l'utilisateur clique sur le lien.
- Avantage:
Les captures de cette solution, en live:
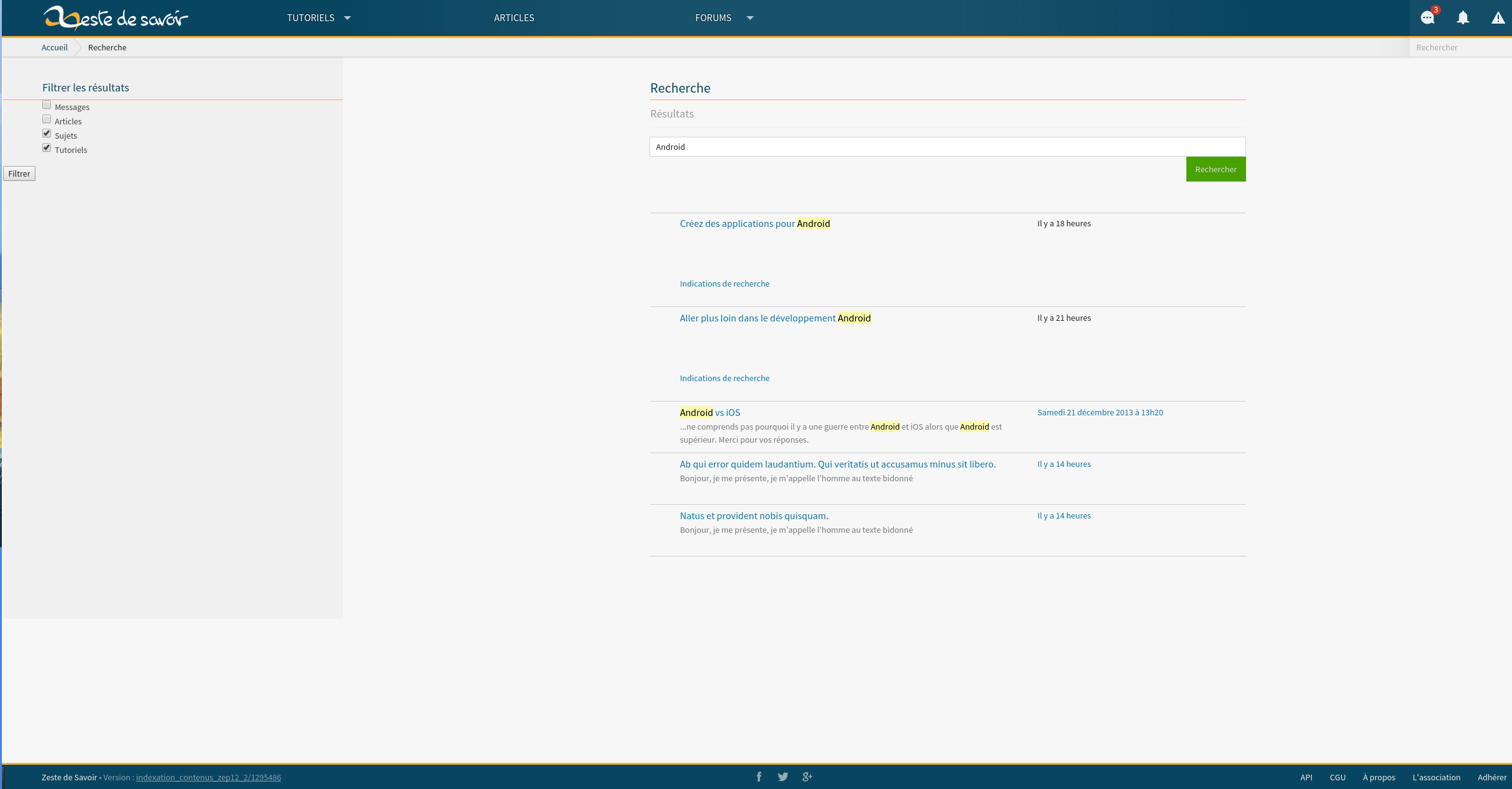
Quand un utilisateur recherche le terme "Android" dans la bare de recherche, il tombe sur cette interface:
 .
.
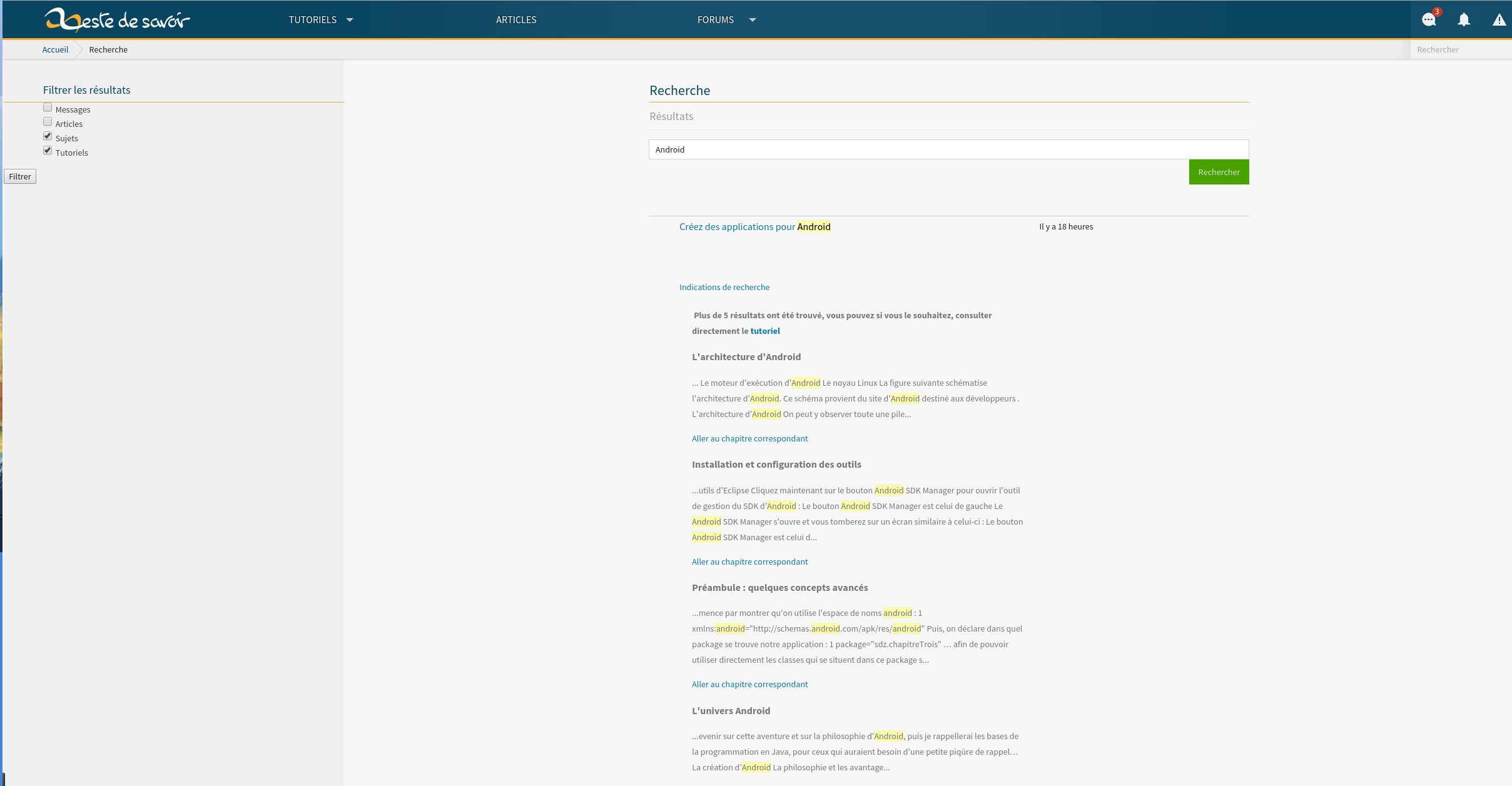
Notez le nouveau lien Indications de la recherche. Si l'utilisateur clique sur le lien, le systéme lui affiche:
 .
.
On voit tous les résultats qui correspondent à ça recherche dans le tutos. Il peut être rediriger sur le chapitre (et non sur l'extrait comme aujourd'hui).
Que faire ?
Quels solutions est dans votre coeur ? Avez-vous une autre solution ? Qu'en pensez-vous ? Une autre lib, qui correspond mieux au besoin ?
PS: Désolé pour le post un peu long … .





