Ce court chapitre a pour unique objectif de vous présenter un type d'objet un peu particulier : le JavaBean. Souvent raccourci en "bean", un JavaBean désigne tout simplement un composant réutilisable. Il est construit selon certains standards, définis dans les spécifications de la plate-forme et du langage Java eux-mêmes : un bean n'a donc rien de spécifique au Java EE.
Autrement dit, aucun concept nouveau n'intervient dans la création d'un bean : si vous connaissez les bases du langage Java, vous êtes déjà capables de comprendre et de créer un bean sans problème particulier. Son utilisation ne requiert aucune bibliothèque ; de même, il n’existe pas de superclasse définissant ce qu'est un bean, ni d'API.
Ainsi, tout objet conforme à ces quelques règles peut être appelé un bean. Découvrons pour commencer quels sont les objectifs d'un bean, puis quels sont ces standards d'écriture dont je viens de vous parler. Enfin, découvrons comment l'utiliser dans un projet ! 
Objectifs
Pourquoi le JavaBean ?
Avant d'étudier sa structure, intéressons-nous au pourquoi d'un bean. En réalité, un bean est un simple objet Java qui suit certaines contraintes, et représente généralement des données du monde réel.
Voici un récapitulatif des principaux concepts mis en jeu. Je vous donne ici des définitions plutôt abstraites, mais il faut bien en passer par là.
- Les propriétés : un bean est conçu pour être paramétrable. On appelle "propriétés" les champs non publics présents dans un bean. Qu'elles soient de type primitif ou objets, les propriétés permettent de paramétrer le bean, en y stockant des données.
- La sérialisation : un bean est conçu pour pouvoir être persistant. La sérialisation est un processus qui permet de sauvegarder l'état d'un bean, et donne ainsi la possibilité de le restaurer par la suite. Ce mécanisme permet une persistance des données, voire de l'application elle-même.
- La réutilisation : un bean est un composant conçu pour être réutilisable. Ne contenant que des données ou du code métier, un tel composant n'a en effet pas de lien direct avec la couche de présentation, et peut également être distant de la couche d'accès aux données (nous verrons cela avec le modèle de conception DAO). C'est cette indépendance qui lui donne ce caractère réutilisable.
- L'introspection : un bean est conçu pour être paramétrable de manière dynamique. L'introspection est un processus qui permet de connaître le contenu d'un composant (attributs, méthodes et événements) de manière dynamique, sans disposer de son code source. C'est ce processus, couplé à certaines règles de normalisation, qui rend possible une découverte et un paramétrage dynamique du bean !
Dans le cas d'une application Java EE, oublions les concepts liés aux événements, ceux-ci ne nous concernent pas. Tout le reste est valable, et permet de construire des applications de manière efficace : la simplicité inhérente à la conception d'un bean rend la construction d'une application basée sur des beans relativement aisée, et le caractère réutilisable d'un bean permet de minimiser les duplications de logiques dans une application.
Un JavaBean n'est pas un EJB
Certains d'entre vous ont peut-être déjà entendu parler d'un composant Java EE nommé « EJB », signifiant Enterprise JavaBean. Si ce nom ressemble très fortement aux beans que nous étudions ici, ne tombez pas dans le piège et ne confondez pas les deux : les EJB suivent un concept complètement différent. Je ne m'attarde pas sur le sujet mais ne vous inquiétez pas, nous reviendrons sur ce que sont ces fameux EJB en temps voulu.
Structure
Un bean :
- doit être une classe publique ;
- doit avoir au moins un constructeur par défaut, public et sans paramètres. Java l'ajoutera de lui-même si aucun constructeur n'est explicité ;
- peut implémenter l'interface
Serializable, il devient ainsi persistant et son état peut être sauvegardé ; - ne doit pas avoir de champs publics ;
- peut définir des propriétés (des champs non publics), qui doivent être accessibles via des méthodes publiques getter et setter, suivant des règles de nommage.
Voici un exemple illustrant cette structure :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | /* Cet objet est une classe publique */ public class MonBean{ /* Cet objet ne possède aucun constructeur, Java lui assigne donc un constructeur par défaut public et sans paramètre. */ /* Les champs de l'objet ne sont pas publics (ce sont donc des propriétés) */ private String proprieteNumero1; private int proprieteNumero2; /* Les propriétés de l'objet sont accessibles via des getters et setters publics */ public String getProprieteNumero1() { return this.proprieteNumero1; } public int getProprieteNumero2() { return this.proprieteNumero2; } public void setProprieteNumero1( String proprieteNumero1 ) { this.proprieteNumero1 = proprieteNumero1; } public void setProprieteNumero2( int proprieteNumero2 ) { this.proprieteNumero2 = proprieteNumero2; } /* Cet objet suit donc bien la structure énoncée : c'est un bean ! */ } |
Exemple
Ce paragraphe se termine déjà : comme je vous le disais en introduction, un bean ne fait rien intervenir de nouveau. Voilà donc tout ce qui définit un bean, c'est tout ce que vous devez savoir et retenir. En outre, nous n'allons pas pour le moment utiliser la sérialisation dans nos projets : si vous n'êtes pas familiers avec le concept, ne vous arrachez pas les cheveux et mettez cela de côté ! 
Plutôt que de paraphraser, passons directement à la partie qui nous intéressera dans ce cours, à savoir la mise en place de beans dans notre application web !
Mise en place
J'imagine que certains d'entre vous, ceux qui n'ont que très peu, voire jamais, développé d'applications Java ou Java EE, peinent à comprendre exactement à quel niveau et comment nous allons faire intervenir un objet Java dans notre projet web. Voyons donc tout d'abord comment mettre en place un bean dans un projet web sous Eclipse, afin de le rendre utilisable depuis le reste de notre application.
Création de notre bean d'exemple
Définissons pour commencer un bean simple qui servira de base à nos exemples :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | package com.sdzee.beans; public class Coyote { private String nom; private String prenom; private boolean genius; public String getNom() { return this.nom; } public String getPrenom() { return this.prenom; } public boolean isGenius() { return this.genius; } public void setNom( String nom ) { this.nom = nom; } public void setPrenom( String prenom ) { this.prenom = prenom; } public void setGenius( boolean genius ) { /* Wile E. Coyote fait toujours preuve d'une ingéniosité hors du commun, c'est indéniable ! Bip bip... */ this.genius = true; } } |
com.sdzee.beans.Coyote
Rien de compliqué ici, c'est du pur Java sans aucune fioriture !
J'ai ici créé un bean contenant seulement trois propriétés, à savoir les trois champs non publics nom, prenom et genius. Inutile de s'attarder sur la nature des types utilisés ici, ceci n'est qu'un exemple totalement bidon qui ne sert à rien d'autre qu'à vous permettre de bien visualiser le concept.
Maintenant, passons aux informations utiles. Vous pouvez remarquer que cet objet respecte bien les règles qui régissent l'existence d'un bean :
- un couple de getter/setter publics pour chaque champ privé ;
- aucun champ public ;
- un constructeur public sans paramètres (aucun constructeur tout court en l'occurrence).
Cet objet doit être placé dans le répertoire des sources "src" de notre projet web. J'ai ici, dans notre exemple, précisé le package com.sdzee.beans.
Jetez un œil aux figures suivantes pour visualiser la démarche sous Eclipse.
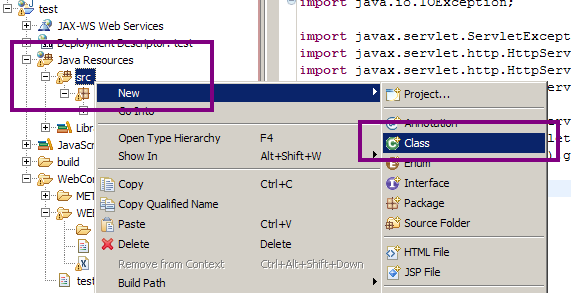
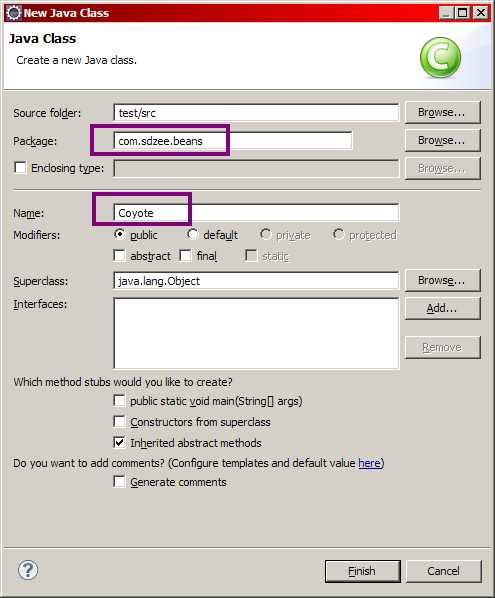
Vous savez dorénavant comment mettre en place des beans dans vos projets web. Cela dit, il reste encore une étape cruciale afin de rendre ces objets accessibles à notre application ! En effet, actuellement vous avez certes placé vos fichiers sources au bon endroit, mais vous savez très bien que votre application ne peut pas se baser sur ces fichiers sources, elle ne comprend que les classes compilées !
Configuration du projet sous Eclipse
Afin de rendre vos objets accessibles à votre application, il faut que les classes compilées à partir de vos fichiers sources soient placées dans un dossier "classes", lui-même placé sous le répertoire /WEB-INF. Souvenez-vous, nous en avions déjà parlé dans le troisième chapitre de la première partie.
Par défaut Eclipse, toujours aussi fourbe, ne procède pas ainsi et envoie automatiquement vos classes compilées dans un dossier nommé "build". Afin de changer ce comportement, il va falloir modifier le Build Path de notre application.
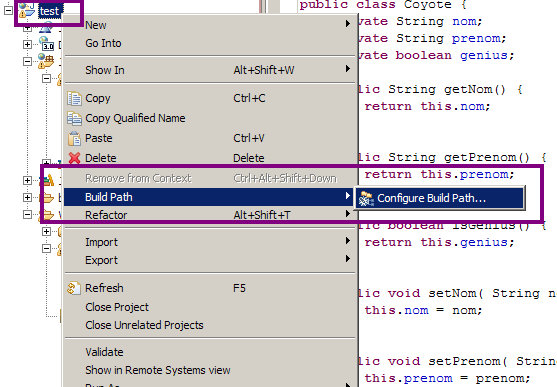
Pour ce faire, faites un clic droit sur le dossier du projet, sélectionnez "Build Path" puis "Configure Build Path…", comme indiqué à la figure suivante.
Sélectionnez alors l'onglet source, puis regardez en bas le champ Default output folder, comme sur la figure suivante.
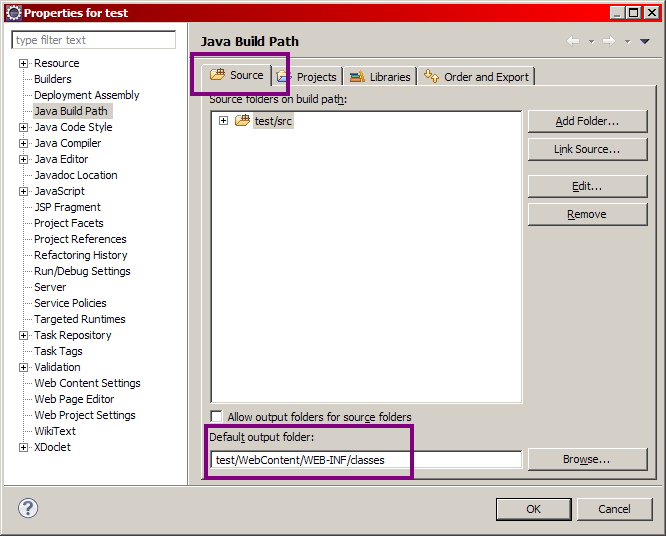
C'est ici qu'il faut préciser le chemin vers WEB-INF/classes afin que nos classes, lors de leur compilation, soient automatiquement déposées dans le dossier pris en compte par notre serveur d'applications. Le répertoire souhaité n'existant pas par défaut, Eclipse va le créer automatiquement pour nous.
Validez, et c'est terminé ! Votre application est prête, vos classes compilées seront bien déposées dans le répertoire de l'application, et vous allez ainsi pouvoir manipuler vos beans directement depuis vos servlets et vos JSP !
Par défaut, Eclipse ne vous montre pas ce répertoire "classes" dans l'arborescence du projet, simplement parce que ça n'intéresse pas le développeur de visualiser les fichiers .class. Tout ce dont il a besoin depuis son IDE est de pouvoir travailler sur les fichiers sources .java ! Si toutefois vous souhaitez vérifier que le dossier est bien présent dans votre projet, il vous suffit d'ouvrir le volet Navigator, comme indiqué à la figure suivante.

Mise en service dans notre application
Notre objet étant bien inséré dans notre application, nous pouvons commencer à le manipuler. Reprenons notre servlet d'exemple précédente :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | ... import com.sdzee.beans.Coyote; ... public void doGet( HttpServletRequest request, HttpServletResponse response ) throws ServletException, IOException{ /* Création et initialisation du message. */ String paramAuteur = request.getParameter( "auteur" ); String message = "Transmission de variables : OK ! " + paramAuteur; /* Création du bean */ Coyote premierBean = new Coyote(); /* Initialisation de ses propriétés */ premierBean.setNom( "Coyote" ); premierBean.setPrenom( "Wile E." ); /* Stockage du message et du bean dans l'objet request */ request.setAttribute( "test", message ); request.setAttribute( "coyote", premierBean ); /* Transmission de la paire d'objets request/response à notre JSP */ this.getServletContext().getRequestDispatcher( "/WEB-INF/test.jsp" ).forward( request, response ); } |
com.sdzee.servlets.Test
Et modifions ensuite notre JSP pour qu'elle réalise l'affichage des propriétés du bean. Nous n'avons pas encore découvert le langage JSP, et ne savons pas encore comment récupérer proprement un bean… Utilisons donc une nouvelle fois, faute de mieux pour le moment, du langage Java directement dans notre page JSP :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | <%@ page pageEncoding="UTF-8" %> <!DOCTYPE html> <html> <head> <meta charset="utf-8" /> <title>Test</title> </head> <body> <p>Ceci est une page générée depuis une JSP.</p> <p> <% String attribut = (String) request.getAttribute("test"); out.println( attribut ); String parametre = request.getParameter( "auteur" ); out.println( parametre ); %> </p> <p> Récupération du bean : <% com.sdzee.beans.Coyote notreBean = (com.sdzee.beans.Coyote) request.getAttribute("coyote"); out.println( notreBean.getPrenom() ); out.println( notreBean.getNom() ); %> </p> </body> </html> |
/WEB-INF/test.jsp
Remarquez ici la nécessité de préciser le chemin complet (incluant le package) afin de pouvoir utiliser notre bean de type Coyote.
Retournez alors sur votre navigateur et ouvrez http://localhost:8080/test/toto. Vous observez alors :
Ceci est une page générée depuis une JSP.
Transmission de variables : OK !
Récupération du bean : Wile E. Coyote
Tout se passe comme prévu : nous retrouvons bien les valeurs que nous avions données aux propriétés nom et prenom de notre bean, lors de son initialisation dans la servlet !
L'objectif de ce chapitre est modeste : je ne vous offre ici qu'une présentation concise de ce que sont les beans, de leurs rôles et utilisations dans une application Java EE. Encore une fois, comme pour beaucoup de concepts intervenant dans ce cours, il faudrait un tutoriel entier pour aborder toutes leurs spécificités, et couvrir en détail chacun des points importants mis en jeu.
Retenez toutefois que l'utilisation des beans n'est absolument pas limitée aux applications web : on peut en effet trouver ces composants dans de nombreux domaines, notamment dans les solutions graphiques basées sur les composants Swing et AWT (on parle alors de composant visuel).
Maintenant que nous sommes au point sur le concept, revenons à nos moutons : il est temps d'apprendre à utiliser un bean depuis une page JSP sans utiliser de code Java !
- Un bean est un objet Java réutilisable qui représente une entité, et dont les données sont représentées par des propriétés.
- Un bean est une classe publique et doit avoir au moins un constructeur par défaut, public et sans paramètres.
- Une propriété d'un bean est un champ non public, qui doit être accessible à travers un couple de getter/setter.
- Il faut configurer le build-path d'un projet web sous Eclipse pour qu'il y dépose automatiquement les classes compilées depuis les codes sources Java de vos objets.
- Un bean peut par exemple être transmis d'une servlet vers une page JSP (ou une autre servlet) en tant qu'attribut de requête.